
多GPU系统的高速互联技术与拓扑发展现状研究
2024-04-18 04:31崔晨吴迪陶业荣赵艳丽
航空兵器 2024年1期
关键词:数据中心
崔晨 吴迪 陶业荣 赵艳丽


摘 要: 多GPU系统通过横向扩展实现性能提升, 以满足人工智能日趋复杂的算法和持续激增的数据所带来的不断增长的计算需求。 对于多GPU系统而言, 处理器间的互联带宽以及系统的拓扑是决定系统性能的关键因素。 在传统的基于PCIe的多GPU系统中, PCIe带宽是限制系统性能的瓶颈。 当前, 面向GPU的高速互联技术成为解决多GPU系统带宽限制问题的有效方法。 本文首先介绍了传统多GPU系统所采用的PCIe互联技术及其典型拓扑, 然后以Nvidia NVLink、 AMD Infinity Fabric Link、 Intel Xe Link、 壁仞科技BLink为例, 对国内外代表性GPU厂商的面向GPU的高速互联技术及其拓扑进行了梳理分析, 最后讨论了关于互联技术的研究启示。
关键词: 多GPU系统; 高速互联技术; 拓扑; 互联带宽; 数据中心
中图分类号: TJ760; TP393
文献标识码: A
文章编号: 1673-5048(2024)01-0023-09
DOI: 10.12132/ISSN.1673-5048.2023.0138
0 引 言
在人工智能三要素中, 随着算法日趋复杂与数据不断激增, 算力逐渐成为人工智能应用创新与落地的关键支撑。
算力的基础是GPU、 FPGA、 ASIC等多种类型的高性能人工智能芯片, 其中GPU在算力峰值、 通用性和兼容性等方面具备较大优势, 成为大多数深度学习模型训练和推理的首选加速器[1-4]。 当前, 全球GPU市场主要由NVIDIA、 AMD、 Intel三家公司垄断, 其先后发布了自己的高性能GPU产品, 通过单个GPU性能的纵向扩展(scale up)和多GPU系统性能的横向扩展(scale out)来满足深度学习不断增长的计算需求。 随着人工智能应用的规模越来越大, 单个GPU通常无法完成训练任务, 多GPU系统逐渐在工作站、 服务器、 超级计算机等各个层面得到了广泛的部署应用[5], 为各种人工智能工作负载提供优异的计算性能和灵活性。
多GPU系统通常以“CPU+GPU”异构计算的方式实现算力扩展, 其中CPU作为控制中心, 对计算任务进行统一调度, 而GPU则作为人工智能加速卡, 专门处理人工智能应用中的大规模矩阵并行计算任务。 使用多GPU系统训练人工智能应用时, 处理器间(CPU-CPU、 CPU-GPU、 GPU-GPU)的互联带宽以及系统的拓扑是影响系统性能的关键因素, 决定了处理器间数据交换的速度, 进而影响了GPU优异的浮点运算性能的实际利用率。 对于CPU-CPU互联, 以Intel CPU为例, 通常通过快速通道互联(Quick Path Interconnect, QPI)或超级通道互联(Ultra Path Interconnect, UPI)进行通信。 而对于CPU-GPU和GPU-GPU互联, 传统的多GPU系统通过PCIe将多个GPU直接与CPU相连, GPU之间则无法直接进行点对点(Peer-to-Peer, P2P)通信, 并且由于CPU提供的PCIe通道数量有限, 因此支持的GPU数量是有限的。 PCIe Switch芯片可用于扩展系统中的PCIe通道数量, 一方面能够容纳更多的GPU, 另一方面同一个PCIe Switch下的GPU可以实现P2P通信。 然而, 随着多GPU系统中GPU相对于CPU的比例持续增长, 且PCIe的带宽远小于CPU和GPU到其DRAM的带宽, 使得PCIe带宽成为限制多GPU系统性能的瓶颈。 当前, 面向GPU的高速互联技术成为解决多GPU系统中带宽限制问题的主流方法。
1 PCIe及其典型拓扑
1.1 PCIe
PCIe是一种高速串行计算机扩展总线标准, 其前身是Intel公司于2001年推出的“3GIO”, 经PCI-SIG認证规范后正式命名为“PCI-Express”, 简称“PCIe”[6]。 PCIe总线作为第三代I/O总线, 具备传输数据速度快、 信号抗干扰能力强、 传输距离远、 功耗低等优点, 使其快速取代ISA和PCI总线, 成为当下应用最为广泛的外设互联协议[7]。 经过约20年的技术迭代与优化, PCIe总线已形成6个标准版本的规范, 如表1所示。 表中的×16表示通道(Lane)数。 PCIe通过链路(Link)实现两台设备的点对点物理连接, 一条链路可以包含×1、 ×2、 ×4、 ×8、 ×12、 ×16、 ×32个信号对, 每一组收发信号对称为一条通道。
2022年1月, PCI-SIG正式发布了PCIe 6.0规范。 PCIe 6.0的主要技术要点是不再采用之前版本所采用的不归零编码(Non-Return-to-Zero, NRZ)调制方式, 而是改用四电平脉冲幅度调制(Pulse Amplitude Modulation 4-Level, PAM4)[8]。 图1给出了这两种调制方式的对比示意图。 NRZ是一种两电平调制技术(PAM2), 采用高、 低两种电平表示逻辑0和1, 每个时钟周期可传输1 bit的逻辑信息。 随着传输速率提高, PCIe的信道衰减越来越大, 使得采用NRZ方法将数据速率提升到32.0 GT/s以上时存在重大挑战。 PAM4使用四种电平来表示四种2 bit的逻辑信息, 即00、 01、 10、 11, 且每个时钟周期可以传输2 bit的逻辑信息。 在相同波特率下, PAM4的数据速率是NRZ的两倍。 此外, PCIe 6.0引入了前向纠错(Forward Error Correction, FEC)机制和循环冗余校验(Cyclic Redundancy Check, CRC), 以缓和PAM4的高误码率[9]。
