
基于依存语法构建多视图汉语树库
2015-04-21 08:43邱立坤王厚峰
中文信息学报 2015年3期
邱立坤,金 澎,王厚峰
(1. 鲁东大学 文学院 山东省语言资源开发与应用重点实验室,山东 烟台 264025;2. 北京大学 计算语言学研究所,北京 100871;3. 乐山师范学院 智能信息处理及应用实验室,四川 乐山 614004)
基于依存语法构建多视图汉语树库
邱立坤1,2,金 澎2,3,王厚峰2
(1. 鲁东大学 文学院 山东省语言资源开发与应用重点实验室,山东 烟台 264025;2. 北京大学 计算语言学研究所,北京 100871;3. 乐山师范学院 智能信息处理及应用实验室,四川 乐山 614004)
树库是自然语言处理中一项重要的基础资源,现有树库基本上都是单视图树,支持短语结构语法或者依存语法。该文提出一套基于依存语法的多视图汉语树库标注体系,仅需标注中心语和语法角色两类信息,之后可以自动地推导出描述句法结构所需的短语结构功能和层次信息,从而可以在不增加标注工作量的前提下获得更多语法信息。基于该体系,构建了北京大学多视图汉语树库(PMT)1.0版,含有64 000句、140万词,支持短语结构语法和依存语法两个视图。
多视图树库;依存语法;短语结构语法
1 引言
树库是标注有句法信息的语料库,是一种深度标注的语言知识资源。在语料库语言学和计量语言学中,树库可以用于研究各种语法现象以及语言整体的特点;在计算语言学中,树库可以用于训练和测试句法分析器。20世纪90年代之前,自动句法分析主要使用规则的方法,通过大量人工总结的规则来进行句法分析。宾州树库[1]以及一系列类似句法树库的构建改变了这一局面。自宾州树库发布之后,词汇化的统计句法分析取得了长足进展,在评测中与基于规则方法相比具有较大优势。Collins[2-3]基于宾州树库所提出的句法分析方法取得了很大成功,代表着统计句法分析方法达到了一个全新的水平。一系列树库的建设促进了统计句法分析研究的产生与繁荣。
就树库构建中的语法理论而言,最主流的理论是短语结构语法,大多数树库都是基于这一理论构建的。依存语法是另外一种比较流行的理论,主要描述词语之间的依存关系,甚至是非相邻的依存关系,在自然语言处理和信息检索中具有重要价值。依存树库因此日益受到重视,许多学者研究将现有的短语结构树库转换为依存树库[4-6]。
