
结合多源专题数据和目视解译的大区域密集湿地样本数据生产
2024-03-20 01:08彭凯锋蒋卫国侯鹏凌子燕牛振国毛德华黄卓
遥感学报 2024年2期
彭凯锋,蒋卫国,侯鹏,凌子燕,4,牛振国,毛德华,黄卓
1.北京师范大学 地理科学学部 遥感科学国家重点实验室,北京 100875;
2.天津师范大学 地理与环境科学学院,天津 300387;
3.生态环境部 卫星环境应用中心,北京 100094;
4.南宁师范大学 地理科学与规划学院,南宁 530001;
5.中学院空天信息创新研究院,北京 100094;
6.中国科学国科院东北地理与农业生态研究所 湿地生态与环境重点实验室,长春 130102
1 引言
基于遥感卫星的地表覆被制图是开展陆表景观变化和生态资源调查的重要技术手段,具有成本低、效率高、覆盖范围大等优势(刘涵和宫鹏,2021)。目前,已有大量学者利用遥感卫星数据开展了水体制图(Pekel等,2016;Deng等,2019;Pickens等,2020)、农田制图(薛冰 等,2019;Zhang等,2020)、森林制图(Hansen等,2013;颜伟 等,2019)、土地利用制图(Li等,2017;Calderón-Loor等,2021)等研究。根据人工干预的程度,遥感制图方法大致分为人工解译法、监督分类法、自动分类法等,其中监督分类方法的分类精度好、制图效率高,应用最为广泛,但该方法需要一定数量的样本数据训练分类器。无论采用何种方法,均需要样本数据对制图结果进行验证,以确保制图成果能够满足生产应用和科学研究要求(Huang等,2020)。因此,精确、高质量的样本数据生产是开展地表覆被制图的基础工作之一。
现阶段,样本数据生产方法大致包括野外实测、无人机调研、高分影像解译和自动生产等方法。野外实测法是指利用野外测量设备(譬如GPS、手持PAD测量仪),到实地进行勘察,在一定大小的样方内确定主导土地覆被类型,记录该地类的地理坐标。该方法大多应用于区域尺度的中、高分影像制图研究(陈劲松 等,2014;Jia 等,2020)。无人机调研法是指利用低空无人机设备对指定区域进行航空摄影,使用布设的地面控制点对获取图像进行几何校正,通过对其进行目视判读获取样本点。随着无人机设备的技术进步和应用普及,越来越多的研究和生产部门使用无人机进行样本数据生产(田富有 等,2019;Sun 等,2021)。高分影像解译是指利用米级或亚米级的高空间分辨率遥感影像,譬如GF-2 影像(Wu 等,2021)、Google Earth 的高分影像(张磊 等,2019)等,通过目视解译生产样本点。该方法大多用于中等空间分辨率的遥感制图研究(何昭欣 等,2019;Xu等,2019)。自动生产法是指基于已有的制图数据集,使用一系列的约束条件筛选稳定、高质量的样本点。譬如,Xie等(2019)使用MCD12Q1 的土地利用数据生产样本点,开展全球30 m 的土地利用制图。Gong等(2019)基于30 m的土地利用数据样本点,对Sentinel-2 影像开展10 m分辨率的全球土地利用制图。
