
基于DFA方法的珠江流域极端降水阈值研究*
2013-06-07 03:31刘丙军伍丽丽陆文秀
中山大学学报(自然科学版)(中英文) 2013年1期
刘丙军,伍丽丽,2,陆文秀
(1.中山大学地理科学与规划学院水资源与环境系,广东广州510275;2.珠江水利科学研究院,广东广州510611)
全球气候持续变化影响下,水循环更为复杂多变,极端降水事件频繁发生。极端降水事件引发的洪涝灾害,越来越影响到人类的正常生活,成为全人类共同面临的生存问题。极端降水事件具有发生频率低、样本少、无规律等特点,其阈值定义方式不统一、方法多样,导致阈值定义具有较强不确定性和无规则性。科学研究流域极端降水阈值定义及其时空分布特征,对降低极端降水事件对社会经济的不利影响,丰富和完善气候变化下水循环要素变异识别理论具有重要理论和实践意义。
国内外定义极端降水事件常规方法包括绝对临界值法、百分位法和极值分布拟合法等。绝对临界值法是由世界气象组织气候学委员会 (CCI/WMO)推荐的一类根据绝对物理界限值定义极端气候事件的方法。它通过经验或统计,采用某一绝对日降水强度作为临界值,若某日降水超过此临界值,则被认为是极端降水事件。由于降水分布空间差异大,各地极端降水的绝对临界值也不统一。我国通常将日降水量超过50 mm的降水事件称为暴雨,若日降水量超过暴雨标准则可认为是极端降水事件[1];百分位值法采用概率统计方法,以超过某一百分位点的日降水量为降水极值,即对降水湿日 (日降水量≥0.1 mm)序列进行频率分析,将第n个百分位对应的日降水量定义为极端降水阈值,当日降水量超过该阈值时,则被认为是极端降水事件。王鹏翔[2]、杨金虎[3]、Judit[4]和 Gemmer[5]等分别选用了99%、97%、95%、90%等多类百分位值来定义研究区域极端降水阈值;极值分布拟合法是利用概率统计方法,根据原始日降水数据样本确定一组门限值,对超过各门限值的样本集分别进行极值分布拟合,将拟合效果最优的样本集门限值作为极端降水阈值。Grieser[6]、谢敏[7]和Santiago[8]等分别对各类极值函数的适用性问题进行了有益探讨。
上述研究方法中,绝对临界值法采用某一绝对日降水强度作为极端降水阈值,具有较强的经验性和主观性,无法反映流域降水时空分布差异特征;百分位值法和极值分布拟合法均以气候要素统计学理论为基础,认为极端降水事件属于单纯的小概率事件,可以利用特定的分布函数拟合来确定极端降水阈值,而较少考虑极端降水的物理背景及形成机理,计算精度受样本容量大小和拟合分布函数类型影响较大。鉴于此,本文在总结上述三类方法在确定流域极端降水阈值存在的不确定问题基础上,尝试运用去趋势波动分析方法 (Detrended Fluctuation Analysis,简称DFA),综合考虑流域极端降水事件的统计特征和物理背景,通过系统动力学研究极端降水事件与正常降水事件之间的界限,确定流域极端降水阈值。当前,DFA方法被广泛应用于水文气候变化趋势及极端事件阈值确定,并取得了较好研究成果[9-11]。
1 DFA方法
1.1 极端降水事件的长程相关性特征分析
自记忆特征是气候系统变化的一项物理特征,在气候时间序列里存在着长程相关性,即气象系统的演化过程具有长时距相依的特征。对于极端降水事件,其演化状态视为水循环系统受到外界扰动而导致的极端异常状态,其对应的演化轨迹不属于正常的演化轨迹,而是水循环系统受到外界扰动而导致的极端异常状态。由于极端降水事件属于小概率事件,所包含水循环系统演化信息极少,对正常降水序列的长程相关性影响很小,甚至可以忽略其统计效应。若对原始降水序列进行数据变换,剔除极端降水数据后的降水序列演变趋势与原始时间序列基本一致,而剔除正常降水数据的降水序列演变趋势与原始序列差异较大。因此,可以根据这一现象,按照由大到小的规则逐步剔除降水序列高值部分,对剔除高值部分后的降水序列组进行长程相关性分析,若能找到降水序列长程相关性系数的突变点,则可认为在此突变点处被剔除的降水高值为极端降水,由此可以划分降水事件的极端状态和非极端状态。
因此,可以利用去趋势波动分析方法在计算时间序列长程相关性的优势,寻求导致降水序列长程相关性发生突变的降水临界值。将该降水临界值作为极端降水阈值,超过该降水临界值的降水样本作为极端降水,而小于该临界值的降水样本作为正常降水。
1.2 DFA方法
DFA是基于随机过程理论和混沌动力学新发展的一种分析方法,主要用于检测时间序列的长程相关性特征。DFA方法通过有效滤去时间序列各个阶段的趋势成分,从而消除趋势中的伪相关现象,来探测出非平稳时间序列中的相关性。从动力学角度分析,通过DFA方法进行数据变换后的序列仍保留着与原始序列相同的持久性 (或反持久性)等演变痕迹,“滤除”了原始序列自身演化的各种短时程相依等趋势成分。因此采用DFA方法分析非平稳时间序列,可以避免对相关性的错误判断。
利用DFA方法,确定降水序列极端降水阈值的基本思路是寻找一个日降水量临界值,保持小于该临界值的降水数据点位置不变时,对大于该临界值的降水数据点,无论这些数据点彼此之间的位置如何变化,对整个序列的DFA指数无影响,可以认为该临界值为降水序列的极端降水阈值。DFA方法具体确定降水序列极端降水阈值的处理程序如下:
1)对某一站点湿日 (日降水量大于或等于0.1 mm)降水序列 {xi,i=1,2,…,n},确定该降水序列{xi}的最大值xmax;确定参考点xR,xR值可以是降水序列平均值xave或者界于最大降水量与最小降水量之间的某一中值xmed;
2)从降水序列{xi}的最大值xmax开始,随机化挑选落在区间{xi,ifxi≥xmax-d×k}内的降水数据,其余数据顺序保持不变,直到xi=xR,将依次生成新的降水序列YJ,J=xmax-d×k,其中d为区间间隔,k=1,2,…,(xmax-xR)/d或k=(xmax-xR)/d;
3)计算每个新生成序列YJ的长程相关性指数DFAJ,分析长程相关性指数随区间J变化的变化过程。对于某一长度为m的降水序列YJ={xj,j=1,2,…,m},其DFA长程相关性指数计算程序如下:
① 计算降水时间序列{xj,j=1,2,…,m}的累积离差:
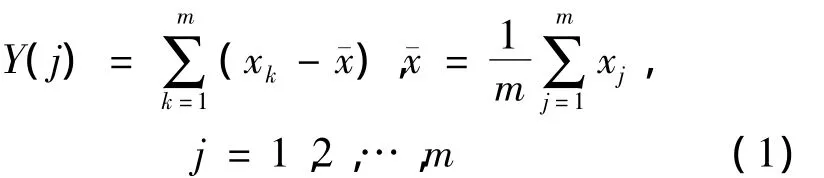
②将累积离差Y(j)等分成Ns个互不重叠时间长度为s的等时距区间,其中Ns=int[m/s]。降水序列个数并不总是时间长度s的整数倍,可能使得小部分降水数据未被利用。为了不丢失降水数据的信息,保证降水序列所有数据得到利用,对Y(j)的逆序同样进行上述操作,这样将共有2Ns个等时距区间。
③对于每个区间v(v=1,2,…,2Ns),利用多项式回归拟合,得到降水序列的局部趋势,滤去该趋势后的序列记为YS(j),表示原序列与拟合序列之差,即