就汉语而言,目前成规模的树库主要有宾州中文树库、清华中文树库、北大中文树库、教育部语用所树库和哈工大依存树库。在现有树库的基础上,本研究提出一套以依存语法为核心的多视图汉语树库标注体系,该体系仅需标注中心语和语法角色(指主、谓、宾、定、状、补等句法成分)两种信息,可以自动推导出短语功能信息(指NP、VP、ADJP等短语功能信息)和层次信息,从而在标准的依存树库基础上自动生成短语结构树库。基于本文所提出的标注体系,我们开发了“北京大学多视图汉语树库1.0版”。
本文其余部分组织如下: 第2节简单介绍相关研究;第3节介绍我们提出的多视图树库标注体系;第4节介绍我们所构建的多视图树库的基本情况;最后一节是结语和展望。
2 相关研究
除去通过自动转换得到的树库以外,世界上成规模的树库主要是短语结构树和依存树两种类型。这两种类型中,又以短语结构树库影响最大、使用最广。比如在英语和汉语中,主要的树库都是短语结构树库。从短语结构树出发,通过自动转换的形式产生了中心语驱动的短语结构语法(HPSG)、词汇功能语汇法(LFG)、组合范畴语法(CCG)等多种类型的树库,许多依存树库也是从短语结构树库转换来的。
多数短语结构树和依存树并不依赖于特定的语法理论,短语结构树和依存树之间的区别主要在于标注信息的侧重点不同。句法结构的描写中可以包括词类、层次、语法结构关系、短语整体功能等信息[7],其中结构关系又可以分解为中心语和语法角色两个信息。短语结构树是一棵层次树,其中突显的是层次信息;此外,由于在自动句法分析中基于生成式规则的(概率)上下文无关文法较为流行,在标注短语结构树时短语整体功能信息就成了另外一个突显的信息;中心语和语法角色信息相对而言不受重视。相比于短语结构树,依存树缺少了短语这一级中间结点,直接描写词与词之间的关系,因此突显的是中心语信息和语法角色信息,层次和短语功能信息在其中均没有直接表示。
目前成规模的中文树库主要有宾州中文树库[8]、Sinica中文树库[9]、清华中文树库[10]、国家语委中文树库[11]、北大中文树库[12]和哈工大中文依存树库[13]。这些树库的基本信息如表 1所示。
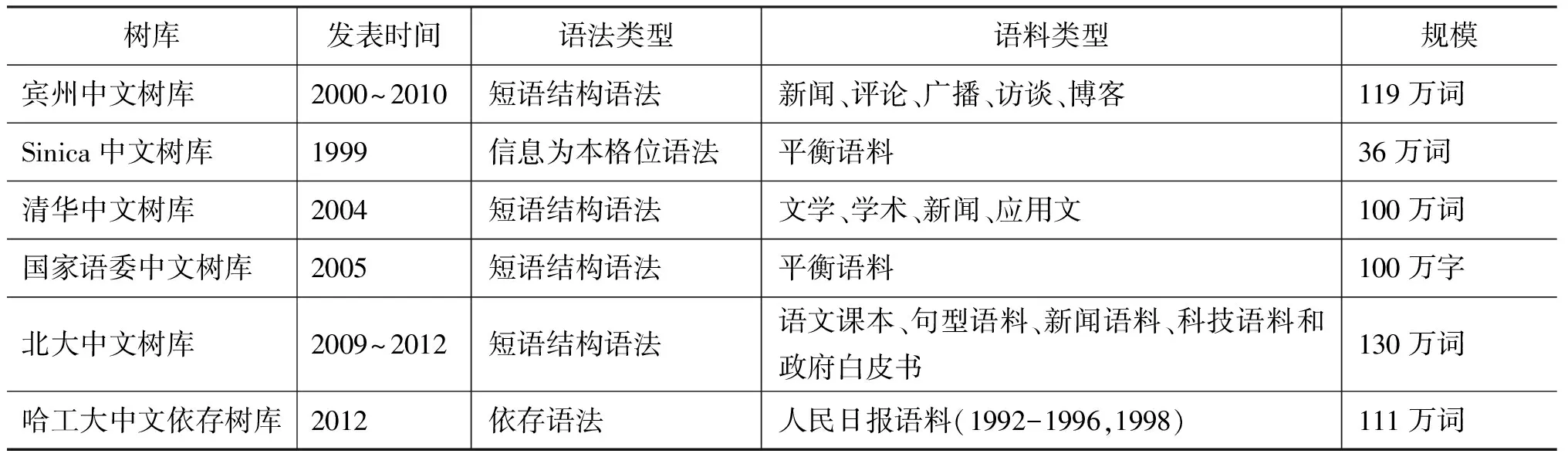
表1 现有中文树库基本信息一览表
除了树库转换之外,多表达形式(Multi-representational)树库是另外一种可行的思路。Xia等[14]介绍了构建Hindi/Urdu语多表达形式树库的计划,并认为下一代树库应该是多表达形式的树库,各表达形式之间可以相互转换。由于该树库及其详细规范尚未发布,所以目前还不知道其细节情况。
3 多视图汉语树库标注体系
