
Cache动态插入策略模型研究*
2013-05-08 13:40石文强倪晓强金作霖张民选
计算机工程与科学 2013年10期
石文强,倪晓强,金作霖,张民选
(国防科学技术大学计算机学院,湖南 长沙410073)
1 引言
近年来,微处理器体系结构已从单核发展为多核。与单核相比,多核的计算能力虽得到极大的提升,但多核中每个计算核心所能得到的存储带宽、存储容量却显著降低,多核的“存储墙”问题变得更加突出。目前,多核处理器普遍采用大容量、高相联度的末级Cache LLC(Last Level Cache)以减少片下访存次数,提升系统整体性能。
多核下,访存序列多样,末级Cache容量、组相联数不断增大,传统的Cache替换算法LRU(Least Recently Used)对 LLC逐渐失效,主要有以下几方面的原因:(1)Cache死块变多:对于某些访存重用性差的程序,部分数据块进入Cache后不会再重用,这样的块称为死块。当组相联度增大后,死块被替换出Cache的时间变长,整个Cache中死块比例增加,Cache的有效利用率变低。Cache预取技术中,也存在类似的死块问题。(2)局部性变差:访存序列经过L1Cache后,到达LLC的访存序列时间局部性降低,而LRU算法利用的就是访存的时间局部性,所以LRU对LLC的效果往往不佳。
针对以上问题,已有大量的相关研究[1~3],解决以上问题的一种思路是改变替换策略的插入策略,即把失效后取回的数据块插入到组内的非MRU(Most Recently Used)位置,这样死块的逐出时间变短,可以提升Cache的有效利用率。但是,目前对插入策略的研究基本都停留在启发式策略的水平上[1~3],缺乏定量的分析及相应的理论优化方法。
针对以上问题,本文提出了一个Cache插入策略的解析模型,该模型以应用的循环序列分布及历史重用信息为输入,使用概率模型迭代计算指定插入策略的失效率,可对不同插入策略的性能进行有效的预测。最后的验证结果表明,模型的精度较高,最大绝对误差为15.6%,平均绝对误差为3.1%。
2 模型定义及假设
首先对Cache中的位置做以下约定。设Cache的组相联度为A,组内A个数据块按物理顺序可依次标记为位置1~位置A,MRU位置在本文中认为是位置1,LRU位置为位置A。组内数据块i是指位于位置i的数据块;数据块i位于数据块j之前是指两者位置有关系i<j。
目前替换策略已具体细化为了三部分[1]:逐出策略、插入策略以及提升策略。逐出策略是指在Cache失效时,如何选择被替换出的块;插入策略即将取回的块置于组内的什么位置;提升策略即命中Cache块后,该块在组内的位置如何变化。本文主要研究Cache插入策略,故假设替换策略中的逐出、提升策略与LRU策略相同,即失效时会将LRU块逐出,命中时会将命中块提升到MRU位置。
为建立Cache插入策略模型,本文引入以下概念[4,5]:
(1)循环序列cseq(Circular Sequence):一个Cache组的访存序列中,数据块B的本次访存与下次访存之间的访存序列(包括B)称为以B为目标块的循环序列。若该序列长度为n,其中不同地址数目为d,则该序列可用cseq(d,n)表示。对于循环序列,由于首尾两次访存必然为B,所以肯定有n≥d+1成立。
(2)子 循 环 序 列 scseq(Sub Circular Sequence):子循环序列是指循环序列cseq(d′,n′)经过n′-n(n<n′)次访存之后剩余的子串,该子串的长度为n,包括d个不同的数据访存,用scseq(d,n)表示。
