
压缩感知字典迁移重构的小样本轴承故障诊断
2024-05-07 02:15孙洁娣赵彬集温江涛时培明
振动与冲击 2024年5期
孙洁娣,赵彬集,温江涛,时培明
(1.燕山大学 信息科学与工程学院,河北 秦皇岛 066004;2.燕山大学 河北省信息传输与信号处理重点实验室,河北 秦皇岛 066004;3.燕山大学 河北省测试计量技术及仪器重点实验室,河北 秦皇岛 066004)
现代大型机械和设备日益复杂化、智能化,滚动轴承作为齿轮箱、动力机械等旋转机械的关键部件,其故障会造成巨大的经济损失甚至带来严重的生命威胁。
近年来,传统的故障诊断方法已逐步发展到智能诊断阶段,基于深度学习的故障诊断方法已成为当前的热点[1-2]。旋转机械智能故障诊断研究自深度学习引入后,摆脱了传统方法对专业知识及诊断经验的过度依赖,通过构建深度神经网络以及对大量样本数据的充分学习,取得了优越的诊断性能。学者们研究了多种基于深度网络模型的诊断方法[3-5],大量研究成果在采用实验室或公开数据库的数据验证时都获得了很好的效果。深度模型的良好性能依赖于故障类别明确、有标签样本充足的可靠数据集,然而在实际工业环境中,工况变化复杂难以预知,采集的新测试样本与训练样本分布差异较大;且监测过程中采集的多为正常状态样本,特定故障类型的有效标签样本极少甚至缺失,这些都造成严重的可学习数据信息不充足的情况,因此深度神经网络方法在面临“小样本、变工况”复杂场景识别时,性能受到极大影响,严重限制了此类方法在实际中的应用。为此,学者们从不同角度为解决小样本智能故障诊断问题进行了广泛研究。
近年来,迁移学习的发展为小样本分类问题提出了新的思路。不同工况下数据的边际分布存在差异,这就导致故障诊断理论算法与工程应用之间存在着障碍。特征迁移学习通过使域分布差异最小化[6-7]获取域间共享特征来消除这种障碍。分布差异通常由最大均值差异(maximum mean discrepancy,MMD)[8]指标来衡量,学者们提出的多种MMD改进算法[9-10]能更好地衡量域间差异,获得更佳的域不变特征提取效果。在提升分布差异函数性能的同时,优化域对齐算法可进一步改善域不变特征。Wu等[11]提出了一种深度强化传输卷积神经网络来解决分布差异问题,能够自主学习故障样本与相应标签之间的潜在关系。Yin等[12]提出基于迁移动态自动编码的学习框架,通过提取数据的动态特征,再用迁移学习解决不同场景下的模型自适应问题。Si等[13]提出了一种具有力矩匹配的无监督深度传输网络,利用灰度时频图像作为网络输入,并采用两种自适应方法来减少分布差异。通过分析文献发现,目前的特征迁移方法主要关注如何分析信号来寻找域不变特征,为此构造的深度神经网络通常较为复杂,训练时间较长,用于缩小域差异的优化函数构造不易,寻找目标域和源域共享的域不变特征一直是研究的重点和难点。
对故障样本进行扩充从而改变数据不平衡状态是另一个解决小样本故障诊断问题的研究方向。此类方法通过对原始一维时域故障信号进行反转、缩放、拼接等多种操作生成新样本,在增加样本量的同时尽可能保证新生成样本的主要故障特征与原始信号相似[14-15];更为常用的做法是利用可变长度的时间窗进行重叠切分来增加训练样本量,此类数据增强方法[16-20]样本变换方式简单,但扩充的数量较少,故障样本多样性不足,不利于深度网络学习,为此学者们研究了基于过采样插值的数据合成方法,最为经典的就是合成少数类过采样技术(synthetic minority oversampling technique,SMOTE)及其变体方法[21]。此类方法在真实样本基础上利用线性插值方法合成新样本,缓解了随机过采样方法带来的过拟合问题。但基于SMOTE的方法合成的样本质量较低,容易降低数据特征的整体稳定性。自适应合成采样(adaptive synthetic sampling,ADASYN)方法[22]通过细化原始SMOTE的样本合成规则,提高了合成样本的质量,但易受到合成规则的影响。
利用生成式对抗网络[23](generative adversarial network,GAN)来产生新样本是目前的另一大类方法。GAN通过生成与真实数据相似的假数据,尽可能地捕捉给定真实数据的分布,生成信号可与原始信号具有相同的分布,在一定程度上缓解了数据不足的问题[24]。目前,GAN已成为故障诊断领域解决数据不足问题的主流方法,Zhang等[25-26]采用GAN方法生成新的样本以扩充训练数据集,并将其用于训练故障诊断模型,提升了模型的泛化性能。但GAN类方法会受到梯度消失、模态崩溃等影响,易导致生成的数据相似度不高;且当只有少量真实一维信号样本的情况下,对样本内在的有效信息学习能力不足,生成的信号质量不佳。
