
文心一言对汉语歧义的翻译研究
2024-05-07 10:56唐红芳李婧怡
名家名作 2024年6期
唐红芳 李婧怡
[摘要] 语言歧义一直都是自然语言处理系统面临的最大挑战之一,最近百度推出的人工智能模型文心一言引起了大众的关注。通过实证研究,分析文心一言在汉语歧义句方面的翻译现状,探讨其在汉语歧义句翻译方面的特点和不足,得出文心一言可以通过人为反馈对结果进行优化,而且关注语言的使用习惯,让表达更地道,但是翻译比较单一,且没有一致性。这让人们更好地了解自然语言处理机制,优化人工智能的性能,让其更好地为人类所用,达到“人机合作”的理想局面。
[关 键 词] 汉语歧义;人机互动;文心一言;翻译
一、引言
我国著名语言学家朱德熙先生认为:“一种语言语法系统里的错综复杂和精细微妙之处往往在歧义现象里得到反映。”随着时代的发展,人工智能逐渐出现在生活中,比如机器翻译、人机对话、智慧教学等,而语言是人机交流最基础的媒介,自然语言的处理就变得十分关键。机器无法像人类一样可以通过生活常识和对汉语的精准掌握来排除歧义,它只有掌握人类制定出来的一套消除歧义的规则才能破解这个难题。而机器翻译就是一个不断去除句子分析歧义的过程。因此,研究自然语言的歧义现象,并制定系统的消解歧义的规则,让机器去掌握,是新时代语言学发展的一个关键方向。
二、文献综述
对于汉语的歧义研究最早可追溯到赵元任先生用英语发表的《汉语歧义问题》。此后,汉语研究者从多个方面对歧义进行了探讨,主要有歧义定义、歧义类型、歧义格式、歧义比较和歧义消解方法等。刘悦怡等(2020)对歧义的分类文献进行了详细的梳理,将现代汉语的歧义类型划分为语音歧义、词汇歧义、句法歧义、语义歧义和语用歧义五大类,本文将按照此分类标准进行实验。目前的歧义研究以书面语歧义为主,语用歧义的相关研究还不够深入,且多注重口头交际,书面交际中的语用歧义研究比较匮乏(尤天来,2022)。因此,这里主要探讨两个基本歧义层次,即词汇歧义和句法歧义,这也是自然语言处理模型要面对的最基本的挑战。
目前对于人工智能在歧义句翻译方面的研究还不多。刘海军等(1997)基于全句翻译的智能英汉机器翻译系统,构造了一个语言环境以消除语境方面的歧义,如组合歧义、省略等语言现象。陈海东(2009)针对计算机翻译系统中汉语词汇切分的问题,提出在汉语标点中利用切分词标点的解决方法。要想机器识别出汉语歧义句并准确翻译成另外一种语言,需要大量的实证研究和推理,从而得到歧义消解的办法。实际上,机器翻译就是一个不断去除句子分析歧义的过程(刘海军等,1997)。
根据上述文献,研究人工智能对于汉语歧义句的翻译现状是有必要的。本文基于一篇研究ChatGPT语义模糊分析的实验步骤,从汉语歧义角度出发,让文心一言翻译一些典型的汉语歧义句,并对翻译结果进行分析,探讨其在汉语歧义句翻译方面的特点和不足,进一步讨论人工智能与语言学理论是否可以相适应。
三、结果与讨论
(一)词汇歧义翻译
刘悦怡等(2020)认为,词汇歧义是指由词(字)形相同、意义不同的词(字)所引起的歧义,且与词汇结构、句法结构的差异无关。词汇歧义又可进一步分为多音词歧义和一词多义歧义。比如说,“这是一本好书”,这句话中的“好”既可以是说书的“内容”好,也可以是说书的本身完好、无损坏,两者都是形容词,所以这是一个词类相同的一词多义歧义。多音词歧义只出现在书面语中,一旦读出来就没有歧义了,但是文心一言支持用户语音输入,因此这里不讨论多音词歧义的翻译情况,只研究一词多义造成的歧义现象。每个句子的实验流程基本如下:(1)翻译。(2)问是不是歧义句。(3)问句子中多义词的含义。(4)再次翻译这句话。
