
一种基于汉维对齐的双语语料库的获取方法
2011-06-05 03:19玛依拉艾尼扎提胡学钢
合肥工业大学学报(自然科学版) 2011年11期
玛依拉·艾尼扎提, 胡学钢
(1.合肥工业大学 计算机与信息学院,安徽 合肥 230009;2.新疆轻工业职业技术学院 计算机系,新疆 乌鲁木齐 830021)
0 引言
新疆维吾尔自治区是多民族的地区,其中维吾尔族人口有926万,占总人口的46%。随着信息化的不断发展,积聚了大量的知识,然而这些知识和信息主要以英语和汉语为载体,极大地影响了维吾尔语言使用者的学习,造成汉维群众交流困难及一系列的社会和政治问题。另一方面,随着少数民族语言信息处理技术的兴起,维吾尔语信息处理技术经过20多年的发展已取得一定成果,如维文操作系统、维文办公软件等。但是,针对自然语言处理中的一些基础性的课题,如语言分析、词性标注、对齐、自动获取等研究相对较少,极大地制约了维文分析的发展。因而,本文研究维吾尔文的语料库获取问题,对机器翻译、双语词典的编纂、自动问答、信息检索、信息抽取等领域[4]的研究具有重要价值[1-4]。
双语语料库是包含2种语言互译信息的特殊的语料库,能够提供2种语言之间的匹配信息,在翻译知识获取、双语词典建立、基于实例的机器翻译、词义消歧等领域有着重要的应用价值。大规模双语语料库的建设是进行基于语料库研究的基础;而目前互联网上存在着丰富的双语资源,为短期内建成大规模的双语语料库提供了可能。
目前,双语语料库的研究主要围绕汉英双语展开[5-6],其中对齐技术是普遍采用的一种方法[7-8]。然而,关于维文和其他少数民族语言的研究相对较少[9-11]。为此,本文在研究汉语文本分析技术的基础上,结合维吾尔语词的特点,在进行了分词、词性标注的基础上,通过汉维的文本对齐,提出了一种双语语料库的构建方法。
1 汉维双语语料库的构建
本文基于汉维对齐方法,提出一种汉维双语语料库的构建方法,该方法主要分以下几个步骤,首先针对维文进行词干提取、词性标注,在此基础上,对汉维文本进行对齐,最后基于对齐方法由已有的汉文语料库构建维文语料库,其原理如图1所示。

图1 对齐语料自动获取原理
1.1 维文的词干提取
维吾尔语中词切分包括音节切分、词根切分和词干切分,本文主要采用词干切分。所谓词干就是指维吾尔语文本中的表示完整词汇意义的整体,维文中词干提取包括2个步骤:从维文中提取出词,并去除词中的构形附加成分;将去除了构形附加成分的部分还原为词典中的原形词。
(1)词干切分方法。由于维吾尔语中有很多构词附加成分构成新词的能力很强,所以有很多词干加了构词附加成分以后构成了其他的词干。如“书加了构词附加成分以后构成了“图书馆”。在切分词干时,由于有这样的词干同时存在,所以在切分时存在多种切分形式,因此本文中采取全切分方法,即列举所有可能的切分形式。具体方法为:从维吾尔语单词的右边起,与词干表进行匹配,从而找到词干的候选边界,如图2所示。

