
基于随机森林的产品垃圾评论识别
2015-04-21 08:43何珑
中文信息学报 2015年3期
何 珑
(1. 福州大学信息化建设办公室,福建 福州 350108; 2. 福建省超级计算中心,福建 福州 350108)
基于随机森林的产品垃圾评论识别
何 珑1,2
(1. 福州大学信息化建设办公室,福建 福州 350108; 2. 福建省超级计算中心,福建 福州 350108)
目前的产品垃圾评论识别方法只考虑评论特征的选取,忽略了评论数据集的不平衡性。因此该文提出基于随机森林的产品垃圾评论识别方法,即对样本中的大、小类有放回的重复抽取同样数量样本或者给大、小类总体样本赋予同样的权重以建立随机森林模型。通过对亚马逊数据集的实验结果表明,基于随机森林的产品评论识别方法优于其他基线方法。
产品垃圾评论;不平衡问题;随机森林
1 引言
近几年,互联网在很大程度上改变了消费者的消费观以及消费意见的反馈途径,网上购物倍受青睐[1]。同时,很多商业网站让他们的顾客在购买产品时对该产品进行评论,以获取对产品有价值的信息。这些观点信息同样对其他潜在用户至关重要。
由于网络的开放性,人们可以在网站上任意书写评论,这导致评论的质量低下,甚至产生垃圾评论,即由一些用户蓄意发表的不切实际、不真实的、有欺骗性质的评论,其目的是为了提升或者诋毁某一产品或某一类产品的声誉,从而误导潜在消费者,或者干扰评论意见挖掘和情感分析系统的分析结果[2]。近几年,国内外针对产品垃圾评论展开了广泛的工作。文献[2-5]在考虑评论文本、产品描述、用户评分、用户投票等信息下,对产品垃圾评论进行识别,并据此总结出识别规则,但这类方法忽略了数据集的不平衡问题,识别精度有待进一步提高。
本文针对产品垃圾评论中数据集的不平衡问题,结合显著性检验[6],提出了基于随机森林的产品垃圾评论识别方法。该方法通过平衡随机森林算法和加权随机森林算法有效消除了不平衡数据集的影响,大幅度提高产品垃圾评论识别精度。
本文主要结构如下: 第2节介绍垃圾评论识别的相关工作,第3节介绍基于随机森林的产品垃圾评论识别方法,第4节是实验内容与结果的分析,最后一节是总结与展望。
2 相关工作
目前许多研究工作已经把产品垃圾评论的识别从对文本及相关特征的研究转移到对评论者行为的研究。文献[7-9]针对垃圾评论者特有的行为,定义相关行为规则挖掘可疑评论者,取得较好的效果,得到众多学者的关注。
在产品垃圾评论及评论者的研究不断取得进展的同时,在线评论中的垃圾评论者小组引起了相关学者的关注,他们比单独的垃圾评论者危害更大,甚至能完全主导某产品的评论情感倾向。文献[10-12]综合考虑了评论者小组、评论者和被评论产品之间的关系,与现有方法形成互补,能找到更加难以检测和精细的垃圾活动。
