
搜索日志中中文人名自动识别
2015-04-21 08:43吕学强
中文信息学报 2015年3期
王 玥,吕学强,李 卓,舒 燕
(1. 北京信息科技大学 网络文化与数字传播北京市重点实验室,北京 100101;2. 北京拓尔思信息技术股份有限公司,北京 100101)
搜索日志中中文人名自动识别
王 玥1,吕学强1,李 卓1,舒 燕2
(1. 北京信息科技大学 网络文化与数字传播北京市重点实验室,北京 100101;2. 北京拓尔思信息技术股份有限公司,北京 100101)
搜索日志中人名识别一直是日志挖掘中的一个重点和难点,其结果好坏直接关系搜索引擎的检索效率和准确率。由于分析了长文本中人名识别方法在搜索日志中使用存在很多困难与不足,因而该文提出了一种在搜索日志中识别中文人名的方法。该方法将搜索日志中人名内部用字的概率特征引入条件随机场,再根据搜索日志的特点计算人名可信度提取搜索日志中的中文人名。在搜狗查询日志上进行实验,正确率平均达到了81.97%、召回率平均达到了85.81%,综合指标F值平均达到了83.79%。
人名识别;搜索日志;条件随机场;可信度
1 引言
近几年,随着互联网的飞速发展,搜索引擎的地位也在不断的上升,对于搜索日志的研究也逐渐成了学术界的热点问题。搜索日志中命名实体识别一直是日志挖掘中的一个重点和难点,其结果好坏直接关系搜索引擎的检索效率和检索准确率。命名实体识别主要包括: 人名、地名、机构名等实体。从近几年Dou Shen、Javier Artiles、张磊[1-4]等人的研究来看,人名在搜索引擎的查询结果中占很大的比例,如果能从搜索日志中自动挖掘出人名实体,那么就能够获得大量具有时效性和实用性的信息。
现有的人名识别方法可以归结为基于规则的方法和基于统计的方法两大类。基于规则的方法准确率相对较高,但是制定规则耗时耗力,且通用性和可移植性不高[5-8];基于统计的方法灵活性和鲁棒性较好,不需要太多人工干预,只要存在大规模的已标注并且校对好的语料库进行训练即可[9-15]。由于搜索日志具有简短、缺少上下文、内容多次重复出现、语句跳跃性强等特点,与长文本存在差异性,长文本中的人名识别方法很难直接应用于搜索日志进行人名识别。Marius Pasc等[16]人尝试使用提取模板的方法在英文的查询日志中中进行了命名实体识别。然而,由于中文本身存在的复杂性,上述的方法并不能被直接用于搜索日志中文人名的识别。因此,本文提出一种基于条件随机场的搜索日志中中文人名识别方法,主要解决搜索日志中中文人名的识别问题。
2 搜索日志中人名的特点
