
基于读者利用挖掘的图书馆决策与应用分析
2009-10-13 03:29张炜洪霞
现代情报 2009年7期
张 炜 洪 霞
〔摘 要〕本文介绍了数据挖掘技术、挖掘过程和数据挖掘体系结构,针对我馆信息管理系统中书目、读者和借阅信息、OPAC检索记录以及WEB问卷调查数据,分析如何应用数据挖掘技术发现读者利用及需求的规律和模式,并探讨了读者利用挖掘在图书馆服务和管理上的应用。
〔关键词〕数据挖掘;读者需求;图书馆决策;个性化服务
〔中图分类号〕G250.7 〔文献标识码〕B 〔文章编号〕1008-0821(2009)07-0047-04
Data Mining for Library Decision-making and
Application Analysis Based on Reader UsingZhang Wei1 Hong Xia2
(1.Library,Yangzhou University,Yangzhou 225009,China;
2.Laboratory and Equipment Manage Department,Yangzhou University,Yangzhou 225009,China)
〔Abstract〕This article introduced the technology,process and architecture of data mining,according to the booklist,the reader and the borrowing information in library information management system,OPAC searching records as well as the WEB questionnaire data,analyzed how to apply the data mining technology to discover the rule and pattern of reader using and demand,and discussed the reader using excavation in the library service and management application.
〔Key words〕data mining;reader demand;library decision-making;individuation service
图书馆作为学校信息资源的汇集中心,是以满足学校全体师生员工的教学、科研和学习的需求为目标。馆藏资源的实用性,只有通过读者的利用才能得到检验,同时利用也是读者对资源实际需求的体现,只有多渠道深层次地挖掘不同读者群的兴趣、借阅习惯、借阅倾向和借阅需求,分析并发现文献结构与读者知识结构的关系,才能预测出读者未来的借阅行为,从而为决策管理提供数据支撑,并快捷、智能化地为读者提供个性化主动服务。因此,面对“被数据淹没,却饥饿于知识”的数字化时代的挑战,如何充分利用数据挖掘技术发现有价值的隐性信息为图书馆管理服务,已成为目前图书馆领域一项非常有意义的研究内容。
本文针对我馆信息管理系统中书目、读者和借阅信息及OPAC检索记录、WEB问卷调查中的能反映不同读者群对不同资源的需求、阅读习惯、阅读倾向等大量的宝贵数据,探讨如何应用数据挖掘技术,找出隐藏在其中的读者需求规律和模式,为图书馆的决策提供数据支撑和参考,以便将其应用到对读者的主动推荐服务上,从而更好地提供智能化的个性服务。
1 数据挖掘概述
数据挖掘根据其主要研究对象的数据结构形式的不同,一般分为数据挖掘、web数据挖掘、文本数据挖掘3种类别。其中面向数值数据的挖掘,通常称数据挖掘。数据挖掘(Data Mining)就是指从大量的数据(结构化和非结构化)中提取有用的信息和知识的过程[1]。
1.1 数据挖掘技术
