
基于自然标注信息和隐含主题模型的无监督文本特征抽取
2015-06-09 23:45饶高琦于东荀恩东
中文信息学报 2015年6期
饶高琦,于东,荀恩东
(1. 北京语言大学 大数据与语言教育研究所,北京 100083; 2.中国语言政策与标准研究所,北京 100083)
基于自然标注信息和隐含主题模型的无监督文本特征抽取
饶高琦1,2,于东1,荀恩东1
(1. 北京语言大学 大数据与语言教育研究所,北京 100083; 2.中国语言政策与标准研究所,北京 100083)
术语和惯用短语可以体现文本特征。无监督的抽取特征词语对诸多自然语言处理工作起到支持作用。该文提出了“聚类-验证”过程,使用主题模型对文本中的字符进行聚类,并采用自然标注信息对提取出的字符串进行验证和过滤,从而实现了从未分词领域语料中无监督获得词语表的方法。通过优化和过滤,我们可以进一步获得了富含有术语信息和特征短语的高置信度特征词表。在对计算机科学等六类不同领域语料的实验中,该方法抽取的特征词表具有较好的文体区分度和领域区分度。
自然标注信息;自然语块;隐含主题模型;领域特征;文体特征
1 引言
文本特征可以从两个方面得到体现:领域性和文体性。前者通过术语的形式得到体现,而后者往往以惯用短语的方式出现。本文统称这两者为特征词语。对于自然语言处理而言,以词和短语形式体现出的文本特征,可以对分词、文本分类和自动文摘等诸多自然语言处理工作提供支持。
当前刻画文本特征的思想多来源于BOW(Bag of Words)模型或其变种,如带有领域词典的特征袋BOF模型[1],使用加入命名实体描写的FLIC[2],带有短语与N-gram描写的STC[3]和利用词间关系进行描写[4]等。它们大多在自建或通用测试集上达到了80%~95%的精确率。但是注意到现有的方法都以词项为语义的承载单元,因而过分依赖于分词和命名实体识别所提供的信息。中文分词虽然在通用语料上取得了较大进步,但在领域性较强的语料中,以术语为代表的未登录词依然是分词F值失落的重要原因。并且领域语料的标注语料十分稀少,训练十分困难。有些领域甚至连生语料也较难收集。基于以上困难,本文提出了一种无需分词与命名实体信息的无监督特征抽取方法,对面向领域语料的自然语言处理具有重要的价值。
自然标注信息(Natural Annotation)来自于语料本身,本质上是语言使用者提供的一种原始众包标注。在海量语料中对自然标注信息进行挖掘和获取几乎不需要标注语料,也极少需要先验知识,但需要大量训练语料。我们注意到以LDA(Latent Dirichlet Allocation,隐含狄利克雷分布)模型为代表的主题模型具有较好的无监督聚类功能,可以对词语间的隐含语义关系进行描述。我们利用这一特点对文本内容进行事先聚类,可以有效地克服自然标注信息需要海量训练语料的缺陷,将自然标注信息的使用大大“轻量化”,使特征词语的整个抽取过程可以在较小规模语料上完成。所以本文将主题建模和自然标注信息相结合,提出了“聚类-验证(Cluster-Verification)”方法,以较少的信息注入在小规模语料上获取文本的领域特征和文体特征。不同于以往的研究,本文方法不需要分词和命名实体信息。而且,其提取的特征并不拘泥于传统意义上词的范畴,而与阅读直觉更加相符。
本文的组织结构如下,第二节简述本文的工作基础即LDA模型和自然标注信息;第三节介绍基于LDA和自然标注信息的无监督“聚类-验证”方法;第四节将描述在计算机领域语料和环境、金融等其余五类领域语料上的实验和结果;第五节中,本文讨论特征词表的领域区分度和文体区分度,并描述了实验中出现的一种术语“生长现象”,第六节是结论和未来的工作。
2 工作基础
2.1 隐含主题模型
LDA模型最早由Blei、Ng和Jordan在2003年提出[5],用以发掘文本中的隐含主题。LDA模型是一种完全的生成模型,其假设一个文本集中存在以狄利克雷分布为先验的隐含主题分布,而对于任一主题也存在一个隐含的词选择分布。它的概率图表示如图1所示,M为文档集中的文档数目,N为文档中的词数。整个过程中的外显参数为词w和超参数α与β。其经验性的选择一般为α=50/T,β=0.01,T为主题个数。