2022年6月, PCI-SIG在开发者大会上宣布PCIe 7.0规范正在开发中, 预计2025年正式发布。 PCIe 7.0同样采用PAM4调制方式, 单通道最大数据速率为128 GT/s, ×16配置下可实现高达512 GT/s的双向带宽。
1.2 典型的PCIe拓扑
在传统的多GPU系统中, 采用的是PCIe直通的方式将多个GPU直接与CPU连接, 如图2(a)所示。 这种互联方式存在两个缺点。 一是GPU之间无法直接进行P2P通信, 二是由于CPU提供的PCIe通道数量有限, 且网卡等其他设备对PCIe的需求也在不断增加, 因此系统能够支持的GPU数量是有限的。
PCIe Switch芯片可用于扩展系统中的PCIe通道数量。 其具有一个上行端口(upstream port)和若干个下行端口(downstream port), 其中上行端口连接主设备, 下行端口连接端节点设备(endpoint), 或者连接下一级Switch继续扩展PCIe链路[10-11]。 通过PCIe Switch对PCIe总线进行扩展, 一方面可以使系统容纳更多的GPU, 另一方面同一个PCIe Switch下的GPU可以实现P2P通信。
在基于PCIe Switch扩展的多GPU系统中, 主要有三种典型的拓扑, 分别为: Balance拓扑; Common拓扑; Cascade拓扑[12], 如图2(b)~(d)所示。 在这三种拓扑中, 同一个PCIe Switch下的GPU可以实现P2P通信, 不同PCIe Switch下的GPU的通信方式则有所不同。 Balance拓扑中不同PCIe Switch下的GPU通常通过CPU之间的QPI或者UPI进行通信(Intel CPU), Common拓扑中则是跨PCIe Root Port进行通信, Cascade拓扑中2级PCIe Switch下的GPU可以实现P2P通信, 不再需要通过PCIe Root Port。
目前PCIe Switch芯片的核心厂商主要是美国的博通(Broadcom)和微芯科技(Microchip), 表2给出了这两家公司的代表性PCIe Switch产品。 其中, Microchip的PCIe Switch分为PFX、 PSX和PAX三个类型, 分别对应于Fanout、 Programmable和Advanced Fabric三种PCIe Switch。 PSX和PAX比PFX擁有更高级的功能, 比如PSX是客户可编程的, 并提供相应的软件开发套件, 而PAX则能够提供高性能的光纤连接。
2 面向GPU的高速互联技术及其拓扑
随着多GPU系统中GPU相对于CPU的比例持续增长, 且PCIe的带宽远小于CPU和GPU到其DRAM的带宽, 使得PCIe带宽成为限制多GPU系统性能的瓶颈。 此外, 高带宽存储(High Bandwidth Memory, HBM)在GPU中得到广泛应用, 且HBM1[13], HBM2[14-16], HBM2E[17-18], HBM3[19-20]的每管脚速率越来越高, 使得GPU与DRAM之间的数据交换带宽得到了大幅提升。 如果仍基于PCIe实现GPU的P2P通信, 则会进一步加剧PCIe带宽对系统性能的影响。 于是, GPU厂商开始寻求面向GPU的高速互联方式, 如Nvidia NVLink, AMD Infinity Fabric Link, Intel Xe Link和壁仞科技BLink等。
2.1 Nvidia NVLink
Nvidia在2016年发布的Pascal架构GPU(P100)中, 推出了新的高速接口——NVLink 1.0。 NVLink 1.0采用Nvidia全新的高速信号互联(High-Speed Signaling interconnect, NVHS)技术, 一条链路由一对Sub-Link组成, 每个Sub-Link对应一个发送方向并包含8个差分信号对, 每个差分信号对以20 Gb/s的速度传输NRZ形式的差分电信号, 因此一条链路的双向带宽为40 GB/s, P100支持4条链路, 从而能够获得160 GB/s的总双向带宽[5, 21]。 NVLink 1.0既支持GPU-GPU的P2P通信, 也支持CPU-GPU的P2P通信(P100可与IBM的POWER8 CPU通过NVLink 1.0互联), 并允许GPU对远端CPU的主机内存和相连GPU的设备内存进行直接读写。
