
一种融合多尺度混合注意力的建筑物变化检测模型
2024-04-15 09:03于海洋滑志华宋草原谢赛飞
测绘工程 2024年1期
于海洋,滑志华,2,宋草原,谢赛飞,景 鹏
(1.河南理工大学 自然资源部矿山时空信息与生态修复重点实验室,河南 焦作 454003;2.黄河勘测规划设计研究院有限公司,郑州 450000)
遥感变化检测是识别多时相遥感图像之间差异性的过程,在城市管理、灾害评估、土地利用变化检测、环境监测等领域应用广泛[1]。建筑物作为人类活动的主要场所和人工地理目标的代表,其变化检测一直是摄影测量与遥感、人工智能等领域的研究热点[2]。近年来深度学习技术在遥感图像目标识别与分类中得到了推广应用,部分学者开始关注其在遥感图像变化检测中的应用[3-6],并取得了一定的研究成果。
目前变化检测方法大致分为两类:传统方法和基于深度学习方法。传统的遥感图像变化检测主要采用图像差分、比值、变化向量分析(CVA)等方法,叶沅鑫[7]和刘陆洋[8]等分别将邻域信息、结构特征和对数比差异图、均值差异图以及主成分分析应用于变化检测,检测精度有一定的提升。但上述方法部分依赖于手工构建的特征表示,对复杂的高层次变化信息的建模能力有限,并且当变化类和非变化类的特征重叠或其统计分布建模不准确时,检测结果会产生较大误差,具有一定的局限性。近年来,基于深度学习的遥感图像变化检测方法发展较快,与传统方法相比,深度学习方法可以更好地处理高分辨率遥感图像所包含的海量信息。基于深度学习的遥感变化检测主要采用孪生结构、编码-解码结构等方法,如Fang等[9]提出了一种密集连接孪生结构网络SNUNet-CD,该网络通过编码器和解码器之间的密集连接,减轻了神经网络深层定位信息损失的问题。Zheng等[10]提出了一种高频注意力引导孪生网络HFA-Net,该网络主要由两个部分组成,即空间注意力(SA)和高频增强(HF)。虽然该模型较有效地改善建筑物边缘细节问题,但高频注意力模块导致模型参数量增加较大,模型计算量开销增加。Zhu等[11]提出了一种孪生全局学习(Siam GL)框架,利用共享参数的孪生架构提取双时态遥感图像特征;全局分层(G-H)采样机制解决样本不足的不平衡训练样本问题,降低了对数据量的要求,但检测精度有待提高。为了解决建筑物变化检测需要大量由双时相图像及其变化图组成的标记数据的局限性,Sun等[12]提出了一种融合图注意机制的孪生嵌套模型SANet,并采用半监督方式训练模型,该方法显著降低了对大型数据集的依赖性,降低了数据采集处理成本,但模型总体精度仍弱于全监督方法。张翠军[13]针对图像背景复杂的问题,提出了一种在特征提取部分用非对称卷积块来代替标准卷积的建筑物变化检测方法,结果表明F1分数有明显提升。综上所述,深度学习允许基于多个处理层构建的模型学习具有多个抽象级别的数据样本表示,与贝叶斯[14]、支持向量机(SVM)[15]、随机森林[16]和决策树[17]等传统机器学习模型相比,具有更多的学习优势。