湿地生态系统是位于水陆过渡区的生态系统,其丰富的生态系统服务功能和物质生产力对于人类福祉和生产生活具有重要作用(彭凯锋 等,2019)。为此,基于遥感影像的湿地制图成为了当前生态资源管理与保护以及科学研究的热点之一,其中样本数据生产是其制图研究和精度验证的必备基础工作之一。湿地生态系统空间分布较为分散,且大都位于偏远、泥泞的地区(Mahdavi等,2018),野外实测或无人机调研的样本生产成本较高、效率较低,难以满足大尺度的湿地遥感制图研究需求。湿地的类型多样,光谱特征复杂(王鹏 等,2017),基于高分影像解译方法难以辨识具有相似光谱和纹理特征的湿地类型,譬如某些草本沼泽和木本沼泽、草本沼泽和洪泛湿地等类型。此外,由于湿地生态系统的复杂性,湿地的定义及其子类型的分类系统尚未形成统一的标准,且现阶段大区域尺度、精细化类别的湿地产品数据较为缺乏(Hu 等,2017;Xu 等,2020),基于自动生产法的湿地样本生产难以满足湿地精细化制图的需求。因此,耦合多种样本生产方法,构建一种准确、高效的湿地样本生产方法,对于开展大区域尺度、精细化类别的湿地遥感制图研究具有重要意义。
目前,已有很多学者针对某一湿地类别生产了一系列湿地专题数据集,譬如水体数据集(Pekel等,2016;Han 和Niu,2020)、潮间带数据(Murray等,2019)、红树林数据集(Giri等,2011)等,这些数据能够辅助大区域湿地样本生产,极大减少工作量。同时,随着长时序遥感数据集的积累和Google Earth Engine 大数据云平台的普及,为样本数据生产提供了良好的数据基础和工具平台。在此背景下,考虑某些湿地类别的易混淆性和湿地专题数据的局限性,本研究基于多平台和多源湿地类型数据,提出一种结合专题数据和目视解译的大区域密集湿地样本生产技术框架,以期为开展大尺度湿地遥感制图提供样本数据基础。
2 研究区域与数据
2.1 研究区概况
本文将地理范围为44.04°E—138.25°E、7.44°S—60.0°N 的区域定义为研究区,覆盖亚洲的北部、中部和南部区域。根据GLWD(Global Lake and Wetland Database)湿地数据的初步统计(Lehner和Döll,2004),研究区湿地资源丰富,包含湖泊、河流、水库、沼泽地等多种湿地类型,总面积为149.24 万km2。该地区经济发展相对落后,当地政府和人们为了获得更多的经济利益,过度开发和使用湿地资源,加之内陆干旱区的湿地受气候变化的影响明显,研究区的湿地退化严重。因此,开展该区域的湿地研究对于全球自然资源保护和可持续发展目标的实现具有重要意义。
2.2 数据收集
为了直接生产和辅助生产湿地样本数据,本研究收集了全湿地类型数据、单一湿地类型数据、土地利用数据及其其他辅助数据等,各数据名称及其介绍如表1所示。JRC-GWS数据、GMW(Global Mangrove Watch)数据、Global Intertidal Change 数据为单一湿地类型数据,其中JRC-GWS 为全球水体数据,错分误差和漏分误差分别小于1%和5%(Pekel 等,2016)。使用1984 年—2019 年的JRCGWS 积水频率产品,能够可靠的筛选水体样本点和非水体湿地样本点。GMW 为全球红树林数据集,总体精度为94%,本研究选择2007年—2016年间共有5 个时相的GMW 产品数据(Bunting 等,2018),将多时相的GMW 数据进行空间相交,选择稳定的红树林区域生产红树林样点。Global Intertidal Change 为全球滨海滩涂数据,总体精度在82%以上(Murray 等,2019),用于生产滨海滩涂样本点。由于滨海滩涂数据将内陆区的部分地物,错分为了滨海滩涂,因此,本研究的滩涂样本点生产仅限于滨海区。