目前数据挖掘技术很多,同一个挖掘方法存在多个不同的挖掘算法。从挖掘功能上主要有分类分析、聚类模式分析、关联规则分析、序列模式分析、时间序列分析等方法。
1.1.1 分类分析
分类分析是根据数据对象寻找相应的分类规则,再根据规则对数据对象进行归纳分类,找出各类的特征属性。
1.1.2 聚类分析
聚类分析是根据数据对象间的相似性条件的满足与否进行数据的划分。把物理或抽象对象的集合组成由类似的对象组成的多个类或簇的过程。由聚类生成的簇是一组数据对象的集合,同一簇中的对象尽可能相似[2]。使得组间的差别尽可能大,组内的差别尽可能小,按照给定的聚类参数(如距离等)进行分解、合并。可应用到读者群体的聚类、图书文献的聚类、读者集群特性和借阅倾向分析等工作环节。其与分类分析不同的是,数据类划分的数量与类型均是未知的。
1.1.3 关联规则分析
关联规则分析是通过寻找数据对象间的关联模式,发现一些有价值的信息。如发现有很多读者借阅了A文献同时也会借阅B文献,则向借阅A文献的读者推荐B文献。一般用支持度和可信度两个阀值来度量关联规则的相关性,还不断引入兴趣度等参数,使得所挖掘的规则更符合需求。此规则挖掘须注意目标明确,选取恰当的最小支持度和最小可信度。
1.1.4 序列模式分析
序列模式分析是在数据库中寻找基于一段时间区域的关联分析。它与关联分析区别在于序列模式表述的是基于时间的关系,分析数据之间的前因后果关系,而不是对象间的关系,侧重点在于分析数据间的前后序列关系。它能发现数据库中形如“在某一段时间内,读者借阅了A文献,接着借阅B文献,而后借阅C文献,即序列A→B→C出现的高频序列”之类的知识,通过时间序列搜索出的重复发生概率较高的模式。在进行分析时须注意选取合适的最小置信度和最小支持度。
1.1.5 时间序列分析
时间序列分析是根据数据随时间变化的趋势进行预测,一般采用在连续的时间流中截取一个时间窗口,并将其中的数据作为一个数据单元,再让此时间窗口在时间流上滑动,以获得建立模型所需要的集合[3]。时间序列的数据库内某个字段的值是实时变化的。
1.2 数据挖掘过程
数据挖掘不仅仅是利用数据挖掘算法对数据进行挖掘的过程。还应包括挖掘目标的确定、前期的数据准备、数据挖掘和对挖掘结果的解释与应用。
1.2.1 确定挖掘目标和数据选择
根据问题和提供服务的要求,明确挖掘目标是数据挖掘的第一步。然后搜索所有与挖掘目标有关的内、外部数据。本文主要针对我馆信息管理系统中的书目信息、读者信息和借阅信息及OPAC检索记录、WEB问卷调查数据。它们的关系如图1所示:
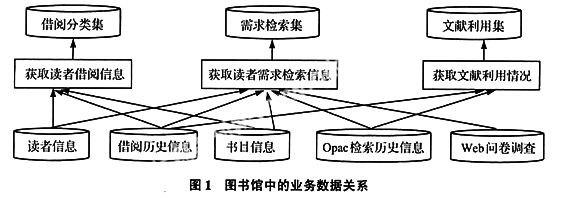
其中opac检索信息主要反映读者需求。内容主要包括读者标识、检索字段、检索时间。由于很多情况下是匿名登录,可以利用IP地址代替读者标识,对于检索字段如是规范的检索式需要记录多个检索词和检索符号、检索项,如是语句或短语还需进行分词;Web问卷调查主要来自“图书馆馆藏资源利用读者评价平台”,通过此平台可以了解不同读者(不同层次、不同院系读者、不同年龄段)对藏书的利用状态评价,分析不同读者群对藏书的需求倾向、对知识获取的范围和阅读的规律性等。
1.2.2 数据预处理和数据转换
数据预处理是对收集到的数据源进行加工处理和组织重构,以上的原始数据存在同构和异构的情况,因此需要从各种数据源中去选择所需要的数据构成目标数据,收集、整理、重构web问卷调查等异构数据,使之转化为标准的结构化数据。并对目标数据进行统一的存储,消除其中的不一致性。如:一些空值数据、不完整不一致的数据、冗余数据和缺失的数据,对它们进行去除噪声、删除无效数据、填补缺失项等操作。
数据转换主要是为了使数据能够适应算法计算的要求而进行的操作。包括离散值数据与连续值数据之间的相互转换、数据值的分组分类、数据项之间的计算组合等,对于高维数据集需要采用维变换或数据约简来减少数据属性值的有效数量。例如为了能实现聚类的分析,须对细而且数值分散的图书索书号进行数据处理,可分别取大类和第二级分类;对每天的流通记录数据可按照年、季、月、星期、小时的不同时间属性进行划分。