目前的变化检测方法除上述的局限性外还往往侧重于深层语义特征的提取,而忽略了像元之间丰富的时空信息,导致成像光照变化及配准误差等极易影响算法精度。文中通过采用一种混合注意力机制,用于捕捉丰富的空间-时间信息,获得光照不变量和配准误差的特征。同时考虑到变化对象具有不同的尺度,为了更好地提取各层级特征,提出构建一种多尺度的混合注意力模块,通过对原始输入图像进行区块划分,并对每块子区域引入混合注意力机制,以获得不同尺度的细节特征,增强模型准确性及鲁棒性。
1 研究方法
1.1 网络模型结构
建筑物变化检测处理流程可以分为3步:①数据预处理,对于获取的原始数据首先需要进行分割,以满足电脑硬件的限制。同时需进行数据增强(翻转、旋转、高斯模糊),以满足模型训练所需的数据量。②训练并优化网络模型,通过梯度更新和反向传播算法优化网络模型。③模型测试,对训练好的模型进行泛化实验,验证模型的有效性。
图1展示了所提出方法的总体结构。该模型主要包括3个部分,特征提取模块、混合注意力模块、评价度量模块。特征提取模块(一种轻量化的孪生网络结构)从输入的高分辨率遥感影像对中获取特征图X1,X2∈RC×H×W,其中H,W是特征图的高、宽,C是每个特征向量的通道维度。将所获取的特征图融合为X,并送入混合注意力模块,通过该模块计算得到相似矩阵A,并经过矩阵乘法和reahape得到更新后的特征图Z1,Z2。调整更新后的注意力特征图大小,恢复至输入图像大小,利用评估度量模块计算两张特征图里每个像素对的距离,最终生成距离图Di,j,并与阈值进行比较得到二值图(0:未变化,1:变化)。
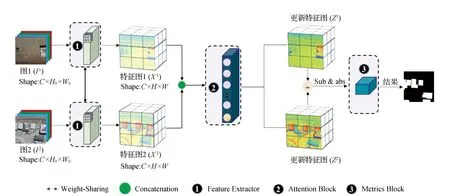
图1 变化检测模型结构
1.2 轻量化的孪生特征提取模块
遥感图像变化检测是一项基于像素级预测的二分类(变化、不变化)任务。在特征提取结构中(见图2),上下文语义引导模块(context guidance block,CGB)采用平行扩张卷积来替代标准卷积,同时利用深度可分离的方式进行计算,显著减少了模型参数量,提高了模型效率。同时,上下文语义引导模块可以获取不同范围内的局部上下文语义信息。网络中的高层特征包含丰富的语义信息,但位置信息较为粗略,低层特征包含丰富的位置、细粒度等信息,但缺乏语义信息。因此,本文将深层语义信息和浅层空间信息进行融合,以产生更为精细的特征表示。轻量化孪生特征提取网络由4个复合层组成,每个复合层分别包含[3, 3, 8, 12]个CGBs。输入数据X经局部和全局语义信息提取后送入由平均池化层、非线性层和sigmoid层组成的结构中用于通道交互和全局信息提取。可以表示为:
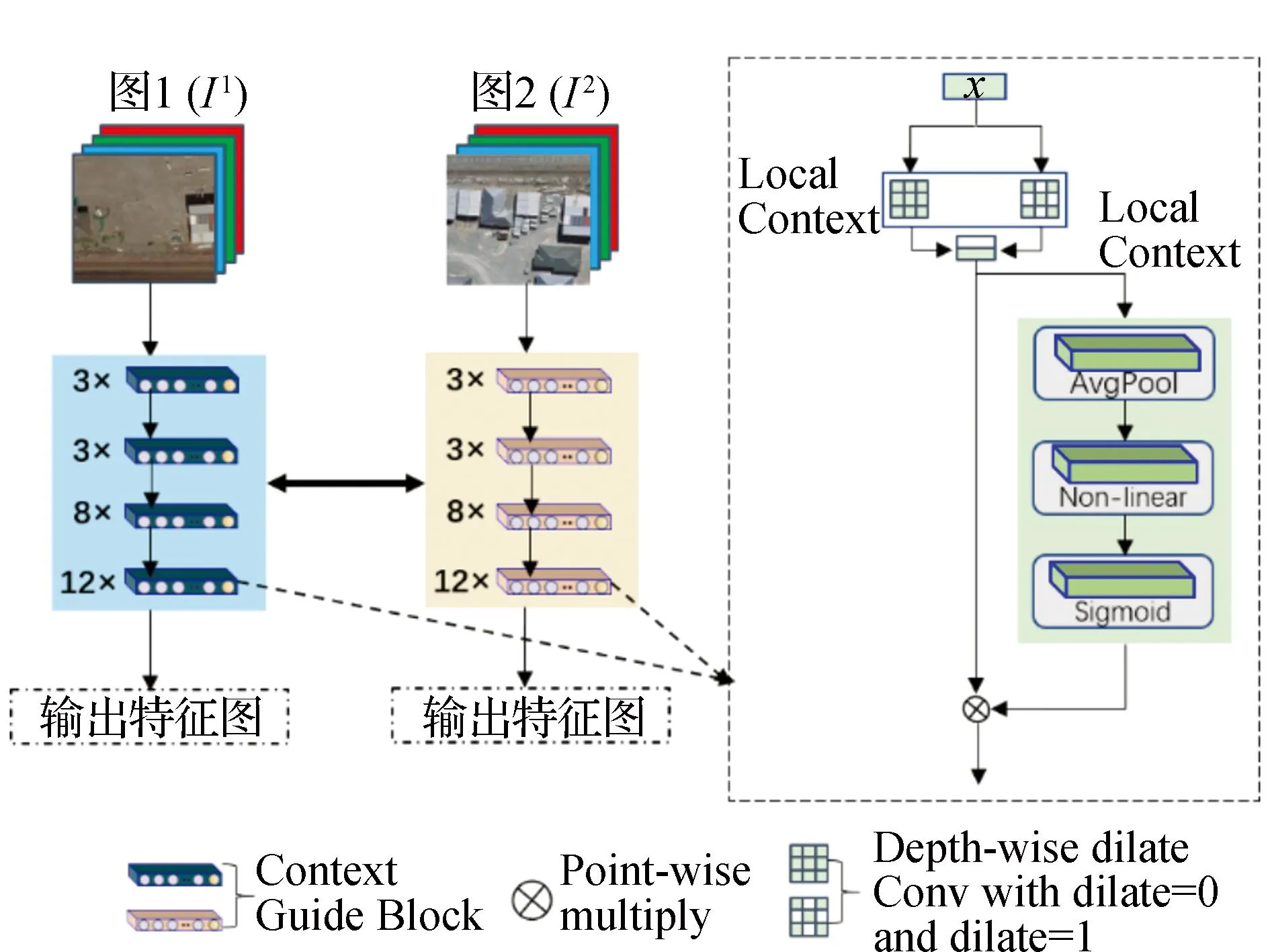
图2 孪生特征提取模块结构
(1)
深度可分离卷积(depthwise separable convolution,DSC)[18]由逐通道卷积和逐点卷积两部分组成(见图3)。首先进行逐通道卷积,它对输入的特征图的每个通道分别使用一个卷积核,然后将所有卷积核的输出再进行拼接,最终得到该部分的输出结果。在逐点卷积中需要使用1×1×C的卷积核对逐通道卷积输出的结果进行计算,C为上层输出结果的通道数。逐点卷积能够让DSC自由的改变输出通道的数量,同时也能对上层输出的特征图进行通道融合。
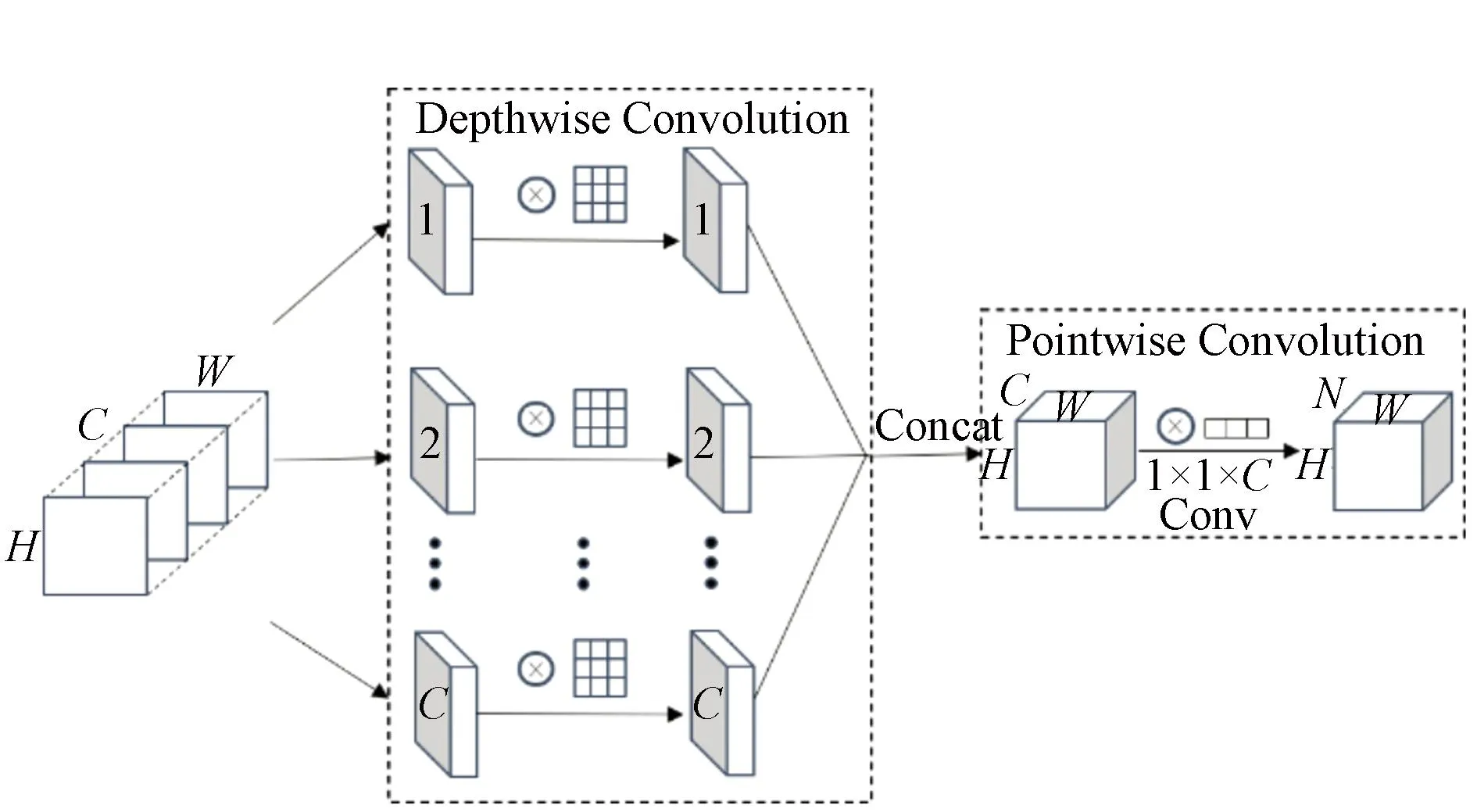
图3 深度可分离卷积结构
标准卷积、逐通道卷积、逐点卷积和深度可分离卷积的参数量计算如式(2)~(5)所示。由算式可知,深度可分离卷积与标准卷积参数量的比值为1/N+1/(K×L),N为输出特征图的通道数,说明DSC的计算效率优于标准卷积。
(2)
(3)
SepConv(Xp,Xd,y)(i,j)=PointwiseConv(i,j)
(4)
((Xp),DepthwiseConv(X,y)(i,j)(Xd,y)).
(5)
其中,X为输入数据;y为尺寸为K×L的卷积核;C为数据的通道数;(i,j)是每张图像的像素数。
1.3 多尺度混合注意力模块
为了充分利用输入图像对的上下文信息,构建了一种多尺度的混合注意力模块,通过聚合不同尺度的通道-空间信息来生成多尺度注意力特征矩阵,提高模型识别精细细节的能力。在多尺度混合注意力模块中,每个分支将特征图均分为一定尺度的子区域,并在每个子区域中引入混合注意力模块,以获取每个子区域的注意力特征,然后将每个分支生成的不同尺度的注意力特征张量进行融合,生成多尺度注意力特征张量,并进行拼接。
如图4(a)所示,将特征提取器获取的特征图送入混合注意力模块中,该模块包含两部分,分别为空间注意力和通道注意力。
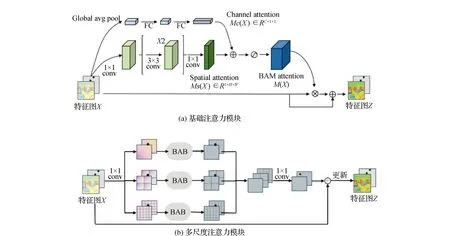
图4 结构
1)首先,对输入特征图X进行全局平均池化操作以聚合不同通道的特征图,同时生成的通道向量FC会对每个通道的特征信息进行编码,最终生成通道注意力矩阵MC(X),如式(6)所示。为了验证通道注意力的效果,使用多层感知机(MLP)对其进行评估,并在MLP之后增加批量归一化(BN)层调整输出尺寸。
MC(X)=BN(MLP(Avgpool(X))).