在NVLink 1.0之后, Nvidia又在2017年的Volta架构(V100)中推出了NVLink 2.0[22], 在2020年的Ampere架构(A100)中推出了NVLink 3.0[23], 在2022年的Hopper架构(H100)中推出了NVLink 4.0[24]。 表3给出了四代NVLink的参数对比。 从表中可以看出, 虽然每条链路的信号对数在逐渐减少, 但每个信号对的数据速率在逐渐增加, 使得每条链路的双向带宽增长到50 GB/s以后保持稳定。 而随着GPU包含的链路数量越来越多, GPU间的双向带宽也在持续增大。 在调制方式上, 前三代NVLink均采用NRZ, 而NVLink 4.0开始采用PAM4[25]。
图3给出了基于NVLink的DGX系统的拓扑[5,22-24]。 基于Pascal架构和NVLink 1.0, Nvidia推出了世界上第一款专为深度学习构建的服务器——DGX-1。 图3(a)是DGX-1系统的混合立方体网格(Hybrid Cube Mesh)拓扑, 其中左右两边的4个P100构成了2个NVLink全连接的四边形, 2个四边形之间也用NVLink进行连接, 每个四边形中的GPU则通过PCIe分别与对应的CPU相连。 通过使用单独的NVLink将2个四边形相连, 一方面能够缓解PCIe上行链路的压力, 另一方面能够避免通过系统内存和CPU间链路进行路由传输[5]。 随着GPU架构的演进, Nvidia对DGX系统不断进行升级。 图3依次给出了基于V100的DGX-1系统(图3(b))、 基于V100的DGX-2系统(图3(c)), 以及DGX A100系统(图3(d))和DGX H100系统(图3(e))的拓扑。 可以看出, DGX系统的拓扑与GPU所包含的链路数紧密相关。 由于实现多GPU系统性能持续扩展的关键是灵活、 高带宽的GPU间通信, 因此在DGX-2系统中, Nvidia引入了NVSwitch 1.0交换芯片。 NVSwitch 1.0具有18个NVLink端口, 每个端口能够与任意其他端口以50GB/s的双向带宽进行全速通信。 DGX-2含有2块基板, 每块基板上有8块V100和6个NVSwitch 1.0, 这是因为V100包含6条链路, 能够同时与6个NVSwitch 1.0连接。 每个NVSwitch 1.0中, 有8个NVLink端口用于基板上的GPU间通信, 另外8个NVLink端口用于与另一块基板相连, 还预留了2个NVLink端口。 因此, DGX-2的GPU间带宽为300 GB/s(50 GB/s×6NVLinks), 总的对分带宽(bisection bandwidth)为2.4TB/s(50 GB/s×8NVLinks×6NVSwitches)。 目前, NVSwitch已经升级到3.0, 表4给出了各版本NVSwitch的参数对比。
从图3(e)可以看出, DGX H100系统中ConnectX-7网络模块取代了PCIe Switch用于GPU与CPU的连接。 NVLink是用于系统内的GPU间高速通信, 而为了实现深度学习和高性能计算工作负载的多系统扩展, 则需要提升多系统中GPU之间的通信能力。 Nvidia ConnectX-7单端口InfiniBand卡默认情况下能够提供高达400 Gb/s的InfiniBand速率, 或者配置高达400 Gb/s的Ethernet速率。 实际上在基于V100的DGX-1和DGX A100系统中都用到了ConnectX网络模块, 不过此时其与系统中的PCIe Switch相连, 用于实现多系统扩展, 其中基于V100的DGX-1系统中采用的是4块ConnectX-4(100 Gb/s), DGX A100中采用的是8块ConnectX-6(200 Gb/s)。
2023年5月, Nvidia发布了Grace Hopper超级芯片, 以及由256块Grace Hopper超级芯片通过NVLink 4.0全互联的DGX GH200系统。 Grace Hopper超级芯片是Nvidia专为大规模人工智能和高性能计算设计的第一款GPU-CPU超级芯片, 将Hopper架构的GPU和Arm架构的Grace CPU通过具有高带宽和内存一致性的Nvidia NVLink Chip-2-Chip(C2C)互联, 并封装在一起构成一个超级芯片[26]。 而DGX GH200中定制的NVLink Switch系统将NVLink 4.0和NVSwitch 3.0相结合, 构成包含96个L1级NVSwitch和36个L2级NVSwitch的两级无阻塞胖树拓扑, 将256个Grace Hopper超级芯片整合成一个整体协同运行, 摆脱了此前的DGX A100和DGX H100等系统中单级NVSwitch最多只能连接8个GPU的限制。 DGX GH200系统旨在处理大规模推荐系统、 生成式人工智能和图形分析等TB级模型, 可为巨型人工智能模型提供144 TB的共享内存和1 exaFLOPS的FP8性能[27]。
除了面向深度学习的DGX系统, Nvidia還构建了面向人工智能与高性能计算的HGX系统、 面向数据中心和边缘的EGX系统、 面向工业边缘人工智能的IGX系统等。
2.2 AMD Infinity Fabric Link