(3)首次访存 Dis(Distinct):对于cseq(d′,n′)中的某次数据访存,若该地址在cseq(d′,n′)之前的访存中没有出现过,则称本次访存为首次,否则称为非首次 NoDis(None Distinct),cseq(d′,n′)中的d′即循环序列中首次访存的个数。
(4)重用距离(栈距离):若某cseq(d,n)的目标块为B,则B的重用距离为d。若B在整个访存序列中只有一次访存,那么其重用距离为∞。
(5)状 态s(d′,n′,d,n,p):对 于 某cseq(d′,n′),经过一定次数的访存后子循环序列为scseq(d,n),且目标块在组内的位置为p,目标块的当前状态可用s(d′,n′,d,n,p)表示。当只考虑一个cseq(d′,n′)的状态时,s(d′,n′,d,n,p)可简写为s(d,n,p)。
(6)循环序列分布图 CSH(Circular Sequence Histogram):某段时间内应用中所有循环序列出现的频数分布。某些cseq(d,n)中的d值与n值可能会很大,实际统计时,将所有d值大于阈值dmax的归为一类;对于每个d,将n值大于阈值nmax的归为一类。所以,CSH可表示为一个(nmax+1)×(dmax+1)的二维矩阵,CSH(n,d)表示循环序列cseq(n,d)出现的次数。
由于数据访存具有较强的局部性,当dmax与nmax足够大时,处在两阈值之外的循环序列很少,不会对模型的精度产生很大的影响。一般情况下,若Cache组相联度为A,可取dmax=2A,nmax=2dmax。
(7)历史栈距离分布图 HSH(History Stack Histogram):HSH统计了同一块两次访存重用距离之间的转化关系,HSH(d0,d1)表示本次访存栈距离为d1的数据块中上次访存栈距离为d0的比例。HSH与CSH 有相同的最大重用距离阈值dmax,故 HSH 为一个(dmax+1)×(dmax+1)的矩阵。
本文中提升流(Promotion Stream)是指访存命中的数据块组成的数据流;插入流(Insertion Stream)是指访存失效后进入Cache的数据流;动态插入策略是指对于不同的应用,选择不同的插入位置以提高应用性能的替换策略。
3 Cache动态插入模型
本节对Cache的插入策略进行了建模,其中使用了以下符号定义:PP(cseq(d,n))表示提升流循环序列cseq(d,n)的失效率,PI(cseq(d,n))表示插入流循环序列cseq(d,n)的失效率,Pmiss表示插入策略的整体失效率,p0表示插入策略的插入位置,hi表示所有重用距离为i的数据块的命中率,h=[h1,h2,…,hdmax]表示各重用距离命中率的集合,CSHP、CSHI为提升流与插入流的循环序列分布图。
3.1 建模基本步骤
Guo F[4]首次对 Cache的逐出策略进行了理论建模,该模型以访存序列的循环序列分布CSH与替换策略函数为输入,通过递归概率模型来计算各循环序列的失效率,经多次迭代整体失效率Pmiss计算出给定逐出策略的Cache失效率。
插入策略模型与逐出策略模型[4]最主要的不同是:在逐出策略模型下提升流与插入流行为相同,所以只需考虑整体数据流即可;动态插入策略下,提升流与插入流的行为不同,插入策略模型需要分别考虑提升与插入两种数据流。具体而言,有以下两个方面的问题需要解决:
(1)输入获取问题:在逐出策略模型中,其输入与逐出策略无关,所以对于不同的逐出策略可由统一的硬件采样其输入分布情况;而动态插入策略需要掌握不同插入策略下提升流与插入流的重用分布情况,以对相同应用的不同插入策略的性能做出评价,目前已有的采样方法却不能同时获得多种插入策略下输入的分布情况。