搜索日志是由搜索引擎的查询串构成的,在内容上与长文本存在一定的差异性。长文本是整句构成段落,段落再构成篇章而形成,搜索日志是由查询串组成。查询串形式具有多样性的特点,主要由整句、多个关键词、单独词语、单独短语等构成。从长度上看,长文本长度各异,但是以长句为主,而搜索日志中查询串的主要长度集中在2~35个字符范围内,相对于长文本较短。从重复性上分析,长文本前后文整句重复的概率很小,而搜索日志中查询串会出现大量的重复现象。
由于搜索日志和长文本有很大差异性,所以搜索日志与长文本中中文人名的存在形式也存在着很大的差别,如表1是搜索日志中中文人名的特点。

表1 搜索日志中中文人名特点
表1中列出的搜索日志中人名存在的各种特点,也正是导致长文本中人名识别方法在搜索日志中效果都不甚理想的原因之一。
3 搜索日志中中文人名识别方法
搜索日志中人名前后字词之间存在一定的连续性,可以将搜索日志中人名识别的问题转化成序列标记问题。而条件随机场正是专门解决序列标记问题的模型,因此本文选用条件随机场进行中文人名识别。
3.1 人名标记方法
本文采用四词位标记法[17]作为文本中字的序列标注方法,如表2。

表2 特征标记及其意义
3.2 人名特征及其特征取值
由于搜索日志中人名存在很强烈的用字特征,因此,很有必要建立人名知识库将用字特征引入条件随机场。
3.2.1 人名用字知识库的构建
本文使用的人名知识库包括姓氏表、单名用字表、双名首字表、双名末字表。
姓氏表整理方法: 提取百家姓、维基百科[18]中中国姓氏表和2000年11月《人民日报》中不重复的姓氏构成词表。单名用字表、双名首字表、双名末字表的整理方法: 将《人民日报》和“加加亚洲人名库[19]”中包含姓氏表中姓氏的人名抽取出来,同时统计所有人名中,每类用字出现的频次,然后将结果存储下来构成这三个表。
3.2.2 姓氏特征及取值
姓氏在中文姓名用字中出现的频度非常高,所以当前字是否在姓氏表中出现是中文人名识别的一个很重要的特征。
标注方法: 集合F{(k1,fk1),(k2,fk2),…(ki,fki)…(kn,fkn)}为姓氏用字集合,ki为第i个姓氏,fki为姓氏ki出现的频次,xi为当前字。
如果(xi,fxi)∈F,则xi标记为Y;如果(xi,fxi)∉F,则xi标记为N。
3.2.3 单字双字人名特征及取值
中文人名用字本身就有明显的特征,一些字在人名中大量重复出现。通过统计发现这些大量出现的字在单字人名、双名首字、双名末字中出现的概率也是相差很大的,所以本文加入人名用字特征。
将人名用字分为三类:
单字人名: “刘哲”中“哲”字;
双名首字: “刘亦菲”中“亦”字;
双名末字: “赵忠祥”中“祥”字。
