
一种海量分布式数据Top-k查询算法*
2013-05-08 13:40魏贤全郑洪源丁秋林
计算机工程与科学 2013年10期
魏贤全,郑洪源,丁秋林
(南京航空航天大学计算机科学与技术学院,江苏 南京210016)
1 引言
近年来,随着云计算和数据密集型运算领域迅速发展,数据处理规模不断扩大,为分布式环境下Top-k查询带来了新的挑战,如何在海量分布式数据中实现Top-k查询成为了研究的热点。Top-k查询是一种十分重要的查询操作,广泛应用于网络和系统监控、证券分析、网络日志分析等领域。这些应用均产生了海量数据,这些数据通常分散在各地的网络节点,Top-k查询的目的是在大量的数据中找出用户最为关心的k个值。例如,通过谷歌搜索“Top-k”,返回结果约有 3 680 000 000条。为了使用户有良好的使用体验,搜索引擎系统需能够快速地返回评分结果最高的前k个查询结果。
目前,针对分布式数据的Top-k查询存在多种算法,例如最被广泛认可的是TA(Threshold Algorithm)算法[1~3],但是TA算法通常适用于集中式网络,如传统的针对数据库的应用程序。当应用于大型分布式网络的时候,由于TA算法中数据交换的次数不能预先确定,往往会带来大量的带宽消耗。因此,第一个适用于分布式网络环境并且拥有固定交换次数的算法 TPUT(Three-Phase Uniform-Threshold algorithm)[4]被 提 出。TPUT 算法在很大程度上减少了网络的存取代价,但TPUT算法的效率是建立在假设各节点数据具有相同的分布性的基础上,对于实际的分布式系统效率则可能较低。KLEE算法[4]给出了分布式环境下的Top-k算法的框架,它允许在效率和结果质量之间做出权衡取舍,但是KLEE得到的仅仅是Top-k查询的近似结果。文献[5]给出了动态分布式环境下的Top-k查询计算方法,该算法主要从网络拓扑的角度提高了查询的效率,但没有充分考虑各节点的数据分布,网络传输总量仍然较高。文献[6~8]讨论了分布式环境下基于skyline的Top-k查询以及传感器网络的Top-k查询。文献[9]对 TPUT算法进行了改进,提出了 TPOR(Three-Phase Object-Ranking algorithm)和 HT(Hybrid-Threshold algorithm)算法。TPOR算法采用传输对象的排名取代传输对象的数值,在一定程度上避免了单一节点传输数据量过大的问题,但是若各节点排名相差较大时,效率比TPUT更差。HT算法结合了TPOR和TPUT两种算法的优点,但是由于没有考虑数据分布情况以及存在阈值计算粗糙的缺点,应用于实际情况时往往仍有很大的网络消耗。
鉴于现有算法的不足,本文提出了适用于海量分布式数据的Top-k查询新算法ECHT(Early-Clipping Histogram-Threshold algorithm)。该算法的主要优势有以下几点:(1)采用改进限定误差直方图描述各节点数据分布情况,改善了同类算法数据分布不均时Top-k查询低效问题。(2)引入了早裁剪思想,在大量数据对传输之前,结合改进限定误差直方图和数据排名提前进行数据裁剪,从而大量减少网络带宽消耗。(3)改进的阈值计算方法提高了阈值估算精度,进一步降低了网络带宽消耗。实验表明,ECHT算法在网络带宽消耗和网络响应时间方面均优于其他同类算法。