式中,Pv(j)是第v个子区间的拟合多项式。可见DFA滤去了累积离差中的k阶趋势成分及原始序列中的k-1阶趋势成分。
④计算每个子区间滤去局部趋势后的方差:

⑤计算标准DFA的波动函数:
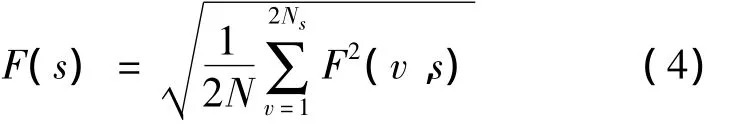
若降水序列{xj}是长程幂律相关的,则F(s)与s应满足幂律关系,即

对 (5)式两边取对数,得
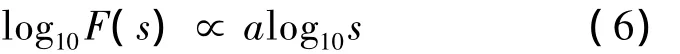
⑥ 在双对数坐标系(s,F(s))中绘制alog10slog10F(s)函数关系的散点图,可确定波动函数的α标度指数,该指数即为DFA指数。当0.5<α<1时,表明此序列各个值之间不是独立的,具有长程相关性。
4)不同降水序列YJ的DFA指数序列{DFAj},会逐渐收敛于原始降水序列的DFA指数值。但指数序列{DFAj}收敛于原始值的收敛程度并不完全一致,而是围绕原始DFA指数值有着非常小幅度的波动。因此,需要通过计算{DFAj}的方差序列 { v arj}来消除这一波动对判断收敛点带来的影响。方差定义为:

式中,DFAj表示第j个新生序列的DFA指数,N表示总的新生成序列 YJ个数,E表示指数序列{DFAj}的平均值。{varj}与{DFAj}的收敛性具有同步性[12],要确定{DFAj}的收敛点,则应先划分出{varj}的收敛区。本文采用BG算法确定收敛区转折点,并运用χ2检验检测{varj}的收敛点。BG算法和χ2检验方法的具体原理与步骤可参见文献 [13]。
5)根据确定{DFAj}收敛点,找到导致DFA指数发生突出的降水临界值,该临界值即为降水序列的极端降水阈值。
2 珠江流域极端降水阈值分析
2.1 珠江流域基本概况和数据
珠江流域位于东经102°14'-115°53',北纬21°31'-26°49'之间,西起云贵高原、北起南岭山地,经两广丘陵、珠江三角洲入南海。该流域地处低纬季风地区,地域广大,气候复杂,大部分地区属于南亚热带湿润气候,北部为中亚热带湿润气候,西部滇南河谷为北热带湿润气候。气候温和多雨,多年平均温度在14~22℃之间,流域降水空间分布差异明显,总体呈东多西少变化趋势,多年平均年降水量在1200~2200 mm之间。流域下游地区较上游地区易发生强降水,最大连续降雨量、最大连续降雨天数以及最大连续降雨强度及三者叠加综合指数在空间分布上呈东大西小的局势,珠江三角洲、桂林市、百色市等地区是流域极端降雨高发区;流域极端降水总量无明显变化,极端降水强度略有上升,但突变不明显[14]。考虑到降雨空间分布的整体性,本次将广西省东南部、广东省西南部及海南岛一并纳入研究。
本文研究选取的降水指数为日降水强度,采用的数据来源于中国气象信息中心,基本资料由气象部门根据规范要求整理记录,质量可靠。研究区域内共有83个国家气象站点,在各观测站点记录中,资料最长站点记录年限为1951-2009年,资料最短站点记录年限仅为2000-2009年,按照样本空间和时间代表性的要求,保证流域内所选择站点分布密度的合理性,以及各站点样本序列有完整的丰、平、枯水文变化周期,最终选择经过质量控制且无缺测值的62个站点地面湿日降水观测资料,序列长度为51年 (1959-2009年)。同时,考虑到珠江流域气候条件受人类活动影响非常小,变化缓慢,有较长的变化周期,因此,本次所采用的系列降水资料基本产生于同一自然条件,具有较好的一致性。

图1 珠江流域雨量观测站点及多年平均年降雨等值线图Fig.1 The contour of mean precipitation of the hydrological stations in the Pearl River Basin
2.2 极端降水阈值分析结果
运用DFA方法,确定珠江流域各站点极端降水阈值,其空间分布见图2。利用珠江流域多年平均降水量、湿日Cv值和湿日Cs值等指标,分析利用DFA方法确定流域极端降水阈值的合理性:
1)运用DFA法,确定的珠江流域各站点极端降水阈值唯一,且空间分布差异明显。极端降水阈值高值中心主要分布在流域东南沿海地区,包括都安、桂林、信宜、高要、罗定、台山、深圳、汕尾、汕头等站点,这些站点极端降水阈值超过50 mm/d;低值中心主要分布在西北部和西南部,包括威宁、泸西、靖西、龙州、罗甸、玉林、桂平、韶关、梅县、湛江等站点,大部分站点阈值在30 mm/d以内。
2)分析珠江流域由DFA方法确定的流域极端降水阈值与其降水序列的百分位值对应关系,见图3。不同站点极端降水阈值在降水序列中所处百分位值不统一,其中,降水强度普遍较小的西南地区高强度降水事件发生频率低,极端降水事件在整个降水序列中所占比重较小,该地区由DFA方法计算得到的极端降水阈值所处百分位值较高;降水强度普遍较大的珠江三角洲及东南沿海一带,高强度降水事件发生频繁,极端降水事件在整个降水序列中所占比重较大,这些地区由DFA方法计算得到的极端降水阈值所处百分位值较低。可见,由DFA方法确定的流域极端降水阈值高、低值区与所处百分位的高、低值区大体一致。
3)变差系数Cv和偏态系数Cs分别表征降水序列时间分布的离散程度和不对称程度,若降水序列Cv或Cs越大,则表明降水序列离散程度或不均匀程度也越高,即小概率降水事件越偏离于均值,相应极端降水阈值也越大。分析由DFA法确定的珠江流域极端降水阈值,其空间分布与湿日Cv值、湿日Cs值空间分布基本一致,全流域有75%的站点极端降水阈值与其湿日Cv值、湿日Cs值呈正比关系。如流域东南部沿海地区处于降水高值区,该区域极端降水阈值普遍较大,达到55 mm/d以上;流域西部广西桂林等地湿日降水Cv值、Cs值较高,表明该区域降水过程变幅较大,其极端降水阈值也较大。