但目前的工作忽略了产品垃圾评论识别中的数据集不平衡问题。因此,本文在文献[6]工作的基础上,提出基于随机森林的产品垃圾评论识别方法,以获得的显著性特征建立随机森林模型进行识别。实验结果表明,本文的模型不仅优于基线方法,而且在精度上有了很大的提高。
3 基于随机森林的产品垃圾评论识别
产品垃圾评论识别问题实质上是一个二分类问题,将评论分为垃圾评论和非垃圾评论。目前的产品垃圾评论识别相关方法主要考虑了如何利用评论文本、产品描述、用户评分、用户投票等信息对垃圾评论进行识别,忽略了产品垃圾评论数据集的不平衡性[13]。不平衡数据集通常会带来以下问题[14]:
(1) 容易导致小类样本的稀疏和缺失;
(2) 分类器难以区别小类样本和噪声样本;
(3) 决策面偏移问题,如基于特征空间决策面的分类器SVM,由于小类样本少,分类器扩大决策边界,导致最后训练的实际决策面偏离最优决策面;
(4) 评价指标问题: 传统的分类器以高的分类正确率作为目标,但是在不平衡数据集问题中,以高正确率作为目标的话,造成分类器偏向于大类而忽视了小类,导致小类分类效果明显较差。例如,假设一个样本集中小类和大类的样本比例为1∶99,如果以高正确率为目标,那即使将所有的样本都分为大类,仍然还是可以达到99%的高正确率。
这些问题导致传统分类方法在对不平衡数据集进行分类时,其性能就远不如在均衡数据集上的表现。因此,本文提出了基于随机森林的产品垃圾评论识别方法,旨在应对数据集的不平衡问题,有效提高产品垃圾评论的识别精度。
针对本文数据集,定义每个评论表示为特征向量{xi,yi,1≤i≤7 315},其中xi={xi,1,xi,2,…,xi,n},yi={0,1},n为模型使用特征个数,则每个特征可以表示为向量Xj={x1,j,x2,j,…,x7 315,j,1≤j≤n}Τ。
3.1 随机树算法
随机树是指计算机随机选择节点的生长方式而构成的树状数据结构,是决策树的一种。多棵随机树可以组成随机森林,其算法描述如表1所示:
其中,ID3算法依据的是信息增益来选择属性。设训练集D,其中|D|是D中训练样本的个数,Ci(i∈{1,2,…,m})是类别属性第i个取值对应的样本数,pi为Ci在D中出现的概率,即pi=Ci/|D|。则有

(1)
按某属性A对D进行划分,假设A有v个取值{a1,a2,…,av},则按照属性A对训练集D中的实例进行分类还需要的信息量如式(2)所示。
(2)
