
融合RepVGG的YOLOv5交通标志识别算法
2024-05-10 03:37郭华玲刘佳帅郑宾殷云华赵棣宇
科学技术与工程 2024年9期
郭华玲, 刘佳帅, 郑宾, 殷云华, 赵棣宇
(1.中北大学电气与控制工程学院, 太原 030051; 2.瞬态冲击技术重点实验室, 北京 102202)
近些年,伴随着自动驾驶与高级驾驶辅助系统的蓬勃发展,交通场景的目标精确检测也成为其中的重要一环。其中,交通标志作为交通运输系统中不可或缺的组件之一,其为驾驶者或行人提供了丰富的道路状况以及实时的交通条件,提供了利于自动驾驶的指导性或提示信息[1]。目前,交通标志的检测算法可分为传统的交通标志检测算法和基于深度学习的交通标志检测算法。传统检测算法的核心是特征的提取与分类。基于交通标志的色彩与形状,结合特征提取方法对其进行提取,利用分类器来识别交通标志。孙晓艳等[2]采用自适应伽马变换的颜色增强方式,采用最大稳定极值区域提取感兴趣区域(region of interest,ROI),并基于方向梯度直方图,利用支持向量机完成交通标志识别,提高了分类精确度,但误检率过高。Xiao等[3]融合定向梯度直方图(histograms of oriented gradients,HOG)与布尔卷积神经网络(Boolean convolutional neural network,BCNN),针对德国交通标志检测数据库(German traffic sign detection benchmark,GTSDB)[4]进行交通标志识别,取得了不错的效果,但识别速度无法满足实时需求。韩伟等[5]提出基于极坐标分区的局部二值模式特征提取法,实现交通标志的识别。传统交通标志的检测算法虽在不断的改进中提升了检测性能,但传统交通标志检测算法仍存在计算复杂、泛化性差、操作烦琐等问题。
随着图形处理器(graphics processing unit,GPU)性能与芯片工艺的提升以及大数据的不断发展,基于深度学习的检测开始在目标检测领域崭露头角。依照检测步骤可将深度学习的目标检测算法分为两个类别,一类是以Fast-RCNN(fast regions with convolutional neural network features)[6]、Mask-RCNN(mask region-based convolutional neural network)[7]为代表的two-stage法,该类算法通常先产生候选框,随后进行分类与定位。另一类算法则是以YOLO(you only look once)[8]与SSD(single shot multibox detector)[9]为代表的one-stage法,该类算法无需进行候选框的产生,直接进行物体类别的分类与定位。在交通标志的识别中,郭璠等[10]基于YOLOv3算法并融入通道注意力和空间注意力机制,使得小目标的检测性能得以提升。但训练得到的模型较大,不适合用于实际的项目中。袁小平等[11]使用多种卷积构建多尺度特征提取模块,并设计了轻量混合注意力模块,检测精度得以提高,但检测速度仅49帧/s,实时性较差。林轶等[12]将批量归一化操作与卷积合并,同时引入空间金字塔池化模块和CIoU(complete-IoU)损失函数,在CTSDB数据集上取得很高的检测精度,但对于小目标的检测效果不佳。
综上所述,现选用检测速度更快、检测精度更高、模型占用内存更小的YOLOv5算法。并对其主干特征提取网络与Neck层中的CBS模块进行RepVGG模块的替换,提高模型的特征提取能力的同时提高检测精度。而后将通道注意力模块(channel block attention module,CBAM)融合到Neck层中,提高模型对小目标的鲁棒性,最后使用EIoU(efficient-IoU)损失函数来代替GIoU(generalized-IoU)损失函数,提升模型的迭代速度与检测精度。将模型运用于CCTSDB数据集中,验证改进算法的可行性与实用性。
1 YOLOv5结构
2015年,YOLO算法的提出将目标检测问题划分为了回归问题,YOLO把图片细划为网格,再由网格预测检测目标。而YOLOv2提出Darknet-19,利用锚框提高算法的召回率。2018年,YOLOv3提出Darknet-53网络,强化其检测速度与精度。到了2020年,Bochkovskiy等[13]在YOLOv3的基础上,融合多通道网络(cross-stage partial network,CSPNet)与Darknet-53作为主干特征提取网络,在主干网络末端添加金字塔空间池化结构(spatial pyramid pooling,SPP)来扩大模型的感受野并结合路径聚合网络(path aggregation network,PANet)形成YOLOv4网络。CSPNet可以实现多样的梯度组合,而SPP模块通过4种池化核对特征图进行处理实现更好的特征提取效果。
图1为YOLOv5的结构图。YOLOv5相较于YOLOv4,除了继续在主干网络中沿用C3结构,也在Neck层中添加了C3结构,增强了网络的特征融合能力。