3.1 多视图树的定义与基本框架
对同一个句子,基于同一个数据源,提供多种视图,如依存视图、短语结构视图、组合范畴语法视图等。我们称这种树为多视图树。一般意义上的依存树、短语结构树或组合范畴语法树可以视为单视图树。
多视图树的“多”首先体现在构建阶段。在构建多视图树时,可以选一个视图作为中心视图,其他视图与中心视图共享数据、彼此之间可以相互转换。
多视图树的“多”还体现在使用阶段。在使用阶段,多视图树不仅仅为同一个句子提供多种体系的句法分析结果,更重要的是这些不同体系的句法分析结果具有相同数据来源,不同视图只是同一数据来源的不同表现形式而已。
本文设定的多视图汉语树库基本框架为: 以依存视图为核心,在句法层面上仅仅标注中心语和语法角色两类信息,通过层次生成程序和结构功能映射规则自动地产生层次信息和短语结构功能信息,从而自动转换出相应的短语结构树;在语义层面上,通过对部分语法标签的细化进一步标注语义角色标签,并通过虚词的格传递来保证语法依存和语义依存在中心语上的一致性;在以上视图的基础上再生成组合范畴语法视图。最终生成的多视图树库可以含有语法依存视图、短语结构视图、组合范畴视图和语义依存视图等多个视图。
在本文中,我们主要讨论含有短语结构语法和依存语法两个视图的多视图树,其中需要解决的关键问题是短语整体功能的推导和层次信息的推导。
3.2 短语功能和层次信息的可推导性及解决办法
3.2.1 整体功能的可推导性及推导方法
对于短语整体功能的可推导性,汉语学界很早就有过讨论。朱德熙先生[15]提出,“内部构造相同的结构,功能一般相同;功能相同的结构,内部构造不一定相同。” 陈保亚先生[16]则将之总结为结构功能原则,“如果两个言语片断的直接成分功能相同,结构关系相同,它们的功能也相同。”“这个规律叫做结构功能原则。根据这一原则,只要知道了直接成分的功能和结构关系,结构功能就知道了”。换言之,我们知道了具有依存关系的两个词的词类以及它们之间语法关系的类型,这两个词构成的短语的功能也就可以推导出来了。
按照结构功能原则,推导短语整体功能时在每一步都需要知道直接成分的功能。依存树中只标注了词的功能标记,没有短语的功能标记,但是通过递归的方式,可以依次获得各短语直接成分的功能标记。
本文使用短语功能标记作为推导的目标标记,推导短语整体功能的规则为: 父结点词类+子结点词类+语法角色=>短语整体功能标记。例如,“v+n+VOB=>VP”表示父结点词类为动词(v)、子结点词类为名词(n)、子结点充当父结点的宾语(VOB),则整个短语的功能类型为动词性短语VP。