(2)两个数据流的相互作用问题:提升流与插入流单个数据流的建模可以采用与逐出策略相似的递归概率计算的方法,但两者之间不是独立的,如何对两者的作用进行建模是本模型需要解决的一个问题。
本文主要通过以下几步对Cache的访存序列进行建模,通过多次迭代计算指定策略的失效率:
(1)获取应用的CSH、HSH分布。
一种应用的CSH与HSH可以通过编译、模拟或在硬件中增加计数器来获得[4,5],本文不对此进行详细讨论。
(2)输入循环序列分布的计算。
在逐出策略模型输入CSH的基础上,本文引入历史栈距离分布HSH、第i次迭代中各重用距离的命中率h(i)来计算不同插入策略下提升流与插入流的循环序列分布。其中,CSH、HSH只与应用相关,可通过硬件采样获得;h(i)与当前插入策略相关,需要通过多次迭代来不断提升其精度。
(3)循环序列失效率的计算。
与逐出模型[4]相似,本文使用了递归概率计算循环序列的失效率。但是,插入模型不仅需要考虑提升流与插入流单个数据流的行为,建模时还需考虑提升流与插入流在Cache中的相互作用。
(4)整体失效率的计算及迭代返回。
计算出整体失效率 Pmiss及h(i+1),判断其是否达到精度要求或达到最大迭代次数,是则停止迭代,否则将h(i+1)返回第(2)步进行下一轮迭代。
3.2 输入访存序列分布的计算
针对不能获得不同插入策略下提升流与插入流重用分布的问题,本文提出可使用循环序列分布CSH、历史栈距离重用分布HSH、动态插入策略下各重用距离的命中率h三种数据来计算各插入点的输入分布情况。
提升流分布可以认为是访存命中的数据块被提升至MRU位置后下次重用时的循环序列分布。若令HSH (d′,d)表示本次重用距离为d′的数据块中上次重用距离为d的数据块的比例,hd为重用距离为d 的数据块的命中率,则hd′·HSH(d′,d)为重用距离为d的数据块中由上次重用距离为d′的数据块在本次转化为提升流的比例。若令rd表示重用距离为d的数据块转化为提升流的比例,则有:

得到rd后,假设对相同的d各个n的命中率相同,CSHP(d,n)为提升流中cseq(d,n)的频数分布情况,则有:得出提升流的分布后,由于CSH对所有策略都不变,只与应用相关,则插入流的重用分布为:
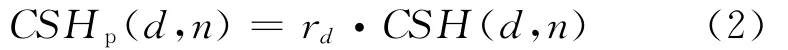
CSHI(d,n)=CSH (d,n)-CSHP(d,n)(3)至此,可以根据CSH、HSH及h得出提升流与插入流的分布情况。
3.3 提升流循环序列的失效模型
单个提升流循环序列PP(cseq(d′,n′))可采用递归概率的方法进行计算,该方法主要由一组状态与相应的状态之间的转化概率组成,从对目标块的第一次访存开始,每次计算一次访存所造成的状态转换及相应的概率,直至构造出完整的cseq(d′,n′),这个构造过程也即数据的访存过程[4]。对于cseq(d′,n′),第i次访存结束后设其状态为s(d,n,p),下次将考虑第i+1次数据访存可能造成的状态转化情况及相应的概率,如图1所示。

Figure 1 State transition of the promote stream图1 提升流的状态转换图
图1 中s(d,n,p)为当前状态,其它状态为下次访存后的状态,状态之间的连线上标记状态转化的条件。图1中共有七种转化情况,可产生四种新的状态。其中,Dis表示访存为首次访存,NoDis表示非首次访存;p<p0表示目标块位置在p0之前,p≥p0表示目标块的位置在p0之后;Miss表示访存失效,Hit表示访存命中;Hit≥p表示命中位置大于或等于p,Hit<p表示命中位置小于p。