首先,对它进行简单句的测试,包括“桌子上放着苹果”“菜不热了”和“ 他走了一个小时了”,并判断文心一言能否识别出其中的歧义现象,答案是不能。 像“桌子上放着苹果”这句话中的“苹果”既可以指水果,又可以指苹果牌电脑,因此在没有语境的情况下,这是一个歧义句。但是文心一言并没有看出这里的歧义,坚持认为“苹果”是指水果。这样的情况在测试的三个例句中都有发生,文心一言都只能确认这个词语最常见、用得最多的意思,对其进行英语翻译也只提供了这一种翻译方式,包括 “There is an apple on the table”,“The food is not hot anymore”,“He has been gone for an hour”。
其次,通过多轮有意提问的方式,比如“有没有可能‘菜不热了中的‘热字是作动词表示加热”等这种指向性的提问方式,获得的反馈是积极的,通过人为提示,知道这个词语可能还存在的几个意思,不过也暗示用户要提供更多的语境信息和明确表达自己的需求,才能避免句子歧义。但是也发现一个现象,即使它知道这是一个歧义句,其展现出来的歧义解释有些不符合人们正常的思维规律,比如说对于“菜不热了”中“热”这个字的解释是“菜已经冷掉了”和“这不是一道热菜”,后面一个解释似乎不符合语言使用习惯,且已有文献并未提供这个解释(刘悦怡等,2020)。
最后,在几轮提问和获得正向性反馈的基础上,让其再次翻譯一下这句话,并且提问方式换成了“这句话可以有哪些翻译”,或许是受到提问中“哪些”这个词的影响,一般会得到多种答案,大都包含了这个词语不同意思的翻译,并且对于用法没那么常见的解释,也会提供更加准确、地道的英语句子,比如说“他走了一个小时了”理解为“他已经去世一个小时了”的话,比较直接的翻译是“He has been dead for an hour”。但是这种翻译并不符合英语的语用习惯,因此它建议翻译成“He passed away an hour ago”。
总的来说,文心一言很难识别出一词多义歧义句,有时甚至还会提供错误的意思,但是通过人为有意的引导和提醒,它可以识别出这个多义词的多重含义,说明文心一言具有根据用户反馈从而提高回答准确度的能力,因此,我们可以通过有意识的训练提问方式,来获得想要的答案,从而减少机器运行负担。比如说,可以问“这句话有哪些翻译”而不是“请翻译一下这句话”,这样得到的答案或许更符合我们的预期,也能扩宽知识量。
(二)句法歧义翻译
句法歧义是指句子因结构层次不同或句法成分之间的关系不同而产生的歧义,又可以细分为结构层次歧义和结构关系歧义(刘悦怡等,2020)。比如说,“小王和小张的同学”是典型的结构层次歧义,句子由于层次切分的不同,可以产生两种解释,即“小王/和小张的同学”和“小王和小张的/同学”。像“学习文件”这句话,两种解释的结构层次都相同,都是“学习/文件”,但是成分间的关系不同,“学习”和“文件”的关系既可以是偏正结构,也可以是动宾结构,因此称为结构关系歧义。这一部分我将分析五个句子,每个句子的分析步骤大致如下:(1)翻译。(2)问是不是歧义句。(3)确定有歧义的部分。(4)再次翻译这句话。