随着2017年发布基于全新的Zen架构的锐龙(Ryzen)桌面CPU和霄云(Epyc)服务器CPU, AMD引入了新的内外部互联总线技术——Infinity Fabric Link 1.0(IF Link 1.0), 用于实现CPU-CPU互联, 每条链路的双向带宽为42 GB/s。 IF Link 1.0集数据传输与控制于一体, 由传输数据的Scalable Data Fabric(SDF)和负责控制的Scalable Control Fabric(SCF)两个独立的通信平面组成, 其中SDF提供核心、 内存和IO之间的一致性数据传输, SCF为系统的配置和管理提供通用的命令和控制机制, SDF和SCF均可以在同一裸片(die)内、 同一封装(package)内的裸片间以及双插槽系统(two-socket system)中的封装之间进行通信[28-29]。 SDF有两种不同的SerDes(Serializer/Deserializer)类型, 一种是IF on-package(IFOP), 用于封装内裸片间的短途互联, 另一种是IF inter-socket(IFIS), 用于不同插槽上芯片间的长途互联[30]。
2018年, AMD发布面向计算领域的镭龙(Radeon)Instinct MI50和MI60 GPU加速器(均为Vega20架构), 采用IF Link 2.0技术, 支持GPU-GPU互联, 且每条链路的双向带宽增加到了92 GB/s, 每个MI50或MI60包含2条IF Link, 可通过4块GPU构成一个环状拓扑, 实现184 GB/s的对分带宽[31]。 图4给出了基于IF Link的AMD多GPU系统的拓扑[32-33], 其中的图4(a)是环状拓扑的示意图。 2020年, AMD发布了专门针对高性能计算和人工智能而设计的CDNA架构, 同年发布了基于CDNA架构的数据中心GPU——Instinct MI100加速器。 MI100采用IF Link 2.0技术, 以23 GT/s传输速率和16-bit单向位宽实现92 GB/s的双向带宽, 每个MI100包含3条IF Link, 可实现276 GB/s的GPU-GPU带宽, 此外还可以通过PCIe 4.0直连的方式提供64 GB/s的CPU-GPU带宽[34]。 4块MI100可以构成一个全连接的四边形拓扑(如图4(b)所示), 对分带宽增加到了368 GB/s。 这种全连接的拓扑能够提高常见的通信模式(例如all-reduce和scatter/gather)的性能, 而这些通信原语广泛应用于高性能计算和深度学习, 例如训练神经网络时的权重更新通信阶段[32]。
2021年, AMD发布了CDNA 2架构, 并先后发布了由基于CDNA 2架构的图形计算裸片(Graphcis Compute Die, GCD)封装而成的Instinct MI200系列加速器, 包括2021年发布的MI250和MI250X, 以及2022年的MI210。 CDNA 2架构的主要改进之一就是基于IF Link 3.0技术提升了每个GCD的通信能力, 每颗GCD包含8条IF Link, 每条链路的双向带宽为100 GB/s。 MI250和MI250X的外形规格为OAM(OCP Accelerator Module)形态, 均包含2颗GCD, 每颗GCD的其中4条IF Link用于OAM封装内的2颗GCD互联(GCD间的最大双向带宽为400 GB/s), 其余4条IF Link则用于与其他加速器或者主机互联, MI250最多可提供6条外部IF Link, MI250X最多可提供8条外部IF Link。 MI210为PCIe形态, 只包含1颗GCD, 最多可提供3条外部IF Link。 GCD中有1条特殊的链路, 其既可以作为一致性主机接口, 也可以作为下行PCIe4.0接口。 该接口的物理层为16通道的IF Link, 当与优化的第三代AMD霄云CPU相连时, 该接口逻辑上可作为IF接口, 实现缓存一致性; 当与其他x86服务器CPU相连时, 这个接口会退化为标准的PCIe接口, 实现与主机的非一致性通信[33]。
表5给出了三代IF Link的参数对比。 IF Link 3.0支持一致性的CPU-GPU互联, 可实现CPU的DRAM内存与GPU的HBM内存的一致性内存架构。 在图4(c)所示的基于MI250X加速器的拓扑中, MI250X中的GCD通过IF Link与优化的第三代AMD霄云CPU相连。 图4(d)所示的基于MI250加速器的拓扑以及图4(e)所示的基于MI210加速器的拓扑是更为主流的机器学习拓扑, GPU通过PCIe 4.0与主机CPU相连, 此时CPU-GPU互联受限于PCIe带宽, IF Link主要用于提升GPU-GPU的互联带宽以及GPU内部的GCD-GCD互联带宽。 另外图4(d)与图4(e)中霄云CPU间的互联用较粗的IF Link表示, 这是因为CPU间的IF Link数量是可变的, 取决于系统的实现方式。
根据AMD于2022年6月发布的新的CDNA架构路线图, 其预计将于2023年推出CDNA3架构以及MI300数据中心APU。 MI300将基于CDNA3架构的GPU与基于Zen 4架构的霄云CPU通过3D堆叠集成到一个封装内, 采用IF Link 4.0技术实现基于HBM内存的统一内存架构, 以进一步降低延迟、 提高能效。
2.3 Intel Xe Link