单字人名标记方法: 集合W{(w1,fw1),(w2,fw2)…(wi,fwi)…(wn,fwn)}表示单字人名表,其中wi表示集合W中的第i个字,fwi表示wi的出现的频次,xi表示当前待标记字,函数Fre(W,xi)表示W集合中xi的词频。
如果Fre(W,xi)>0且pm
双名首字、双名末字的标记方法同单字人名,它们的不同之处就是查询词语的集合词表不同,在进行标记的时候阈值参数的数值可能不同。
3.3 特征模板的选取
考虑到人名用字、训练语料和姓氏用字之间的依存和共现关系,条件随机场的特征模板要进行合理的设计。识别中使用的模板文件,每个特征项都设定了与其相关的复合模板关系。
由于人名的上下文对人名识别会产生一定影响,表3的模板选取就表示字的上下文关联关系,从当前字开始,选取向前两字向后两字共五字的关联特征。

表3 字特征应用的特征模板
表4至表7表示人名用字特征模板的选取方式,以及人名用字的内在关联关系。
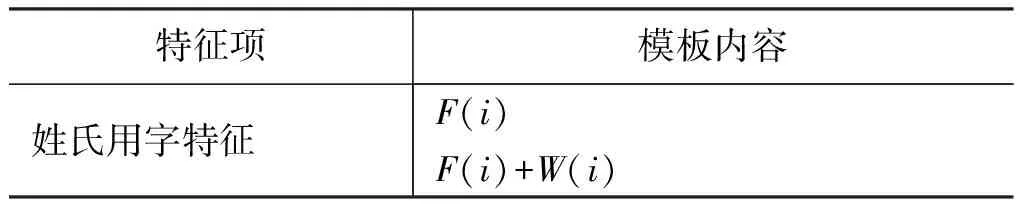
表4 姓氏用字特征应用的特征模板

表5 单名用字特征应用的特征模板

表6 双名用字特征应用的特征模板

表7 双名末字特征应用的特征模板
表3至表7中,i表示当前字所在位置,W(i)表示字i,F(i)字W(i)的姓氏特征标记,S(i)表示字W(i) 的单名用字特征标记,DF(i)表示字W(i)的双名首字特征标记,DL(i)表示字W(i)的双名用字特征标记。
3.4 训练语料的重组
由于搜索日志中人名有上下文严重缺失的特点。而人民日报中的语料,绝大多数是完整的句子,人名存在上下文。如果使用原始格式的训练语料加入条件随机场进行学习,模型很难学习到搜索日志中人名的这一特点,所以本文中方法将训练语料进行了修改和扩充。首先将训练语料中所有的中文人名提取出来,以每一行为一个人名的形式加入到原始的人民日报语料中再进行特征标记处理,这样条件随机场在训练的时候,既可以学习到有上下文的人名的标注形式,也能够学习到上下文缺失的人名的标记方式,这样使训练语料更加符合搜索日志中搜索串的特点。
4 基于可信度的人名召回
4.1 人名可信度
由于训练语料并不是基于搜索日志而是来源于人民日报的分词语料,人民日报属于新闻语料,并不能涵盖搜索日志语料的所有特点。因此,在训练的过程中,条件随机场很难学习到搜索日志的全部特点,这将导致最终人名识别结果不够完整。为此引入可信度的方法,对CRF漏识别的特定形式人名进行召回。
可信度是用来描述几个连续的中文字符构成人名的可能性的一种概率。本文将中文人名可信度定义为

(1)
其中,P(FirstName)表示姓氏用字可信度,P(Word)表示名字用字可信度。
姓氏用字可信度定义如下:
(2)
其中,fki表示姓氏表集合F中第i个姓氏ki的频次。