(6)
2)空间注意力模块利用1×1卷积对输入特征图X进行降维,并在整个通道维度上进行合并和压缩。然后利用两个3×3的扩张卷积扩大感受野,使之能够充分利用上下文时空语义信息,同时降低了模型参数量。最后,采用1×1卷积将特征图简化为空间注意力图MS(X),并在空间注意力分支末尾应用BN层调节输出结果尺寸。空间注意力计算如式(7)所示。
(7)
其中,f代表卷积操作,下标代表卷积次序,上标表示卷积核大小。
将获得的通道注意力图MC(X)和空间注意力图MS(X)进行组合,生成最终的3D注意力图M(X)。由于MC(X)和MS(X)具有不同的尺寸,因此,首先将两种注意力图扩展为C×H×W,然后采用元素求和的方法进行组合,这样更有助于梯度更新传播。最后采用非线性函数sigmoid获得[0, 1]范围内的注意力特征图M(X),将M(X)与输入特征图进行逐元素相加获得更新后的特征图Z,如图1所示。
M(X)=σ(MC(X)+MS(X)).
(8)
式中,MC(X)∈RC是通道注意力;MS(X)∈RH×W是空间注意力。
如图4(b),将混合注意力作为基础注意力模块(basic attention block, BAB)引入到多尺度分割特征图中。
1)多尺度分割:多尺度混合注意力模块(multi-scale attention block, MSAB)将原始特征图X1,X2堆叠为特征张量X,然后送入3个分支,每个分支将特征张量均分为d×d个子区域,d=[1,2,5],并对每个分支引入BAB模块。
2)引入混合注意力模块:通过对多尺度分割所产生的每个特征图子区域引入混合注意力模块,以生成不同尺度的注意力特征。
3)特征融合:对不同尺度的输出特征图进行融合,并经过1×1卷积生成新的特征图,再与原始张量X相加,产生更新后的张量Z。在混合注意力模块中下采样阶段的卷积和非线性映射用于提取变化区域的显著特征,最大池化层用于降低特征图的分辨率,同时增大特征图的感受野。
随着下采样层数的增加,感受野会逐渐增大,特征图的判别能力会逐渐增强;上采样使用双线性插值将特征图逐步恢复为原始大小。
1.4 评价度量模块
深度度量学习涉及训练网络,以学习从输入到嵌入空间的非线性变换。其中,相似样本的嵌入向量更加相近,而不同样本差距更大。为了评价由特征提取模块提取、多尺度注意力模块更新后的特征图(Z1、Z2)之间的相似度,文中采用对比损失函数(Contrastive Loss函数)作为评价度量标准。Contrastive Loss函数能有效地处理孪生神经网络中的数据对,表达式如下:
1/2(Y){max(0,m-DW)}2.
(9)
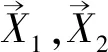
首先利用双线性插值将更新后的特征图Z1、Z2调整为大小相同,并作为位时图像输入评价度量模块。然后根据像素对计算调整后的特征图之间的欧氏距离,生成距离图。通过生成的距离图与阈值相比较,确定该像素点是否发生变化。
(10)