h×w×c表示模块右侧数字为对应特征图的尺寸参数,h、w、c分别对应特征图的高度(high)、宽度(weight)和通道数(channel);k(kernel)为卷积核的尺寸;s(stride)为卷积步幅;p(padding)为填充像素行/列数图1 YOLOv5网络结构Fig.1 YOLOv5 network architecture
综上所述,得益于YOLOv5模型小、训练时间短、推理速度快、更易部署等特点,YOLOv5更加适用于自动驾驶中的交通标志识别。
2 改进YOLOv5算法
2.1 RepVGG模块
RepVGG[14]在VGG网络中引入identity残差分支,利用结构重参数化实现模型在训练阶段与推理阶段的解耦。
RepVGG的训练模块如图2(a)所示,由3×3卷积、1×1卷积、残差结构构成多分支网络。引入的残差结构,可以有效针对梯度消失的情况,促使模型更快收敛。

图2 RepVGG训练模型和推理模型结构Fig.2 RepVGG training model and inference model structure
推理模块如图2(b)所示,由3×3卷积和激活函数ReLU组成的类VGG结构,因结构简单,能够极大加速模型的推理。RepVGG采用重参数化将训练模型转化为推理模型,融合CONV与BN层,将处理后的卷积层都转换成为3×3卷积,最后合并分支中的3×3卷积,叠加所有分支的权重W和偏置b,从而得到最终的3×3卷积进行推理。为了满足交通标志检测模型精度高、速度快的需求,引入RepVGG模块,提高主干网络的特征提取能力,减少特征信息丢失,在提高网络特征取能力的同时兼顾速度。
2.2 CBAM注意力模块
注意力机制可以帮助卷积神经网络将特征的权重从特征图中提取出来,再将权重进行重分配从而抑制无效特征增强有效特征,使得网络能够更好地关注到图像中的重点区域。
如图3所示,CBAM包括通道注意力模块(channel attention module,CAM)与空间注意力模块(spatial attention module,SAM)两部分,特征图经由通道注意力模块,消除空间维度的影响,使网络更专注于关键特征,再经由空间注意力模块,使网络学习到关键特征的具体位置。

图3 CBAM注意力机制Fig.3 CBAM attention mechanism
在CAM中,先对输入特征图进行平均池化和最大池化,消除空间维度的影响,得到两个一维特征。再将两个一维特征输入到两层共享神经网络中,神经元个数分别为c/r和c。然后,将各元素进行相加合并,并通过Sigmoid激活函数进行非线性处理,生成通道注意力特征Mc(F)∈Rc×1×1。最后通过通道注意力特征Mc(F)和输入特征图F进行元素相乘的方式,重新分配通道权重,得到新的通道特征图F′。通道关注度Mc(F)∈Rc×1×1的计算公式为
Mc(F)=σ{MLP[AvgPool(F)]+
MLP[MaxPool(F)]}

(1)
式(1)中:σ为Sigmoid函数。
空间注意力模块将通道特征图F′作为输入,为了加强对待检测目标的关键区域的关注,依次对通道特征图F′进行基于通道的全局最大池化和全局平均池化,从而得到两个特征图。再合并两个特征图的通道数,获得尺寸为2×h×w的空间特征图。之后利用7×7的卷积核与Sigmoid函数对其进行卷积与非线性处理,得到特征图的空间关注度Ms(F)∈RH×W,最后将经由通道注意力模块所得的特征图F′与空间注意度Ms(F)∈RH×W逐元素相乘得到最终特征图F″。此时网络不仅学习到了该特征包含什么关键特征,还学习到了关键特征所在位置。空间关注度Ms(F)∈RH×W的计算公式为
Ms(F)=σ(f7×7{[AvgPool(F);MaxPool(F)]})