如果是单字名,名字用字可信度定义如下:
(3)
其中,fwi表示单名用字集合W中第i个人名用字wi的频次。
如果是双字名,名字用字可信度定义如下:
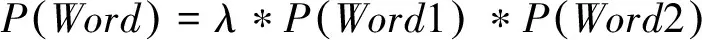
(4)
其中,fui表示双名首字用字集合U中第i个人名用字ui的频次,fvi表示双名末字用字集合V中第i个人名用字vi的频次,λ表示双名调节系数。
4.2 基于可信度的人名连词特征召回
搜索日志中大量出现“其他词语+人名1+连词+人名2+其他词语”这种形式的查询串,而识别的时候经常会出现“人名1”和“人名2”中只有一个被识别出来,本文通过如下方法将另一个人名也识别出来。
首先,从训练语料中抽取连词词表,将前后都为人名的连词抽取出来组成一个词表Q{q1,q2,...,qi,...,qn},其中qi表示抽取出的第i个连词。
其次,设R{r1,r2,...,ri,...,rn}是条件随机场识别后的查询日志,ri表示第i个查询串,ri[j]表示查询串ri中第j个字。如果ri[j]∈Q且(ri[j-m],...,ri[j-1])(m=2,3)是之前条件随机场识别出的人名,那么将(ri[j-2],ri[j-1])、(ri[j-3],ri[j-2],ri[j-1])分别计算人名可信度P(ri[j-2],ri[j-1])、P(ri[j-3],ri[j-2],ri[j-1]),取两者中较大的,如果较大的可信度达到一定阈值P1,那么将其标记为人名;如果ri[j]∈Q且(ri[j+1],...,ri[j+m])(m=2,3)是之前条件随机场识别出的人名,那么同理将(ri[j+1],ri[j+2])、(ri[j+1],ri[j+2],ri[j+3])分别计算人名可信度P(ri[j+1],ri[j+2])、P(ri[j+1],ri[j+2],ri[j+3]),取两者中较大的,如果较大的人名可信度达到一定阈值P1,那么将其标记为人名。
4.3 基于可信度的人名模板召回
由于搜索日志中人名出现位置有重复度高的特点,例如,[高圆圆]泳装图片、[郭晶晶]泳装图片,这两个搜索串中人名只要识别出一个另一个就可以通过抽取的模板进行匹配,从而将另一个识别出来。
模板分三种: 第一种,前置模板“美丽女人[陈好]”;第二种,是后置模板“[高圆圆]泳装照片”;第三种,是包含模板“天王巨星[刘德华]的演唱会”。
处理策略: 首先在集合Q中将所有的查询串中已识别的人名全部去掉,剩余部分单独存储即为模板,使用模板匹配Q集合中没有识别出人名的查询串,匹配过程查询串的内容必须要完全包含模板中的内容,而且未包含部分只能为连续的二至三个汉字,匹配成功后将这个连续二至三个汉字的字符串计算人名可信度,达到一定阈值P2的即标记为人名。