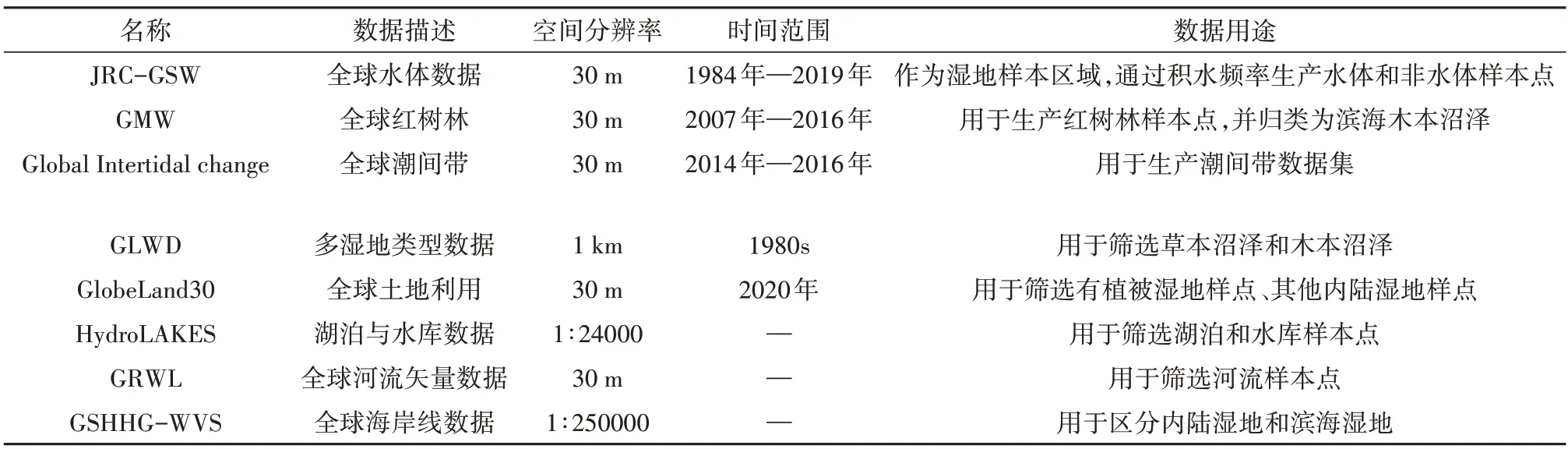
表1 湿地数据及其他辅助数据的列表Table 1 List of wetland datasets and other corresponding auxiliary datasets
GLWD为全湿地类型数据(Lehner 和Döll,2004),该数据的精度和空间分辨率较粗,主要用于辅助目视解译。GlobeLand30 为土地利用数据,2020年的数据总体精度为85.72%(Jun等,2014)。该数据包含了湿地图层,主要用于筛选有植被湿地和其他内陆湿地样本点。HydroLAKES 是全球湖泊与水库矢量数据,该数据是耦合多源专题数据和遥感解译产品,生产了湖泊数据集,包含了10 ha以上的湖泊、水库和其他湖泊类型等(Messager等,2016),可用于生产湖泊样本和水库样本。GRWL(Global River Widths from Landsat Database)是基于Landsat 影像生产的河网数据集,记录了河流中心线及其宽度(Allen 和Pavelsky,2018),可用于筛选河流样本点。GSHHG-WVS 为全球海岸线数据集(Wessel和Smith,1996),可用于区分滨海湿地样本和内陆湿地样本。
3 研究方法与基础
3.1 研究方法
本文探究国家或大洲尺度的全湿地类型样本点生产技术方法,基于已有的湿地专题数据集、土地利用数据集等,并使用GEE(Google Earth Engine)、Google Earth 和Collect Earth 等平台工具,提出一种结合多源数据和目视解译的大尺度密集湿地样本生产方法,总体思路如图1 所示。首先,使用专题数据生产初始湿地样本点,即使用全球JRC 水体数据生产水体样本点和非水湿地体样本点,使用全球滩涂数据和GMW 红树林数据分别生产滨海滩涂样本点和红树林样本点。其次,基于湿地专题数据和GEE 平台统计的样本点NDVI 序列,筛选潜在其他内陆湿地样本和有植被湿地样本。再次,基于HydroLAKES 和GRWL 河流数据等筛选水体样本点,生产河流、湖泊、水库、内陆水体和滨海水体。最后,基于Google Earth 和Collect Earth 平台对未确认属性的样本点进行人工目视解译。
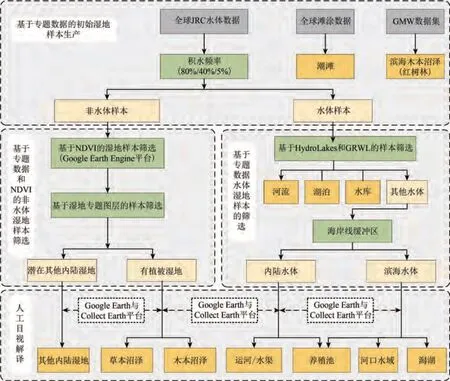
图1 湿地样本数据生产的技术流程图Fig.1 The flowchart of wetland samples production
考虑研究区范围大,通常的湿地分类研究采用分块迭代的方式开展。本研究按5°×5°格网将研究区分为102个单元,设计每个单元的样本数约为1500 个,共需要生成约15 万个湿地类型样本点。对于水体样本点,本研究使用80%积水频率筛选1984 年—2019 年稳定水体样点,这些水体样点在2020 年大都保持属性不变。对于非水体样本点,大都使用Google Earth 平台中2020 年附近的高分影像解译。对于滨海滩涂样点,使用2014年—2016年的数据集近似表征2020 年的滨海滩涂样点。对于红树林样本点,使用1996 年、2007 年、2008 年、2008 年、2010 年、2015 年、2016 年的数据集进行相交,选择稳定的红树林区域作为样点区,因此红树林样本点时相也可以为2020 年。综上所述,本研究生产的全湿地类型样本点的时相为2020年,生成的样本点为稳定、高质量的样本点,可用于开展中等空间分辨率(10—30 m)的湿地制图研究。