通过设计不同的规则体系,可以从同样的依存树库生成不同体系的短语结构树库。目前,我们已经设计出针对北大中文树库和宾州中文树库两套体系的推导规则。
3.2.2 层次的可推导性及推导方法
对于整体功能的可推导性,学界基本上是有共识的;层次的可推导性,目前却很少有人论及。本文中将以并列结构为例来分析层次推导过程中的歧义及其消解办法。
并列结构是一类比较特殊的结构,从依存树转换到短语结构树的过程中,并列结构的子结点在与父结点结合时会面临歧义,其子结点可能依附于并列结构多个并列成分中的一个,也可能依附于整个并列结构。如果以并列结构中最左侧的并列成分为核心结点,则左边的子结点可能依附于最左侧的并列成分,也可能依附于整个并列结构;如果以最右侧的并列成分为核心结点,则右边的子结点可能依附于最右侧的并列成分,也可能依附于整个并列结构。
例如,在以最右侧并列成分为核心结点的情况下,图 1中“建立和完善”是一个并列结构,“各地”是并列结构的一个子结点,它依附于整个并列结构,为两个并列成分所共享,位于父结点的左侧;“市场”也是并列结构的一个子结点,它也依附于整个并列结构,为两个并列成分所共享,位于父结点的右侧。在图 2中,“充满生机、充满希望”是一个并列结构,“希望”只是并列结构中的一个并列成分的子结点,而不是整个并列结构的子结点。从依存树上看,图 1 中的“市场”和图 2 中的“希望”均依存于最右侧的并列成分,但是在前一个句子中,“市场”事实上依附于整个并列结构,为并列成分所共享;在后一个句子中,“希望”事实上只依附于最右侧的并列成分,不为其它并列成分所共享。在转换到短语结构树时,仅依存于一个并列成分的子结点与依存于整个并列结构的子结点就会难以区分。以最左侧并列成分为核心结点时会有类似的问题,在此不再赘述。
为了解决并列结构的层次歧义问题,本文将并列结构区分为共享并列(COS)和一般并列(COO)。所谓共享并列指的是,两个或多个并列成分共享右边的子结点,右边的子结点从依存树上看只指向并列结构最右侧的结点(即并列结构的核心结点),实际上却是并列结构中多个并列成分共享的子结点。共享并列之外的并列为一般并列,其中的并列成分不共享右边的子结点。因此,图 1中的并列结构为共享并列(COS),图 2中的并列结构为一般并列(COO)。通过共享并列和一般并列的区分,可以较好地解决将依存树转换到短语结构树时推导并列结构层次时所面临的歧义。
限于篇幅问题,详细的层次推导算法将另文叙述。