(2)
式(2)中:f7×7为7×7的卷积核。
2.3 损失函数的改进
选择合适的损失函数有利于获得针对该数据集表现优异的模型,并且在训练过程中达到更快收敛[15]。
YOLOv5使用GIoU损失函数,引入预测框与真实框的最小外接矩形。GIoU损失函数为
(3)
式(3)中:A为预测框的面积;B为真实框的面积;C为A,B的最小外接矩形的面积。引入最小外接矩形,即使A,B不相交仍可以实现梯度下降。但其也存在一定的缺陷。如图4所示,当A,B为包含状态时,此时GIoU损失函数便无法确定两个框的位置关系。
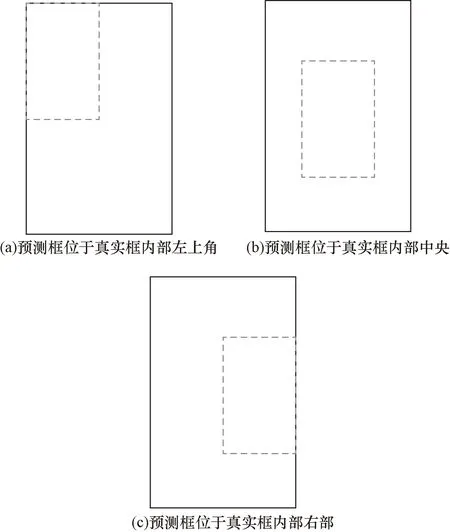
图4 预测框与真实框互为包含Fig.4 The prediction box and the real box are mutually inclusive
为了解决这一问题,CIoU[16]损失函数通过增加多种判别因素,使真实框的拟合更加趋向平稳。为CIoU损失函数表达式为
(4)
式(4)中:ρ2(A,B)为预测框与真实框中心的欧式距离;c为两框的最小闭包区域的对角线长度;α为平衡比例的参数;v用于判断预测框与真实框的长宽比统一性;Aw、Ah、Bw、Bh为预测框与真实框的宽高。但CIoU损失函数未考虑长宽边长真实差,纵横比描述的是相对值,存在一定的模糊。
故采用EIoU[17]损失函数来替代CIoU损失函数。EIoU损失函数表达式为


(5)
式(5)中:b和bgt为预测框与真实框的中心点;ρ为两点的欧式距离;d为两框的最小外接矩形的对角线长;ω、ωgt、h、hgt分别为预测框与真实框的宽度与长度;cω、ch分别为覆盖两个框的最小外接矩形的宽度和长度。
EIoU损失函数不仅考虑了预测框与真实框的重叠面积、中心点距离以及长宽边长真实差,相较于CIoU损失函数还对纵横比的模糊定义提出了解决方法,能有效帮助模型更好地收敛,从而获得更加出色的模型。
2.4 改进YOLOv5的结构
改进后的YOLOv5结构如图5所示,将主干特征提取网络中的CBS模块替换为RepVGG模块,加强主干网络的特征提取能力。在Neck层将CBS模块替换为RepVGG模块,并在图像特征提取前融合CBAM注意力机制,提升网络对于特定目标区域的感知能力,从而实现更高的目标检测精度。最后在网络训练过程中使用EIoU损失函数,通过引入目标框长度、宽度,解决了GIoU、CIoU损失函数在水平和垂直方向上误差较大的问题。