图1 隐含主题模型LDA的概率图表示
2004年,Griffiths与Steyvers[6]开始采用吉布斯采样(Gibbs Sampling)学习LDA模型。本文使用的工具也采用了该采样方法。
2.2 自然标注信息
自然标注信息的概念来自互联网应用中的用户生成信息(User Generated Content)。它作为一个概念最早由孙茂松在2011年提出[7],用以从海量互联网数据中提取对自然语言处理可用的信息。其后饶高琦和黄志娥[8-9]将其发展,用于无监督发掘语料库中的词汇信息。不少学者也在中文分词和博客信息挖掘中使用自然标注信息进行尝试[10-12]。近几年,关于自然标注信息的研究日益广泛,逐渐扩展到信息检索[13]、社会计算[14]、情感分析[15]、信息抽取[16]。但总体而言,该领域的研究都需要较大的训练语料,并且方法仍处于起步阶段。
人类语言中蕴含有丰富的自然标注信息,其中以标点符号为代表的显性自然标注信息对词边界的探测具有重要意义。如式(1)所示,Pi为一处自然标注(如标点符号),如果其在中文里绝不与其他符号构成词,则其自身就形成了一处天然的词边界。

饶高琦[8]的工作发现,大规模语料中仅通过显性自然标注信息(主要包括标点符号、拉丁字母和阿拉伯数字)对字符串进行切分就可以获得《现代汉语词典》中几乎所有的词项。仅使用1998年《人民日报》的语料进行切分也可以获得现汉87.84%的词项。这样出现在显性自然标注信息之间的汉字字符串被称作“自然语块”(Natural Chunk),其边界是词边界的子集。
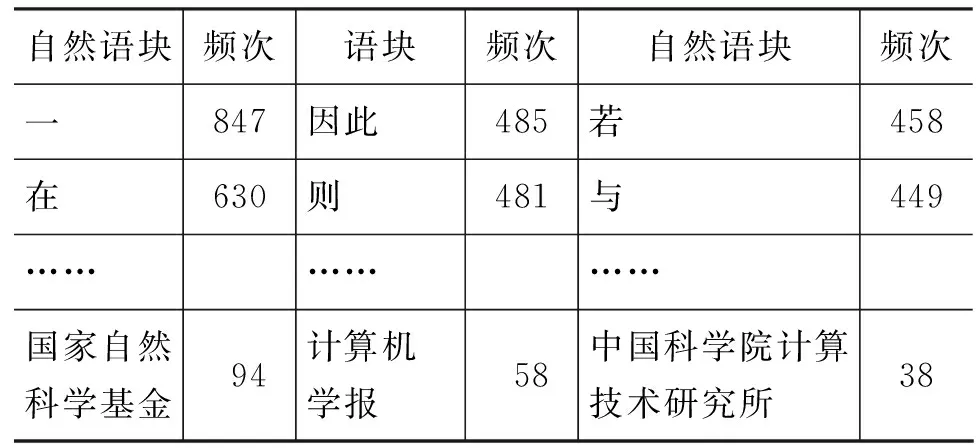
基于此,本文假设在领域语料中通过自然标注信息对字符串的切分也可以无监督的获得具有领域性的词语或语块。本文使用了来自2002年《计算机学报》的文本220篇。将标点符号、运算符号、拉丁字母和阿拉伯数字视作标记词边界的自然标注信息,并替换为标记‘SPACE’。这样整个语料仅存留汉字字符和‘SPACE’标记(替换后约217万字)。将由此形成的自然语块进行统计可以获得结果如表1所示。

表1 计算机科学语料上的自然语块举例
续表
自然语块频次语块频次自然语块频次一847因此485若458在630则481与449………………国家自然科学基金94计算机学报58中国科学院计算技术研究所38
由表1可注意到,由自然标注信息标识的词边界具有很高的正确率。饶和黄都报告了由显示自然标注信息而来的词边界识别在通用语料上具有较高正确率[8-9]。而在本文所使用的计算机科学领域语料中,显示标注信息和汉字字符结合成词的现象同样少见。少量例外现象多为如“χ2检验”这样处于半译写状态的外来术语。
原始语料在加入标点符号和拉丁字母的自然标注信息后形成加工语料。但是从上表所示的现象中还可以注意到,该抽取结果并不能体现出其作为科技论文的文体特征。另一方面在领域特性上,语块频次也无法显示其作为计算机语料的领域特性,排位最高的术语仅占到第80位。其他技术性术语排名更加靠后。其原因在于文本所具有的领域性并不完全由字词的频次体现。领域性的短语和词汇往往隐藏在文本所述的众多主题之中。因此有必要使用主题建模的方法对文本进行加工。
3 “聚类-验证”方法
3.1 LDA聚类方法
本文假设如果一个字符串可以形成稳定使用的词或惯用短语,则其内部成分(字或字组)出现的相对位置,上下文环境,甚至概率都趋于相近。又因为稳定使用的词(或短语)的子串共同参与了该词(或短语)的语义表达,则它们也倾向于出现在同一个主题之中。基于统计方法的主题建模通常以词簇来表现主题。在只存在字符边界(没有分词信息)和显性自然标注信息的语料中,构成一个词(或短语)的字(或字组),也倾向于被LDA模型聚类别同一主题内,如图2所示。