3.2 湿地分类体系
由于湿地群落的复杂性和季节变化特征,湿地分类系统及其类型定义尚未形成统一的规范。为了使得生产的湿地数据具有较高的一致性,相关学者积极开展标准湿地分类体系的研究,譬如CLC(CORINE Land Cover)分类系统、LCCS FAO(FAO Land Cover Classification System)、MAES(Mapping and Assessment of Ecosystem Service classification system)、基于LCCS的湿地分类系统等(Finlayson,2018;Weise 等,2020;Xu 等,2020)。本研究考虑湿地类型在遥感影像的可分性和湿地资源管理的需求,采用Mao等(2020)提出的湿地分类体系。同时,考虑其他内陆湿地(譬如河漫滩、藓类湿地、河心洲等)的重要性以及与其他湿地类型的可分性,本研究将该类型加入湿地分类体系中。本研究的湿地分类体系如表2所示。
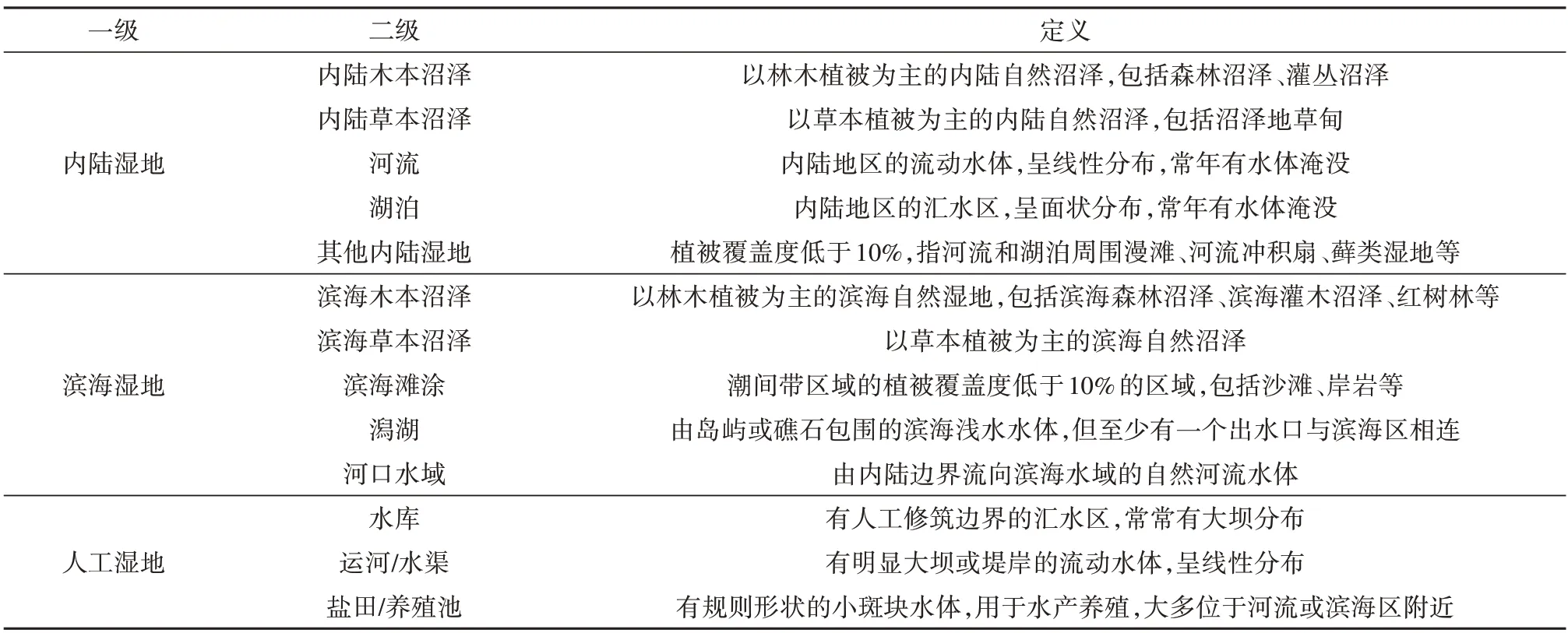
表2 湿地分类体系及其类型定义Table 2 Wetland classification system and its sub-type definition
3.3 工具平台介绍
本研究使用GEE(Google Earth Engine)云平台辅助湿地样本数据生产。GEE 是由美国谷歌公司开发的遥感大数据平台,不仅存储了Landsat、MODIS、Sentinel 等遥感影像以及其他地理空间数据,同时也具有强大的数据分析和计算能力。本研究基于GEE 平台,统计样本点在MOD13Q1 的NDVI时间序列影像的像元值,时间范围为2001年—2020 年,每个样本点对应457 个NDVI 值。分析样本点的NDVI 时间序列变化,可以可靠的筛选出有植被湿地和潜在其他内陆湿地。
本研究使用Google Earth和Collect Earth软件开展样本点目视解译工作。Google Earth 软件是开展样本数据生产的常用工具平台,可以为用户提供高、中、低等多种分辨率影像,但该平台样本管理功能不够友好。为此,联合国粮农组织(FAO)开发了Collect Earth 软件,可以方便的对样本数据进行管理和分析,同时该软件能够轻松访问Bing Maps、Google Earth Engine 的影像,获取每个样本点的空间信息和时间序列信息。结合Google Earth和Collect Earth 平台的样本采集,能够提升样本生产的精度与效率。生产过程示意图如图2所示。
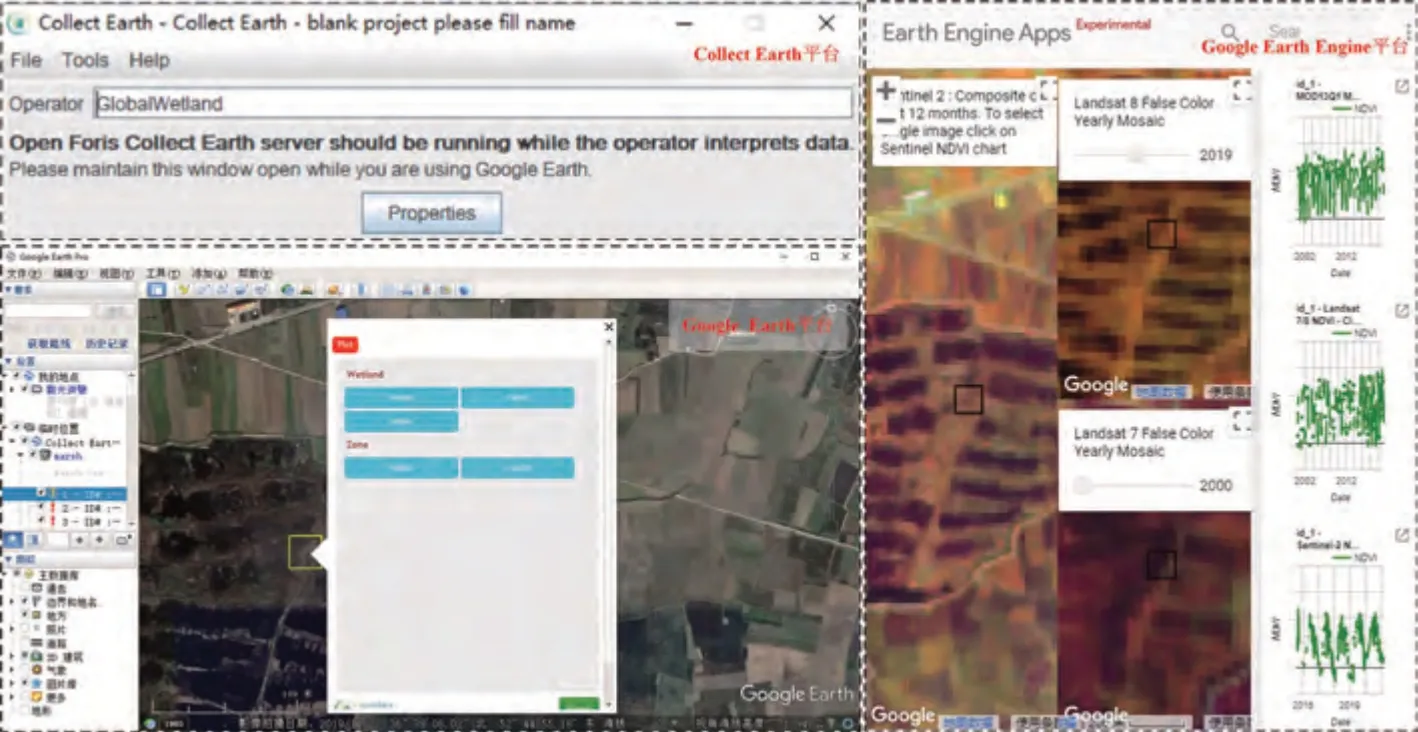
图2 结合Google Earth和Collect Earth平台的样本采集示意图Fig.2 Sample collection diagram combining Google Earth and Collect Earth software
4 样本生产过程与结果
4.1 水体类型的湿地样本数据生产