图2 词干切分方法
图2中,通过边界将单词划分为2部分,右侧setm表示从词右边切分出的候选词干,左侧是切除了词干后的构形附加成分。
(2)词干还原。维文中,尤其是在书面语中,词干原形加了构形附加成分以后,会发生辅音增加、元音弱化、元音脱落等情况,导致找不到完全匹配的词干,为此必须进行词干还原。
下面详细解释各种不同情况的处理办法:① 辅音增加,词干表中的词干+辅音,并且该词干以元音结尾时,删除词干后的辅音进行词干还原;② 元音弱化,当待切分词失配的位置为,且词干中对应位置为时,对待切分词进行音节切分,当所在的音节为开音节,则将用替换;③ 元音脱落,当失配的位置为词干的第2个元音(该元音为),且该元音以后位置上的字母与待切分词串从该元音位置开始的字母都相同,则将插入待切分词中的相应位置。
1.2 维文的词性标注
本文中维语词性标注方法遵循以下几个规则:以“.”为标志读取一个句子;句子划分后,按空格读取词汇;对每个词进行语料库中的现成词的比较,若该词汇在语料库中不存在,则认为是生词,不进行标注,将其作为生词插入到当前语料库中。
具体词性标注过程算法描述如下:

上述算法描述中有2个关键函数firstTagging和Viterbi,下面分别对其进行说明。
(1)first Tagging。表示对词干进行初始词性标注,其具体步骤描述为:① 将该词干在词干表中进行查询;②若该词干在词干表中的词性唯一,则该词干的词性唯一确定;否则将这些词性作为候选词;③ 若词干为未登录词,则查询词干表中的附加成分来确定词干的候选词性。
(2)Viertbi。该算法是一种基于句子的词性标注算法,它通过为每个句子选取一个最可能的标记串来完成对整个句子的词性标注;该算法采用动态规划方法,通过计算词性状态序列对观察序列的后验概率,保留概率最大的路径,并在每个状态节点记录下相应的状态信息以便最快获取词性序列。
Viterbi算法是词性标注系统中的重要算法。假定有N个词性标记,给定词串中有M个词。考虑最坏的情况,扫描到每一个词时从当前词前面一个词的各个词性标记(N个)到当前词的各个词性标记(N个),有N2条路径,扫描完整个词串(长度为M),计算次数为M个N2相加,即对于确定的词性标注系统而言,N是确定的,因此随着M长度的增加,计算时间以线性方式增长。也就是说,Viterbi算法的计算复杂性是线性的,因而算法的时间开销随着约束长度的增加而增加。
在本文维吾尔语词性标注的应用中,为了缩短约束长度N,将词性明确的词作为含有兼类词或者未登录词的子词串的边界,即将一个句子分为若干个边界词性确定的子句,分别计算词性概率最大的标记串。该方法减少了需要搜索的路径,因而降低了Viterbi算法的时间复杂度。
1.3 汉维文的对齐
双语语料库是一种包含2种语言互译信息的特殊的语料库,对齐技术是加工双语文本的核心。
定义1 对齐就是从互译的不同语言文本中找出互译片断的过程,双语语料库对齐可分为段落、句子、短语、单词等不同级别的加工深度,语料库的加工深度决定了语料库所能提供的知识的粒度。
定义2 锚点的作用就是将整个语料库分成一些小的对齐片断;同时把每一对相对应的句子称作句珠(Sentence bead)。
通过汉维词汇对之间的特征比较,已有的研究首先对汉语句子进行分词,找到可以用于汉维语料库分段的锚点词汇对,并在此基础上通过锚点词所在句子的匹配获得锚点句子对来进行分段。但是这种方法仅适合于具有较多高频固定词的双语文本的分段对齐,对于高频固定词较少的双语文本,该方法则会出现由于数据稀疏问题导致分段太粗及准确率下降。然而现实中,尤其是网络上的文本数据,90%以上段落并不对应或者没有明显的段落标记,从而使得自然段的对齐比较困难,并且分段太粗,因此针对这种情况有必要进行重新分段。本文提出将2篇互译的双语文本各看成一个整体,对文本中段落进行重新组合后对齐。
例1 睡觉了:/r睡觉/v了/y,

例2 他 去 医 院 了:他/r 去/v 医 院/n了/y,

由上述例子可以看出,对一个双语平行文本的段落对齐,就是要找出2种语言文本中段落之间的对应关系,那么对齐后的文本就表现为具有相等段落总数的互译组块序列。其中,r表示代词,v表示动词,n表示名词。针对汉维语言的特点,本文针对对齐过程中句子顺序不一致的问题,总结出汉维对齐的部分规则,见表1所列。