其中,下标i,j分别表示像素点位置;θ是分离变化区域的固定阈值;P为生成的变化图,1表示变化,0表示未变化。
2 实验数据与精度评价指标
2.1 数据集
数据集WHU-CD[19]选取的是新西兰城市克赖斯特彻奇,覆盖了2011年2月发生6.3级地震并在随后几年重建的区域。该数据集由2012年4月获得的航拍图像组成,其中包含20.5 km2的12 796座建筑物(2016年数据集中同一区域的16 077座建筑物)。遥感影像空间分辨率为0.2 m。
数据集LEVIR-CD[20]由637个高分辨率(VHR,0.5 m/px)的Google地球图像对组成,大小为1 024像素×1 024像素。时间跨度为5~14年,图像对土地利用有显著变化,尤其是建筑增加。LEVIR-CD涵盖各种类型的建筑,如别墅住宅、高大公寓、小型车库和大型仓库。LEVIR-CD总共包含31 333个单独变化的实例。
2.2 数据预处理
由于电脑内存限制高分辨率遥感影像并不能直接用于变化检测的数据集,需对数据进行预处理。
1)对遥感影像进行切片,设置切片大小为256像素×256像素,重叠度为0。其中双时相的遥感影像为3通道的RGB图像,标签(label)为单通道的灰度图(灰度值:0~255)。
2)为增强模型的泛化能力,对数据进行适当的数据增强处理,主要技术手段包括:翻转、旋转、色彩增强(减弱)、高斯模糊。
3)对数据增强后的数据集进行划分,其中训练集占70%,验证集占10%,测试集占20%。
2.3 实验环境与参数设置
实验硬件采用Ubuntu18.04.5LTS操作系统,GPU采用RTX2080Ti,CPU采用Xeno(R)×5650,深度学习框架采用pytorch1.6、python3.6,CUDA版本11.4,CUDNN版本8.2.2。
在神经网络训练过程中参数不断进行更新,但固定学习率不能适应所有参数的更新,为平衡不同参数的学习能力应动态调整学习率,文中采用Adam优化器更新网络权重,模型训练初始学习率设置为0.001,同时采用ReLU作为激活函数,迭代次数epoch=200。
2.4 精度评价指标
实验结果精度评定采用总体精度(OA)、平均交并比(MIoU)、精确率(Precision)、召回率(Recall)及F1值。其中F1值能够很好的兼顾精确率和召回率。算式如下:
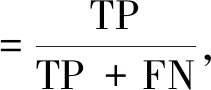
(11)
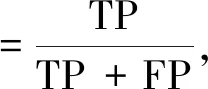
(12)
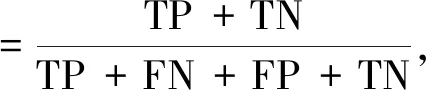
(13)
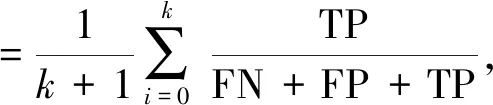
(14)
(15)
式中:TP:真阳性(真实值为1,预测值也为1);TN:真阴性(真实值为0,预测值也为0);FP:假阳性(真实值为0,预测值为1);FN:假阴性(真实值为1,预测值为0);k为分类数。