4.4基于可信度的人名重复性召回
由于搜索日志有同一人名多次大量出现的特点,比如: [霍震霆]与[朱玲玲]照片、[霍震霆]等查询串都出现了霍震霆,如果一个人名被识别,那么再次出现该人名的时候就可以直接判断出当前词语是不是已出现的人名。
处理策略: 将已识别的人名加入词表,进行可信度计算,达到阈值P3的直接存入人名词表,与原始搜索日志进行匹配,如果能够匹配,直接标记为人名。
5 实验结果与分析
对于统计方法,使用机器学习模型进行人名识别评测,往往需要一定规模的测试集。这种测试集一般可分为两种,一种是只含人名的句子集合,另一种是完全真实的语料。前者没有考虑到真实的语言环境,识别结果往往偏高。因为在真实语料中不含人名的句子大量存在,其中不是人名的成分可能会被错误识别出来而影响结果,但是这样的句子可能会被人为去除掉,所以结果并不能体现真实的效果。另一种是使用大规模的训练语料,在一个小规模的真实样本中进行测试,大规模的训练语料几乎包含了小型测试语料的所有内容, 这样的结果也并不客观。
本文为避免上述情况,将实验一共分五组,训练语料是2000年11月的《人民日报》,测试语料分别是在2008年6月1日至2008年6月5日的搜狗搜索日志[20]。每天的搜索日志都分别先去重,然后得到五天无重复的搜索日志,对于无重复的搜索日志分别随机抽取1 000条作为测试集。
本文中单名用字的阈值是8,双名首字阈值为20,双名末字为20。双名调节系数λ取0.5。连词特征人名可信度阈值取1.78*10-6。阈值P2取1.6*10-6。阈值P3取3.0*10-6。
5.1 评测指标
针对中文人名,本文采用了三个评测指标,即准确率(P)、召回率(R)和综合指标F值(F),其定义如下:
准确率:
(5)
召回率:
(6)
F值:
(7)
其中β是准确率P和召回率R之间的权衡因子,这里,P和R同等重要,因此取β=1,此时F值称为F1值。
5.2 结果分析
本文选用最新版ICTCLAS的人名识别结果和郭家清的一种基于条件随机场的人名识别方法[21]作为对比试验,表8是两个对比实验与本文中条件随机场的识别方法的识别结果对比。
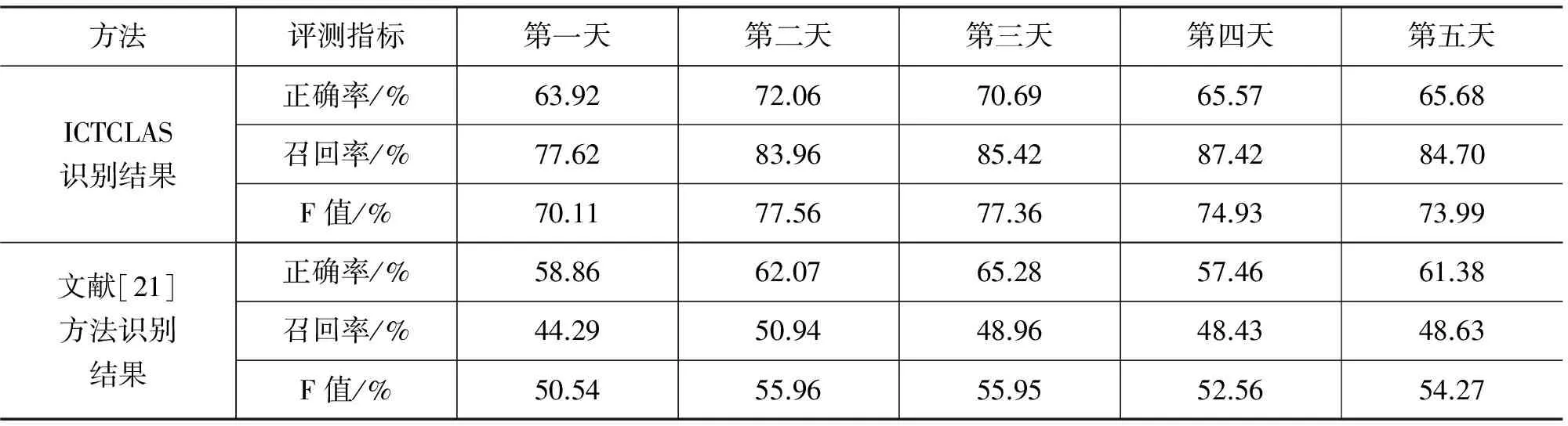
表8 ICTCLAS、文献[21]与条件随机场识别结果

续表
从表8可以看出在五天的搜索日志上,本文条件随机场的识别方法正确率平均比ICTCLAS的识别结果高14.73%,召回率平均提高了0.01%,综合效果F值平均提高了8.22%;比文献[21]的方法正确率平均提高了21.31%,召回率平均提高了35.59%,综合效果F值平均提高了29.16%。所以从总体效果上看,本文的方法在搜索日志中识别中文人名是有效的。