0号主题:型模化的简细存原表簇角顶三们外量向二我1号主题:概的念格所而则更应了及称被本某名前当优2号主题:信息中据来获确基的对相地是通部标首目三3号主题:存储问访一之和方共享可为表冲完执指比或图2 无词边界语料上的LDA聚类结果举例
形成上例的语料为《计算机学报》生语料,标点符号为停用词,处理单元是汉字,参数为α=0.23,β=0.01,迭代次数1 000。注意到,虽然LDA模型在生语料上体现出了较好的字聚类性能,但是构成某词语的汉字也可能构成其他主题的其它词语,因此一个词的内部构件间的概率并非完全相等。加之LDA模型的随机采样方法,这些都决定了一个主题虽倾向于包含构成一个词的众多子串,但其相对位置和词内原来的字序很少相同。对此,本文选取每个主题中出现概率最高的N个字,对其进行N x N的两两匹配,形成每个主题的候选词集S。又因为自然标注信息标记词边界具有高正确率的特性。我们使用它对S中的成员进行过滤和确认,经过优化打分(即自然标注信息的验证过程)之后形成筛选词表。
在生语料中,经过一次主题成员的两两匹配,所获得的候选词显然都是二字串。我们选取其中高置信度的成员,回标原始语料,从而增加原始语料内的词边界信息,以形成结构更加丰富的“字-词”混合语料。这一过程改变了LDA的聚类对象和概率空间,使得主题成员得到改变,从而再进行下一轮迭代后,获取更多特征词语。
3.2 自然标注信息验证过程
对LDA聚类产生的候选词表S中的成员,我们可以使用其在原始语料中与自然标注信息的相对位置来判断其成为词(或短语)的可能性。因为本工作采用了显性的自然标注信息如标点符号和数字。它们直接表达了作者的切分意图。在语料中,自然标注信息被替换为‘SPACE’符号。两个‘SPACE’标记之间的字符串(自然语块)Ci+1……Ci+n可以被认为是一个独立单元,其左右边界为词边界。它未必是语言学上的词,然而语块Ci+1……Ci+n与语言学上的词Word之间必然存在如下四种包含关系,如式(2)~式(5)所示。
即Word与自然语块的两个边界同时邻接(式(2),Word等于语块本身),与自然语块左边界邻接(如式(3)),与自然语块右边界邻接(如式(4))和成为自然语块的子串(如式(5))。
对于待验证的词(或短语),其是否稳定使用则可以用其在原始语料中出现四种蕴含关系的频次来衡量。因此使用式(6)来对候选词集成员打分。
Score=λbfb+λs(fl+fr)+λnfn
(6)
Score为候选词集成员成为一个稳定使用词的可能性打分,λb、λs、λn是四种蕴含状况所占有的权重。当一个候选词Word首尾与自然语块一致,都是词边界的时候,其成为一个语言学上的词的可能性最大。我们朴素地认为左邻接与右邻接的权重相等,且略小于两侧邻接的权重。考虑到使用语料的规模较小,有很多词没有机会出现在含有自然标注信息的上下文中,因此其在单纯汉字字符上下文中出现的频率也应被考虑。所以式(6)的参数有λb>λs>λn,且λb+2λs+λn=1的关系。
候选词表成员经过打分排序,形成重排过滤词表S_f。本文利用该词表,使用最大正向分词方法,对语料进行回标,使得原始语料的结构得到改变,词边界更加丰富,进而优化下一轮迭代中的聚类结果。整个聚类-验证的迭代过程如图3所示。
审计委员会特征与审计费用相关性的实证研究 ……………………………………………………………………… 陈 丹(3/32)

图3 聚类-验证方法的工作流程
4 实验
4.1 自然标注信息的注入
本文选取了来自2002年《计算机学报》的文本220篇,汉字字符约217万个。将标点符号、运算符号、拉丁字母和阿拉伯数字等显性自然标注信息替换为标记‘SPACE’后(语料样例见图4),共形成自然语块87 348个(举例见表1)。