3 实验结果与分析
3.1 消融实验分析
采用消融实验对比分析改进模块对模型性能的影响。对比对象包括不包含注意力模块的骨干模型(Base)、融合混合注意力模块的网络(BAB)和融合多尺度混合注意力模块网络(MSAB),实验数据集采用WHU-CD和LEVIR-CD。
图5为WHU-CD数据集消融实验不同网络收敛情况统计对比。选取Precision、Recall、F1 3个代表性评价指标,分析不同模块在WHU-CD数据集上迭代训练过程中收敛情况。相较于基线模型和BAB模型,MSAB模型在迭代训练过程中保持了最高的Precision和F1值。Recall值统计结果显示,随着迭代训练次数的增加,仅融合注意力模块的BAB模型性能有所下降,增加多尺度特征的MSAB模型能够保持较高的精度。表1为WHU-CD数据集消融实验测试精度对比统计结果。BAB模型相较于基线模型在Precision、MIoU、F1值上分别提升了6%、2.1%、3.9%。MSAB在BAB的基础上分别提升了3.8%、3.6%、2.5%,证明改进模块的有效性。
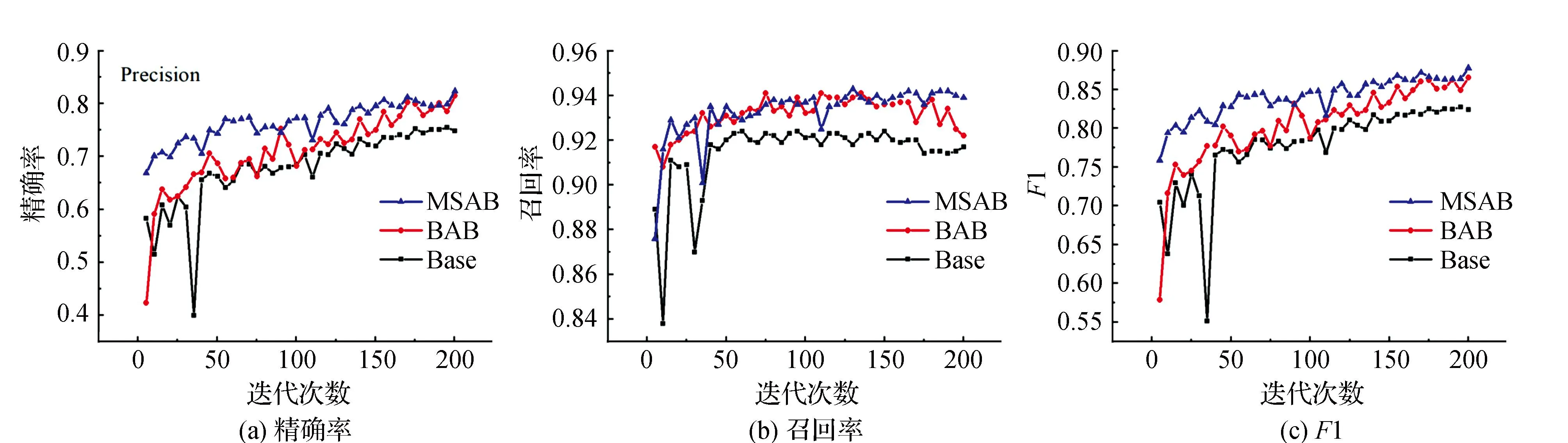
图5 WHU-CD数据集消融实验不同网络收敛情况对比
为了保证模型具有良好的普适性,在LEVIR-CD数据集上也进行了消融实验。实验中不同网络收敛情况对比,如图6所示。从图6统计结果可以看出,融合了多尺度混合注意力模块的网络在精确率(Precision)、召回率(Recall)、F1值评价指标上依旧优于基线模型和BAB模型,且召回率提升明显。由表2测试统计结果可知,融合BAB模块后的模型优于基线模型,平均交并比(MIoU)提高2.2%、F1值提高2.8%。进一步融合MSAB模块后,每个评价指标均有提升,其中平均交并比达到87.9%,F1值达到88.1%,相较于基线网络分别提升了5.6%、5.4%。试验结果表明,融合多尺度混合注意力模块后增强对变化像素识别能力的同时又提高了感受野,进一步提升模型识别精细特征的能力,通过增加实验数据集种类,表明了本文所提方法具有良好的泛化能力。

表2 LEVIR-CD数据集消融实验测试集结果对比
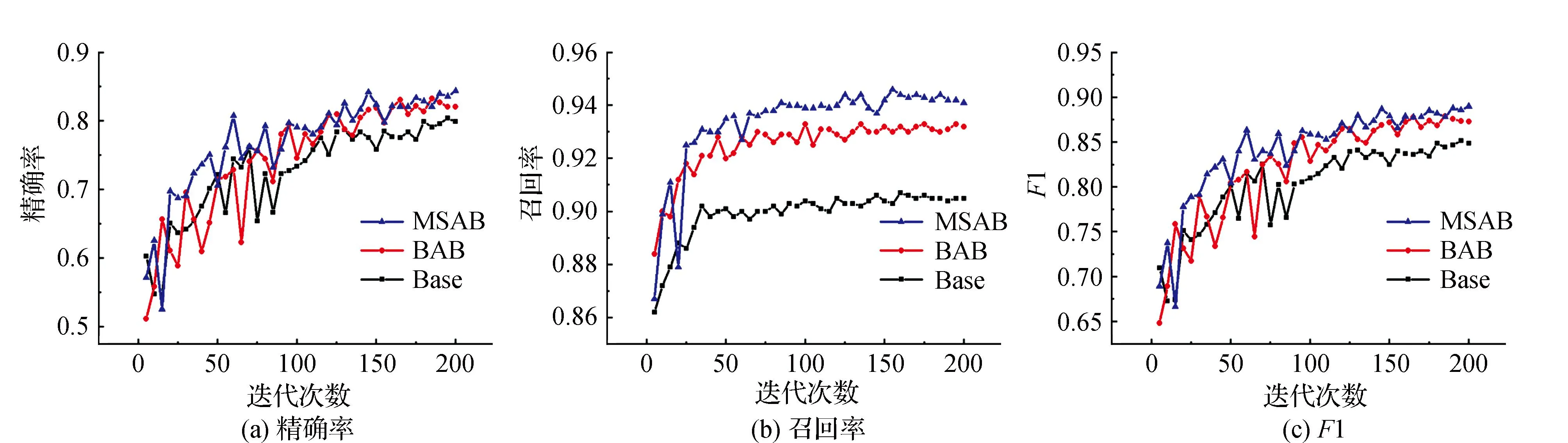
图6 LEVIR-CD数据集消融实验不同网络收敛情况对比
3.2 与其他算法的对比试验
通过实验对所提方法进行综合评估,并与其他优秀的变化检测方法STANet[21]、IFNet[22]、FC-EF[23]、FC-Siam-conc[23]、FC-Siam-diff[23]和DSAMNet[24]进行对比。如表3所示,与6种变化检测模型相比,采用融合多尺度混合注意力的轻量化模型进行建筑物变化检测,可以实现更好的检测分割精度。所提方法在WHU-CD数据集上的F1-score达到87.8%,优于其他对比模型,MIoU、Recall、OA等关键指标也均有不同程度的领先,其中Recall值提升5.6%。表4是基于LEVIR-CD数据集得到的测试结果,文中所提出的改进方法具有最优的F1、MIoU、Recall和OA统计值。