1.2.3 数据挖掘
数据挖掘阶段将根据挖掘目标和特点选择相应的算法,在净化和转换过的数据集上进行数据挖掘,用知识库中的领域知识指导搜索,寻找特定的感兴趣的模式或数据集,并对挖掘得到的知识模式进行分析与评估,将模型评估与数据挖掘集成在一起,以便将搜索限制在有价值的模式上。这是一个反复迭代进行的过程,需要对挖掘结果进行不断的实践应用、测试、和比对,直至读者满意。
1.2.4 挖掘结果的解释和应用
挖掘结果往往不是可视化的,是难以理解的。因此需要对结果进行合理的解释,将发现的知识以便于用户理解和观察的可视化方式反映给用户,并提供个性化的主动推荐服务。
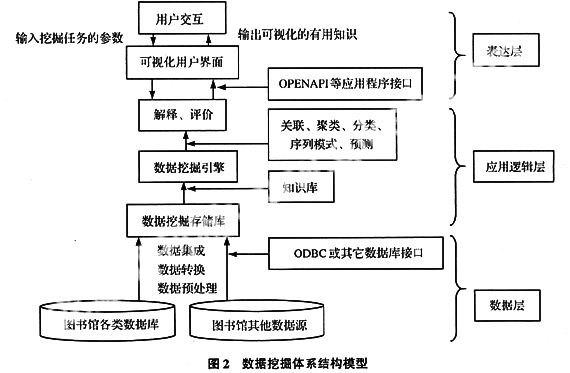
1.3 数据挖掘结构模型
数据挖掘体系结构主要包含三层,即:数据层、应用逻辑层和表达层,其中第一层是数据层,主要通过ODBC或其它数据库接口提取图书馆相关的各类数据。第二层是应用逻辑层,主要完成数据挖掘、应用服务等处理功能。第三层是表达层,主要负责用户与数据挖掘系统间的交互。结构模型如图2所示。
2 读者利用及需求挖掘在图书馆服务管理中的应用
图书馆每天都会产生大量的数据, 这些数据背后蕴藏了丰富的、未知的、有用的知识,对图书馆决策、管理及应用是非常有价值的。而目前图书馆自动化系统一般只用来做一些常规的业务数据统计,无法发现这些数据中存在的关系和规则,无法预测读者的信息需求,更缺乏对大量的统计数据中隐含的关联的归纳、分析与揭示,使图书馆对读者信息需求和文献利用的捕获停留在比较浅显的层面,这就需要我们通过挖掘读者信息需求、文献利用的分类的聚合、读者分类、需求聚类等数据,寻找各学科及不同学科层次之间的一些相互关联的知识,以辅助图书馆的决策,优化图书馆的馆藏布局;通过挖掘读者年龄、性别、学历、学科背景、职业等属性来发现不同的读者群对不同类别文献的借阅模式和兴趣规则,据此可以更好地提供个性化信息服务。
2.1 图书馆管理决策方面的应用
2.1.1 分析读者的利用与需求,提升图书馆服务与管理
(1)通过对读者借阅次数和图书借阅频率数据的挖掘,每月出一个图书借阅排行榜和读者借阅次数排行榜。对排在前十位的图书重点介绍和推介。对排在前十位的读者,可剖析其所借阅书籍类别,提高读者导读的效果,从而提高图书利用率,引导读者阅读趋向,以保持他们的借阅忠诚度。
(2)由于读者最大借阅册数和借阅周期一般是根据读者的身份特征设定的,这就会使得不同借阅需求读者的资源分配不均,可通过聚类分析方法(如采用k-means算法)对读者在某个时间段的借阅次数进行聚类计算,将聚类结果存储在读者聚类结果表中,一方面可以了解读者对图书馆服务的使用程度,另一方面也可以根据读者的使用情况划分读者群,针对不同的读者群采取不同的服务措施,可按照读者的聚类结果定期调整读者的最大借阅次数和借阅周期,以满足不同读者群的需求,充分利用馆藏资源,为他们提供主动的推荐服务。
(3)通过时间序列分析挖掘出借阅流通量的周期性规律,特别是年、季、月、星期、小时等不同时间特性的不同读者群的借阅量规律,找出读者在各种不同的时期里,使用图书馆的状况,了解读者需求,从而进一步分析读者借阅书籍的高峰期和低谷期,籍此可以在人力、财力资源有限的情况下,为流通部门日常工作的安排提供科学合理的参考数据,为读者提供更多更优质的服务。在此基础上还可加入文献类别的分析,利用聚类分析,来探讨时间与文献间的关系,从而了解到读者借阅的喜好,并可在热门时段作强力图书推荐或在借阅冷清时段作积极的推销。
2.1.2 获取文献利用状况,优化馆藏布局