SPACE在处理器内部有SPACE个开关控制这SPACE个端口之间的连接关系SPACE如图SPACE所示SPACE这SPACE个端口之间共有SPACE种连接方式SPACE如图SPACE所示SPACE处理器内部的这些开关可以在算法的执行过程中动态地置成开或关SPACE从而将整根总线分成一些相互独立的子总线SPACE图4 引入显性自然标注信息后的原始语料举例
本文使用马萨诸塞大学的开源工具Mallet实现LDA模型[17],并根据经验选择主题数目为220个,α=50/220,β=0.01,迭代次数1 000。第一轮主题训练结果的举例见图2。对每个主题我们选取出现概率最高的20个字进行N x N组合,形成每个主题的候选词集S。在自然标注信息验证过程中,使用式(6)打分。并在参数约束条件下,根据经验选取了λb=0.5, λs=0.2, λn=0.1。
第一次迭代共得到候选词4 708个,得分最高的15个如表2所示。因为原始语料没有词边界,则聚类对象均为单字,故得到的候选词都是二字词。

表2 过滤重排词表中打分前十五的词语举例
与表1相比,其对领域性的表达得到了较大增强。如果将单字词的组合视作词组,也判为抽取正确(因为其并未打破词边界),得分最高的600个候选词中正确率为92.7%。
并且注意到600个候选词中44个错例里有43个是和“的”字的组合,如“的对”、“的数”、“义的”等。出现这一现象的原因在于“的”字是现代汉语各类语料中出现频率最高的汉字。虽然很少与显性自然标注信息邻接出现,但是其自身过高的频率也拉高了它和自己邻接汉字组成的候选词的得分。可以观察到,“的”字组合错例中的另一个字都是计算机领域中高频词的首字或末字,如“的对(话、象)”和“的网(络、关、口、端、卡)”等。
“的”、“着”、“也”、“是”与“和”等在自然标注信息的研究中通常被称作隐性自然标注信息[8]。本文参考了饶在大规模通用语料中的统计结果,从选取词边界标记置信度较高的隐性自然标注信息11个*′是′,′和′,′的′,′也′,′着′,′与′,′个′,′在′,′之′,′有′,′为′,对候选词集S进行过滤,大大地提升了正确率(99.8%)。并且为了在语料回标过程中减少交搭型歧义的出现,我们将词语长度加入打分公式以获得更长的切分单元。修正后公式如式(7)所示。
Score′ =Length(Word)*Score
(7)
4.2 迭代实验

在处理器内部有SPACE个开关控制这SPACE个端口之间的连接关系SPACE如图SPACE所示SPACE这SPACE个端口之间共有SPACE种连接方式SPACE如图SPACE所示SPACE处理器内部的这些开关可以在算法的执行过程中动态地置成开或关SPACE从而将整根总线分成一些相互独立的子总线SPACE图5 第二轮迭代后回标形成的语料样例
对重新注入过自然标注信息的语料进行新一轮的迭代。
随着自然标注信息的注入,原始语料的边界信息更加丰富。抽取出的“总词表”规模随迭代次数明显增长(图6)。原始语料的字表规模为2 495个,即语料共使用汉字2 494种。在第20次迭代后词表规模则达到5 376个。

图6 重排过滤词表的规模随迭代次数的变化
通用词语的领域性和文体性特征均不明显。因此为了进一步提高重排过滤词表中术语和特征词组所占的比例,降低通用词语的排名,本文使用了1998年1月的《人民日报》所生成的词表对重排过滤词表进行剪枝。在诸次迭代所产生的词表中,剪枝率为5.2%~21.3%。
表3、表4和图7—图9分别为在计算机领域语料上迭代20次过程中,特征词表、通用词、术语、特征短语和抽取规模的变化。还可以看到词表正确率(既抽取出的字符串是词或词组,下同)基本稳定,术语和短语数量稳步上升。术语比例在七次迭代前后收敛。表5为第九次迭代时抽取结果的举例。可以看到抽取出的词项由短语(如“本算法”、“我们采用”)和术语(如“数字音频信号”、“软件体系结构”)构成。在第五部分中我们将对短语和术语分别进行分析。类似的,本文也在其他领域语料上进行了相同的实验。表6为在环境科学、金融学、医学和土木工程四个领域各选取期刊论文100篇,迭代九次后的结果。它们与在计算机科学语料上第九次迭代后的结果具有可比性。

表3 抽取词数和通用词比例

表4 特征词表中术语比例和特征短语比例

图7 短语数量随迭代次数变化(横轴为迭代轮数,主纵轴为词数,副纵为短语正确率)