Intel在其2020年架构日发布了名为Xe的GPU架构家族, 主要包括针对集成显卡和低功耗的XeLP微架构、 针对高性能游戏的XeHPG微架构、 针对数据中心和人工智能的XeHP微架构以及针对高性能计算的XeHPC微架构。 2021年, Intel进一步公布了XeHPC微架构的IP模块信息。 XeHPC微架构由2个堆栈(stack)组成, 每个堆栈包含4个切片(Xe slice), 64个核心(Xe core), 以及8条高速一致性Xe Link。 XeHPC微架构共包含16条Xe Link, 能够实现GPU-GPU的高速一致性数据传输。
2023年1月, Intel推出了针对高性能计算和人工智能设计的数据中心GPU Max 1550(代号为Ponte Vecchio), 采用OAM外形规格, 具有16个端口, Xe Link带宽为53 GB/s。 Max 1550可通过Xe Link构成2卡、 4卡、 6卡、 8卡的全互联拓扑, 图5给出了8卡全互联拓扑的示意图。 Intel 起初规划推出的Max系列GPU除了600W OAM形态的Max 1550, 还有450W OAM形态的Max 1350(16个端口), 以及300W PCIe形态的Max 1100(6个端口)。 2023年4月, Intel对Max系列GPU布局进行了调整, 移除了Max 1350, 并将在后续推出Max 1450, 通过降低I/O带宽以满足不同的市场需求。
与Nvidia的GH200超级芯片以及AMD的MI300数据中心APU类似, Intel原计划推出将其x86 CPU和Xe GPU集成封装到一起的高性能计算XPU(代号为Falcon Shores), 但根据Intel最新消息, 新的Falcon Shores设计将转向纯GPU核心, 并计划于2025年发布。
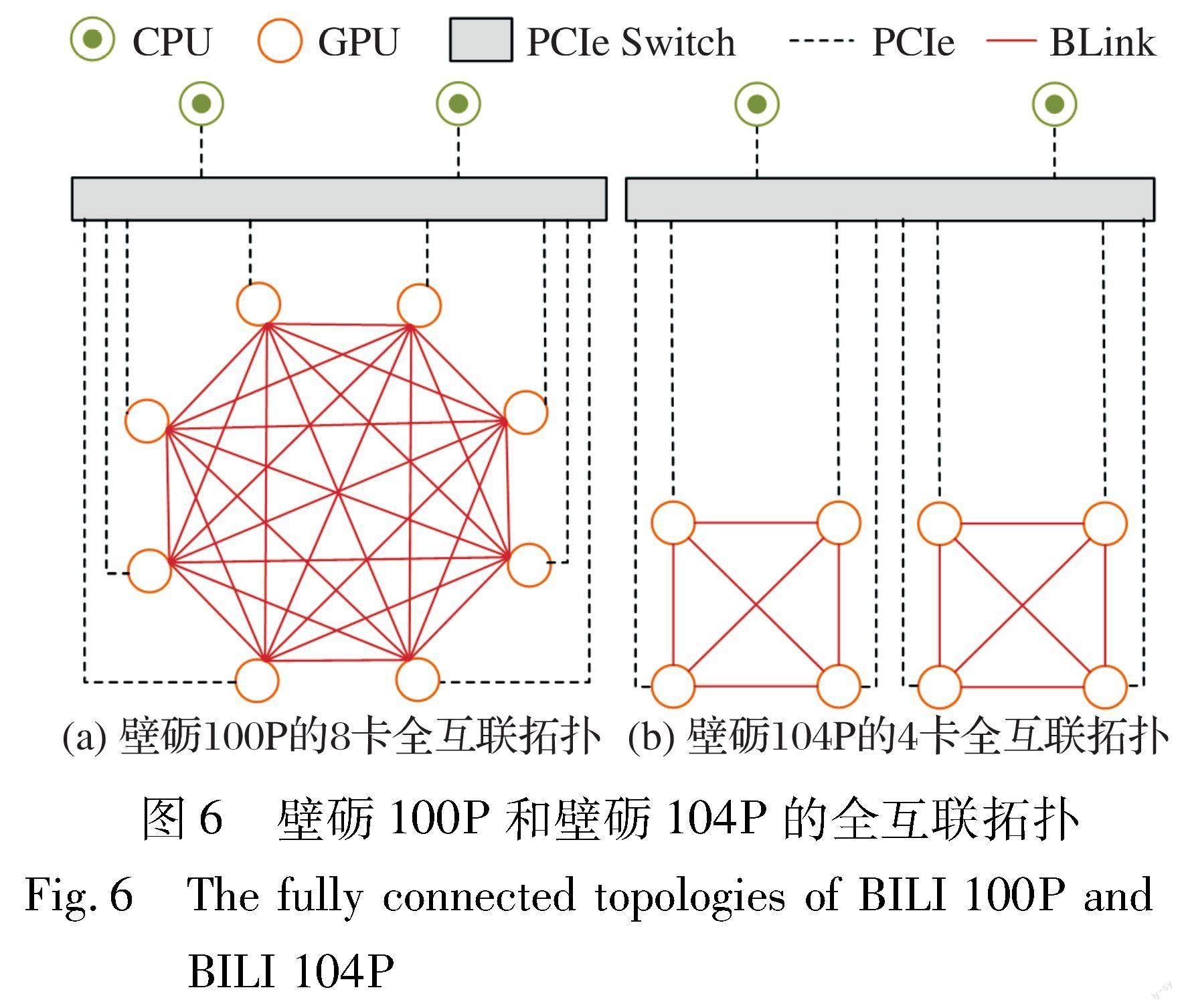
2.4 壁仞科技BLink
壁仞科技是一家成立于2019年的國产GPU公司。 2022年8月, 壁仞科技发布了基于“壁立仞”架构的通用GPU算力产品BR100芯片和BR104芯片, 均采用芯粒(Chiplet)设计理念, 前者包含2个计算芯粒, 后者包含1个计算芯粒, 同时, 壁仞科技还发布了基于BR100的壁砺100P OAM模组, 以及基于BR104的壁砺104P PCIe板卡[35]。
为了实现系统性能扩展, 壁仞科技自研了BLink接口, 每条链路的双向数据速率为64 Gb/s, BR100芯片包含8个×8端口, 每组×8BLink的双向带宽为64 GB/s。 壁砺100P OAM模组支持7个×8端口, 总计可提供448 GB/s的双向带宽, 最高可实现8卡全互联(如图6(a)所示)。 壁砺104P PCIe板卡支持3个端口, 总计提供192 GB/s的双向带宽, 最高可实现4卡全互联(如图6(b)所示)。
3 研究启示
3.1 计算与内存性能快速提升, 互联带宽面临更高要求
表6给出了Nvidia和AMD两家公司数据中心GPU的计算和内存性能。 其中FP32是深度学习训练中最为常用的格式, 表中给出的FP32性能指的是向量计算性能; INT8是推理阶段的一个流行格式, 表中给出的INT8性能指的是带有张量核心(Nvidia)或矩阵核心(AMD)的性能。 凭借日益先进的芯片工艺, 以及张量核心/矩阵核心、 HBM内存等技术的助力, GPU的计算性能与内存性能得到了快速提升。
当使用多GPU系统进行神经网络的并行化训练时, 无论是采用数据并行还是模型并行, 都需要在GPU之间进行通信, 其中数据并行通过传递梯度完成对参数的更新, 通信开销较小, 而模型并行需要传递特征图, 其通信开销会远大于数据并行。 目前, 面向GPU的高速互联技术相比于传统的PCIe在互联带宽方面已经取得了非常大的性能提升, 如采用NVLink 4.0的Nvidia Hopper架构GPU的互联带宽已达到900 GB/s, 而PCIe 5.0(×16)的带宽则为126 GB/s。 然而, 与GPU优异的计算性能和上千GB/s的内存带宽相比, 互联技术仍然需要进一步升级, 只有这样才能支撑数据在GPU间的快速流转, 从而提升GPU的算力利用率, 充分释放多GPU系统的算力性能。
3.2 高速互联技术之间存在兼容性问题
当前, 数据中心对计算加速硬件的需求不断上升, GPU以及多GPU系统拥有广阔的市场空间, 国内外众多厂商纷纷推出了自己的GPU产品和面向GPU的高速互联技术。 然而, 各个厂商的面向GPU的高速互联技术主要基于私有协议实现, 各技术之间存在兼容性问题, 不同厂商的GPU互联时无法有效利用面向GPU的高速互联通道, 往往需要通过传统的PCIe实现通信, 这就导致在支持高速互联的多GPU系统中通常只能包含来自同一个厂商的多个GPU, 限制了多GPU系统配置的灵活性。 因此, 需要考虑面向GPU的通用高速互联技术, 一方面支持不同厂商的GPU之间进行高速互联, 使得用户可根据需求在多GPU系统内部配置不同厂商的GPU, 提升配置的灵活性; 另一方面也能打破技术壁垒, 有助于降低数据中心GPU的使用成本。
3.3 Balance拓扑是面向GPU的高速互联技术的主流拓扑