2 问题描述
分布式环境下Top-k查询的定义如下:假设分布式网络中有(m+1)个节点,其中有一个中心节点N0和m 个节点N1,N2,…,Nm。N1,N2,…,Nm均和中心节点N0相连,每个节点Ni存储的是形如 〈x,vi(x)〉的数据序列,其中x表示对象的标识符,vi(x)表示对象x在节点Ni的属性值,各节点按照vi(x)属性值大小降序排列。每个节点的数据对象存在重叠但又不完全相同,如果对象y不出现在节点Ni,则定义vi(y)=0。
假定所有对象的数据集为U = {O1,O2,…,On},对于对象Oi,令vij(y)表示对象Oi在节点Nj的属性值。令Vi为对象Oi在中心节点N0的聚集值,即对象Oi的评分。则:
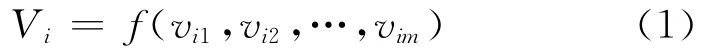
其中,f通常是连续的严格单调函数。Top-k查询的目标就是返回所有对象中评分最高的k个对象作为查询的结果,为了讨论方便,本文采用聚集函数作为求和函数。
在分布式环境下,Top-k查询的目标是用最少的带宽消耗查找出最高评分的k个对象,由于目前在实际的分布式网络环境下,带宽和传输速度相对于时间仍然是主要瓶颈,所以为了简化问题的分析,假设在每个节点的计算成本可以忽略不计而节点间的通信开销就是查询响应时间。因此,本文以网络中传输〈object,Score〉对的数目作为算法表现的判别标准,因为其消耗了绝大部分带宽。
3 ECHT算法
本节主要介绍基于改进限定误差直方图和早裁剪思想的Top-k查询新算法ECHT,首先介绍数据分布的描述方法,给出改进限定误差直方图形式化描述,设计直方图信息的存储结构,并简要说明选用改进限定误差直方图描述数据分布的原因及优势;之后介绍早裁剪算法,简要论证ECHT算法的查询结果是Top-k查询的准确结果;最后给出了ECHT算法的详细步骤。
3.1 改进限定误差直方图
限定误差直方图[10]的相关定义如下:
设U = {O1,O2,…,On}是由n个对象组成的对象集,A = {a1,a2,…,am}是U 的属性集,为了讨论方便,假设A中每个元素的值域为整数,取值介于Min和Max之间(包含Min和Max)。节点Ni的数据存储形式为数值对〈Oi,Ai〉。我们用二元组集合 T = {〈a1,v1〉,〈a2,v2〉,…〈am,vm〉}来表示对象的数值分布。这里,vi表示U中属性值
T上的直方图H定义如下:

定义2 (限定误差为Const的直方图)对直方图H,Const是一个给定的常数,作为额定误差。对任意的a和b,a∈A,b∈A,a≤b,对范围查询t,t.A≥a∧t.A≤b,有|r-r′|≤Const,这里的r和r′分别是查询结果大小的准确值和估计值,则称H是支持范围查询时限定误差为Const的直方图。
文献[10]中给出了采用直方极差生成限定误差直方图的算法(以下简称算法1),但是该算法生成直方数较多,因此我们提出了改进的限定误差直方图,该直方图生成算法具体描述如下:
算法2 一遍扫描二元组集合T上的元组,在生成每一个直方时,记住所遇到的最大值Max和最小值Min(当开始一个新直方时,将vi当作Max和Min的值)。接着计算直方hj的中位数vmid(hj)并将新的vi值与Max、Min比较,若|vmid(hj)-Min|>Const,或若|vmid(hj)-Max|>Const,结束本直方。与该vi值相对应的ai不包含在该直方内。若vi>Max,则将vi作为新的Max值;若vi<Min,则将vi作为新的Min值。
算法可在O(n)时间内完成,n为对象集U 中对象的个数。
相对于算法1,改进算法提高了数据分布不均的适用性,并且很容易可以证出,算法2生成的限定误差为Const的直方数不多于算法1生成的限定误差为Const的直方数。
3.2 直方图信息存储结构
在ECHT算法中,每个节点需要保存对应的直方图信息,对于改进的限定误差直方图。直方图的第i个单元保存的信息包括:
(1)直方的上界值和下界值:UVi和LVi;
(2)对象名列表name_list[i]压缩数据。
定义1 (直方图)定义T上的直方图H 是一个三元组集合 {hi= (asi,ati,ani),1≤i≤m},其中 [asi,ati](1≤i≤m)是属性A 的子区间,ani表示落入该区间的元组的总个数。Hi称为直方图的一个直方或桶,m是直方图H 所包含的直方数。H必须满足如下三个条件:
为了进一步优化直方图的存储、缩短直方图估值的查询时间,采用Bloom filter压缩存储对象名列表,Bloom filter是一种多哈希函数映射的快速查找算法,能够快速判断某个元素是否在一个集合内。ECHT算法采用Bloom filter目的是快速判断出对象x的取值范围v(x)。
利用改进的限定误差直方图和Bloom filter表可以快速判断元素x的取值范围 [lv(x),uv(x)],并保证估值的误差小于Const(Const为常数)。鉴于这两种数据结构的特点,确保该算法能够满足不同数据分布情况下Top-k查询的要求,并降低网络传输的数据量,这对Top-k查询提供了很大的帮助。由于限定误差直方图是事先构造好的,所以构造直方图和相应的Bloom filter表的时间可以忽略,本文只考虑传输直方图信息所带来的带宽消耗。为了进一步降低带宽消耗,中心节点N0预先存储子节点的部分直方图信息,并采用LRU策略(最近最少使用策略)维护中心节点存储的直方图信息,从而保证时间与空间的良好平衡
3.3 早裁剪算法
同类别的分布式Top-k查询算法,包括TA、TPUT、TPOR、HT等算法,不能满足不同数据分布的要求,并且数据传输量较大,为了避免此类算法的不足,本文提出了一种早裁剪算法。该算法旨在传输大量〈object,Score〉数据对前进行数据的裁剪,算法的优势主要体现在以下三个方面:(1)通过限定误差直方图的信息估计对象的数值下界,提升了阈值计算的精确度,减少了大量无用数据的传输;(2)采用早裁剪思想,ECHT算法的第二步采用传输数据对象列表的方式,数据总中心结合限定误差直方图信息计算列表中对象的上下界,并根据数值上下界提前裁剪无用的对象;(3)子节点维护已上传数据对象信息,从而避免对象值重复上传到中心节点,进一步降低了网络数据传送量。以下从两个方面介绍早裁剪算法:
(1)确定阈值τ1和τ2。