图8 术语数量随迭代次数变化(横轴为迭代轮数,主纵轴为词数,副纵为术语正确率)

图9 特征词表规模与正确率(横轴为迭代轮数,主纵轴为词数,副纵为词语正确率)

表5 计算机学报语料下第九次迭代打分前二十词举例

表6 在非计算机领域语料上的迭代实验结果
5 实验分析和讨论
5.1 领域区分度
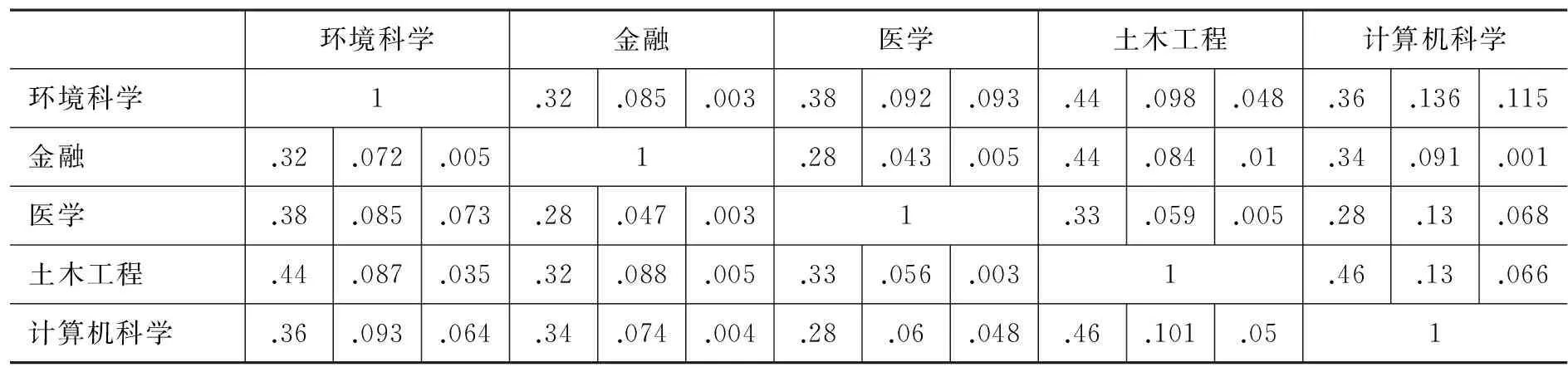
通过观察不同语料中特征词表,我们验证了特征词表和术语对领域性充分刻画的性能。如表7所示,学科间的差异通过词表重合率得到较好体现。如环境科学和医学、计算机科学术语重合较多,和土木工程、金融重合很少,这符合一般直觉。这样的差异是通过分词词表的比较无法获得的。其中我们对语料分词后,不同领域语料的最高频1 000个词(已去停用词)形成的词表之间的重合度远大于特征词表(术语+惯用短语)和其中术语的重合度且差异不大。这表明了抽取出的特征词表对不同领域文本具有很强的区分度。
表7 不同领域语料特征词表中的术语重合度(每一个单元格中左栏为两个领域分词词表中最高频1000词的重合比例,中栏为两个领域所抽取特征词语表的重合比例,右栏为两个领域中所抽取术语的重合比例)
环境科学金融医学土木工程计算机科学环境科学1.32.085.003.38.092.093.44.098.048.36.136.115金融.32.072.0051.28.043.005.44.084.01.34.091.001医学.38.085.073.28.047.0031.33.059.005.28.13.068土木工程.44.087.035.32.088.005.33.056.0031.46.13.066计算机科学.36.093.064.34.074.004.28.06.048.46.101.051
5.2 特征短语与文体区分度
对过滤后的特征词表进行标注和统计可以观察到随着迭代次数的增加,词表规模、术语和通用词的绝对数量都在增加,整体正确率基本稳定(图7—图9)。比例和绝对数量增长最为明显的是一类“特征短语”。文体特征可以由这类短语进行刻画。
本文将特征短语分为两类:术语增生而形成的和表示习惯用法的。如“服务器上”、“满足约束条件”和“基于斐波那契数列”这样的短语包含有术语,属于术语增生型,通常是术语和虚词或动词的组合。这是随着迭代次数增加,已形成的术语和高共现词语组合构成的。在特征短语中,术语增生而得的短语比例相对较少,而且集中于一些极高频术语的周围,如“在算法”、“算法中”、“由算法”和“算法进行”等,带有较强的领域性。
“一种基于”、“我们提出了”、“下面给出”和“如图”等则属于惯用短语。 对20次迭代后产生的短语进行统计发现18.9%的短语为术语增生型,惯用短语占81.1%。在学术期刊语料中,发现后者普遍体现了学术、技术写作的文体特点。由于上一部分实验中选取的五种语料均为科技论文,语体相同。本文以《圣经》中记录耶稣言行的马太福音为语料进行实验以进行对比分析。结果发现与计算机科学语料短语的重合度仅为1.4%。图10为两者惯用短语的举例。