由图2可知, 在Balance拓扑中GPU被平均分配到各个CPU, 整个系统结构对称、 负载均衡。 同一个PCIe Switch下的GPU可以进行P2P通信, 不同PCIe Switch下的GPU则需要通过CPU之间的QPI/UPI等进行通信。 由于各CPU挂载的GPU数量均衡, 总的PCIe上行带宽较高, CPU-GPU通信性能较好。 通过对基于Nvidia NVLink、 AMD IF Link、 Intel Xe Link、 壁仞科技BLink的多GPU系统拓扑进行梳理分析, 可以发现结构对称、 负载均衡的Balance拓扑是目前基于面向GPU的高速互联技术的数据中心多GPU系统的主流拓扑。
結合Balance拓扑特点, 初步分析有以下几个原因。 一是虚拟化在数据中心发展中扮演着重要地位, 而Balance拓扑适合GPU直通虚拟化, 能够保证虚拟化时GPU资源的性能均衡。 二是Balance拓扑具有广泛的适用性, 既适用于训练或推理等人工智能场景, 也适用于高性能计算场景。 三是Balance拓扑总的上行带宽较高, 其良好的CPU-GPU通信性能有利于充分发挥CPU的逻辑控制和GPU的并行计算性能。 四是随着GPU支持的高速互联链路数量的增加, 多GPU系统内的走线也越来越复杂, 而结构对称、 负载均衡的拓扑有利于简化布局、 节省空间。
3.4 异构超级芯片成趋势, CPU-GPU互联是关键
无论是Nvidia已经发布的Grace Hopper超级芯片, 还是AMD将要发布的MI300数据中心APU, 以及Intel原计划推出的“Falcon Shores” XPU, 都预示着“CPU+GPU”的异构超级芯片将成为下一代数据中心高性能芯片的主流架构趋势。 随着Intel将其“Falcon Shores”设计转向纯GPU核心, 意味着未来几年内Intel将在与Nvidia和AMD的超级芯片竞争中处于劣势。
对于“CPU+GPU”的异构超级芯片而言, CPU-GPU互联是超级芯片的关键技术。 以Grace Hopper超级芯片为例, 其通过NVLink C2C将Grace CPU和Hopper GPU互联。 NVLink C2C是基于NVLink技术的处理器间互联技术, 具有以下四点优势。 一是支持一致内存模型, 一方面CPU和GPU线程可以同时且显式地访问CPU和GPU的内存, 另一方面可以采用LPDDR5X拓展GPU可访问的内存容量。 二是高带宽, NVLink C2C可提供每方向450 GB/s、 共计900 GB/s的双向带宽, 是PCIe 5.0(×16)的7倍多。 三是低延迟, 支持处理器和加速器之间的load/store等原子操作, 能够对共享数据进行快速同步和高频更新。 四是相比于PCIe 5.0, NVLink C2C有明显的能效与面积优势。
根据AMD目前对MI300 APU的架构设计, 其将从CDNA 2的一致内存架构, 升级为CDNA 3的统一内存架构。 需要注意的是, 这里的一致内存架构中CPU的DRAM内存和GPU的HBM内存位于不同的封装内, 虽然能够基于IF Link 3.0实现内存一致性, 但是不具备统一的内存地址空间; 而在统一内存架构中, CPU和GPU位于同一封装内, 且采用统一的HBM内存, 不再需要冗余的数据拷贝。 MI300 APU采用IF Link 4.0技术, 可实现高带宽、 低延迟、 高能效的CPU-GPU互联。
4 结 束 语
本文对传统的PCIe互联技术及其典型拓扑, 以及Nvidia NVLink、 AMD Infinity Fabric Link、 Intel Xe Link、 壁仞科技BLink等面向GPU的高速互联技术及其拓扑进行了梳理分析, 并讨论了关于互联技术的研究启示。 相比于PCIe, 这些面向GPU的高速互联技术具有两个特征: 一是带宽远高于PCIe, 能够显著加快GPU间的数据交换速度, 提升多GPU系统的并行训练性能; 二是除了GPU-GPU互联以外, 还可以支持CPU-CPU或CPU-GPU等类型的处理器互联方式, 增加了多GPU系统拓扑的灵活性, 并进一步提升了多GPU系统的整体性能。
本文所讨论的互联技术针对的是处理器间的互联, 包括CPU-CPU、 CPU-GPU和GPU-GPU。 对于多GPU系统而言, 除了处理器间的互联, 处理器与内存、 网卡、 I/O设备等的互联也是决定多GPU系统性能的重要因素。 而对于由多个多GPU系统构成的多节点超级计算机系统来说, 还需要考虑节点间的互联技术, 如InfiniBand、 以太网等。 此外, 带宽是各种互联技术的主要指标, 但同时也需要对延迟与能效进行综合考量, 只有这样才能在提升互联速度的同时降低使用成本。 未来可结合异构超级芯片, 进一步研究互联带宽、 算力资源等的有效利用问题, 充分释放多GPU系统的高性能计算能力。
参考文献:
[1] Raina R, Madhavan A, Ng A Y. Large-Scale Deep Unsupervised Learning Using Graphics Processors[C]∥26th Annual International Conference on Machine Learning, 2009: 873-880.