3 结论
流域极端降水事件发生频率低、样本少,受全球气候变化、下垫面条件等多种内外部因素影响,其时空演化具有较强不确定性。本文针对流域极端降水阈值定义方式不统一、方法多样等特点,总结了绝对临界值法、百分位值法、极值分布拟合法在确定流域极端降水阈值存在的不确定性问题,并尝试运用DFA方法确定流域极端降水阈值,探讨了该方法的物理机制及其适用性。得出如下结论:
1)运用绝对临界值法、百分位值法和极值分布拟合法等确定流域极端降水阈值,三种方法以经验公式或统计公式为主,较少考虑极端降水的物理背景及形成机理,且计算结果受样本容量大小和拟合分布函数类型等因素影响较大,方法存在较强经验性和主观性;

图4 珠江流域降水湿日Cv值和Cs值分布情况Fig.4 Distribution of the CVand Csfor the dairy rainfall in the Pearl River Basin
2)DFA方法以系统动力学为基础,利用变换前后降水序列的长程相关指数变化特征,确定流域各站点极端降水阈值。与常规方法相比,该方法原理正确严谨,计算结果唯一,能较好反映流域降水序列的统计效应和物理背景。但该法要求样本容量大,且计算复杂。
[1]闵屾,钱永甫.中国极端降水事件的区域性和持续性研究[J].水科学进展,2008,19(6):763-771.
[2]王鹏翔,杨金虎.中国西北近45年来极端高温时间及其区域性增暖的响应[J].中国沙漠,2007,27(7):649-655.
[3]杨金虎,江志红,王鹏祥,等.中国年极端降水事件的时空分布特征.气候与环境研究[J],2008(1):75-83.
[4]JUDIT B,RITA P.Analysis of precipitation conditions for the Carpathian Basin based on extreme indices in the 20th century and climate simulations for 2050 and 2100[J].Physics and Chemistry of the Earth,2010,35:43-51
[5]GEMMER M,FISCHER T,JIANG T,et al.Trends in Precipitation Extremes in the Zhujiang River Basin,South China[J].Journal of Climate,2011,24(3):750-761.
[6]谢敏,江志红,丁裕国.运用Gumbel-Logistic模式模拟区域暴雨的试验[J].沙漠与绿洲气象,2011,5(1):1-5.
[7]GRIESER J,STAEGER T,SCHOENWIESE C D.Estimates and uncertainties of return periods of extreme daily precipitation in Germany[J].Meteorologische Zeitschrift,2007,16(5):553-564
[8]SANTIAGO B,MARTA A ,SERGIO M,et al.Assessing trends in extreme precipitation events intensity and magnitude using non-stationary peaks-over-threshold analysis:a case study in northeast Spain from 1930 to 2006[J].International Journal of Climatology,2011,31:2102-2114
[9]张斌,史凯,刘春琼.元谋干热河谷近50年分季节降水变化的DFA分析[J].地理科学,2009,29(4):561-566.
[10]BUNDE E K,KANTELHARDT J W,BRAUN P,et al.Long-term persistence and multifractality of river runoff records:Detrended fluctuation studies[J].Journal of Hydrology,2006,322:120-137.
[11]LUCIANO T,JORGE O P,BEATRICE S.Long-term persistence and multifractality of river runoff records:Detrended fluctuation studies[J].Physica A ,2012,391:1553-1562
[12]侯威,章大全,周云,等.一种确定极端事件阈值的新方法:随机重排去趋势波动分析方法[J].物理学报,2011,60(10):1-15.
[13]封国林,龚志强,董文杰,等.基于启发式分割算法的气候突变检测研究[J].物理学报,2005,54(11):5494-5499.
[14]彭俊台,张强,陈晓宏.珠江流域极端降雨时空演变特征分析[J].灾害学,2011,26(4):24-34.
猜你喜欢
成都信息工程大学学报(2021年4期)2021-11-22
黑龙江气象(2021年2期)2021-11-05
现代临床医学(2021年2期)2021-03-29
中国感染与化疗杂志(2020年2期)2020-01-11
电子制作(2019年14期)2019-08-20
疯狂英语·新读写(2018年3期)2018-11-29
党的生活·党员电教与远程教育(2017年9期)2017-10-17
故事会(2016年21期)2016-11-10
共产党员(辽宁)(2012年21期)2012-09-20