《计算机学报》本文采用当且仅当实验表明我们给出了定义如下《马太福音》我告诉你们所以你们要记着说不要怕他们回答说
图10 马太福音与计算机学报的特征短语举例
注意到,特征短语与陈文亮[1]的工作中所提出的特征关联词有一定的相似性,但它的粒度超过复合词,多为短语。例如本文方法提取的“本文采用”比“本文”和“采用”两个词更能体现科技论文的文体性。因而文本特征中文体风格这一特点可以由特征短语体现。
5.3 复杂术语生长
在诸次迭代中,LDA聚类后形成的主题由“字簇”变为“字-词簇”,并逐渐向“词簇”变化(图11为第三次迭代中LDA聚类产生的簇)。类似的,在候选词表与后续的过滤重排词表中,词语长度也在逐渐增长,呈现出一种生长态势。如上一部分提到的第一次迭代中的错例“务器”,在第二次迭代中就和“服”组合成为“服务器”。“网络”是在第一次迭代中形成的二字术语。更长的术语“服务器网络”则在第17次迭代中出现。

0号主题:的超顶点图邻中有最小量通分树孔连矩阵含维次所相1号主题:区间值离散化概率属性模型参数叶斯样本学习贝数目合督处理数监混2号主题:时间本次可新并复图所重在及若将可以号结果多过3号主题:图形相似尺寸几何相似性特征识别图中元素结构约束对其性方法模式连接图11 第三轮迭代中经过LDA聚类后的主题举例
又如“自组织隐马尔可夫模型”这一复杂术语,它的生长过程如图12所示,图中数字为该字符串第一次出现时的迭代轮数。其中“自组织”和“模型”在语言学上都是该术语的子成分。而且它们很晚才发生组合。这是因为“自组织”和“模型”频率很大,而且本身可以出现在大量的其他术语中,因而作为“自组织隐马尔可夫模型”的组分不如其他组分(如“隐马尔可夫”)的结合程度高。
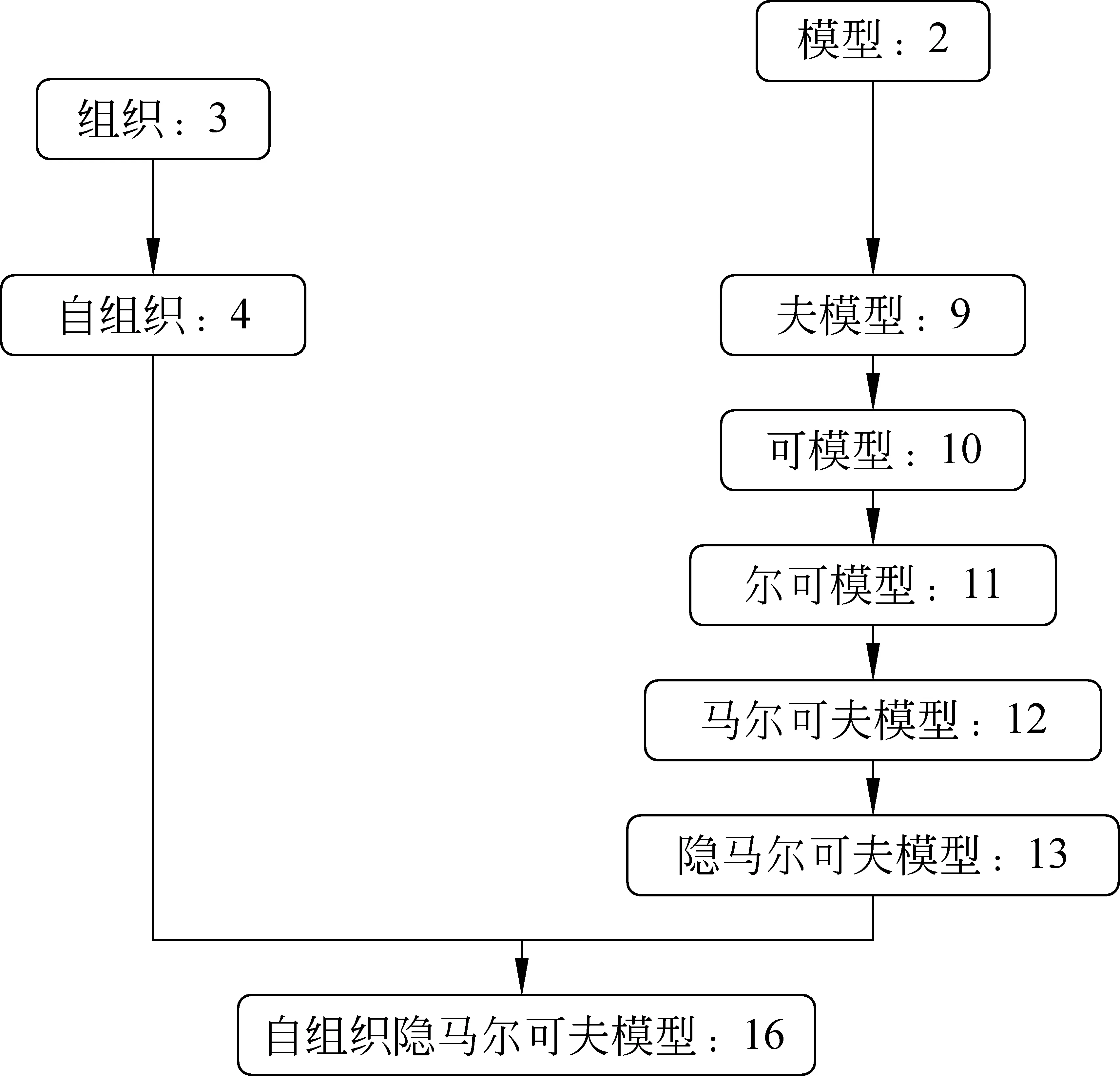
图12 “自组织隐马尔可夫模型”的生长过程
6 结论与展望
本文提出了无监督提取文本特征的“聚类-验证”方法:使用隐含主题模型在领域语料中进行无监督聚类,并采用隐性和显性的自然标注信息对提取出的候选字串进行验证,从而获得特征词表。统计显示该词表具有较高的正确率。通过对原始语料进行回标,我们改变主题模型的概率空间和字词分布。迭代多次后可以获得较好体现语料领域特征和文体特征的词语表。实验从217万字的计算机领域语料中获得了可表征其领域特性和文体特征的词语表,并在和环境、金融等语料上实验的比较中体现出了其领域性差异。我们还通过科技论文和《圣经》语料对比的实验结果,验证了该方法对语体差异描写的有效性。
本文方法使用主题模型对候选字符串进行预聚类,有助于加速通过自然标注信息发现词语的过程。相较于以往自然标注信息的使用方法,本方法所需训练语料少。全过程中待处理语料的信息注入仅限于显性自然标注信息(标点符号、运算符号、字母和数字)与11个隐性自然标记,在过滤优化过程中也仅使用了1998年1月人民日报词表。
不同于以往的研究,该方法不需要分词语料和命名实体信息。因而对缺乏资源的语种和语料处理具有较好的借鉴意义。然而本文只是无监督聚类和自然标注信息相结合的一次尝试。从表3的错例(如“出一”、“现了”)所代表的现象可以发现,如果在实验过程中注入饶高琦[8]的隐性自然标注信息将有助于效果的提升。
本文方法在主题模型本身的优化、求优打分的调参和自然标注信息的灵活应用等方面都有待未来更深入的研究。在词语生长这一现象中,如何使用不同无监督学习策略来控制和发掘词语的组分和生长过程,将对更深入的研究构词,实现词法自动分析带来巨大帮助。
[1] 陈文亮, 朱靖波, 朱慕华, 姚天顺. 基于领域词典的文本特征表示[J]. 计算机研究与发展, 2006, 42(12):2154-2160.
[2] 赵世奇, 刘挺, 李生. 一种基于主题的文本聚类方法[J]. 中文信息学报, 2007, 21(2):59-62.
[3] Zamir O and Etzioni O. Web Document Clustering: A Feasibility Demonstration [C]//Proceedings of the 21st International ACM SIGIR Conference on Research and Development in Information Retrieval(SIGIR 1998). Melbourne, Australia, 1998:46-54.