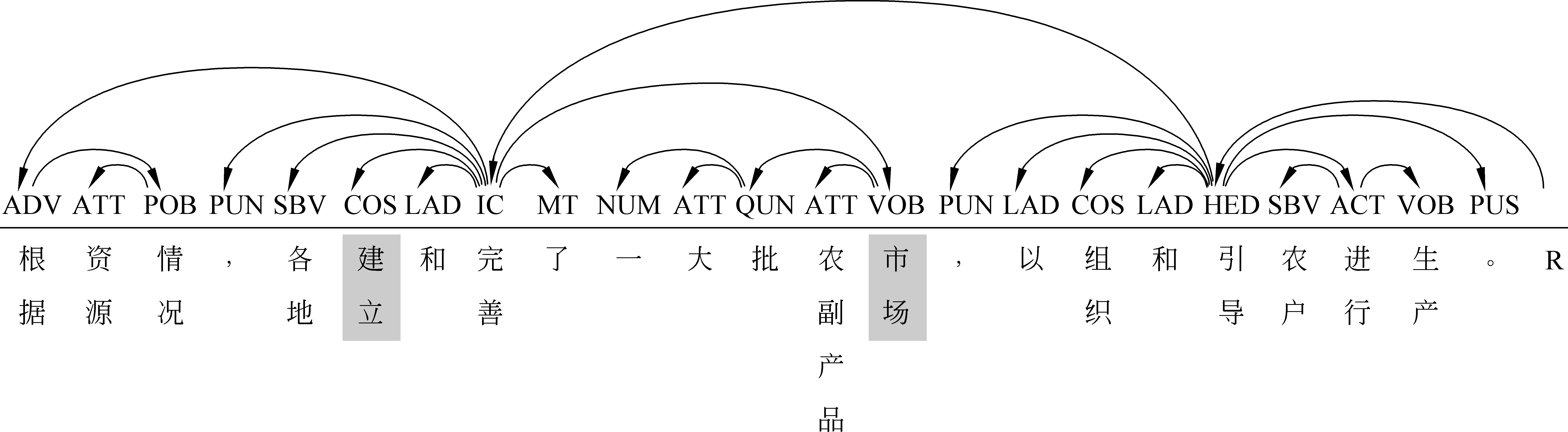
图1 含并列结构的依存树示例1
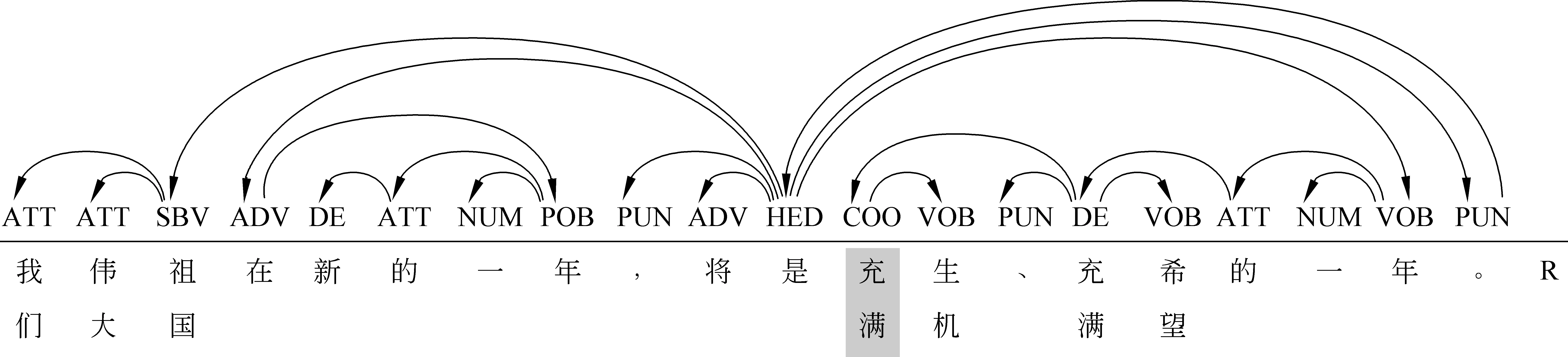
图2 含并列结构的依存树示例2
3.3 支持多视图的依存语法标注体系
设计支持多视图的依存语法标注体系的主要工作是发现视图转换时的歧义,并通过语法标注体系的设计和约定来消解这些歧义,上文中共享并列与一般并列的区分就是一个典型的例子。根据从中心语和语法角色出发推导层次和短语整体功能信息的需要,本文提出如表2所示的依存语法标注体系,共含有30个语法角色标签,这些语法角色大体上可以分为三类。

表2 支持多视图的依存语法标注体系
第一大类是句子的核心结点以及与谓词中心语具有直接依存关系的结点,称之为主干成分,共11个。其中“核心、主语、宾语、补语、状语、时体、连动”等标记与一般语法书中所讲的基本一致,“话题”用于标示一般所说的主谓谓语句中的大主语,“强调”用于标示一般所说的客体提前到主语之后、动词之前的现象,“间接宾语”用于标示双宾语中的近宾语,“行为宾语”用于标示兼语句。
第二大类是与谓词中心语的子结点或孙子结点具有直接依存关系的结点,称之为局部成分,共九个。其中“定语、数字、数量、介宾、同位”与一般语法书中所讲的基本一致,“数量补语”用于标示后置的起修饰功能的数量结构,“的字、地字、得字”分别用于标示依附于“的、地、得”充当定语、状语和补语的成分。
第三大类是一些较为特殊的结点,共十个。其中,“前附加、后附加”用于标示连词、语气词及一些助词等,“独立成分、并列式独立成分”均指独立于句子的主谓宾结构之外的成分,“重叠”主要指动词重叠现象,“并列、共享并列”均指并列结构,“小句”用于标示小句的核心结点与另一个小句核心结点之间的关系,“标点、跨句标点”之间的区别在于是否跨一个以上的小句。这些特殊标记的设置也是为了消解视图转换时的层次歧义。
根据本文所设计的视图转换算法(包括整体功能推导和层次推导),可以将图1和图2所示的依存树分别转换成图3和图4所示的短语结构树(宾州中文树库格式*在图中没有显示由词类直接上升的短语功能标记。另外,该短语结构树是严格的二叉树,这也是不同于宾州中文树库的地方。如需要,每个短语功能标记上还可以显示两个直接成分之间的语法结构关系标记。)。在转换过程中,通过共享并列和一般并列的区分,可以解决并列结构所带来的层次歧义问题。例如,图1中,“建立”和“完善”之间的语法角色是共享并列(COS),“组织”和“引导”之间的语法角色也是COS,所以两个动词先组合成VP,然后再带宾语。图2中,两个“充满”之间的语法角色是一般并列(COO),所以两个动词先分别带一个宾语,组成两个VP,两个VP再组合形成一个更大的VP。