则属性A上的信息增益为:InfoGain(A)=Info(D)-InfoA(D),属性的信息增益越大说明根据该属性对D进行划分之后,D中的每一个实例进行正确分类还需要的信息熵越少,即系统更趋于有序。ID3算法选取信息增益最大的属性作为每个节点的分裂属性递归地构造决策树。
3.2 随机森林
随机森林(RF,RandomForest)是由L.Breiman[15]于2001年提出的。随机森林是一个组合分类器,由决策树构成随机森林的基础分类器。单棵决策树可以按照一定精度分类,为了提高精度,很简单的方法就是种植一片森林,并让所有决策树参加投票,选出投票最多的分类。这就是随机森林的思想基础。
3.3 基于随机森林的产品垃圾评论识别方法
在文献[16]中,Chen等提出了两种使用随机森林来处理不平衡数据集分类问题的方法,一种是基于代价敏感学习的方法,另一种基于样本采样技术。他们采用了准确率、召回率、F值等评价指标对两种方法进行实验,实验结果证明了该两种方法能有效提升小类的预测精度,同时,该方法也是现有方法中性能最优的。
本节我们将介绍随机森林是如何结合最经典的两种分类器构建方法,装袋法(bagging)和Adaboost方法来处理产品垃圾评论中的不平衡数据集问题。
3.3.1 平衡随机森林(BalancedRandomForest,BRF)算法
Bagging方法: 对原始实例数为N的数据集,每一个新的训练集都是通过一种叫做步步为营法(bootstrapping)随机重复采样得到的,即对N个实例有放回的重复采样N次得到训练集。应用这种方法生成的训练集一般只包含原始实例大约67%的样本,其余的样本作为袋外数据(OBB)用于测试[17]。
Bagging+BRF算法如以下陈述:
Step1: 针对本文不平衡数据集(x1,y1),…,(xn,yn),其中随机森林的每一次迭代,从128个重复评论中以bootstrapping的方式进行N次重复采样,同时从非重复样本中随机抽取同样的样本数;
Step2: 基于每一个步步为营样本,构建一棵随机树。
Step3: 重复Step1-2,得到期望的随机树数量。
Step4: 让每一棵树都对输入的向量xi进行投票。
Step5: 计算所有的投票数,其中票数最高的分类就是向量xi的分类标签。
3.3.2 加权随机森林(WeightedRandomForest,WRF)算法
Adaboost算法是由FreundandShapire[18]1996年正式提出的,是在boosting算法的基础上发展而来,它克服了boosting算法的诸多缺陷,在机器学习领域受到极大的关注。
Adaboost+WRF算法描述如下:
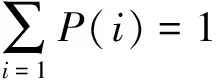
Step2: 调用随机森林算法进行N次迭代,每次迭代过程中,样本权重参与寻找最佳分裂点。在每棵树的终节点,样本权重同样也被考虑在内,每个终节点的预测类别是由“加权多数投票”方式决定的,从而得到一个预测函数序列h1,h2,…,hN,对每个预测函数hi也根据它们的预测效果赋予不同的权重θi,效果越好,则权重越大。
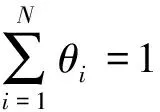
以上两种方法中BRF的效率高于WRF,这是因为BRF只使用部分数据集进行训练,而WRF需要完整的数据集,但WRF分类精度明显高于BRF。
4 实验结果及其分析
4.1 语料
本文使用了由BingLiu在网上提供的来自Amazon的数据集,如表2所示。使用该数据集的原因是它的数据量大,且Amazon作为最成功的商业网站之一,拥有着相当长的历史,使用该网站提供的数据集是相当合理的。本文的实验就是从mproducts领域中随机抽取了部分评论进行研究,在保留同一用户对同一产品的最新评论后,获得7 315个评论,其中重复评论有128个,大类和小类的比例约为56∶1,数据集的不平衡性相当大。
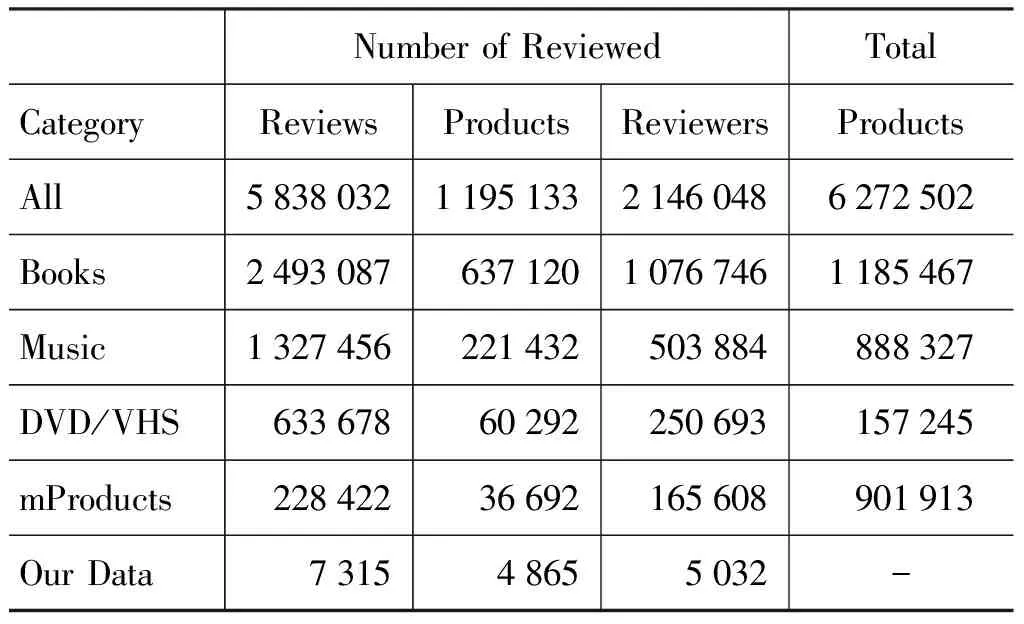
表2 Amazon数据集
4.2 实验结果及其分析
本文是以文献[6]的研究工作为基础,分类所采用的所有特征以及显著性特征均为文献[6]中所述的特征,本文将不再详细说明。本文实验以WEKA[19]作为实验平台,以F值和AUC值(曲线下面积)作为主要评价指标,比较了不同基线方法与随机森林的性能差别以及不同参数对随机森林识别性能的影响,同时,在实验中采用十倍交叉验证的方法。针对基线方法与随机森林的实验结果如表3所示。
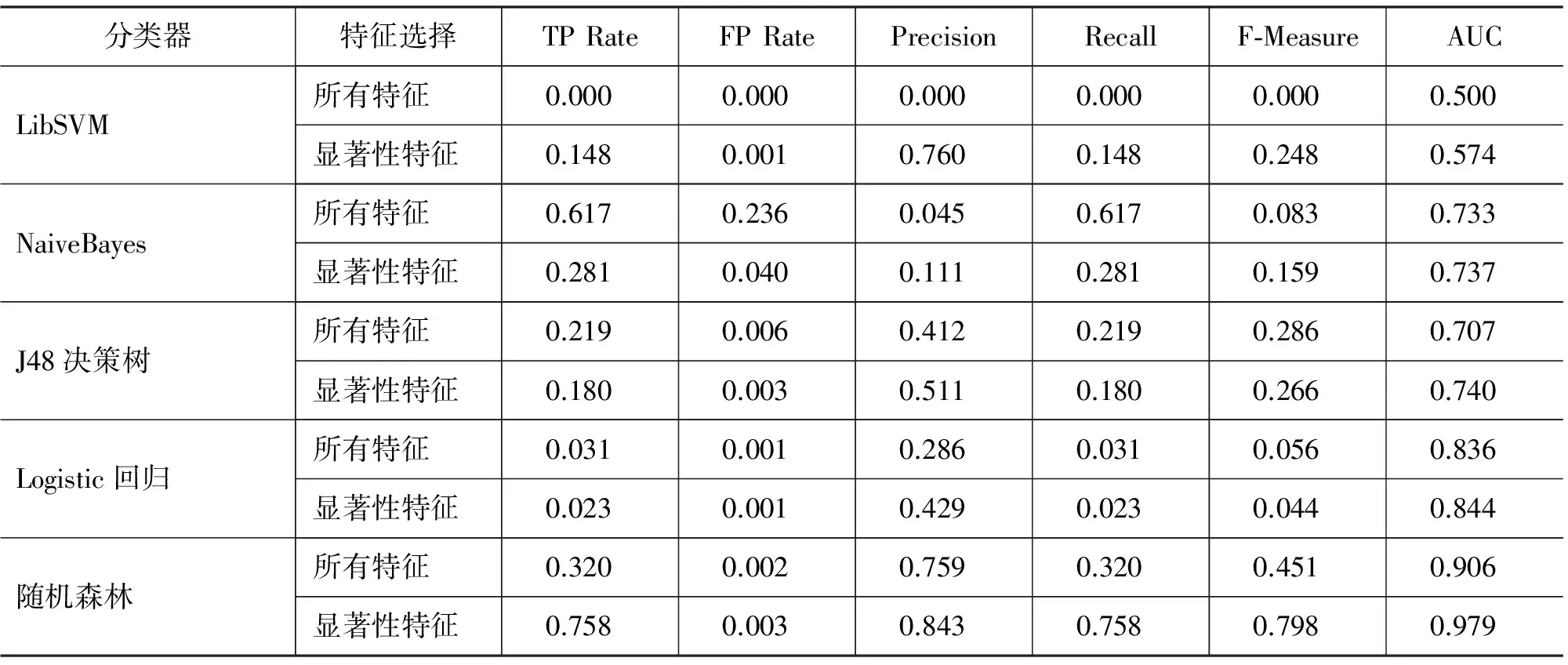
表3 随机森林与基线方法的识别效果
从表3实验结果可以看出:
(1) 在基于所有特征的前提下,随机森林算法不仅AUC值达到90.6%,F值也是五者之中最高的,达到45.1%;SVM算法在默认参数下训练完全失败;J48的F值达到28.6%,但AUC值不高;logistic回归AUC值虽然高达83.6%,但F值低下,只有5.6%;
(2) 在综合应用文献[6]的显著性特征之后,Logistic回归模型、J48算法的AUC值和F值均没太大变化;SVM算法、NaiveBayes算法的F值有了明显的提高,但AUC值依然很低;随机森林F值从45.1%大幅提升到将近80%,AUC值也提升到97.9%。这充分说明了随机森林算法的性能优于其他四种基线算法,能够平衡由数据集不平衡引起的误差,同时也证明了显著性特征与随机森林算法的有效结合能进一步改进算法。