[4] 吴双, 张文生, 徐海瑞. 基于词间关系分析的文本特征选择算法[J]. 计算机工程与科学, 2012, 34(6):140-145.
[5] Blei D M, Ng A Y, Jordan M I. Latent Dirichlet Allocation [J]. Journal of Machine Learning Research, 2003, 3:993-1022.
[6] Griffiths T L, Steyvers M. Finding scientific topics [J]. Proceedings of the National Academy of Sciences of the United States of America, 2004, 101 (Suppl 1):5228-5235.
[7] 孙茂松: 基于互联网自然标注资源的自然语言处理[J]. 中文信息学报, 2011, 25(6):26-32.
[8] 饶高琦, 修驰, 荀恩东. 语料库自然标注信息与中文分词应用研究[J]. 北京大学学报(自然科学版), 2013, 49(1):140-146
[9] Huang Z E, Xun E D, Rao G Q, et al. Chinese Natural Chunk Research Based on Natural Annotations in Massive Scale Corpora [C]//Chinese Computational Linguistics and Natural Language Processing Based on Naturally Annotated Big Data. Springer Berlin Heidelberg, 2013:13-24.
[10] Zhongguo Li, Maosong Sun. Punctuation as Implicit Annotations for Chinese Word Segmentation [J]. Computational Linguistics, 2009, 35(4):505-512.
[11] Si X, Liu Z, Sun M. Modeling Social Annotations via Latent Reason Identification [J]. Intelligent Systems IEEE, 2010, 25(6):42-49.
[12] 刘知远, 司宪策, 郑亚斌,等. 中文博客标签的若干统计性质[C]//中国计算技术与语言问题研究——第七届中文信息处理国际会议论文集. 2007.
[13] Jeremy, Ginsberg, Matthew H, Mohebbi, Rajan S, Patel, et al. Detecting Influenza Epidemics Using Search Engine Query Data [J]. Nature, 2008, 457(7232):1012-1014.
[14] Sepandar D. Kamvar and Jonathan Harris. We Feel Fine and Searching the Emotional Web [C]//Proceeding s of the Fourth ACM International Conference on Web Search and Data Mining (WSDM 2011). HongKong, China, 2011:117-126.
[15] Qu and Liu. Interactive Group Suggesting for Twitter [C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics (ACL 2011), Portland, USA, 2011:519-523.
[16] Wu and Weld. Open Information Extraction using Wikipedia [C]//Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics (ACL 2010). Uppsala, Sweden, 2010:118-127.