本文方法召回率在第三天的数据上低于ICTCLAS,是由于训练语料只是用了一个月的人民日报,所以训练集和测试集产生的数据稀疏非常严重,第三天的日志这种现象尤为明显,所以召回率略有下降,经过补充训练集,这种缺陷就可以被弥补。
表9是在条件随机场的识别结果上加入人名可信度的方法的结果。
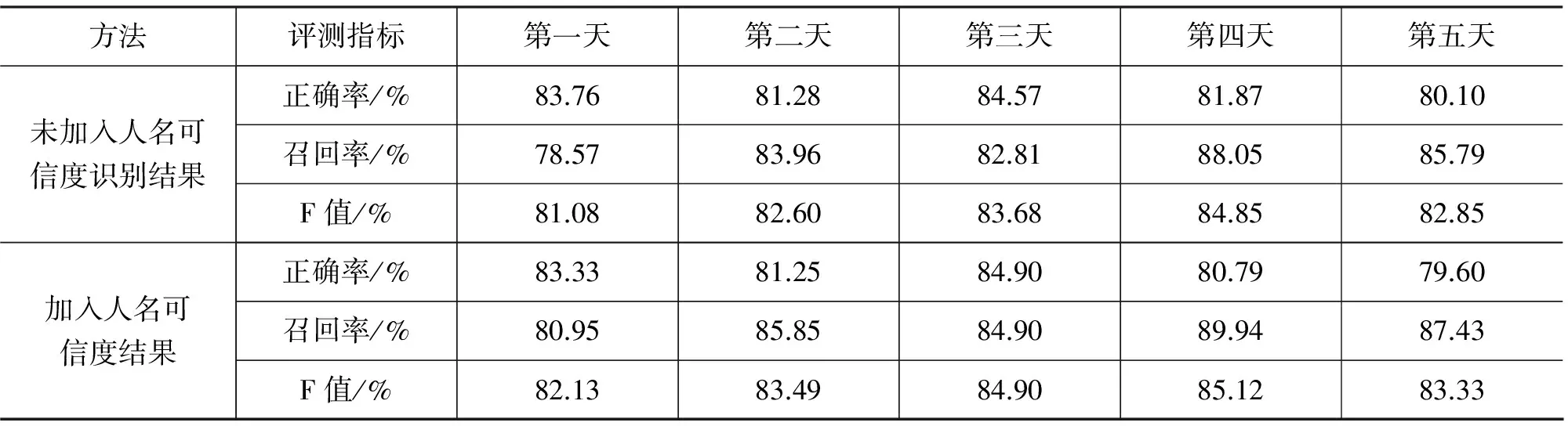
表9 加入人名可信度和不加入人名可信度的结果对比
从表9可以看出在五天的搜索日志上,加入人名可信度方法后,总体效果比条件随机场直接识别出的结果又有所提升,综合指标F值提升了0.78%,说明人名可信度方法也是行之有效的。
表10是本文方法的总体结果。
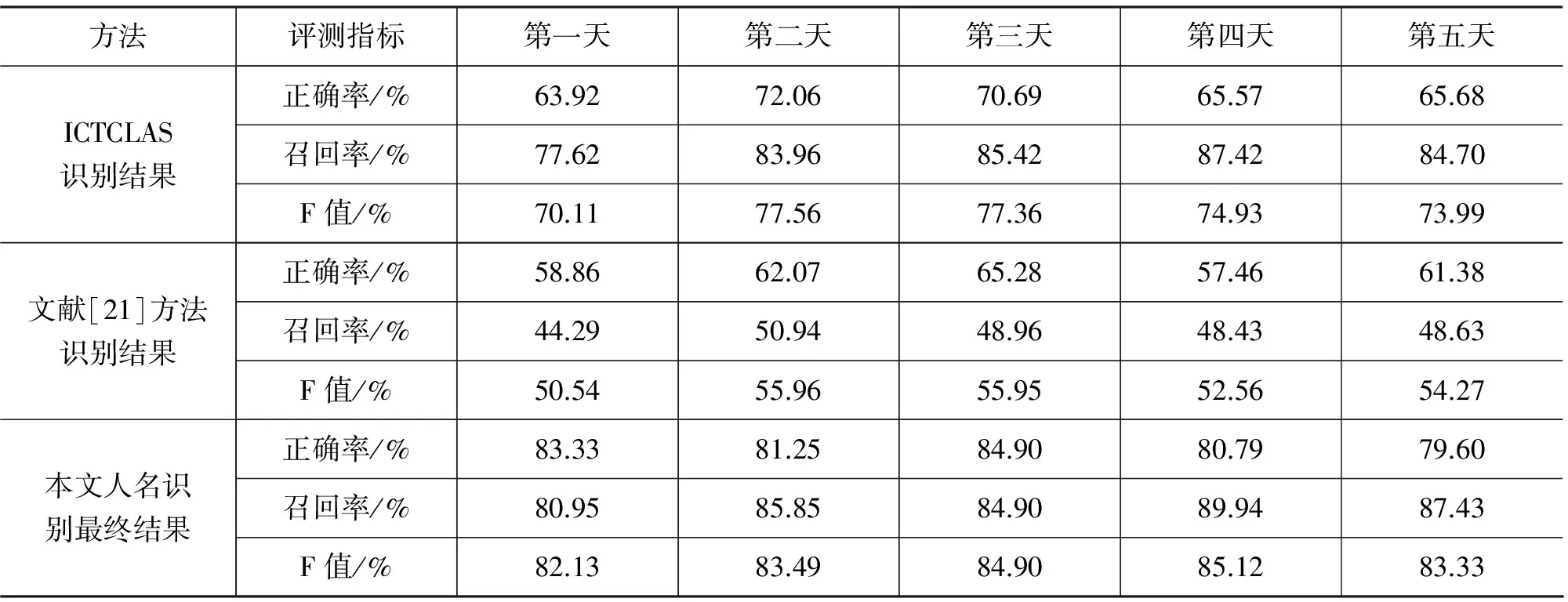
表10 Baseline方法与最终结果对比
从五天的结果来分析,本实验中方法识别的结果,正确率平均比ICTCLAS要高14.39%,召回率平均高1.99%,综合指标F值平均高 9.00%;与文献[21]的方法相比,正确率平均高20.96%,召回率平均高37.56%,综合指标F值平均高29.94%;无论单项还是总体识别效果都要优于对比方法。
在搜索日志中识别人名,正确率比召回率更重要。如果需要在搜索日志中挖出一个人名词典,假设从一亿条搜索日志中挖出了1 000万条人名,这么庞大的数据量是不可能进行人工校对的,只有保证抽取结果有较高的正确率的情况下,识别结果才可以被直接应用,对于学术研究或工程应用才能够产生价值。
6 结论
本文系统地阐述了中文人名在日志中的构成形式及其特点,分析了长文本中的人名识别方法应用在搜索日志中进行中文人名识别的缺陷和不足。而后,本文提出了一种基于条件随机场的人名识别方法,利用日志中人名的特点,进行中文人名的识别。通过对五天去重的搜狗日志进行的实验能看出,本文方法较大地提高了日志中人名识别的效果。但是由于国内外资源的限制,现在搜索日志中没有已标记好的权威语料可以作为训练集,而手动制作搜索日志的标记语料,费时费力。因此,本文选定通用语料人民日报并对其进行重组作为训练集,目的是为了半自动地构建已标记的日志语料,为搜索日志的进一步研究工作奠定基础。本文训练语料的规模很小,如果能够扩大训练语料,最终识别结果还会有很大上升的空间。我们的下一步研究工作就是半自动地制作已标记的搜索日志语料,并将本文方法进一步细化,然后将已标记的搜索日志语料作为训练集合,深入研究并推广,使其应用在地名、机构名、术语、缩略语等其他搜索日志未登录词的识别中。