表1 句子顺序不一致性的规则
2 实验系统
基于上述方法,本文使用C#实现了汉维双语语料库的自动获取系统,该原型系统流程描述如图3所示。

图3 实验原型系统流程示意图
文本分析结果如图4所示,维文语料库的获取如图5所示。
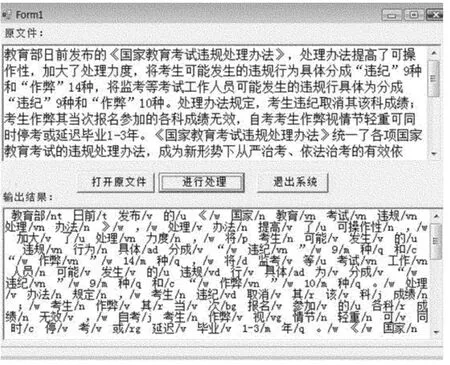
图4 汉维对齐的文本分析结果

图5 汉维对齐语料测试
3 结束语
本文主要探索了利用对齐技术构建汉维双语语料库的方法,首先对汉维文本分别进行分词和词性标注,在此基础上通过实际文本对照分析,建立汉维2个语料之间的规则,利用这些规则建立2个语言的对齐语料。此外,基于上述方法实现了汉维双语语料库的自动获取系统。
[1]Dolan W B,Pinkham J,Richardson S D.NSR-MT:the Microsoft research machine translation system [C]//American Massage Therapy Association,2002:237-239.
[2]Wu D,Xia X.Large scale automatic extraction of an English-Chinese translation lexicon[J].Machine Translation,1995,9(3/4):285-313.
[3]韩晓东,王晓博,刘 超.中文文档与源代码间关联关系提取方法的研究[J].合肥工业大学学报:自然科学版,2010,33(2):188-192,207.
[4]Fattah M A,Ren F,Shingo K.Adaptive threshold parameters for bilingual dictionary extraction from the Internet archive[J].International Journal Information,2005,8(1):165-175.
[5]王占军,姚卫东.一种汉英双语句子自动对齐算法[J].计算机仿真,2009,26(2):329-333.
[6]钱丽萍,赵铁军,杨沫昀,等.基于译文的英汉双语句子自动
对齐[J].小型微型计算机系统,2001,22(1):123-125.[7]刘 昕,周 明,朱胜火,等.基于自动抽取词汇信息的双语句子对齐[J].计算机学报,1998,21(Z1):151-161.
[8]李维刚,刘 挺,张 宇,等.基于长度和位置信息的双语句子对 齐 方 法 [J].哈 尔 滨 工 业 大 学 学 报,2006,38(5):689-694.
[9]热西旦·塔依,吐尔根·依布拉音.汉文-维吾尔文双语语料库中基于词典译文的句子对齐方法研究[J].新疆大学学报:自然科学版,2009,26(3):359-363.
[10]田生伟,吐尔根·依布拉音,禹 龙,等.多策略汉维句子对齐[J].计算机科学,2010,37(4):215-219.
[11]热西旦·塔依,吐尔根·依布拉音.汉文-维吾尔文双语语料库中段落对齐技术研究[J].新疆大学学报:自然科学版,2010,27(1):102-105.
猜你喜欢
书香两岸(2020年3期)2020-06-29
天津外国语大学学报(2020年1期)2020-03-25
计算机工程与应用(2018年19期)2018-10-16
语言与翻译(2015年4期)2015-07-18
新晨(2013年7期)2014-09-29
新晨(2013年5期)2014-09-29
新晨(2013年10期)2014-09-29
民族古籍研究(2012年0期)2012-10-27
当代外语研究(2010年3期)2010-03-20
小学生·多元智能大王(2006年1期)2006-01-18