[17] McCallum, Andrew Kachites. MALLET: A Machine Learning for Language Toolkit [OL], http://mallet.cs.umass.edu. 2002.
Unsupervised Text Feature Extraction Based on Natural Annotation and Latent Topic Model
RAO Gaoqi1, 2, YU Dong1, XUN Endong1
(1. Beijing Language and Culture University, Institute of BigData and Language Education, Beijing 100083, China;2.Institute for Chinese Language Policies and Standards,Beijing 100083, China)
Text features are often shown by its terms and phrases. Their unsupervised extraction can support various natural language processing. We propose a “Cluster-Verification” method to gain the lexicon from raw corpus, by combining latent topic model and natural annotation. Topic modeling is used to cluster strings, while we filter and optimize its result by natural annotations in raw corpus. High accuracy is found in the lexicon we gained, as well as good performance on describing domains and writing styles of the texts. Experiments on 6 kinds of domain corpora showed its promising effect on classifying their domains or writing styles.
natural annotation; natural chunk; latent topic model; domain feature; stylistic features

饶高琦(1987—),博士研究生,主要研究领域为计算语言学、语言政策与语言规划。E-mail:raogaoqi-fj@163.com于东(1982—),通信作者,讲师,主要研究领域为计算语言学。E-mail:yudong@blcu.edu.cn荀恩东(1967—),教授,主要研究领域为自然语言处理、计算机教育技术。E-mail:edxun@126.com
1003-0077(2015)06-0141-09
2015-07-10 定稿日期: 2015-09-03
国家自然科学基金(61300081,61170162);国家社科重大基金(12&ZD173);国家语委科研基金(YB125-42);北京语言大学研究生创新基金(14YCX074)
TP391
A
猜你喜欢
计算机与现代化(2022年5期)2022-06-06
通信技术(2021年12期)2022-01-25
广东教育·综合(2021年11期)2021-12-02
牡丹江教育学院学报(2021年1期)2021-03-23
英语世界(2021年13期)2021-01-12
师道·教研(2020年3期)2020-04-02
中学生英语·教师版(2019年6期)2019-08-01
山西青年(2019年14期)2019-01-15
——以“把”字句的句法语义标注及应用研究为例
中文信息学报(2017年6期)2017-03-12
外语教学理论与实践(2014年2期)2014-06-21