早裁剪算法提高了阈值计算的精确度,该算法中阈值τ1和τ2的确定方法类似,算法初始阶段,各节点将排名靠前的k个对象及其得分发送到中心节点,中心节点根据对象得分和直方图信息估算其总分。例 如,对 象 O 的 估 计 得 分S′(O)=f(S′1(O),S′2(O),…,S′m(O)),为了讨论方便,f选用求和函数,则对象O的估计得分为:
S′(O)=S′1(O)+S′2(O)+ … +S′m(O))(2)
若对象O在子节点i的得分已上传,则S′(O)=Si(O);否则,在直方图的name_list列表查找其所在直方的下界LVi,若找到S′i(O)=LVi,否则S′i(O)=0。假设估计得分排名第k的估计值(即下界值)为Tl,则有:

用同样方法可确定τ2。阈值确定引入了限定误差直方图信息,假设对象O的真实得分为S(O),则其估计值S′(O)与实际值S(O)满足关系|S(O)-S′(O)|<m*Const,通常情况下估计值与真实值的误差远远小于m*Const,从而大大提高了阈值的计算精度。
(2)数据早裁剪规则。
ECHT算法的第二步将阈值τ1以及排名靠前的k个对象列表发送到m 个节点,子节点根据接收到的阈值τ1和k个对象列表,确定需要上传到数据中心的对象。对象确定方法与HT算法类似,具体可参考文献[9],不同的是ECHT算法在确定需要上传到数据中心的对象后,没有将对象数值传送到中心节点,而是将需要传输的对象列表采用Bloom filter压缩并发送到中心节点,避免了数据对盲目上传带来的大量网络开销。中心节点计算各节点发送的对象的下界,并对下界值进行排序,假设排名第k的下界值为EVk,对于排名在k以后的对象,计算其对象上界,对象O的上界值U′(O)的计算方法如下:
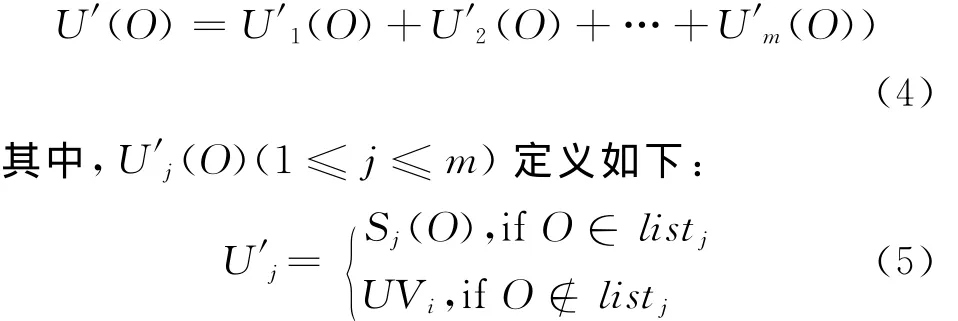
其中,UVi为对象O所在直方的上界值,listj是第j个节点已经上传属性值的对象列表。
假设m个节点共上传的对象集为U,数据裁剪的目的即找出这样的对象集D,使得D中的每个对象都不可能存在于Top-k查询的结果集。对象集D的判定方法如下:

由上述规则即可得到无需上传的对象集D,从而避免了大量无用数据值的传输。
3.4 Top-k查询结果准确性分析
ECHT算法返回的结果为准确的Top-k查询结果,而非近似结果,由于Bloom filter结构存在一定的错误率,为了避免其错误率带来的影响,保证ECHT算法结束之后能够得到准确Top-k查询结果,ECHT采用如下方法:
获取裁剪对象集D后,中心节点便可以计算各节点需要上传的对象集Ujnew,结合m个节点已上传的对象列表listj(1≤j≤m),Ujnew采用Bloom filter表压缩并将压缩后的向量和阈值τ2发送到各个节点。Ujnew的定义如下:

ECHT选取对象集Ujnew发送对应的网络节点Nj,Nj选取属性值大于阈值τ2的对象,并判断该对象是否属于数据对象集Ujnew,若属于则将该对象及其属性值发送到中心节点。由于Bloom filter错误率仅存在于误判属于集合,不会把属于这个集合的元素误认为不属于这个集合,因此当ECHT算法中Bloom filter出现误判时,仅仅会产生极少量的冗余传输,而不会产生数据对象数据的漏传,从而巧妙地避免了Bloom filter的错误率问题,确保了返回的Top-k结果的正确性。