首先分析一个结构层次歧义句,在汉语中,“张三和李四的同学”属于结构层次歧义句,由于连词“和”管辖领域的不同,其层次可以理解为(N1+和+N2)+的+N3,也可以理解为N1+和+(N2+的+N3),从而产生歧义,既可以表示“张三自己和李四的同学”,也可以表示“张三和李四两个人的同学”,其中同学可能是一个,也可能是两个或者很多个。当问文心一言这句话是不是歧义句时,它辨别了这是一个歧义句,然而它给出的歧义解释并不全面,只包含 “张三和李四共同的同学”和“张三和李四各自的同学”这两个意思。当继续问能不能有“张三自己和李四的同学”这个意思时,它同意存在这个解释。从最初的翻译“Classmate of Zhang San and Li Si”增加了“Zhang Sans classmate and Li Si's classmate”另一种英文表述。因此,对于汉语中的结构层次歧义句翻译,我们可以在询问时组织好措辞,尽可能简明地表明问题,包括词语的单复数形式、句子切分后的语序等,把潜在的歧义都显化出来,以获得更加准确的结果。
同样的结构层次歧义句“咬死猎人的狗”却有不同的实验结果,一开始它不认为这是歧义句,翻译出来的句子也是 “The dog that bit the hunter to death”。后面经过多次提问,它认为这句话中的歧义问题可以通过上下文或者语境来消解,因此在实际使用中一般不会造成误解。而且最后给出的翻译都包含了这两种释义,即“The dog that bit the hunter to death”“The hunters dog that was killed by an attacking animal”“The hunters dog that was bitten and killed by another dog”这再一次印证了有效的提问方式和人为的反馈可以提高文心一言文本内容生成的准确性。
对于结构关系歧义,我选取了两种关系不同的短语,即“学生家长”这种并列或偏正结构,以及“学习文件”这种偏正或动宾结构。第一种关系歧义句,它只识别出了偏正结构,即“学生的家长”,翻译结果为“Students parents” or “students parents”。经过提醒后,也指出并列结构的解释需要依靠语境,而且这是一个复数概念,或许是上一轮回答有提到“复数”概念,最后让它再次翻译的时候,“学生”都是复数形式,不同于第一次给出的有单数形式。第二种却恰恰相反,最先给出的翻译 “learned document”到最后直接没有了,只剩下动宾结构的形式,这要归于中间多轮刻意的询问。它可以准确识别出这句话存在两种解释方式,即“学习这份文件的内容”和“将文件作为学习资源”,但是在翻译环节出现了错误,只翻译出了动宾结构这种形式。
尽管文心一言前后回答存在出入,但经过多次的询问之后,其最后给出的翻译结果也不十分完美,但是这对研究这个模型是如何自我学习有重要的作用,而且还有助于用户学习如何与其互动,以达到更好的效果。文心一言可以通过人为干预来提升其回答的准确性,因此可以让用户自主学习有效的交流方式和提问方式,这或许不失为一个好办法。
四、歧义句生成测试
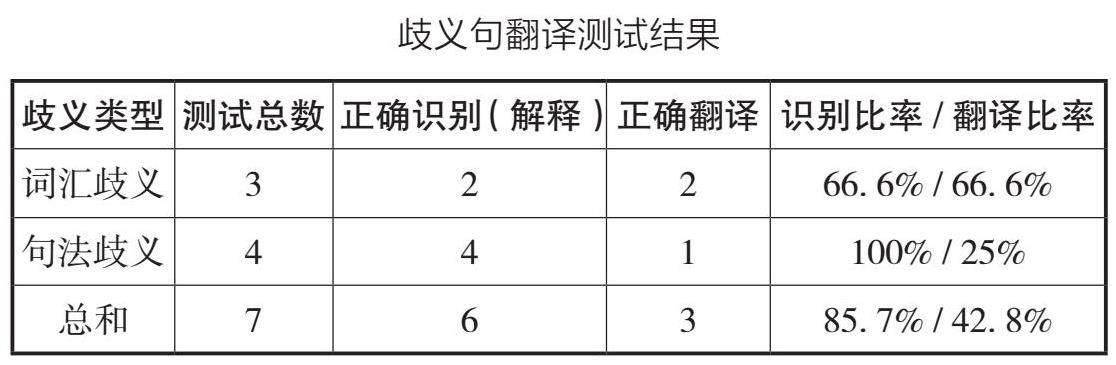