在随机森林算法中,不同的随机种子(S)、迭代次数(T)和不同分类器构建方法均会对实验结果有影响,针对不同参数及构建方法的实验结果如表4、表5所示。
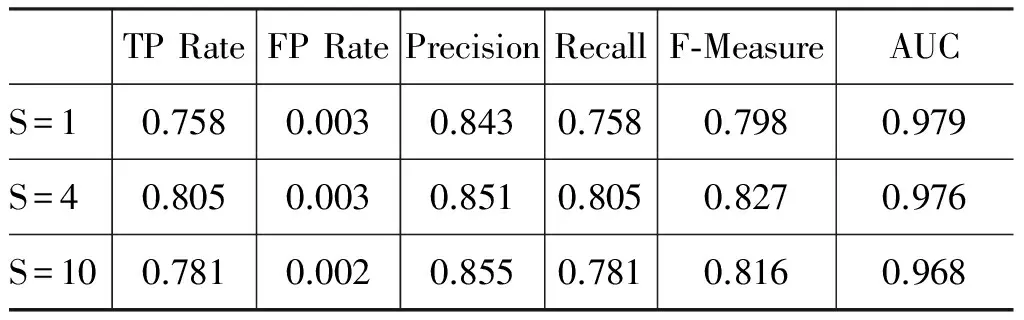
表4 随机森林中不同S的影响
从以上实验结果可以看出:
(1) 从表4可以看出,对不同的随机种子,随机树的F值最高有82.7%,最低达79.8%,变化较大,同时,三者AUC值均保持96.8%以上。说明不同的随机种子对随机森林的结果影响较大,也说明了随机森林算法能有效解决数据集的不平衡问题;
(2) 从表5可以看出,随着迭代次数T的增加,随机森林的F值有了明显的提高,其中Bagging算法迭代10次与20次F值相差达4.3%;
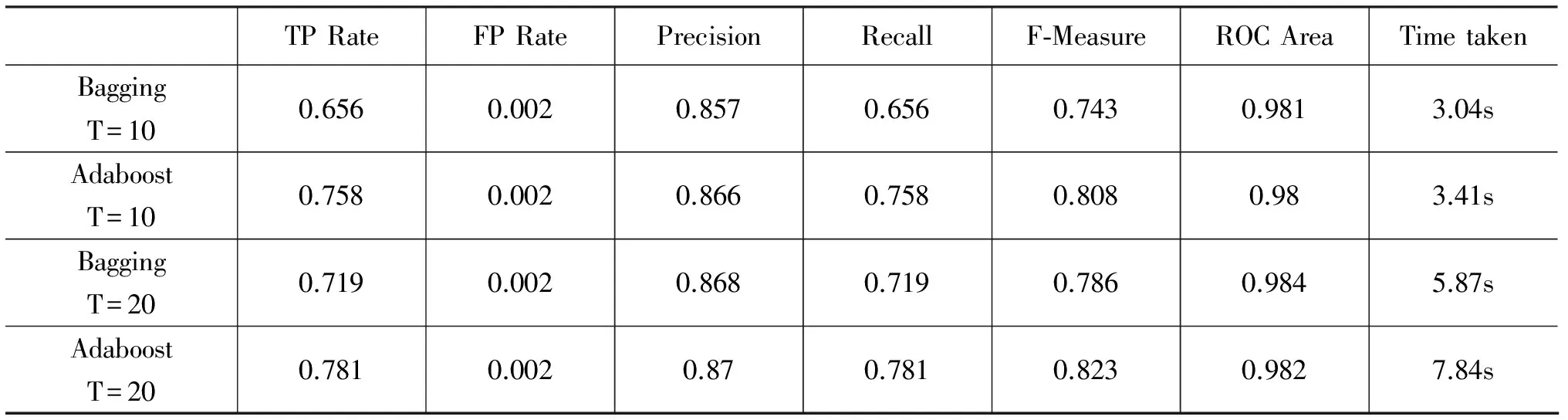
表5 随机森林中不同T/分类器构建方法的影响
(3) 从表5还可以看出,Adaboost算法的F值均大于Bagging算法的F值,但时间消耗上Adaboost算法要高于Bagging算法,同时两者的AUC值均高达98%以上。
综上所述,基于随机森林的产品垃圾评论识别方法优于基于SVM/NaiveBayes/J48/Logistic回归的基线方法,能够有效解决产品垃圾评论识别中的数据集不平衡问题,从而大幅度提高产品垃圾评论识别的精度;结合显著性的特征的随机森林算法能够进一步有效提高识别精度。
5 总结与展望
忽略产品垃圾评论识别中的数据集不平衡问题会导致分类精度的下降。结合显著性特征的随机森林算法能够有效解决这一问题。本文对N. Jindal等人提出的方法进行研究,在文献[6]的基础上,分析了存在的问题,提出利用更为合理的显著性特征建立随机森林模型,从而提高了模型质量。通过在亚马逊数据集的实验,验证了本文方法的有效性。我们未来的工作将致力于通过对模型参数的最优化来进一步提高识别精度。
致谢 感谢Bing Liu在个人网站为本文提供了实验数据集。
[1] 赵妍妍,秦兵,刘挺. 文本情感分析[J]. 软件学报,2010,21(8): 1834-848.
[2] N Jindal and B Liu. Review Spam Detection[C]//Proceedings of the 16th international conference on World Wide Web. New York: ACM, 2007:1189-1190.