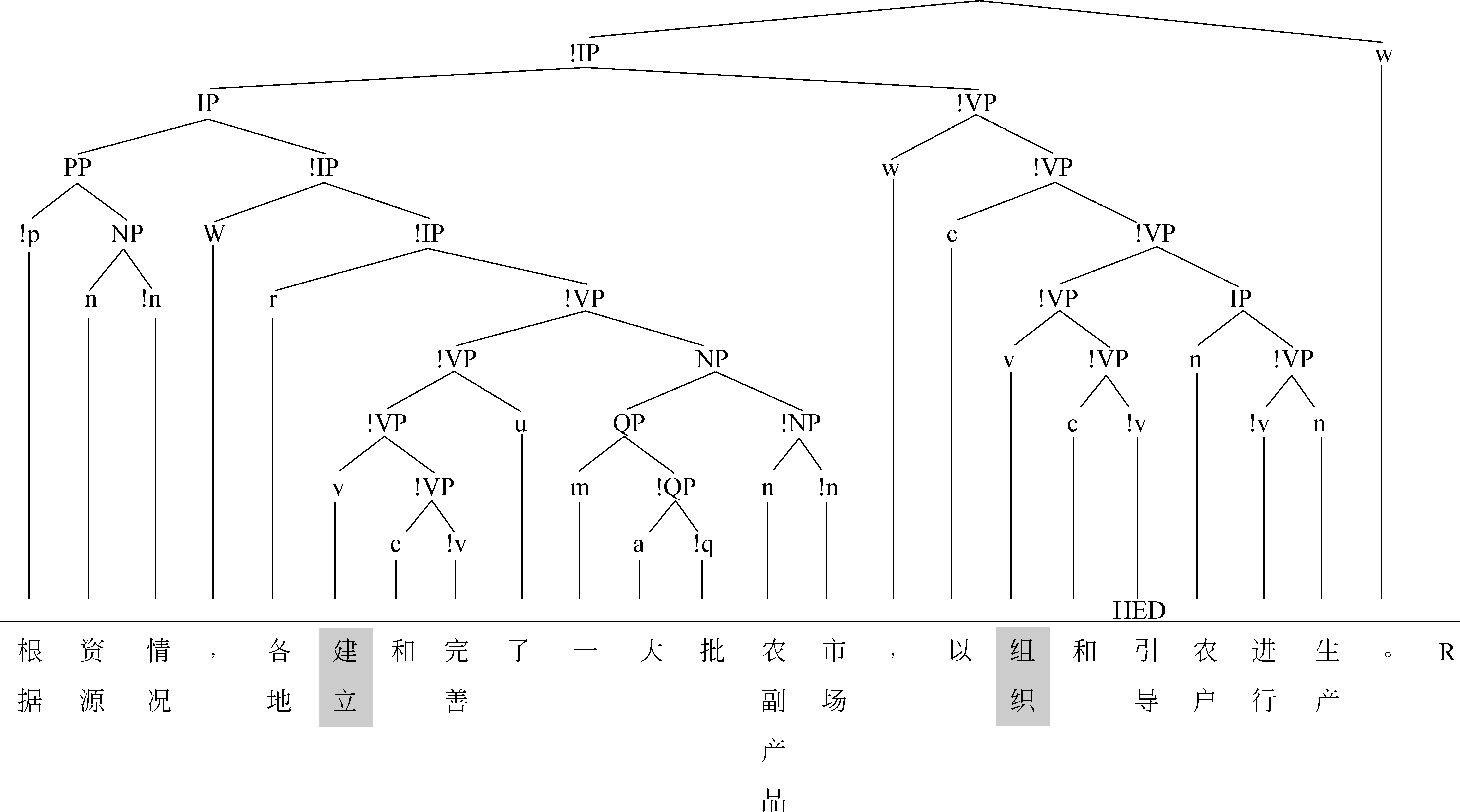
图3 从依存视图转换得到的短语结构视图例1
4 多视图汉语树库的标注实践
基于上述体系,我们制定了一部比较完整的句法树库标注规范,并开发了一套支持短语结构语法和依存语法两个视图的标注工具。该工具的主要功能有: 编辑依存弧和标签,查询词、词性、语法角色或特定结构,检测视图转换错误,检测标注错误,检测标注不一致现象等。
使用上述规范和工具, 我们已经进行了大规模树库的标注实践。部分语料采用两个标注人员双盲标注、第三方校对的标注方式完成;部分语料采用双遍校对的方式完成。目前已经完成标注的语料为2000年1月份和1998年1月份1~10日10天的《人民日报》语料,共计64 000句140万词。我们将该树库命名为“北京大学多视图中文树库1.0版”,并于2014年年底发布,其中1998年1月份1~10日10天共计14 000句语料将面向国内学术界免费共享*具体信息发布在http://klcl.pku.edu.cn/上,敬请留意。。该版本树库支持短语结构语法和依存语法两个视图,其中依存语法视图使用本文所提出的标注体系,短语结构语法视图基本采用宾州中文树库的标注体系。
5 结语和展望
在本文中,我们提出了一套以依存语法为核心的多视图汉语树库标注体系,并介绍了基于该体系构建的“北京大学多视图中文树库1.0版”的基本情况。受篇幅所限,本文只做框架性的介绍,文中所提及的整体功能推导方法、层次推导算法(包括算法的可靠性测试)、树库标注规范、树库标注工具等未详细说明,将另文介绍。
后续发布的版本将会从以下几个方面升级: (1)增加视图类别。陆续提供组合范畴语法视图、语义角色视图、篇章结构视图等;(2)扩展语料范围。语料涉及的领域将会扩展到微博、产品评论、问答和专利等;(3)扩大语料规模。在2014年年底以前达到300万词以上的规模。
[1] M P Marcus, B Santorin, M A Marcinkiewicz. Building a large annotated corpus of English: the Penn Treebank[J]. Computational Linguistics, 1993, 19(2): 313-330.