[1] Downey D,Broadhead M,Etzioni O.Locating complex named entities in Web text[C]//Proceedings of the 20th international joint conference on artifical intelligence.San Francisco,CA: Morgan Kaufmann Publishers Inc.2007: 2733-2739.
[2] Shen D,Walker T,Zheng Z,et al. Personal nameclassification in Web queries[C]//Proceedings of the international conference on Web search and web datamining. New York,NY: ACM,2008: 149-158.
[3] Artiles J,Gonzalo J,Verdejo F. A testbed for people searching strategies in the www[C]//Proceedings of the 28th Annual International ACM SIGIR Conference on Research and Development in Information Retriev - al. New York,NY: ACM,2005: 569-570.
[4] 张磊,王斌,靖红芳等.中文网页搜索日志中的特殊命名实体挖掘[J].哈尔滨工业大学学报,2011,43(5):119-122.
[5] 罗智勇,宋柔.一种基于可信度的人名识别方法[J].中文信息学报,2005,19(3): 67-72,86.
[6] 宋柔.基于语料库和规则库的人名识别方法[M].计算语言学研究与应用,北京:北京语言学院出版社,1993年.
[7] 郑家恒,李鑫,谭红叶.基于语料库的中文姓名识别方法研究[J].中文信息学报,2000, 14(1):7-12.
[8] 时迎超,王会珍,肖桐,胡明涵. 面向人名消歧任务的人名识别系统[J]. 中文信息学报,2011,25(3): 17-22.
[9] 李波,张蕾. 基于错误驱动学习和知网的中文人名识别[J]. 计算机工程,2012,38(12): 179-181.
[10] 张华平,刘群.基于角色标注的中国人名自动识别研究[J].计算机学报,2004,27(1): 85-91.
[11] 毛婷婷,李丽双. 基于混合模型的中国人名自动识别[J].中文信息学报,2007,21(2): 22-28.