[3] G Wu, D Greene, B Smyth et al. Distortion as a validation criterion in the identification of suspicious reviews[C]//Proceedings of the First Workshop on Social Media Analytics.New York: ACM, 2010:10-13.
[4] 何海江, 凌云. 由Logistic回归识别Web社区的垃圾评论[J].计算机工程与应用,2009,45(23):140-143.
[5] F Li, M Huang, Y Yang et al. Learning to identify review Spam[C]//Proceeding of the 22nd International Joint Conference on Artificial Intelligence. 2011: 2488-2493.
[6] 吴敏, 何珑. 融合多特征的产品垃圾评论识别[J]. 微型机与应用, 2012, 31(22): 85-87.
[7] J Staddon and R Chow. Detecting reviewer bias through web-based association mining[C]//Proceedings of the 2nd ACM workshop on Information Credibility on the Web. New York: ACM, 2008: 5-10.
[8] N Jindal, B Liu, and EP Lim. Finding Unusual Review Patterns Using Unexpected Rules[C]//Proceedings of the 19th ACM International Conference on Information and Knowledge Management. New York: ACM, 2009: 1549-1552.
[9] E Lim, VA Nguyen, N Jindal et al. Detecting Product Review Spammers using Rating Behaviors[C]//Proceedings of the 19th ACM International Conference on Information and Knowledge Management. New York: ACM, 2010:939-948.
[10] A Mukherjee, B Liu, J Wang et al. Detecting Group Review Spam[C]//Proceedings of the 20th international conference companion on World Wide Web. New York: ACM, 2011: 93-94.
[11] G Wang, S Xie, B Liu et al. Review Graph based Online Store Review Spammer Detection[C]//Data Mining (ICDM), 2011 IEEE 11th International Conference on. IEEE, 2011: 1242-1247.
[12] A Mukherjee, B Liu, N Glance. Spotting Fake Reviewer Groups in Consumer Reviews[C]//Proceedings of the 21st international conference on World Wide Web. ACM, 2012: 191-200.
[13] H He, E A Garcia. Learning from imbalanced data[J]. IEEE Transactions on Knowledge and Data Engineering, 2009, 21(9): 1263-1284.
[14] 陈振伟, 廖祥文. 结合AB-SMOTE和C-SVW的中文倾向性句子识别[J]. 福州大学学报(自然科学版),2012,40(3):49-54.
[15] L Breiman. Random forests[J]. Machine Learning, 2001. 45(1):5-32.
[16] C Chen, A Liaw, L Breiman. Using random forest to learn imbalanced data[C]//Proceedings of University of California, Berkeley, 2004.
[17] L Breiman. Bagging Predictors[J]. Machine Learning, 1996, 24(2):123-140.
[18] Y Freund, R Shapire. Experiments with a new boosting Algorithm[C]// Proceedings of the 13th International Conference. 1996: 148-156.
[19] http://www.cs.waikato.ac.nz/ml/weka/[OL]
Identification of Product Review Spam by Random Forest
HE Long1,2
(1. Information Construction Office, Fuzhou University, Fuzhou, Fujian 350108,China; 2. Fujian Supercomputing Center, Fuzhou, Fujian 350108, China)
Current review spam identification methods are focused on the feature selection, without addressing the imbalance of the data set. This paper presents a product review spam identification method based on the random forest, with the same number of samples extracted from the large and small class with replacement repeatedly, or with the same weight assigned to the large and small class. The experimental results on Amazon dataset show that the random forest method outperforms other baseline methods.
product review spam; imbalance problem; random forest

何珑(1971—),硕士,高级工程师,主要研究领域为操作系统、数据库、网络和信息安全及云计算、大数据分析挖掘等。E⁃mail:helong@fzu.edu.cn
1003-0077(2015)03-0150-05
2013-05-15 定稿日期: 2013-10-17
福建省自然科学基金(2010J05133)
TP391
A
猜你喜欢
科普童话·学霸日记(2021年2期)2021-09-05
汽车与驾驶维修(维修版)(2021年6期)2021-08-18
汽车与驾驶维修(维修版)(2021年6期)2021-08-18
当代陕西(2019年24期)2020-01-18
电子技术与软件工程(2019年18期)2019-11-18
中国惯性技术学报(2018年4期)2018-11-08
小太阳画报(2018年10期)2018-05-14
电子技术与软件工程(2017年14期)2017-09-08
中学生数理化·高二版(2016年8期)2016-05-14
航天返回与遥感(2014年5期)2014-07-31