分析湿地类型的定义发现,河流、湖泊、水库、河口水域、潟湖、运河/水渠、人工养殖池等均属于水体类型。本小节基于JRC水体数据、HydroLAKES数据、GRWL 数据和GSHHG-WVS 数据,通过规则筛选和目视解译的方式生产水体类型样本点。
首先,基于JRC 水体数据生产水体样本点:将JRC 积水频率大于80%的区域作为稳定水体区域,并在此区域内生成随机点,样本之间的最小采样距离为300 m,共生成了124839 个水体样本点,如图3(a)所示。其次,基于HydroLAKES 数据生产湖泊、水库样本点,该数据包含了10 ha 以上湖泊、水库和其他湖泊类型。将80%的积水频率边界与HydroLAKES 数据的湖泊和水库图层进行相交,从而筛选出湖泊和水库的稳定水体边界。由于湖泊图层包含了自然湖泊和小面积的水库/坑塘,本文将该图层面积小于500 ha的斑块删除,仅保留大面积湖泊。使用该数据,能够生成湖泊样本点和水库样本点,共生产湖泊样本点59090 个、水库样本点14854 个,如图3(b)所示。然后,使用GRWL 河网数据生产河流样本点。将GRWL的河流中线数据与80%积水频率边界进行相交,筛选河流边界,同时参照水库数据,剔除河流中的水库边界。使用该数据筛选水体样本,共生成河流样本25503个,如图3(c)所示。再次,使用GSHHG-WVS 海岸线数据建立15 km 缓冲区,使用该矢量数据对剩余样本点进行分类,生成内陆水体样本点16230 个,滨海水体样本点9192 个,如图3(d)所示。最后,使用Google Earth 和Collect Earth 软件,对滨海水体进行目视解译,生产河口水域、潟湖、盐田/养殖池的样本;对内陆水体进行目视解译,生产养殖池、运河/水渠样本。河口水域是位于滨海区的河流水体,与浅海水域相连;潟湖是位于滨海区的湖泊,呈面状分布,至少有一个出水口与滨海水体相连;盐田/养殖池形状规则,面积较小,大都位于河流和滨海区附近;运河/水渠呈线性分布,宽度较窄,大都有修筑的人工护岸设施。
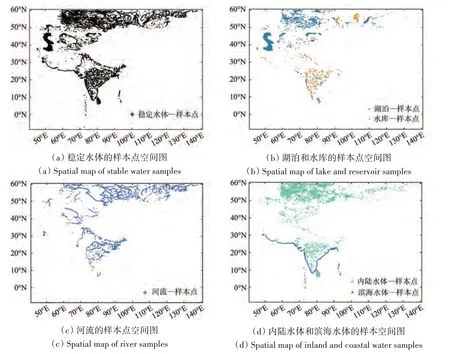
图3 水体类型的湿地样本点空间图Fig.3 Spatial maps of wetland samples of water types
4.2 其他内陆湿地的样本数据生产
其他内陆湿地是指植被覆盖度低于10%的区域,通常为河流和湖泊周围漫滩、河流冲积扇、藓类湿地等。考虑其他内陆湿地的植被特征和地理特征,本小节使用JRC 水体数据、3.1 小节的河流与湖泊边界数据、GlobeLand30 数据以及GEE 平台统计的NDVI 时间序列,并结合目视解译的方式,生产其他内陆湿地样本点。首先,使用JRC数据生产种子样本点:将积水频率为5%—40%之间的区域作为潜在非水体湿地区,以最小间隔距离为300 m 生产种子样本点。其次,基于NDVI 时间序列筛选潜在其他内陆湿地样本点:考虑其他内陆湿地的低植被特征以及其NDVI 数值的异常波动,将满足“NDVI>0.12 的次数大于200 或NDVI>0.2 的次数大于100”样本点剔除,剩余点为潜在其他内陆湿地样本点,共计13747个。再次,使用GlobeLand30 数据筛选其他潜在内陆湿地样本点:该数据的湿地图层包含了洪泛湿地、草本沼泽、木本沼泽等类型,使用该图层与潜在其他内陆湿地样本点相交,进一步筛选潜在其他内陆湿地样本点。然后,使用河流和湖泊最大水体边界对潜在其他潜在内陆湿地样本点进行筛选,从而得到河流与湖泊周边的潜在其他湿地样本点。经过以上过程,并删除滨海区的潜在其他内陆湿地点,生产了9884个潜在其他内陆湿地样本点,如图4(a)所示。最后,通过目视解译的方式,对筛选的潜在其他内陆湿地进行解译,确认为其他内陆湿地样本点共8410 个。目视解译过程中,对稀疏样点区或典型区也进行样本增选,共876个。最终的样本点如图4(b)所示。