[12] 李中国,刘颖.边界模板和局部统计相结合的中国人名识别[J].中文信息学报,2006,20(5): 44-50,57.
[13] Brown P, De Souza P,Mercer R, et al. Classbased n-gram models of natural language[J]. Journal Computational Linguistics,1992,18(4): 467-479.
[14] Chen H H,Ding Y W,Tsai S C,et al. Description of the NTU system used for MET2[C]//Proceedings of the 7th Message Understanding Conference.[S. l.]: [s. n.],1998.
[15] Joachims T. Text Categorization with support vector machines: Learning with many relevant features[J]. Springer, 1998,1398(23): 137-142.
[16] Pasca M. Weakly-supervised discovery of named entities using Web search queries[C]//Proceedings of the 16th International Conference on Information and Knowledge Management. New York, NY: ACM, 2007:683-690.
[17] 黄昌宁,赵海.由字构词——中文分词新方法; 中文信息处理前沿进展——中国中文信息学会二十五周年学术会议论文集[C]//中国中文信息学会二十五周年学术会议,2006.
[18] 维基百科.常见姓氏列表[OL].[2012].zh.wikipedia.org/wiki/常见姓氏列表.
[19] 姚勤智.亚洲人名词库[OL]. [2012] http://bbs.jjol.cn/showthread.php?t=2001.
[20] 搜狐研发中心.用户查询日志[OL]. [2012].www.sogou.com/labs/dl/q.html.
[21] 郭家清,蔡东风等.一种基于条件随机场的人名识别方法[J].通讯和计算机,2007,4(2)27-30.
Automatic Identification of Chinese Names in Search Logs
WANG Yue1, LV Xueqiang1, LI Zhuo1, SHU Yan2
(1. Beijing Key Laboratory of Internet Culture and Digital Dissemination Research, Beijing Information Science and Technology University,Beijing 100101,China; 2. Beijing TRS Information Technology Co., Ltd, Beijing 100101,China)
Search log name recognition has been a focus in Log Mining, which has direct impact on search engine’s retrieval efficiency and accuracy. The paper analyzes the drawbacks of name identification methods for long texts when applied to search logs, and proposes a method to identify Chinese names in search logs. The method employs the name internal word probability extracted from search query logs by the Conditional Random Fields, then estimates the credibility of person name according to the characteristics in the search log. Experimental results on Sogou query logs show that our approach reaches 81.97%accuracyand 85.81% recall on average, yielding F-measure of 83.79% .
recognition of person names; search query logs; conditional random fields; reliability

王玥(1987—),硕士,研究实习员,主要研究领域为中文信息处理、大数据处理。E⁃mail:butcher20@163.com吕学强(1970—),博士,教授,主要研究领域为中文信息处理、多媒体信息处理。E⁃mail:lxq@bistu.edu.cn李卓(1983—),博士,讲师,主要研究领域为移动互联网。E⁃mail:lizhuo@bistu.edu.cn
1003-0077(2015)03-0162-07
2013-04-08 定稿日期: 2013-07-18
国家自然科学基金(61171159、61271304 );北京市教委科技发展计划重点项目暨北京市自然科学基金B类重点项目(KZ201311232037);北京信息科技大学网络文化与数字传播北京市重点实验室开放课题(ICDD201203 )
TP391
A
猜你喜欢
奇妙博物馆(2022年9期)2022-09-28
小天使·一年级语数英综合(2022年3期)2022-04-16
国际医药卫生导报(2022年5期)2022-03-18
通信技术(2021年12期)2022-01-25
汉字汉语研究(2021年1期)2021-06-11
蚌埠医学院学报(2020年1期)2020-12-11
汉字汉语研究(2018年3期)2018-11-06
作文世界(小学版)(2017年8期)2017-09-07
——以“把”字句的句法语义标注及应用研究为例
中文信息学报(2017年6期)2017-03-12
外语教学理论与实践(2014年2期)2014-06-21