3.5 ECHT算法步骤
本节主要介绍ECHT算法的具体步骤,ECHT算法引入了改进的限定误差直方图,使得算法能够满足不同数据分布的要求,另一方面提高了阈值的计算精度,结合早裁剪算法思想,进一步提高了算法的高效性。ECHT算法的具体步骤如下:
(1)中心节点发送Top-k请求,每个节点将排名靠前的k个对象发送到中心节点,中心节点结合本地存储的各节点直方图信息计算所有对象的数值下界集合(S′)(集合(S′)的计算方法参照公式(2))。中心节点获取排名靠前的k个对象,根据公式(3)计算得到阈值τ1,然后将对象列表和τ1发送到各个本地节点。
(2)本地节点收到阈值τ1和对象列表后,计算对象列表中各对象的属性值,并取最小的属性值Pmin。若Pmin≥τ1,将属性值大于Pmin的对象列表及少量直方图信息发送到中心节点;否则将属性值大于τ1的对象列表发送到中心节点。中心节点收到各节点发送的对象列表,根据早剪切算法,获取裁剪对象集D,并计算各节点需要上传的数据对象集Ujnew(Uj的计算方法参照公式(6))。中心节点将对象集Ujnew采用Bloom filter算法压缩为向量btj并与τ2并发送到本地节点。
(3)本地节点收到向量btj和τ2,将属性值大于τ2的对象采用向量btj判断是否属于对象集,若属于,则将该对象及其属性发送到中心节点,否则不发送。数据中心收到各个节点发送的数据后,重新计算各个对象下界,并计算下界排名第k的对象的总得分τ3,中心节点计算已访问对象的上界(参考公式(4))并裁剪上界值小于τ3的对象,从而获得候选集S。
(4)中心节点将候选集S发送到各个节点,节点将尚未发送的对象的得分值发送到中心节点。中心节点重新计算S中对象的局部聚集值,然后输出局部聚集值最高的前k个对象,即为Top-k查询的结果。
4 实验与分析
本节通过实验评价ECHT算法的性能,并与同类TPUT算法、HT算法、KLEE算法进行比较。实验没有比较TA算法,是因为TPUT、HT等算法在绝大部分情况下的表现好于TA算法。KLEE是高效率的算法,但其效率是建立在损失部分正确率的基础上的,在实验中,我们只考虑其效率,忽略该算法的错误率。
实验中,我们选择9台普通PC机作为实验环境,分别编号为PC0~PC8。PC机的配置:CPU为 Pentium(R)Dual-Core E5800,主 频 为 3.20 GHz,内存为2GB,硬盘为320GB,操作系统为Windows XP,模拟程序由Java编写。这里我们使用PC0作为中心节点,PC1~PC8作为普通节点。
实验选用的数据集是实际应用的数据集,数据集的内容是某海事局2012年全年一百余艘船舶机舱监控数据,数据量为TB级。限定误差直方图的误差常数由数据集极差计算获得,此处Const=10,Bloom filter的PFP <0.004,依次对数据集进行 Top-5、Top-50、Top-100查询,得出的网络带宽消耗和查询响应时间结果如图1和图2所示。
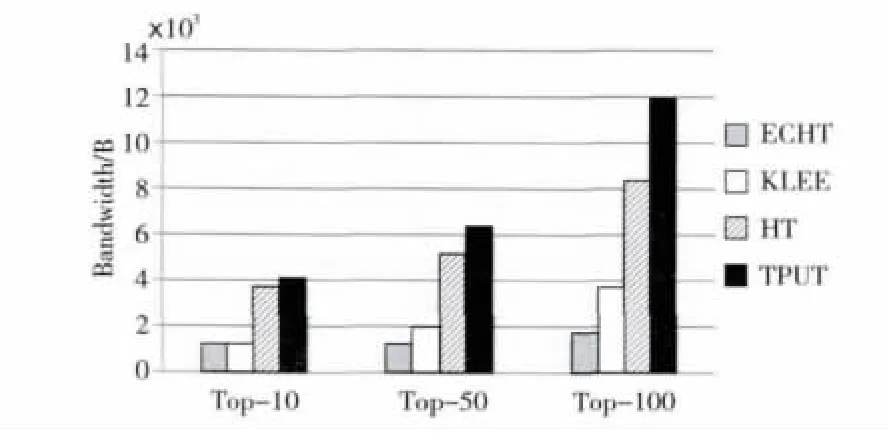
Figure 1 Network bandwidth consumption comparison图1 网络带宽消耗算法比较图