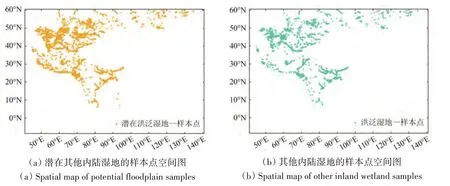
图4 潜在其他内陆湿地和其他湿地的样本点空间图Fig.4 Spatial maps of potential other inland wetland samples and potential other inland wetland samples
4.3 有植被湿地的样本数据生产
分析湿地分类体系可知,有植被湿地包括内陆/滨海草本沼泽、内陆/滨海木本沼泽,这些湿地类型大多是由季节性水体淹没的植被。本小结探究结合湿地专题数据和人工目视解译的方式生产有植被湿地样本。首先,基于JRC 数据生产潜在种子样本点:在积水频率为5%—40%的区域生成样本点,样本点的最小间隔为300 m。其次,基于NDVI 时间序列筛选潜在有植被湿地样本点:将样本点的NDVI>0.2 次数超过200 次的样本点,作为潜在湿地样本点,共计34145个,如图5(a)所示。再次,使用GlobeLand30 数据进一步筛选有植被湿地样本点。根据GlobeLand30的湿地图层定义,该图层包含沼泽地、红树林、森林/灌丛湿地等。本研究使用该数据对潜在有植被湿地进行筛选,生成有植被湿地样本点,共计8164个,如图5(b)。
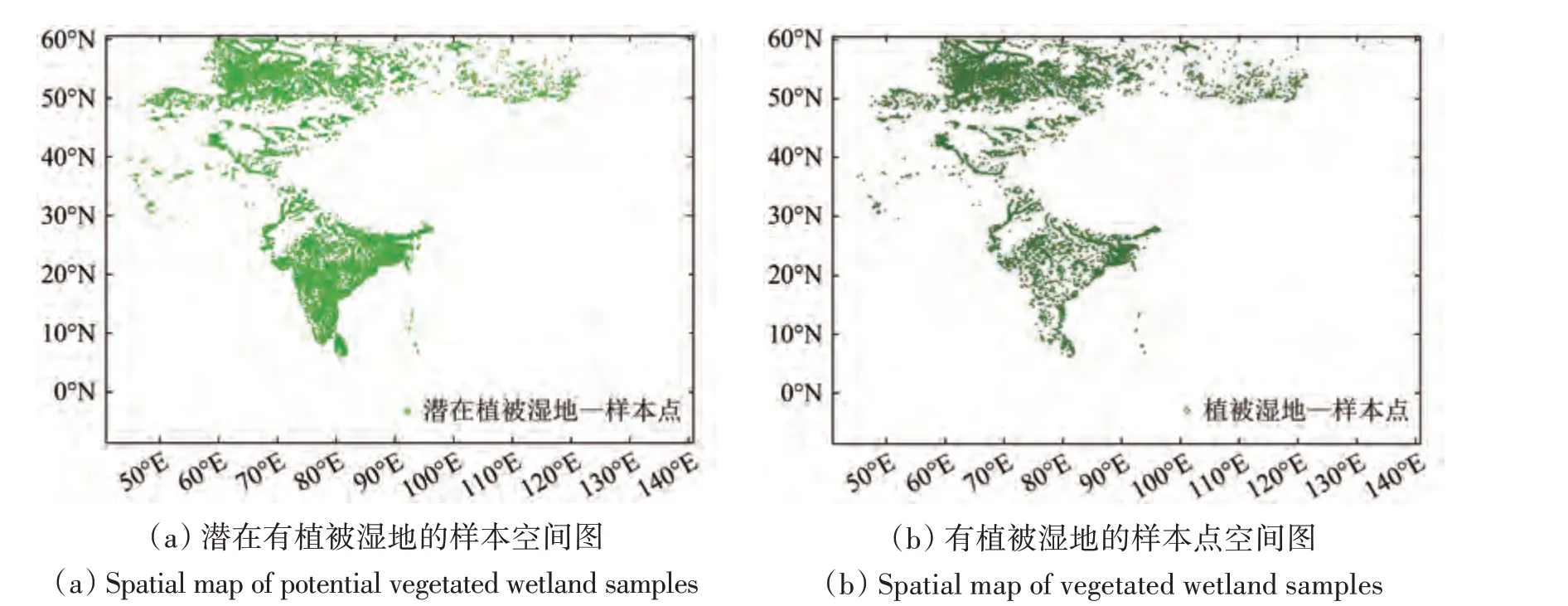
图5 潜在有植被湿地和有植被湿地的样本空间图Fig.5 Spatial maps of potential vegetated wetland samples and vegetated wetland samples
将以上有植被湿地样本点导入Collect Earth 平台中,进行目视解译判读木本沼泽和草本沼泽。由于部分草本沼泽和木本沼泽具有相似光谱特征和NDVI 时间序列特征,本研究将有植被湿地样点分两部分进行解译。首先,使用GLWD 的“淡水草本沼泽/洪泛湿地”图层对有植被湿地进行筛选,选择的样本点大都为草本沼泽类型,导入到Collect Earth 平台进行目视解译。这种方式解译,能够对草本沼泽和木本沼泽提供先期认知。其次,将剩余有植被湿地样点导入到Collect Earth 平台,进行目视解译。
通过有植被湿地的样本解译,总结了草本沼泽和木本沼泽的颜色、纹理和NDVI 时间序列特征。对于草本沼泽:(1)颜色:生长季为青绿色、浅青色;非生长季为灰色、红褐色;(2)纹理:纹理较为匀质;(3)NDVI 时间序列特征:NDVI数值在0—0.5 间周期变化,但部分草本沼泽样本点的NDVI 在0—0.8 间周期变化。草本沼泽的高分影像、NDVI 变化图与实景照片如图6(a)所示。对于木本沼泽:(1)颜色在生长季为绿色、青绿色;非生长季为褐色、红褐色;(2)纹理:纹理粗糙,有颗粒状;(3)NDVI时间序列特征:NDVI数值在0—0.8 之间震荡。木本沼泽的高分影像、NDVI变化图与实景照片如图6(b)所示。