图1中,对于状态参数n,每次访存后,子循环序列的长度n必然会减1。对于d,如果此次访存为首次出现,则d减1(情况5、6、7),否则d保持。对于参数p,若目标块位于插入点位置之前(p<p0)时,失效不会使目标块的位置后移,p值不变(情况1、6);NoDis时,若访存命中位于目标块之前时(Hit<p),则目标块的位置也不会受到影响(情况2);除此三种情况外,目标块的位置都会向后移,p值加1。七种情况中,p0的影响体现了插入流与提升流的相互作用,表1给出了各种情况下的状态转移概率。
表1中,PDis表示此次访存为首次的概率,PNoDis,Hit<p表示访存为非首次命中且命中位置在目标块p之前的概率,PNoDis,Hit≥p表示其在p 之后的概率。PDis,Hit表示访存为首次命中的概率。为简化以上四个概率的计算,本文假设循环序列中首次与非首次访存为均匀分布,组内各个位置的访存次数及命中率相同,具体四个概率的计算在此不详细列出。

Table 1 Transition probability in each state表1 各种情况的状态转移概率
在提升流的状态转换图中,存在一些边界情况需要特别考虑。主要有两种:当p>A时,这时表示目标块已经被移出,所以目标块下次访存时其必然失效,若计算其失效率,可直接返回1。当p+d≤A时,此时目标块位于p位置,后继序列中还有d个首次访存,最坏情况下目标块被后移d个位置,但由于p+d≤A,所以目标块仍在组内,此时不会失效,若计算其失效率可直接返回0,表示其肯定命中。
将状态转换图及状态转移概率结合起来,便可以计算某个cseq(d,n)中目标块的失效概率。若S(d,n,p)为scseq(d,n,p)下目标块的失效概率,由图1及表1所示,S(d,n,p)可采用以下递归函数进行计算:
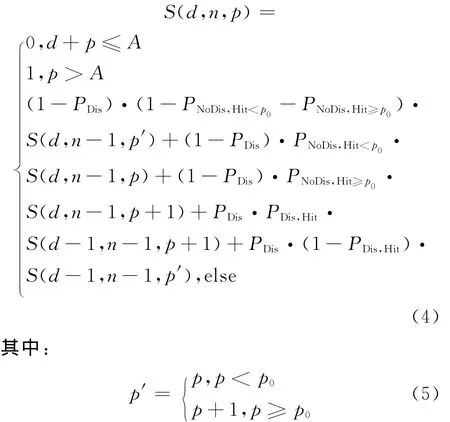
若要计算提升流中某个cseq(d,n)中目标块的失效率,由于该序列的第一个数据地址肯定为目标块且位于1位置,cseq(d,n)中目标块的失效率就等于scseq(d-1,n-1,1)的失效率[4],即:

给定cseq(d,n)后,S(d-1,n-1,1)的计算过程中只有Pmiss为未知量,递归过程中每递归一步,计算中引入Pmiss的阶都为一阶,S(d-1,n-1,1)的最大递归深度为n-1,所以PP(cseq(d,n))是一个以Pmiss为变量的n-1阶多项式[4]。
对于插入流PI(cseq(d,n))的计算,其模型推导过程与PP(cseq(d,n))完全相同,在此不详细列出。
3.4 整体失效率的计算
当获得了每个循环序列的失效率之后,各个重用距离的命中率为:

3.5 使用迭代法求出整体失效率
在模型的第一、二步中,由CSH、HSH及h计算出了提升流分布CSHP与插入流分布CSHI;在模型的第三、四步中以CSHP、CSHI及P(i)miss为输入,使用递归概率模型计算出P(i+1)miss及h(i+1)。而整体失效率Pmiss又可由h、CSH计算得出,所以第三、四步相当于只求出了h(i+1)。综上,模型第一步到第四步相当于以CSH、HSH及h为输入求出了h,可由下式表示:
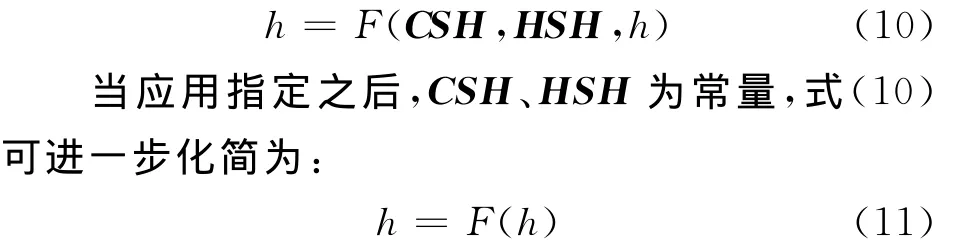
式(11)构成了以h为未知量的dmax元非线性方程组,对于此类非线性方程组,有多种解法,但是这些方法需要求出F的一阶偏导,计算复杂。在本问题中,F为多项式方程组,具有较好的求解性质,可直接采用迭代法求解:

式(12)中,h(i)为第i次迭代求出的解。当迭代达到最大迭代次数或Pmiss达到以下精度要求时,则停止迭代:

式(13)中ε为精度要求,本文取ε=10-4。模型的初始迭代解使用LRU策略下各重用距离的命中率hlru,即:

实际计算表明,模型的收敛速度很快,一般迭代三次以内便可以达到所需精度要求。
4 模型验证
4.1 验证方法
为了对动态插入策略模型的准确度进行验证,本文对全系统模拟器Simics的Cache模块进行了修改,在其中的末级Cache L2上验证了动态插入策略,测试程序采用SPEC2006标准测试集。
对于Cache替换策略模型的评价,一般都采用真实失效率与预测失效率之间的差值作为评价指标,称为绝对误差[4,5]。
对于同一应用,相邻插入点下插入策略的性能相差不大,可以一定的间隔选择插入点位置。本文中,对于不同的组相联度A,选择了1、A/4、A/2、A3/4、A共五个插入点作为插入策略的验证位置。本文在8路512KB与16路1MB两种Cache配置下对五种插入策略进行了验证。
4.2 结果及误差分析
验证结果表明,8路时,平均绝对误差为1.2%,最大绝对误差为10.9%;16路时,平均绝对误差为3.1%,最大绝对误差为15.6%。整体而言,当相联度增大时,预测误差增大。表2为16路配置下SPEC2006各测试程序五种插入策略中预测误差最大的情况,p0表示插入策略的插入位置。
表2中,大部分测试程序最大绝对误差的绝对值小于3%,模型绝对误差较大的情况一般出现在插入点位置靠后的情况。图2为预测误差最大的459.GemsFDTD的预测情况。从图2中可以看出,当插入位置为1、A/4、A/2、A3/4时,模型的预测误差较小。当插入点位置为A时,预测误差达到15.6%,此时误差主要出现在插入点位置后移使应用失效率急剧上升的情况。虽然绝对误差较大,但是模型也能很好地预测出其失效率的迅速增长,说明此插入策略性能较差,但对于指导插入策略的选择已经足够。
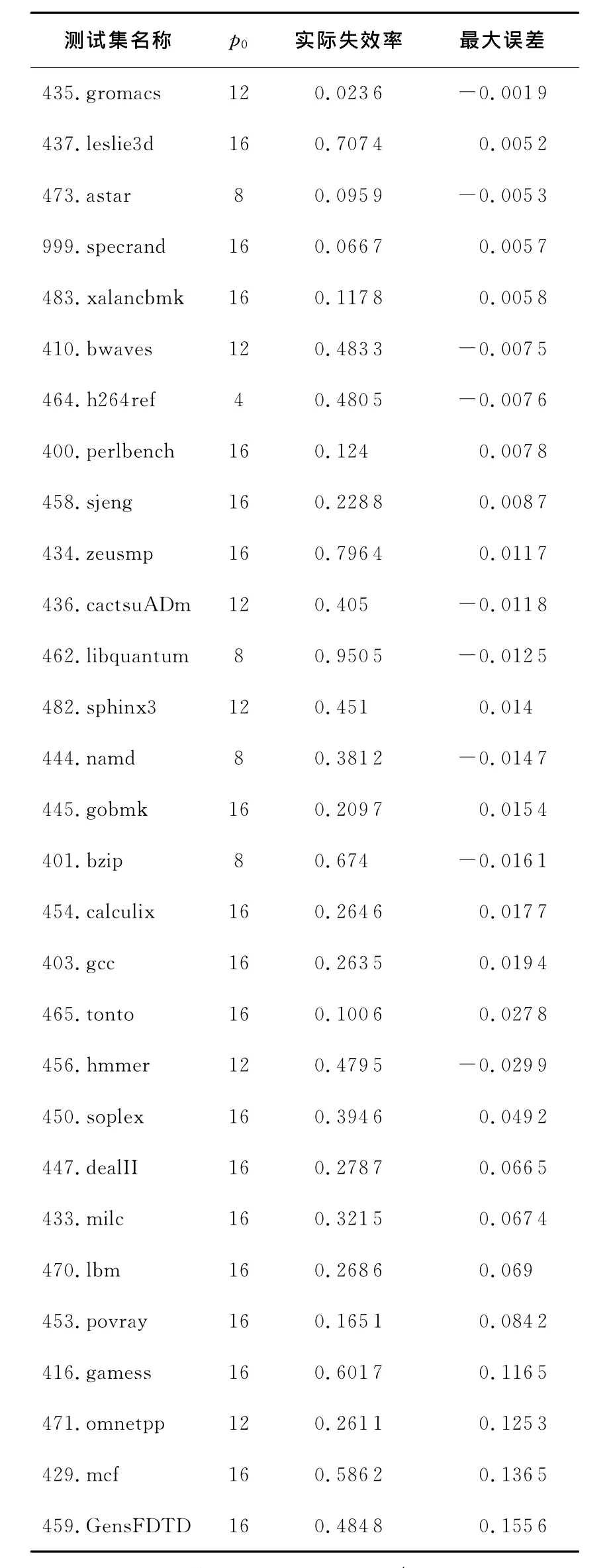
Table 2 Max error of insertion policy in SPEC2006表2 SPEC2006测试集插入策略最大预测误差表
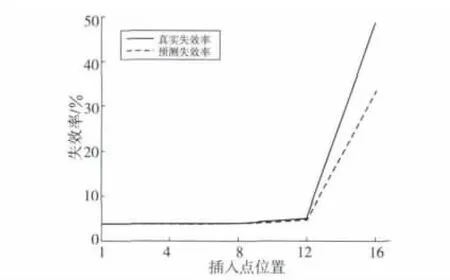
Figure 2 Miss rate prediction of GemesFDTD in different insertion policy图2 GemesFDTD测试程序下不同插入策略失效预测情况
表2中,误差绝对值大于3%的预测失效率都小于实际预测失效率,且此时应用本身的失效率也较大。对模型误差的进一步分析表明,误差较大时其误差主要集中在PP(cseq(dmax+1,nmax+1))上,cseq(dmax+1,nmax+1)表示重用距离大于dmax且长度大于nmax的序列,这部分序列重用距离较大、失效率较高。但是,模型在计算时是按重用距离为dmax+1、长度为nmax+1的循环序列对其进行失效率计算,所以失效率估计会偏低。当dmax、nmax很大时,这部分序列的数量很小,不会对模型误差有较大的影响,但对某些应用,其局部性较差,其CSHP(dmax+1,nmax+1)的数量会很大,此时这部分的影响会比较大。该问题出现的根本原因是dmax、nmax的取值偏小,但是dmax、nmax太大会增加计算复杂性,模型需要在精确度与计算复杂性之间进行折衷。
5 结束语
本文提出了一个Cache插入策略模型,该模型以较简单的方法对Cache访存数据流的行为特性、Cache插入策略的内部作用过程进行了有效的数学描述,可对不同配置下Cache插入策略的性能进行较为准确的预测,最后的验证结果表明,模型的精度较高,最大绝对误差为15.6%,平均绝对误差为3.1%。