想了解文心一言对于歧义句的概念界定,最直接的办法就是让其自己生成一个歧义句,结果它生成的句子是“他背着我去了一趟书店”,显然这是一个歧义句,而且是多音词歧义,但它给出的两种解释都属于一个意思,即“他偷偷地去了书店,不想让我知道”和“他去书店的时候,我是知道的,但是我是在店外等他,而他没有告诉我他去书店干了什么”。因此,它对于汉语歧义句的定义完全没概念,只知道有几种不同的解释方式就算作歧义句,不管解释得对与否。这或许也是导致它前后回答矛盾、得出的翻译结果不够全面的原因之一,此次实验的全部数据总结如下表:
表格包含了文心一言对于汉语歧义句的翻译测试结果,其中正确识别(解释)行列是指通过提示后的结果,正确翻译是指最后测试的翻译结果。实验结果表明文心一言可以借助用户的提问方式和反馈来优化其生成结果。不过它也多次提出,消除歧义的关键是充足的语境。但是,它正确且全面地把歧义句翻译出来的比率只有识别的一半,即42. 8%,主要表现在句法歧义方面。英文的句法习惯不同于中文,可能受提问方式的影响,从而影响对中文歧义句的判断。
五、结论
本文从汉语歧义角度出发,让文心一言翻译一些典型的汉语歧义句,并对翻译结果进行分析,探讨人工智能在汉语歧义句翻译方面的特点和不足,结果表明文心一言在歧义句翻译方面有利有弊,它可以通过人为反馈对结果进行优化,而且关注语言的使用习惯,让表达更加地道,但是翻译比较单一,且没有一致性,答案多变不固定,有时还会出现有歧义的英语句子。然而,实验也会存在一些局限性,文心一言作为一款人工智能模型,一直在优化迭代,导致这个实验中的一些数据和结果可能会与未来的模型存在出入。这需要做更多研究和实验,以更好地了解和发展自然语言处理机制,优化人工智能的性能,让其更好地为人类所用,达到“人机合作”的理想局面。
参考文献:
[1]陈海东.计算机翻译存在的困难及解决方法新探[J].广东科技,2009,18(16):87-88.
[2]贾光茂.英汉语量词辖域歧义的认知语法研究[J].现代外语,2020,43(4):451-462.
[3]刘海军.智能机器翻译中的语境信息处理[D].北京:中国科学院研究生院(计算技术研究所),1997.
[4]刘悦怡,宫齐.现代汉语歧义类型的再讨论[J].暨南学报(哲学社会科学版),2020,42(5):24-32.
[5]尤天来.言语行為理论视角下的语用歧义策略研究[D].长春:吉林大学,2022.
[6]于秒,周思敏,龙佳欣.内隐韵律与语境对汉语均衡型歧义结构歧义消解的作用[J].心理与行为研究,2022,20(6):739-746.
[7]赵帅,鹿士义,陈婧,等.母语为韩语的汉语学习者加工“V+N1+的+N2”歧义结构的眼动研究[J].心理与行为研究,2019,17(1):15-23.
作者简介:
唐红芳(1968—),女,汉族,湖南浏阳人,教授,研究方向:语用学、应用语言学、外语教学。
李婧怡(2000—),女,汉族,湖南岳阳人,硕士研究生在读,研究方向:外国语言学及应用语言学。
作者单位:湖南工业大学
猜你喜欢
中国外汇(2019年12期)2019-10-10
学苑创造·A版(2018年12期)2018-03-04
时代人物(新教育家)(2017年10期)2017-12-18
中国篆刻(2017年5期)2017-07-18
学苑创造·A版(2017年6期)2017-06-23
疯狂英语·新悦读(2017年2期)2017-04-08
文学教育(2016年18期)2016-02-28
海南师范大学学报(社会科学版)(2015年7期)2015-12-28
时代英语·高二(2015年1期)2015-03-16
河南医学高等专科学校学报(2014年3期)2014-03-11