图6 草本沼泽和木本沼泽的样本示意图Fig.6 The diagram of marsh sample and swamp sample
基于以上过程,完成对草本沼泽和木本沼泽的目视解译。同时对稀疏样点区或典型湿地区,在Google Earth 平台经进行样本增选,并使用海岸线缓冲区进行区分内陆和滨海的湿地类型。共生产内陆草本沼泽16747个,内陆木本沼泽10786个,滨海草本沼泽701 个,滨海木本沼泽378 个,如图7(a)所示。此外,本研究使用GMW红树林数据生产红树林样本点。为了保证样本的准确性和稳定性,本研究使用2007年、2008年、2010年、2015年、2016 年的5 个时相数据生产样本点。将这些数据进行空间相交,在公共相交区域内生成红树林样本点,共生成红树林样本点5000 个,如图7(b)所示。将生产的红树林样本点归为滨海木本沼泽。
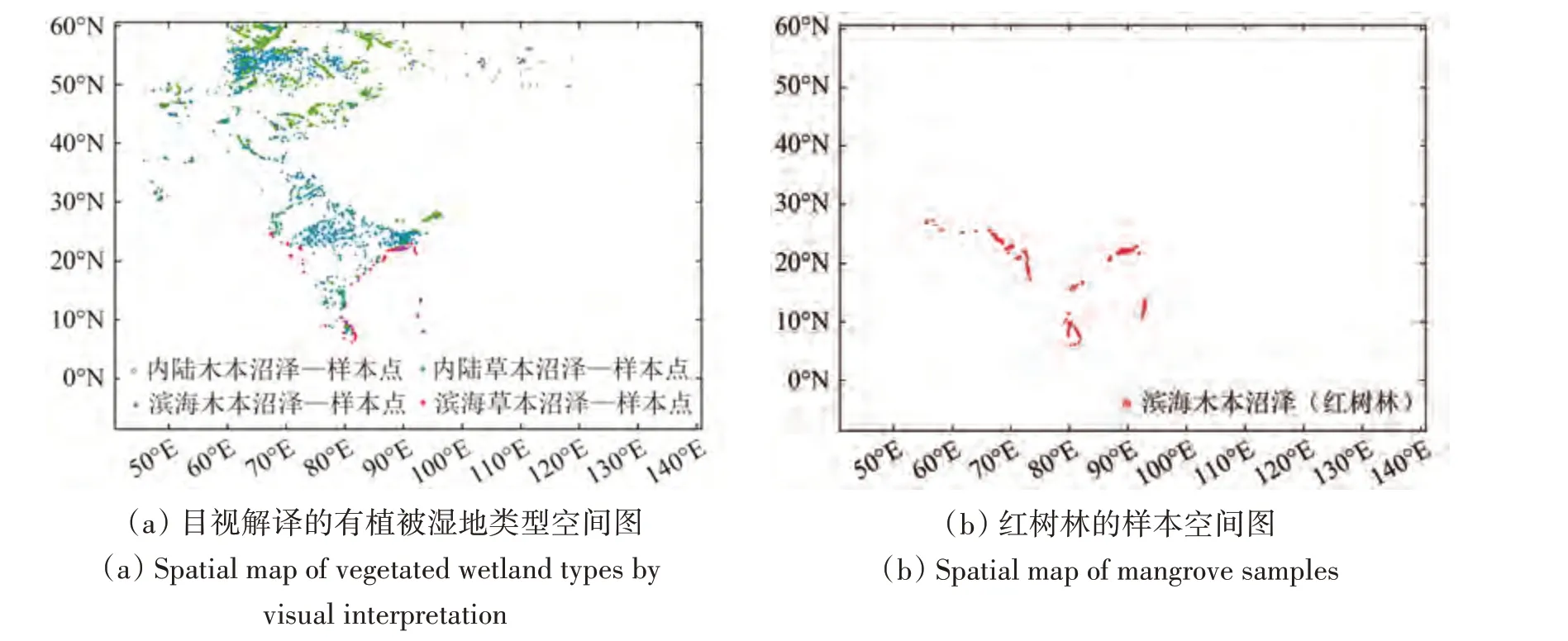
图7 有植被湿地类型的样本空间图Fig.7 Spatial map of vegetated wetland samples
4.4 滩涂的样本数据生产
滩涂是指潮间带地区的植被覆盖度低于10%的区域,包括沙滩、岸岩等。本研究使用Murray等(2019)生产的全球滩涂数据集生产本研究区的滩涂样本点。该数据是基于长序密集的Landsat影像生产的,空间分辨率为30 m,数据的总体精度为82.3%。本研究使用2014 年—2016 年时期的数据产品生产样本点,样本点的最小间隔为300 m,共生产了2500个样本点,如图8所示。
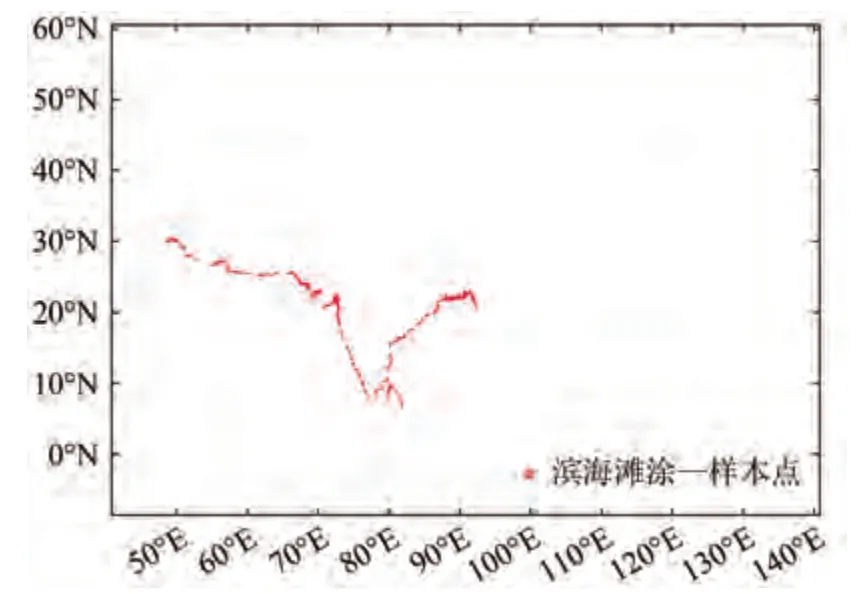
图8 滨海滩涂样本点的空间图Fig.8 Spatial map of coastal tidal flat samples
5 讨论
现阶段,湿地制图研究大多侧重于湿地遥感分类研究,而将湿地样本点生产作为研究基础之一。该研究范式适用于小尺度湿地遥感研究,但对于大尺度的湿地制图研究,如何准确、高效地生产高质量的样本点,是保证其研究结果准确性的核心工作之一。本研究系统梳理了国内外的湿地分类体系,选择了适用于大区域尺度湿地遥感制图的分类系统;然后基于国内外已有的湿地数据、土地利用数据以及其他数据,针对性的提出适用于大尺度的密集湿地样本生产方法。该方法充分利用了已有的数据基础,生产了河流、湖泊、水库、滨海木本沼泽(红树林)、滩涂等多个湿地类型样本,同时筛选了有植被湿地、其他水体类型和其他内陆湿地等样本点,能够在保证样本精度和质量的前提下,极大减少人工目视解译的工作量。本研究可为开展湿地遥感制图的样本生产提供一定的技术参考,对于开展大区域的湿地资源调查具有重要意义。
本研究生产了大洲尺度的全湿地类型样本点,但仍存在有待改进的地方。首先,本研究将基于规则筛选和目视解译的样本点全部作为湿地类型样本点,未考虑湿地类型样本均衡性的问题。未来的湿地分类研究中,可根据算法要求和各湿地类型占比,选择合适比例的湿地子类型样本点。其次,缺少对生产湿地样本的精度验证。尽管本文生产了可靠、稳定的湿地类型样本,但样本生产过程中难免存在误差。在未来的研究中,可选择典型区的样本点进行二次人工目视解译,以验证样本的可靠性和精度。