Figure 2 Network response time comparison图2 网络响应时间算法比较图
从图1和图2可以发现,ECHT算法的网络带宽消耗和网络响应时间均优于其他三个算法,随着k的增加,ECHT算法的优势更加明显。通过对三次查询结果的对比发现,ECHT、HT和TPUT算法的Top-k查询结果集相同,ECHT算法的 Top-k 查 询 结 果 为 准 确 Top-k 结 果 集。KLEE算法的结果集为近似Top-k结果集,三次查询的准确度分别为70%、94%和85%。
为了比较各算法对海量数据的处理性能,给出了不同数据量情况下各算法的Top-k查询效率对比,实验数据分别取监控数据集的25%、50%、75%、100%,k=100,实验的对比结果如图3和图4所示。
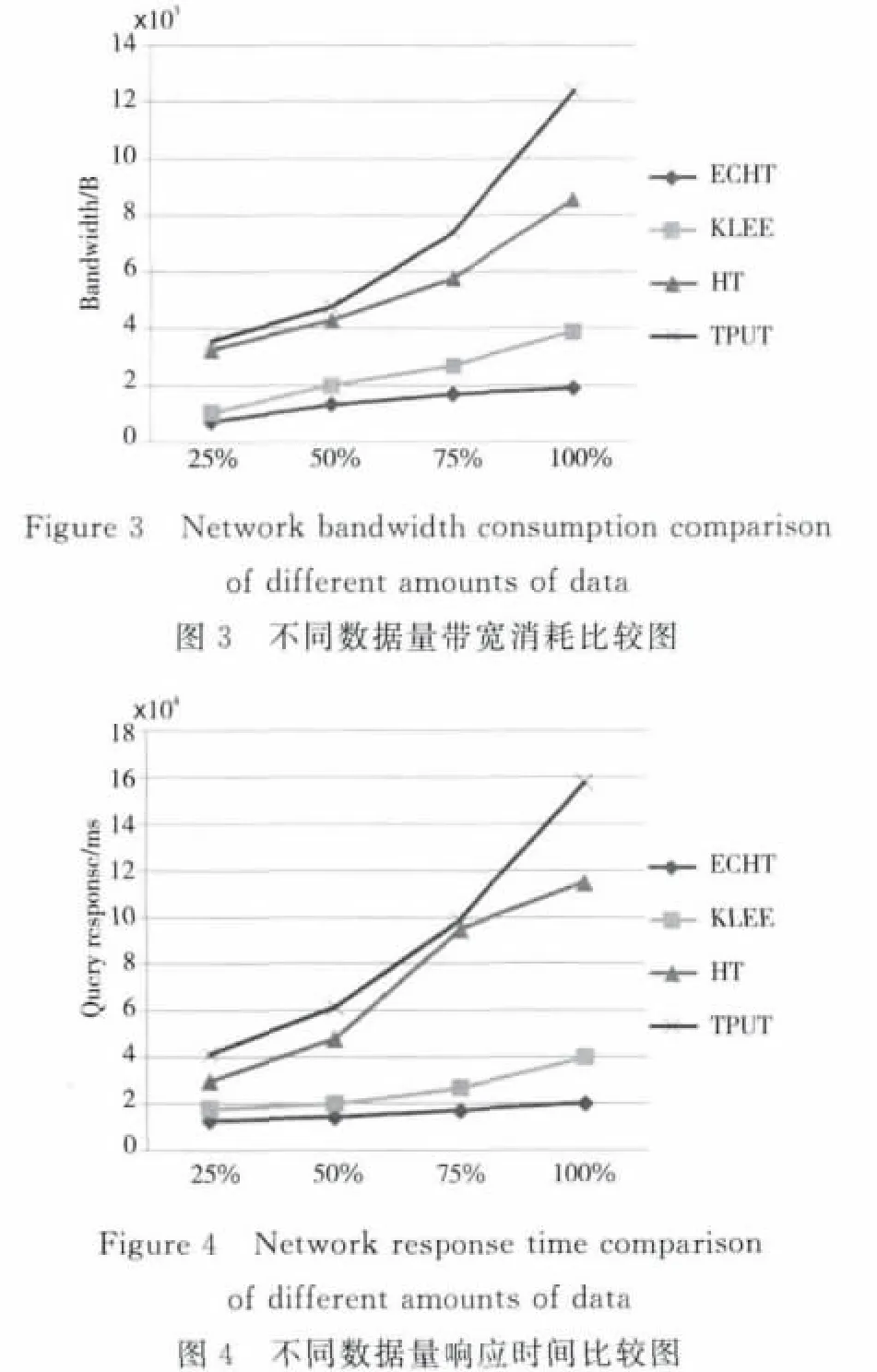
从图3和图4可以看出各算法的性能随数据量变化的情况,随着数据量的增大,ECHT算法的网络带宽消耗和网络响应时间的优势愈加明显。本文数据量从2.5×1010到10×1010条,能够说明算法对于海量数据处理的性能。由图3和图4可见,TPUT算法和HT算法需要大量的随机查询,特别是在海量数据情况下,产生了大量的数据传输和IO延时,算法效率较低,KLEE算法较TPUT和HT算法有优势;而由于ECHT算法的早裁剪和避免重传等机制,算法表现优于KLEE算法,而且随着数据量的增大,ECHT算法的优势愈加明显。
5 结束语
本文提出了一种解决海量数据分布式Top-k查询的新算法,评价该算法的性能标准是低网络带宽消耗和低网络延迟,本文研究的算法已经初步用于某海事局船舶数据采集及管理系统中。实验及初步应用表明,该算法相比同类算法优势明显,具有较好的应用价值。
[1] Pang H H,Ding X,Zheng B.Efficient processing of exact top-kqueries over disk-resident sortedlists[J].VLDB Journal,2010,19(3):437-456.
[2] Arai B,Das G,Gunopulos D,et al.Anytime measures for top-kalgorithms on exact and fuzzy data sets[J].VLDB Journal,2009,18(2):407-427.
[3] Lu W,Chen J,Du X,et al.Efficient top-kapproximate searches against a relation with multiple attributes[J].World Wide Web,2011,14(5-6):573-597.
[4] Neumann T,Bender M,Michel S,et al.Distributed top-k aggregation queries at large[J].Distributed and Parallel Databases,2009,26(1):3-27.