图5 改进YOLOv5网络结构Fig.5 Improving YOLOv5 network structure
3 实验及结果分析
3.1 数据集准备
数据集采用由长沙理工大学制作的CCTSDB[18]交通标志数据集,其为当前中国交通标志公认的数据集之一。从中选取10 000张图片,该数据集标注的数据共分为指示、禁止、警告3种类型。将标注信息通过程序转换为TXT格式,按照9∶1的比例将数据划分为训练集与测试集。训练时,采用Mosaic数据增强,将4张图片拼接为一张图像,加强图像的多样性,降低GPU资源的消耗。
3.2 训练环境与评测标准
实验在Windows 10系统下进行,实验设备为Intel i7CPU,显卡为GTX3090,24 G显存。使用Pytorch1.12,CUDA版本为11.3,使用Python语言进行代码编写。
目标检测的重要性能评价指标为准确率(precision,P)、平均准确率(mean average precision,mAP)、召回率(recall,R),公式如下。
(6)
(7)
(8)
式中:TP为真正例,即样本自身的真实标签为A,而预测的标签也为A;FP为假正例,即样本自身的真实标签为B,但预测的标签却为A;FN为假负例,即样本本身的真实标签为A,但预测的标签为B;AP为所有类别的平均准确率均值;N为类别数。
3.3 实验结果与分析
选择部分从校园以及街道所采集到的图像对改进算法与YOLOv5算法进行对比测试。图6所示为改进算法与原算法的检测结果对比。
由图6可知,原始YOLOv5在照片相对比较模糊且交通标志比较小的情况下会出现检测缺失,第二张图无法检测出禁止标志的现象。而改进算法针对第一张图像的交通标志检测置信度更高,且成功识别第二张模糊图像中的小目标。
图7所示为改进算法与YOLOv5、YOLOv4的评测标准对比,可以看出,在训练初期改进算法与YOLOv5算法相较于YOLOv4来讲收敛更快,而在迭代10次以后,可以明显看到改进算法在各项指标都超越了另外两种算法,在迭代39次时基本各项数据达到最优,后续的迭代评价指标也基本维持在最优值仅有小幅度波动。

图7 评测标准对比Fig.7 Comparison of evaluation standards
各算法的最优性能指标如表1所示。可以看到,改进的算法相比较于原始YOLOv5在准确率上提高了4.99%,达到91.55%,召回率提高了3.62%达到85.04%。mAP提高了1.73%,达到了91.71%。
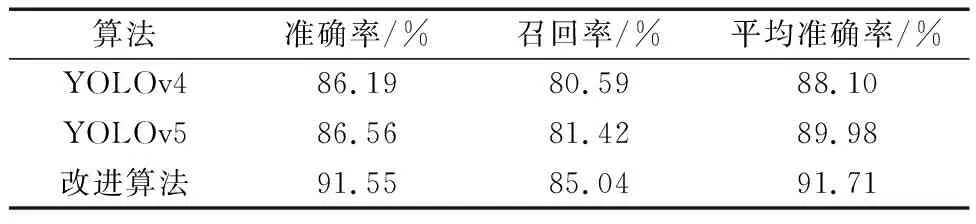
表1 改进算法与其他算法的性能对比Table 1 Comparison of performance between improved algorithms and other algorithms
4 结论
针对传统交通标志检测算法所存在的精度较低的问题,提出一种融合RepVGG的改进YOLOv5算法。通过更替主干特征提取网络中CBS模块为RepVGG模块,在Neck层融合CBAM注意力机制、RepVGG模块。改进后的YOLOv5得益于重参数化后的RepVGG模块,算法在CCTSDB数据集的检测精度、检测速度得以优化,适宜应用在实践中。所以改进算法在自动驾驶交通标志识别方面有着较高的应用价值。但CCTSDB的交通标志类型过少,面对复杂多样的交通路况与标志并不能精确检测其具体含义,接下来会使用分类更为多样与精确的TT100K数据集来对算法进行验证,实现更加有指导意义的交通标志检测。
猜你喜欢
东方少年·布老虎画刊(2023年12期)2024-01-01
汽车实用技术(2022年9期)2022-05-20
小雪花·成长指南(2022年1期)2022-04-09
电子制作(2018年19期)2018-11-14
传媒评论(2017年3期)2017-06-13
自动化学报(2017年11期)2017-04-04
第二课堂(课外活动版)(2016年2期)2016-10-21
小天使·一年级语数英综合(2016年8期)2016-05-14
噪声与振动控制(2015年4期)2015-01-01
小天使·一年级语数英综合(2014年7期)2014-06-26