增加小类别样本数量是解决数据不平衡问题的有效方法。当前多数方法主要针对故障样本的时域信号进行处理,仅采用少量样本、集中在时域生成的方法易受原信号影响,出现生成信号质量不高、样本重叠、泛化等问题。GAN类方法存在训练困难、生成样本多样性不足等问题,且若需要生成多种不同类型的故障数据需要重新进行网络训练和调整。如何从本质上挖掘不同类型样本内在的有效故障信息,从多个角度生成样本信号,在增加数量的同时丰富样本多样性,具有重要的理论研究和应用意义。
近年来发展起来的压缩感知(compressed sensing,CS)理论,将传统的对信号采样转化为对信息的采样,通过变换空间投影方法实现了对原始信号有效信息的获取。压缩感知变换得到的是一种新的变换域信号,它以新的形式包含了原时域信号的全部有用信息[27]。采用不同的重构方法对同一采集结果进行逆向变换后,可以得到含有相同有效信息但时域表征略有差异的重构信号。这一独特的性质为解决机械故障诊断领域面临的数据不平衡问题提出了新的思路!基于字典学习的重构算法因其良好的重构性能和灵活的字典构造方法,在轴承故障领域得到了较为广泛的研究[28-29]。Wang等[30]提出了一种有较深且共享结构的字典学习方法,采用有特征传递的字典层,通过共享结构学习不同类别的共同特征,提取特征后用于故障诊断。Zhao等[31]提出了一种新的数据融合驱动的稀疏表示学习框架,通过融合策略消除每个故障类字典中原子共享中不重要的特征,进一步提高了融合字典的可辨别性,可用于小而不平衡的样本的故障诊断。Chen等[32]提出了一种多尺度交替方向乘法的字典学习,可用于轴承故障诊断的故障脉冲提取和特征增强。利用字典学习方法获取源域故障字典,将其迁移至目标域后结合压缩感知重构方法生成目标域样本信号,达到扩充样本量、解决小样本分类问题的目的。
针对实际轴承故障诊断中,有标签数据极少的小样本情况严重影响深度网络模型的识别性能的问题,本文将压缩感知重构与特征迁移学习结合,提出了一种新的基于字典迁移的压缩感知重构数据增强方法。文中首先对典型故障信号进行学习生成原始故障字典,再通过迁移学习方法获得目标域迁移字典,最后通过压缩感知重构生成目标域新样本信号,在此基础上训练深度神经网络模型,实现小样本轴承故障诊断。文中采用广泛使用的智能诊断网络验证了所提出的方法,结果表明本文方法可在获得域不变特征基础上,实现数据的增强和多样性的充实,且诊断性能较好。
1 相关理论概述
1.1 常用的数据增强方法
在轴承故障诊断领域,常用来进行一维故障振动样本增加的方法包括滑动窗重叠切分、线性插值以及GAN方法。
传统的方法主要采用固定长度的窗对获取的一维振动信号进行重叠切分,此类方法处理简便,速度快,且通过调整重叠率可以进行不同程度的样本扩充。不足之处包括仅对部分数据进行重复,未考虑对故障信息的影响;另外受重叠率影响,扩充的数据量有限。
SMOTE作为一种结合临近样本生成新样本的过采样技术,通过计算欧氏距离得到每个少数类样本的一些邻居样本。再随机从最近K个邻居中选取扩增倍数个邻居样本,并按照以下公式分别与原样本构建一个新的样本。
(1)
此类方法有效缓解了随机过采样引起的过拟合问题,由于算法简单而得到广泛应用。然而在选择最近邻样本时存在一定的随机性,且关键参数K值确定困难,难以保证增强效果的稳定,还易出现分布边缘化问题。
生成对抗网络利用生成器和判别器之间博弈的结果[33]、在判别器的监督下由生成器生成样本。如果生成数据的分布能够与真实的数据分布吻合,那么判别器将被最大限度地混淆。在数据增强领域,由于一维数据变换方式单一,GAN生成数据的多样性不如二维信号丰富,同时其模型训练中出现的梯度消失会使生成的样本与实际样本相差较大,模式崩溃则将导致最终生成的样本固化,缺乏多样性。训练时需要大量的标记样本作为模型的输入,但生成样本的质量难以控制,且训练时间较长。
1.2 基于字典学习的压缩感知重构
由Candes等[34]提出的CS在实际工程应用领域得到广泛应用。
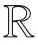
YM×1=ΦM×NXN×1
(2)
这少量的测量Y中包含了信号X的全部有用信息,观测信号M与原信号长度N之间的维数差异可定义为压缩比(compression ratio,CR)
(3)
结合测量矩阵,采用不同的优化算法可由压缩采集结果重构出原信号。字典学习类重构算法以数据的稀疏性为前提,用少量字典原子线性组合的方式表示数据的绝大部分信息,其目标函数如式(4)。
(4)
2 本文提出的算法
实际轴承故障诊断中,因小样本问题导致深度神经网络类故障识别方法性能受到较大影响。本文以压缩感知故障信息提取为基础,结合字典学习和域间迁移,提出一种基于学习字典原子迁移重构的数据增强方法,解决小样本故障识别问题。首先利用源域数据通过小波包字典优化算法生成特定字典,之后利用目标域样本微调表示系数生成迁移字典,再通过迁移字典生成更多有目标域特征的新样本,用生成的新样本训练深度神经网络故障识别模型,可实现高准确度的轴承故障诊断。图1为本文方法的整体处理过程。