[2] Krizhevsky A, Sutskever I, Hinton G E. ImageNet Classification with Deep Convolutional Neural Networks[J]. Communications of the ACM, 2017, 60(6): 84-90.
[3] Sermanet P, Eigen D, Zhang X, et al. OverFeat: Integrated Recog-nition, Localization and Detection Using Convolutional Networks[EB/OL]. (2013-12-21)[2023-07-13].https:∥arxiv.org/abs/1312.6229.pdf
[4] Simonyan K, Zisserman A. Very Deep Convolutional Networks for Large-Scale Image Recognition[EB/OL].(2014-09-04)[2023-07-13].https:∥arxiv.org/abs/1409.1556.pdf
[5] Nvidia Tesla P100 Whitepaper[EB/OL]. (2016-04-28)[2023-04-17]. http:∥images.nvidia.cn/content/pdf/tesla/whitepaper/pascal-architecture-whitepaper.pdf.
[6] 王法臻, 崔少輝, 王成. PCIe设备驱动程序开发的关键技术[J]. 现代电子技术, 2021, 44(16): 65-69.
Wang Fazhen, Cui Shaohui, Wang Cheng. Key Technologies of PCIe Device Driver Development[J]. Modern Electronics Technique, 2021, 44(16): 65-69.(in Chinese)
[7] 金黄斌. 支持PCIe的千兆以太网芯片设计与验证[D]. 成都: 电子科技大学, 2022.
Jin Huangbin. Design and Verification of Gigabit Ethernet Chip Supporting PCIe[D].Chengdu: University of Electronic Science and Technology of China, 2022. (in Chinese)
[8] 李实. 从1.0到6.0的飞跃之路: PCIe总线技术发展解析[J]. 微型计算机, 2019(24): 94-99.
Li Shi. The Leap Path from 1.0 to 6.0: Analysis of PCIe Bus Technology Development[J]. MicroComputer, 2019(24): 94-99. (in Chinese)
[9] Das Sharma D. PCI Express 6.0 Specification: A Low-Latency, High-Bandwidth, High-Reliability, and Cost-Effective Interconnect with 64.0 GT/s PAM-4 Signaling[J]. IEEE Micro, 2021, 41(1): 23-29.
[10] 郑桥, 韩力, 邢同鹤, 等. 基于PCIe Switch的存储阵列[J]. 电子设计工程, 2019, 27(14): 126-129.
Zheng Qiao, Han Li, Xing Tonghe, et al. Storage Array Based on PCIe Switch[J]. Electronic Design Engineering, 2019, 27(14): 126-129.(in Chinese)
[11] 刘鑫, 林凡淼, 刘凯. 基于FPGA的可动态配置国产PCIe Switch应用设计[J]. 电子设计工程, 2021, 29(17): 80-84.
Liu Xin, Lin Fanmiao, Liu Kai. Application Design of Dynamically Configurable Domestic PCIe Switch Based on FPGA[J]. Electronic Design Engineering, 2021, 29(17): 80-84.(in Chinese)
[12] 林楷智, 宗艳艳, 孙珑玲. AI服务器PCIe拓扑应用研究[J]. 计算机工程与科学, 2022, 44(3): 390-395.
Lin Kaizhi, Zong Yanyan, Sun Longling. Research on PCIe Topology Application of AI Server[J]. Computer Engineering & Science, 2022, 44(3): 390-395.(in Chinese)
[13] Lee D U, Kim K W, Kim K W, et al. 25.2 A 1.2V 8Gb 8-Channel 128GB/s High-Bandwidth Memory (HBM) Stacked DRAM with Effective Microbump I/O Test Methods Using 29nm Process and TSV[C]∥IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC), 2014: 432-433.
[14] Lee J C, Kim J, Kim K W, et al. 18.3 A 1.2V 64Gb 8-Channel 256GB/s HBM DRAM with Peripheral-Base-Die Architecture and Small-Swing Technique on Heavy Load Interface[C]∥IEEE International Solid-State Circuits Conference (ISSCC), 2016: 318-319.
[15] Sohn K, Yun W J, Oh R, et al. A 1.2 V 20 nm 307 GB/s HBM DRAM with At-Speed Wafer-Level IO Test Scheme and Adaptive Refresh Considering Temperature Distribution[J]. IEEE Journal of Solid-State Circuits, 2017, 52(1): 250-260.
[16] Cho J H, Kim J, Lee W Y, et al. A 1.2V 64Gb 341GB/s HBM2 Stacked DRAM with Spiral Point-to-Point TSV Structure and Improved Bank Group Data Control[C]∥IEEE International Solid-State Circuits Conference(ISSCC), 2018: 208-210.
[17] Lee D U, Cho H S, Kim J, et al. 22.3 A 128Gb 8-High 512GB/s HBM2E DRAM with a Pseudo Quarter Bank Structure, Power Dispersion and an Instruction-Based at-Speed PMBIST[C]∥IEEE International Solid-State Circuits Conference(ISSCC), 2020: 334-336.