[5] Wang Bin,Yang Xiao-chun,Wang Guo-ren,et al.Top-kquery calculations in dynamic distributed networks[J].Journal of Computer Research and Development,2007,44(S):85-94.(in Chinese)
[6] Vlachou A,Doulkeridis C,Nørvåg K.Distributed top-k query processing by exploiting skyline summaries[J].Distributed and Parallel Databases,2012,30(3-4):239-271.
[7] Chen B,Liang W,Yu J X.Energy-efficient skyline query optimization in wireless sensor networks[J].Wireless Netw-orks,2012,18(8):985-1004.
[8] Cheng J,Liu W,Zhang S,et al.Energy-efficient top-kqurey approach in wireless sensor networks[J].2010,37(11):19-102.(in Chinese)
[9] Yu H,Li H,Wu P,et al.Efficient processing of distributed top-kqueries[C]∥Proc of the 16th International Conference on Database and Expert Systems Applications,2005:65-74.
[10] Ma Yong,Wang Yang.A new histogram method for size estimation of query result[J].Computer Engineering & Application,2004(5):188-190.(in Chinese)
附中文参考文献:
[5] 王斌,杨晓春,王国仁,等.动态的分布式环境下的Top-k查询计算[J].计算机研究与发展,2007,44(S):85-94.
[8] 程捷,刘文予,张胜凯,等.一种高效节能的无线传感器网络 Top-k查询算法[J].计算机科学,2010,37(11):99-102.
[10] 马勇,王焱.一种新的用于估算查询结果大小的直方图方法[J].计算机工程与应用,2004(5):188-190.
猜你喜欢
湘潭大学自然科学学报(2022年2期)2022-07-28
小学生学习指导(中年级)(2021年4期)2021-04-27
课堂内外(初中版)(2020年5期)2020-06-19
摄影之友(影像视觉)(2018年12期)2019-01-28
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
潍坊学院学报(2016年6期)2016-04-18
雷达与对抗(2015年3期)2015-12-09
中学生数理化·中考版(2015年10期)2015-09-10
计算机工程(2015年8期)2015-07-03