图1 本文方法的整体处理过程
2.1 源域特定字典生成
结合轴承故障信号特性生成特定的字典,能够更好地描述信号。小波包分解是轴承故障信号分析中的有效方法,本文采用小波包分解字典优化方法来生成源域特定字典。首先对小波包分解结果进行优化,再采用已优化的小波包字典分解方法获得初始化基础字典[37],最终通过K-SVD学习生成优化的分解字典。具体的字典构建过程如图2所示。

图2 小波包字典优化算法流程
第一阶段小波包变换矩阵初始化,小波包基函数提取低通和高通滤波器序列,再通过零值扩展、循环移位、合并矩阵和矩阵相乘等操作,形成最终的小波包变换矩阵。第二阶段是字典原子更新,优化具有普适性的小波包初始字典,可通过结合故障信号特征进一步提高表示系数的稀疏程度,该算法的详细过程如下。
步骤1输入先验信息构建小波包基函数。
步骤2构造小波包分解矩阵和重构矩阵,并将小波包重构矩阵作为初始小波包字典。
步骤3输入训练样本数据、构建小波包初始字典和设置K-SVD参数。
步骤4初始小波包字典通过K-SVD算法优化,转化成优化小波包字典。
对于本文研究的一维振动信号,若长度为N的信号中只有T0个元素是非零的,那么本文中将其稀疏度用非零元素的个数T0来表示。
2.2 目标域迁移字典生成
目前多数研究中源域信号来自实验室,能提供大量故障样本,而目标域由于是真实场景数据,故障样本极度缺乏。在共享表示系数的基础上,将源域字典向目标域进行迁移,生成迁移字典,再结合表示系数生成目标域信号,可以实现目标域样本扩充。
本文引入在线字典学习中的字典更新方法来实现字典迁移,可在保证源域表示系数基本不变的前提下生成目标域字典。
以生成的源域特定字典和源域表示系数为基础,目标域真实样本为信息输入,固定表示系数,优化源域字典使其转化成含有目标域信息的迁移字典。
微调表示系数,继续优化目标域迁移字典,使其对目标域样本有更佳的分解效果。
具体过程见算法1。