[18] Oh C S, Chun K C, Byun Y Y, et al. 22.1 A 1.1V 16GB 640GB/s HBM2E DRAM with a Data-Bus Window-Extension Technique and a Synergetic on-Die ECC Scheme[C]∥IEEE International Solid-State Circuits Conference(ISSCC), 2020: 330-332.
[19] Park M J, Lee J, Cho K, et al. A 192-Gb 12-High 896-GB/s HBM3 DRAM with a TSV Auto-Calibration Scheme and Machine-Learning-Based Layout Optimization[J]. IEEE Journal of Solid-State Circuits, 2023, 58(1): 256-269.
[20] Ryu Y, Kwon Y C, Lee J H, et al. A 16 GB 1024 GB/s HBM3 DRAM with on-Die Error Control Scheme for Enhanced RAS Features[C]∥IEEE Symposium on VLSI Technology and Circuits (VLSI Technology and Circuits), 2022: 130-131.
[21] Foley D, Danskin J. Ultra-Performance Pascal GPU and NVLink Interconnect[J]. IEEE Micro, 2017, 37(2): 7-17.
[22] Nvidia Tesla V100 GPU Architecture[EB/OL]. (2017-08-05)[2023-05-31]. https:∥images.nvidia.cn/content/volta-architecture/pdf/volta-architecture-whitepaper.pdf.
[23] Nvidia A100 Tensor Core GPU Architecture[EB/OL]. (2020-07-09)[2023-05-31]. https:∥images.nvidia.cn/aem-dam/en-zz/Solutions/data-center/nvidia-ampere-architecture-whi-tepaper.pdf.
[24] Nvidia H100 Tensor Core GPU Architecture[EB/OL]. (2022-08-04)[2023-05-31]. https:∥resources.nvidia.com/en-us-tensor-core.
[25] Ishii A, Wells R. The NVlink-Network Switch: Nvidias Switch Chip for High Communication-Bandwidth Superpods[C]∥IEEE Hot Chips 34 Symposium (HCS), 2022: 1-23.
[26] Nvidia Grace Hopper Superchip Architecture[EB/OL]. (2023-05-04)[2023-05-31]. https:∥resources.nvidia.com/en-us-grace-cpu/nvidia-grace-hopper.
[27] Nvidia DGX GH200 Datasheet[EB/OL]. (2023-05-06)[2023-06-01]. https:∥resources.nvidia.com/en-us-dgx-gh200/nvidia-dgx-gh200-datasheet-web-us.
[28] Lepak K, Talbot G, White S, et al. The Next Generation AMD Enterprise Server Product Architecture[J]. IEEE Hot Chips, 2017, 29.
[29] Burd T, Beck N, White S, et al. “Zeppelin”: An SoC for Multichip Architectures[J]. IEEE Journal of Solid-State Circuits, 2019, 54(1): 133-143.
[30] Beck N, White S, Paraschou M, et al. ‘Zeppelin: An SoC for Multichip Architectures[C]∥IEEE International Solid-State Circuits Conference(ISSCC), 2018: 40-42.
[31] AMD Radeon Instinct MI50 Datasheet[EB/OL]. (2018-06-24)[2023-06-06]. https:∥www.amd.com/system/files/documents/instinct-mi100-brochure.pdf.
[32] AMD CDNA Architecture[EB/OL]. (2020-11-30)[2023-06-07]. https:∥www.amd.com/system/files/documents/amd-cdna-whitepaper.pdf.
[33] AMD CDNA 2 Architecture[EB/OL]. (2021-11-30)[2023-06-07]. https:∥www.amd.com/system/files/documents/amd-cdna2-white-paper.pdf.
[34] AMD Instinct MI100 Accelerator Brochure[EB/OL]. (2020-05-23)[2023-06-01]. https:∥www.amd.com/system/files/documents/instinct-mi100-brochure.pdf.
[35] Hong M K, Xu L J. 壁仞TM BR100 GPGPU: Accelerating Datacenter Scale AI Computing[C]∥IEEE Hot Chips 34 Symposium (HCS), 2022: 1-22.
Research on the Development Status of High Speed Interconnection
Technologies and Topologies of Multi-GPU Systems
Abstract: Multi GPU systems achieve performance improvement through scaling out to meet the ever-increasing computation demand brought about by increasingly complex algorithms and the continuously increasing data in artificial intelligence. The interconnection bandwidth between processors, as well as topologies of systems are the key factors that determine the performance of multi-GPU systems. In traditional PCIe-based multi-GPU systems, the PCIe bandwidth is the bottleneck that limits system performance. GPU-oriented high speed interconnection technologies become an effective method to solve the bandwidth limitation problem of multi-GPU systems at present. This article first introduces the PCIe interconnection technology and the typical topologies used in traditional multi-GPU systems. Then taking Nvidia NVLink, AMD Infinity Fabric Link, Intel Xe Link, and Biren Technology BLink as examples, GPU-oriented high speed interconnection technologies and topologies of representative GPU vendors at home and abroad are reviewed and analyzed. Finally, the research implication of interconnection technologies is discussed.
Key words: multi-GPU system; high speed interconnection technology; topology; interconnection bandwidth;data center
猜你喜欢
机械研究与应用(2022年4期)2022-09-15
铁道通信信号(2019年8期)2019-10-10
西藏艺术研究(2019年1期)2019-09-04
电子测试(2018年11期)2018-06-26
电子测试(2018年11期)2018-06-26
现代传输(2016年5期)2016-12-19
广东石油化工学院学报(2016年3期)2016-05-17
通信电源技术(2016年5期)2016-03-22
中国交通信息化(2015年8期)2015-06-06
中国交通信息化(2015年3期)2015-06-05