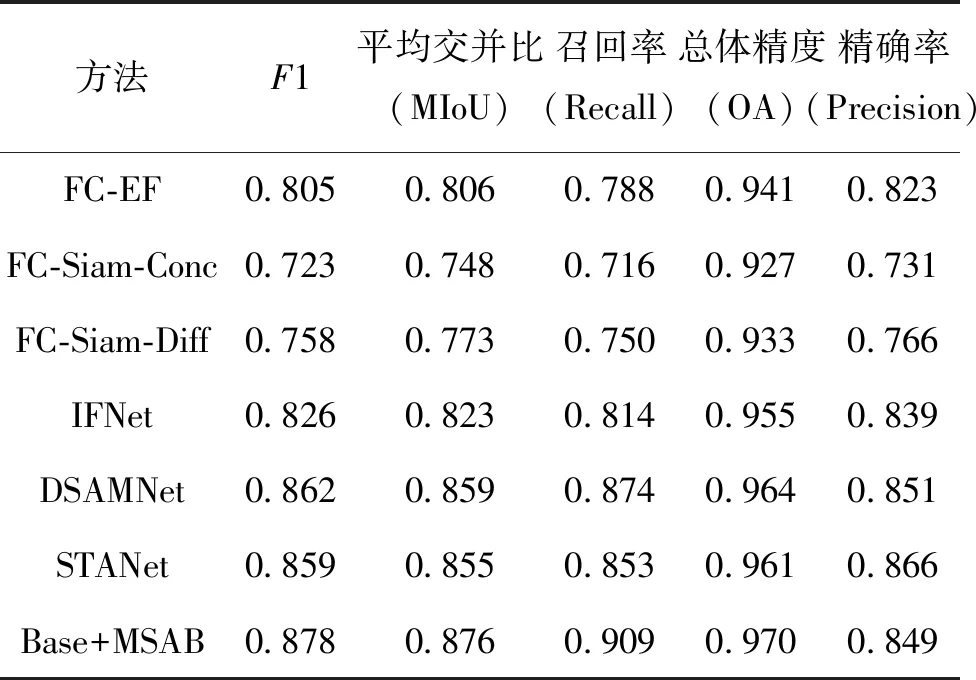
表3 不同变化检测方法在WHU-CD数据集测试结果对比
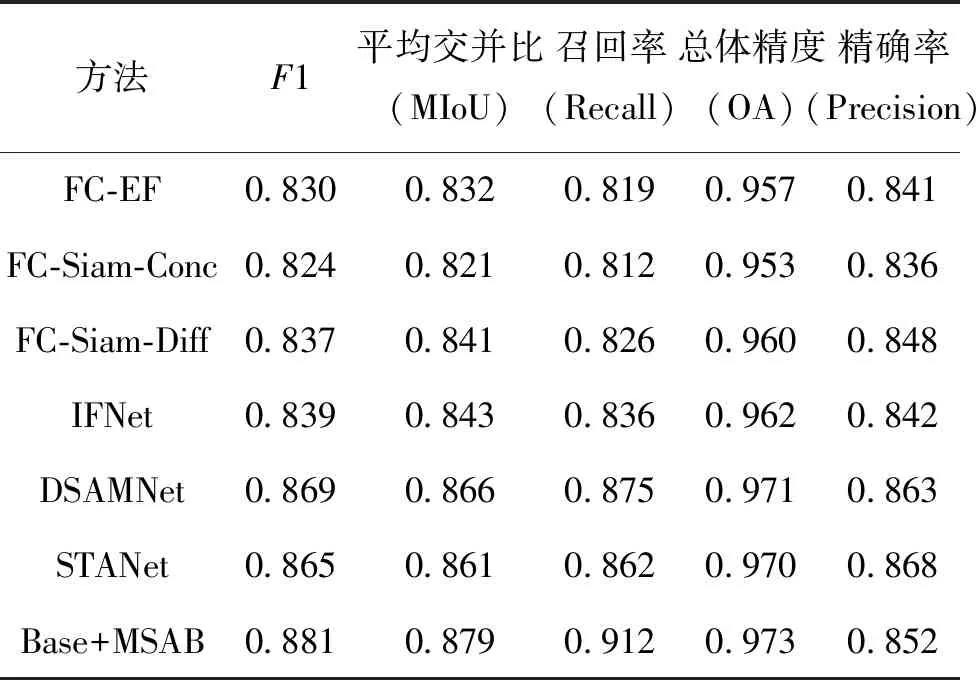
表4 不同变化检测方法在LEVIR-CD数据集测试结果对比
与WHU-CD数据集结果相比,LEVIE-CD数据集上的实验精度有所提升,这主要是由于LEVIR-CD的数据量大于WHU-CD。由表3和表4可知,对比模型对数据量的变化较为敏感,性能损失程度较大,而所提方法在低数据量的测试中更加稳健,性能损失较小。
表5为骨干网络参数和计算量的比较,因为本文所提骨干网络层数为52层,与ResNet-50相似,通过对比可知文中所提骨干网络无论在参数量还是计算量都具有明显的优势。图7为不同模型的参数计算量统计,文中改进方法具有最低的计算量,相较于其他模型中计算量最小的FC-EF模型,计算量降低27.8%,具有较高的计算效率。上述算法对比实验结果表明融合多尺度混合注意力机制的改进模型能够兼顾处理多层次细节特征的同时又能充分利用丰富的上下文时空语义信息,降低计算复杂度,提升变化检测精度。
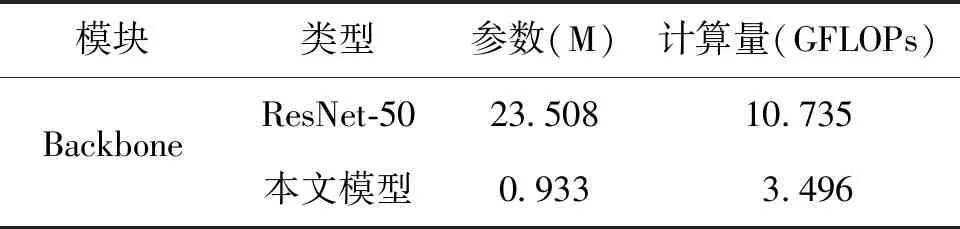
表5 骨干网络参数和计算量的比较
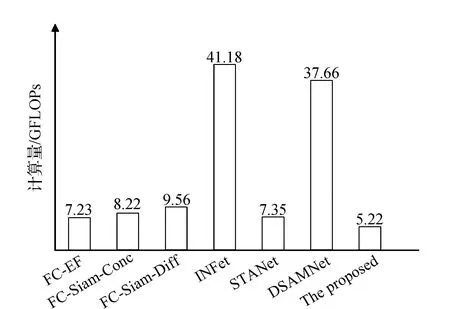
图7 不同模型计算量比较
3.3 实验结果可视化
图8和图9分别为WHU-CD和LEVIR-CD的部分可视化对比结果图,包含大、中、小3种尺度的建筑物类型,白色代表前景(变化像素),黑色代表背景(未变化像素)。与真实标签对比,FC-EF,FC-Siam-Conc和FC-Siam-Diff模型预测结果中,检测建筑物边缘模糊,精度较低。IFNet由于将通道注意力应用于解码器每一级特征提取中,所以预测结果边缘精细度相较于前3种模型有所改进。STANet模型采用孪生结构处理双时相遥感图像,且模型中的自注意力机制能较好的识别建筑物边缘细节特征,相较于IFNet模型有所提升。DSAMNet模型集成了CBAM块以在空间和通道两个层面上获得更具区分性的特征,并集成了深度监督层以获得更好的特征提取,最终的结果相较于STANet有略微的提升。而文中所提方法在聚合上下文语义引导模块的轻量化特征提取器的基础上增加多尺度的混合注意力结构,使模型能更好地识别建筑物边缘特征,预测标签更加精细,降低了因识别变化特征不够明确而造成的预测标签边缘粗糙、缺失的情况,提高了模型准确率。此外,对比模型存在一定的误报率,主要原因在于道路或其他地物具有与建筑物相似的颜色,纹理特征,由于对比模型的感受野(RF)有限,较难辨别这些伪变化。最后,通过图8(第4行)可知,对比模型对于微小尺度的变化不敏感,容易造成微小变化建筑物漏检的问题。