此外,本研究的湿地样本生产方法也存在一定的不确定性。首先,人工目视解译难以判别某些草本沼泽和木本沼泽,某些草本沼泽表现为高植被特征,纹理和颜色特征与木本沼泽相似,从而导致样本解译中存在一些人工误差。其次,本文仅使用JRC 水体数据来框定大多数湿地类型样本点,未能在水体淹没最大范围以外采集样本点。最后,由于湿地专题数据本身存在一定的数据误差,基于专题数据生产的湿地样本同样存在一定的不确定性。然而,对于大尺度遥感分类研究,其样本点不一定要全部覆盖到所有湿地类别区,只要样本满足均匀分类、数量合理即可。同时,Gong等(2019)的研究表明,样本数量减少至原样本量的60%,其分类精度仅下降1%左右,一定程度的样本生产误差对分类研究的影响是可接受的。综上来看,本文湿地样本生产的技术框架,能够满足大尺度湿地遥感制图的要求,是一种准确、高效的湿地样本生产方法。
6 结论
本研究以多源湿地专题数据为基础,以Google Earth Engine 大数据云平台、Google Earth 和Collect Earth 软件等为工具平台,提出了一种准确、高效的大尺度密集湿地样本生产方法。相比于传统的目视解译方法和自动样本生产方法,本研究的样本方案能够充分利用已有的数据基础,有效避免盲目目视解译导致的工作量大、效率低的问题,能够为大尺度精细化湿地制图提供可靠密集的全湿地类型样本数据。
本文开展了大洲尺度的全湿地类型样本数据生产。研究结果表明:本研究共生产了150668 个湿地样本点,其中内陆湿地样本有121412个,滨海湿地样本有11563 个,人工湿地样本有17693 个。13 个湿地子类型中,湖泊样本数量占比最大(39.22%),潟湖样本数量占比最小(0.19%)。同时,河流、水库、内陆草本沼泽和内陆木本沼泽的样本占比也较大。本研究生产了精度可靠、数量充足的全湿地类型样本点,能够为大洲尺度的湿地制图和精度验证提供可靠的数据基础。
此外,本文的样本生产方法及其样本生产结果仍存在有待改进的地方。首先,本文将规则筛选和目视解译的湿地样本全部作为样本集,未充分考虑湿地类型的样本均衡问题。未来的湿地分类研究中,应根据算法要求和湿地类型占比,选择合适比例和数量的样本点。其次,对于某些区域的草本沼泽和木本沼泽,其相似的颜色和纹理特征导致样本解译存在一些人工粗差。未来的湿地样本解译,可加强对解译人员的训练,以增强其对湿地类型的认知。最后,多源辅助数据本身存在一定的误差,基于其生产的样本点存在一定的不确定性。未来的样本生产,可以通过多期数据叠加生产稳定样本、二次人工目视解译等方式,提高样本点质量与精度。
志 谢感谢清华大学宫鹏教授领导全球湿地制图研究,提供全球湿地制图的科学思想。感谢中国科学院东北地理与农业生态研究所王宗明研究员,对本文的湿地分类体系的确定和湿地专题数据的收集提供的帮助和指导。感谢中国地图出版集团左伟编审对地图制图提供的帮助和指导。
猜你喜欢
少林与太极(2021年1期)2021-06-20
重庆与世界(2019年10期)2019-11-25
健身气功(2019年2期)2019-04-18
天津诗人(2017年2期)2017-11-29
下一代英才(酷炫少年)(2017年9期)2017-11-27
网络文学评论(2017年1期)2017-07-22
中国船检(2017年3期)2017-05-18
剑南文学(2016年11期)2016-08-22
华东经济管理(2015年6期)2015-11-14
河北能源职业技术学院学报(2015年3期)2015-02-27