算法1迁移的字典更新算法要求:x为目标域样本,λ∈RR(正则化参数),Do∈RRN×k(初始字典),T(迭代次数)。1:A0∈RRk×k←0,B0∈RRN×k←0(重置“过去”信息)。2 At←At-1+αtαTt3 Bt←Bt-1+xtαTt4 使用算法2计算DtDt≜arg minD∈C1t∑ti=112xi-Dαi22+λαi1()= arg minD∈C1t12Tr(DTDAt)-Tr(DTBt)()5 结束:返回Dt(学习词典)。
在线字典学习方法可以单独更新字典。具体过程见算法2。给定一个表示系数矩阵,通过字典更新算法获得一个近似的字典。无须设置超参数和调整学习率,且运行时间较短。
为了避免字典在更新过程中收敛过快,本文采用正交追踪匹配算法[38]来微调表示系数,它在每一次迭代中计算原子内积的残差,选择局部最优原子,然后用原始信号的逐步逼近来计算该原子的系数。通过小波包字典优化算法生成的字典能够与源域样本很好的匹配,与表示系数结合后生成重构的信号与原始信号误差极小。K-SVD可得出指定稀疏度的稀疏表示系数,正交追踪匹配算法也关注信号的稀疏度。正交追踪匹配算法通过在字典中原子与表示系数正交,通过残差值促进表示系数更新,其更新迭代次数取决于表示系数稀疏度。正交追踪匹配算法通过局部获取表示系数值,得到指定稀疏度的表示系数。这既保证表示系数这一域共享特征的基本不变,也促进了字典的进一步更新。

算法2稀疏编码更新要求:D=[d1,…,dk]∈RRN×k(输入字典),样本x。初始化:初始残差,支撑索引集,迭代初始值j=1。迭代过程:在第T0∗k取整次循环中执行(1)~(3)。(1) 寻找支撑索引:λk=arg maxi=1,…,Nrk-1,di。(2) 将寻找到的最相关字典元素的索引加入索引集:Λk=Λk-1∪{λk}。(3) 更新残差:rk=x-DΛk(DTΛkDΛk)-1DTΛkx。输出:支撑索引集Λk=Λk-1,稀疏系α^=(DTΛkDΛk)-1DTΛkx返回到字典学习更换稀疏编码。
通过以上的字典更新过程,实现了源域字典向目标域字典的迁移,生成了迁移字典。用共享表示系数与迁移字典可生成具有目标域特征样本。
2.3 目标域样本扩充
实际故障诊断中目标域数据来自真实场景,本文的目标域字典生成后,需要少量有标签的目标域样本提供目标域信息,促使字典重构样本时能够更好地向目标域迁移,为此提出用稀疏表示分类算法先筛选目标域标签真实样本,再进行新样本生成。
首先将用于字典学习的由源域样本组成的过完备字典作为基函数,然后通过自适应追踪算法从字典中找到少量的原子,最后通过线性组合的方式拟合目标信号[39]。其目标函数如式(5)所示。
(5)
式中:α为表示系数;λSRC为正则化平衡参数。本文采用的正则化最小化方法为最小绝对值收缩和选择因子算法,可解决L1-范数回归问题,即最小化α={αj}。
(6)
其中∑|αj|≤s,此算法可以选择和缩减变量,作为一个凸函数算法,计算较为方便。先计算表示系数,再通过残差值判断测试样本y标签的真实性,筛选规则可用式(7)表示
(7)
通过残差值来判断目标域样本与源域样本的差异程度,残差值较小的样本更接近标签样本,能够更好地被同类源域样本稀疏表示,可迁移性更好。
通过小波包字典优化算法创建源域字典和表示系数,再通过字典迁移方法生成目标域迁移字典。大量有标签的源域表示系数与目标域迁移字典相乘会生成大量具有目标域特征的样本,完成小样本下目标域样本的数据扩增,采用生成的新样本来训练深度智能故障识别模型,可实现准确的故障识别。
3 实验情况概述
本文选用西储大学(Case Western Reserve University,CWRU)轴承数据中心[40]和机械故障预防技术轴承数据中心[41](Mechanical Fault Prevention Technology,MFPT)的实验数据来进行验证。CWRU实验数据由6205-2 RS JEM SKF深沟球轴承测量信号组成,该信号的轴承负载分别为0 hp、1 hp、2h p、3 hp。本文选取0 hp负载数据作为源域,负载为3 hp数据作为目标域,假设目标域信号处于小样本情况,而源域故障信号较为充足并已标注。需识别的类型包括正常数据(Normal,N)、轴承内圈故障(inner failure,IF)、滚动元件故障(rolling failure,RF)和外圈相对位置重合区(6点方向的中心位置,outer failure,OF),样本长度1 024。参数如表1所示。