图8 WHU-CD可视化结果

图9 LEVIR-CD可视化结果
图10和图11分别为基于WHU-CD和LEVIR-CD的误差对比图。通过对比可得FC-EF,FC-Siam-Conc和FC-Siam-Diff存在较多的漏检(红色)、多检(蓝色)的问题,总体模型精度较低;IFNet在多检问题上有所改善,但依然存在多检严重的问题;STANet和DSAMNet相较于前4种方法在漏检、多检问题上有明显的改善。而文中所提方法漏检(红色)、多检(蓝色)的建筑物明显少于对比模型,更加接近真实的变化情况。
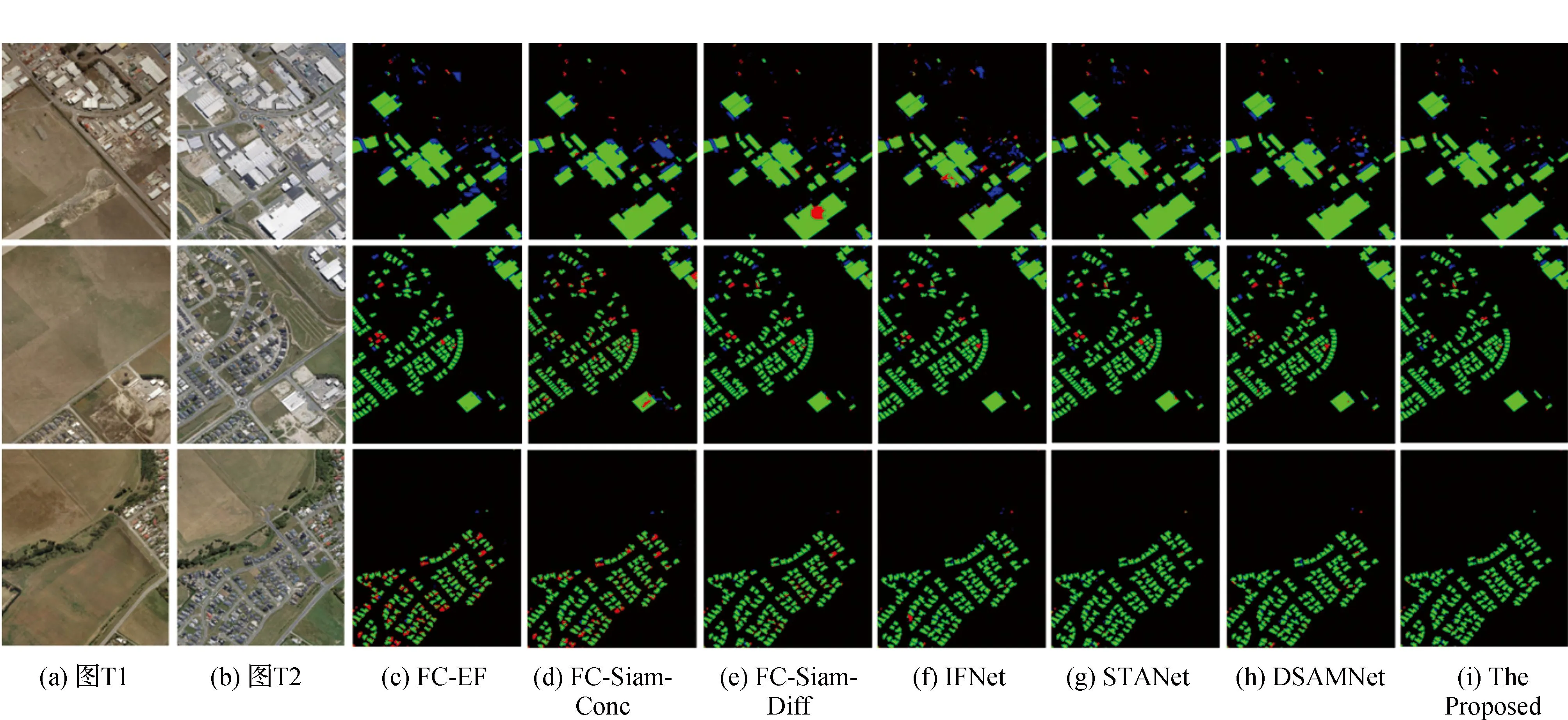
图10 基于WHU-CD的误差图对比 (褐色、绿色:正确检测,红色:漏检,蓝色:多检)

图11 基于LEVIR-CD的误差图对比(黑色、绿色:正确检测,红色:漏检,蓝色:多检)
通过以上评价指标对比,表明本方法在预测标签边缘精细度、误报率、召回率方面具有优势。
4 结 论
针对建筑物变化检测问题,提出了一种融合轻量化特征提取模块和多尺度混合注意力机制的深度学习网络模型,并在WHU-CD和LEVIR-CD公开数据集上进行了消融和对比实验,结论如下:
1)通过与6种优秀的变化检测方法对比,文中所提方法总体精度为97.0%、F1得分为87.8%、平均交并比为87.6%、召回率为90.9%,相较于对比模型表现最优,主要体现在变化建筑边缘预测更加精细化,有效降低了微小建筑物漏检率以及影像非真实变化所引起的错误检测。表明文中所提方法在高分辨率遥感图像建筑物变化检测中效果较好,具有较高的精度。
2)文中所提方法具有最低的模型计算量,显著提升了模型变化检测效率。相较于STANet、IFNet、FC-EF、FC-Siam-conc、FC-Siam-diff和DSAMNet 6种对比模型,文中提出的方法模型计算量仅有5.22GFLOPs,相较于其他模型中计算量最小的FC-EF模型,计算量降低27.8%,具有较高的计算效率。
3)通过在WHU-CD、LEVIR-CD两种数据集上进行测试,实验结果相较于对比模型均达到了最优表现,证明了该方法具有良好的普适性以及鲁棒性,模型泛化能力强。
今后研究将考虑融合多源数据特征进行变化建筑物的精确检测与提取,弥补单一光学遥感图像的局限性,进一步提高检测精度。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小雪花·成长指南(2022年1期)2022-04-09
河北地质(2021年1期)2021-07-21
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
中国生物医学工程学报(2019年5期)2019-07-16
中南林业科技大学学报(2017年12期)2017-12-19
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