(1)通过对流通记录、opac检索请求及馆藏书目库进行分析与挖掘,按文献类别统计文献拒借集、频繁借阅集、文献利用率,并对读者借阅的文献进行关联、聚类分析,挖掘出读者对文献的借阅兴趣、借阅需求,了解文献的受欢迎程度,提高文献的利用率,综合本馆的资源和现有需求量调整采购策略,从而有针对性地补充、丰富、优化馆藏资源,对馆藏文献的调整和资金的合理分配具有实际意义。
(2)通过对文献被借阅次数(总借阅统计次数和当前年被借阅情况)的聚类分析,挖掘出馆藏文献的利用情况,可对借阅频率较高且连续续借的书目,以量化方式反馈给采访部门以加大采访力度。
(3)通过对读者的聚类分析,找出不同读者群间不同的借阅行为,分析其可能存在的阅读倾向,并以概率的形式体现,同时可挖掘出每个读者群间普遍出现的文献类别,分析其所代表的意义,把此作为图书采购的参考依据,以供相关部门决策。
2.2 获取读者需求信息,提供个性化服务
(1)读者需求信息挖掘是一种主动获取不同读者群兴趣模式的方法。通过分类、聚类分析方法,根据不同读者的特征及借阅记录,对读者群体按照年龄、学历、学科背景、职业等属性进行分类,把读者进行群体细分,挖掘出不同读者群体间借阅兴趣的相似性和相异性,找出各类特性的读者群对图书的兴趣需求模式,建立模式之后,该类别其他读者借阅或关注过的文献或者同类别新到的文献,可按照此模式主动推荐给有该特性的读者,实现主动的信息推荐服务。
(2)同时对文献资源进行关联规则分析,寻找读者借阅图书的潜在规律,挖掘出相互之间有密切关系的文献,并找出读者个人特征与文献之间的关联性,进一步了解读者的借阅兴趣及需求,当读者使用其中一个资源时,可将其他相关资源推荐给读者;当有新的文献进馆,可根据该文献的类别,将其推荐给相应类别的读者,自动实现根据读者借阅情况,主动为其提供相关文献的功能,从而能够在个性化服务方面得以实际的应用。在挖掘文献间的关联性时,由于读者的阅读兴趣往往与他的专业相关,不仅要寻找那些借阅频率较高的图书间的关联性(不进行分类的挖掘),还应该对图书进行分类(可根据中图法)的关联规则挖掘,找到同类图书之间的关联性。
(3)读者借阅馆藏可能会先借入门的再借深入的,通过序列模式可挖掘不同读者群体借阅馆藏文献的时间顺序特性,当某一读者群借阅某类文献时,主动向该类读者群推荐具有时间顺序特性的相关类别的后续文献。
3 结 语
随着信息时代数字化、网络化的飞速发展和应用,如何从数据的汪洋大海中及时发现有用的知识,已成为数字化时代图书馆信息管理服务向智能化和服务多元化方向发展所必须面对的问题。因此,变被动服务为主动服务,主动通过聚类、分类、关联规则及序列模式等挖掘技术寻找不同读者群对不同类别书籍的借阅兴趣规则、借阅习惯、需求和倾向等,研究各学科专业的馆藏资源利用、老化程度、经费投入情况,发现各学科领域间、不同读者群潜在需求的知识关联,无疑对图书馆管理与服务向知识服务的层面发展起到很好的指导作用,它不仅是形成最大限度满足读者需求的文献保障体系的重要依据,也是图书馆开展以读者需求为导向的各项智能化个性服务工作的基础。
参考文献
[1]司徒浩臻.数据挖掘技术在图书馆信息服务中的应用[J].现代图书情报技术,2005,(10):15-18.
[2]罗可,蔡碧野,吴一帆,等.数据挖掘中聚类的研究[J].计算机工程与应用,2003,(20):182-184,218.
[3]刘文科.数据挖掘在高校图书馆读者管理中的应用[J].科技情报开发与经济,2007,16(8):67-68.
[4]李玮平.基于数据挖掘的图书馆读者需求分析[J].图书馆论坛,2004,24(3):86-88.
猜你喜欢
电力与能源(2017年6期)2017-05-14
科技传播(2016年22期)2017-03-01
河南图书馆学刊(2016年12期)2017-01-09
河南图书馆学刊(2016年12期)2017-01-09
考试周刊(2016年83期)2016-10-31
信息通信技术(2015年6期)2015-12-26
电子设计工程(2014年18期)2014-02-27