表1 CWRU训练集参数
MFPT轴承数据选取0.235 dm滚筒直径和1.245 dm间隔直径的轴承实验结果,识别的类型包括正常数据(N)、轴承内圈故障(IF)、滚动体故障(RF)和外圈相对位置复合故障(OF)。标签0和1的样本在270 lbs负载下,输入轴频率为25 Hz,采样率为97 656 Sa/s;其他的采样率为48 828 Sa/s,输入轴频率为25 Hz。目标域数据是由负载为50和300 lbs的两种外圈故障、50和250 lbs的两种内圈故障和270 lbs下健康和外圈故障数据共六种故障组成。源域数据参数详如表2所示。

表2 MFPT训练集参数
4 本文方法的数据增强效果分析
4.1 生成样本的时频域质量评估
本文分别选取CWRU中的40个样本、MFPT中的50个样本作为目标域真实样本。源域样本通过字典学习,获得共享表示系数组,与迁移字典相乘可以逼近目标域真实样本。
对于一维时域振动信号,本文用归一化均方误差和皮尔逊相关系数来衡量目标域样本生成的效果。图3和4分别为源域信号、真实样本及生成样本结果。此处以某个内圈及外圈故障信号的生成结果为例,图3给出两种故障信号的时域波形。

(a) 内圈故障
从内圈和外圈故障的目标域生成信号的时域结果能够看出,由源域信号经迁移重构后生成的信号与目标域信号相似性较高;生成的内圈故障与真实内圈故障信号的皮尔逊相关度系数可达到98.75%,归一化均方误差3.83%;外圈故障的皮尔逊相似度系数可达到99.05%,归一化均方误差3.06%。
为了进一步衡量生成信号的质量,图4给出图3中各信号的频域结果。

(a) 内圈故障
从图4(a)和(b)能够看出,真实信号和生成信号在频域上较为相似。迁移重构后的样本与目标域原始样本的平均Pearson相似系数为0.979 7±0.021,NMSE为0.073 9±0.239。
KL(Kullback-Leible)散度可用于衡量两个概率分布之间相似性,为此本文用KL散度来衡量不同数据增强方法产生的数据与原始数据之间的差异程度。本文方法、SMOTE和GAN生成的内圈与外圈故障数据与原始数据分布的KL散度值如表3所示。