[2] M Collins. A Statistical Dependency Parser Of Chinese Under Small Training Data[C]//Proceedings of the 34th Annual Meeting of the ACL, 1996: 184-191.
[3] M Collins. Three Generative, Lexicalized Models for Statistical Parsing[C]//Proceedings of the 35th annual meeting of the association for computational linguistics, 1997: 16-23.
[4] H Yamada, Y Matsumoto. Statistical Dependency Analysis with Support Vector Machines[C]//Proceedings of the 8th International Workshop on Parsing Technologies (IWPT), 2003: 195-206.
[5] 党政法,周强.短语树到依存树的自动转换研究[J].中文信息学报,2005,19(3): 21-27.
[6] 李正华,车万翔,刘挺.短语结构树库向依存树库转化研究[J].中文信息学报,2008,22(6): 14-19.
[7] 朱德熙.现代汉语语法研究[M].北京: 商务印书馆,1979: 42-66.
[8] N Xue, F Xia, F D Chiou, et al. The Penn Chinese Treebank: Phrase Structure Annotation of a Large Corpus[J]. Natural Language Engineering, 2005, 11(2): 207-238.
[9] 陈凤仪,蔡碧芳,陈克健,等. 中文句结构树资料库 (Sinica Treebank)的构建[J]. Computational Linguistics and Chinese Language Processing, 1999, 4(2): 87-104.
[10] 周强.汉语句法树库标注体系[J].中文信息学报,2004,18(4): 1-8.
[11] 靳光瑾,肖航,富丽,等.现代汉语语料库建设及深加工[J].语言文字应用,2005(2): 111-120.
[12] 詹卫东.树库在汉语语法辅助教学中的应用初探[J]. Journal of Technology and Chinese Language Teaching, 2012, 3(2): 16-29.
[13] W Che, Z Li, T Liu. Chinese Dependency Treebank 1.0[DB]. Linguistic Data Consortium, Philadelphia.
[14] F Xia, O Rambow, R Bhatt, et al. Palmer. Towards a Multi-Representational Treebank[C]//Proceedings of The 7th International Workshop on Treebanks and Linguistic Theories (TLT 2009), 2009: 159-170.
[15] 朱德熙.语法讲义[M].北京: 商务印书馆,1982: 21.
[16] 陈保亚.20世纪中国语言学方法论[M].济南: 山东教育出版社,1999: 106-107.
A Multi-view Chinese Treebank Based on Dependency Grammar
QIU Likun1,2, JIN Peng2,3, WANG Houfeng2
(1. Key Laboratory of Language Resource Development and Application of Shandong, School of Chinese Language and Literature, Ludong University, Yantai, Shandong 260045, China; 2. Institute of Computational Linguistics, Peking University, Beijing 100871, China; 3. Lab of Intelligent Information Processing and Application, Leshan Normal University, Leshan, Sichuan 614004, China)
Treebank is an important resource for natural language processing. All the existing dependency treebanks and phrase structure treebanks might be taken as single-view treebanks. This paper proposed a schema for building a multi-view Chinese treebank based on dependency grammar. In this schema, we only need to annotate the head information and syntactic role of a child node, and then could infer the phrase structure function and hierarchy information of the phrase, which can greatly improve the efficiency of the labeling process without losing information. According to this schema, we built the treebank PKU Multi-view Chinese Treebank (PMT) version 1.0, which contains 64 000 sentences and 1.4 million words, and supports the phrase structure grammar view and dependency grammar view.
Multi-view Chinese treebank; phrase structure grammar; dependency grammar
1003-0077(2015)03-0009-07
2013-04-08 定稿日期: 2013-07-24
国家863计划主题项目(2012AA011101);国家社科基金重大项目(12&ZD227);国家自然科学基金青年项目(61103089);山东省优秀中青年科学家科研奖励基金(BS2013DX020);鲁东大学人文社会科学研究项目(WY2013003)。
TP391
A
猜你喜欢
电子制作(2022年1期)2022-01-28
电子制作(2021年14期)2021-08-21
非公有制企业党建(2017年10期)2017-11-03
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
电脑知识与技术(2016年13期)2016-06-29
海峡姐妹(2016年2期)2016-02-27