本模型不仅可以直接用于Cache动态插入、预取数据块放置等策略的优化,可避免单纯某种插入策略的盲目性,还可加深Cache设计人员对影响Cache性能因素的把握以及指导Cache结构设计的优化。
[1] Xie Y,Loh G H.PIPP:Promotion/insertion pseudo-partitioning of multi-core shared caches[C]∥Proc of the 36th Annual International Symposium on Computer Architecture,2009:174-183.
[2] Jaleel A,Theobald K B,Steely S C,et al.High performance cache replacement using re-reference interval prediction(RRIP)[C]∥Proc of the 37th Annual International Symposium on Computer Architecture,2010:60-71.
[3] Jaleel A,Hasenplaugh W,Qureshi M,et al.Adaptive insertion policies for managing shared caches[C]∥Proc of the 17th International Conference on Parallel Architectures and Compilation Techniques,2008:208-219.
[4] Guo F,Solihin Y.An analytical model for cache replacement policy performance[C]∥Proc of the Joint International Conference on Measurement and Modeling of Computer Systems,2006:228-239.
[5] Grund D,Reineke J.Estimating the performance of cache replacement policies[C]∥Proc of the 6th ACM/IEEE International Conference on Formal Methods and Models for Co-design,2008:101-112.
[6] Belady L A.A study of replacement algorithms for a virtualstorage computer[J].IBM Systems Journal,1966,5(2):78-101.
猜你喜欢
中学生数理化·中考版(2022年6期)2022-06-05
数学物理学报(2022年2期)2022-04-26
中学生数理化·中考版(2021年6期)2021-11-22
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
计算机与数字工程(2019年7期)2019-07-31
舰船电子对抗(2019年2期)2019-05-23
小学生导刊(2018年34期)2018-12-18
山东青年(2016年3期)2016-02-28
母子健康(2015年1期)2015-02-28