表3 KL散度测量值
与其他数据生成方法相比,本文方法生成的IR和OR故障信号在数据分布上与原始信号更为相似。本文方法生成的所有类别的故障数据与原始数据的平均KL散度为0.608。
由以上的实验结果可知,本文数据增强方法生成的信号从时域和频域都能与目标域信号较为相似,说明在迁移字典基础上生成新样本的方法是可行且有效的。
4.2 生成信号的故障特征频率分析
轴承故障信号的特征频率是识别故障类型的关键信息。此部分评估本文方法生成的目标域样本特征的保留情况。此处以西储数据负载为3 hp转速为1 730 r/min的目标域内圈故障原始信号为例,采用EEMD分解结合包络谱的方法分析其特征频率。分析结果如图5所示。

(a) 原始故障信号的包络谱结果
由图5(a)的结果可以看到,原始信号与生成信号的包络谱较为相似,表明二者的主要特性相似;图5(b)中,由EEMD分解后的IMF分量及其对应的分量谱可以看出,部分生成信号与原始信号存在一定差异。源域字典建立后,故障信号可唯一地用字典原子与表示系数的组合来描述,因此源域样本的多样性使得表示系数也具有多样性;当目标域迁移字典生成后,表示系数与目标域字典重构生成的信号也具有多样性,既具有目标域的特征,但又与真实目标域样本不尽相同。
4.3 生成样本的特征分布
为验证迁移重构生成样本的合理性以及目标域数据在分类时的判别性,本小节将真实样本以及不同增强算法生成的样本进行特征提取结果的可视化,即将新样本集输入至卷积网络中提取特征后用T-SNE进行可视化。各种方法生成样本的特征分布散点图如图6所示。

图6 各种方法生成样本特征分布图
由图6可知,本文方法生成的样本具有更大的类间距离和更小的类内距离,更有利于提高故障诊断准确率。
5 数据增强对故障诊断效果的影响
5.1 测试网络简介
本文提出的数据增强方法主要用于解决标签样本不足情况下的轴承故障诊断,提高小样本情况下深度神经网络方法的诊断准确率,为了测试本文增强方法生成的样本对于故障诊断效果的影响,此处给出采用常用的深度网络来进行故障分类的结果。
CNN作为一种性能优良的神经网络,在故障诊断领域得到了广泛的应用。现有研究结果表明其网络深度对于复杂信号的学习和分类效果有一定影响,因此本文采用了深度不同的两种卷积网络来验证本文生成样本的有效性,分别为层数较少的一般卷积网络以及稠密网络(DenseNet)。本文构造的一般卷积网络结构如图7所示。

图7 一般CNN网络结构
CNN主要由卷积层、最大池化层和分类器层构成。卷积层和最大池化层用于特征学习。分类器层通过学习的特征将样本分为不同的类别。
本文用于验证的另一种卷积神经网络为稠密网络,其参数如表4所示。

表4 稠密网络参数
DenseNet采用密集连接机制:即互相连接所有的层,每个层都会接受其前面所有层作为其额外的输入。密集连接机制使每个层都会与前面所有层在通道维度上连接在一起,并作为下一层的输入,直接连接来自不同层的特征图,可实现特征重用,提升效率。
5.2 数据增强方法对小样本诊断的性能改善
基于深度学习的智能诊断方法在实际应用中面临小样本情况,严重影响深度网络模型的识别性能。文中提出的数据增强方法能够生成具有故障信号特性的新样本,可用于训练深度网络,且效果较好。本节通过统计实验结果看到本文方法对小样本情况下网络诊断性能的改善。
选取MFPT数据集的数据进行实验,诊断网络为前文的一般CNN网络,采用数据集中的真实故障样本训练网络后进行诊断,图8中浅色柱状结果为不同数量样本训练后的多次诊断平均准确率及标准差。由结果可以看到,当训练样本量减少时,诊断性能下降明显,即同样的诊断网络在故障样本较少时,诊断效果会受到严重影响。图中的深色柱状统计结果为采用本文的数据增强算法,将训练样本量增加后的诊断结果,可以看到诊断效果有了明显改善。

图8 本文增强方法与不同数量真实样本训练网络后的诊断准确率统计
5.3 不同增强算法的诊断结果及分析
本文从压缩感知有效信息提取及重构的思想出发,通过将源域故障字典迁移生成目标域迁移字典,并结合表示系数可在目标域产生大量样本,改善目标域有效样本缺乏的情况。为了验证本文方法的效果,分别采用本文方法增强的样本与常用数据增强算法生成的样本来训练两种测试诊断网络,并分析诊断性能。对比的增强方法为:重叠采样、SMOTE及GAN方法,采用不同的数据增强方法构成的训练样本集主要包括:
(1) 源域:大量有标签源域样本数据。
(2) 真实样本:少量有标签目标域样本数据。
(3) SMOTE,GAN和本文方法:采用这些方法将少量有标签目标域样本数据扩充到同等规模。
(4) 真+源:真实样本和源域样本的数据组合。
(5) 本+源:本文方法生成的数据和源域数据的组合。
所有数据都进行相同的预处理之后,按照上述组合构成训练数据集训练诊断网络提取特征,后续进行故障诊断。
为避免随机因素影响,进行15次故障诊断实验,统计平均诊断准确率和偏差如图9所示。

(a) CWRU数据集结果
由图9和表5的诊断结果看到,由于源域和目标域信号差异较大,直接用源域样本训练模型去识别目标域故障,识别准确率不高;采用SMOTE、GAN及本文方法进行数据增强后,识别准确率有了较大改善,且用本文方法增加的样本训练识别网络,诊断效果好于使用其他两种。

表5 不同数据增强方法诊断准确率统计
综合以上结果可以发现,一方面,采用浅层CNN网络由于较浅的网络特征提取能力不足,当源域与目标域信号差异较大时,识别性能一般;另一方面本文所提方法与其它数据增强方法相比,相同数量的标签样本训练的深度模型,在诊断准确率提升上有较大优势。通过数据增强的目标域新样本和源域样本组成更大规模的数据集可使诊断准确度进一步提升。本文提出方法在CWRU数据集上的诊断准确率比真实样本高2%左右,比其他数据增强方法高1%以上;在MFPT数据集中比真实样本高3.5%左右,比其他数据增强方法高3%以上。
采用同样的训练样本集来训练稠密网络,实验的结果如图10所示。

(a) CWRU数据集结果
由图10和表6的稠密网络诊断结果可以看到,本文方法依然有效。另一方面稠密网络通过更深的网络结构以及密集连接处理,缓解梯度消失问题,加强了特征传播和复用,提升了诊断性能。

表6 不同数据增强方法准确率统计
由以上结果可以看到,本文提出的数据增强方法不仅能够有效增加样本量,并且通过有效信息的提取、学习及迁移,在目标域和源域之间寻找到内在联系,使得不同轴承故障的本质特征得以有效传递,生成的样本更加有利于深度网络的学习。
6 结 论
针对实际轴承故障诊断中,有效的故障样本稀缺产生的小样本故障识别问题,本文提出基于压缩感知学习字典迁移的数据增强算法。该方法通过优化小波包的字典学习方法获取源域字典,并结合少量的真实目标域进行迁移构建目标域迁移字典,最终在目标域生成大量新样本,完成小样本下目标域信号的数据增强。采用常用的深度诊断网络测试结果表明,在不同深度的诊断网络上都获得了较好的性能。与常用的数据增强方法相比,本文方法从新的视角关注对深度故障特征的挖掘和逆向迁移重构,生成的数据时域虽有差异但都含有轴承故障的特定信息,从而改善了生成样本的多样性,为解决小样本故障诊断问题提出新的思路,有一定的理论研究和实际应用价值。
猜你喜欢
计算机技术与发展(2024年3期)2024-03-25
家教世界(2023年28期)2023-11-14
家教世界(2023年25期)2023-10-09
计算机技术与发展(2020年11期)2020-12-04
创新作文(小学版)(2016年19期)2016-08-22
读者(2016年14期)2016-06-29
重庆工商大学学报(自然科学版)(2015年10期)2015-12-28
电子与信息学报(2015年12期)2015-08-17
振动、测试与诊断(2014年5期)2014-03-01
机械与电子(2014年1期)2014-02-28
