
基于VOLT的藏汉双向机器翻译
2022-06-06 01:16孙义栋
计算机与现代化 2022年5期
孙义栋,拥 措,杨 丹
(1.西藏大学信息科学技术学院,西藏 拉萨 850000; 2.西藏自治区藏文信息技术人工智能重点实验室,西藏 拉萨 850000;3.藏文信息技术教育部工程研究中心,西藏 拉萨 850000)
0 引 言
机器翻译又被称为自动翻译,是利用计算机将一种自然语言转换为另一种具有相同含义的自然语言的过程,属于计算机语言学的分支之一,具有重要的科学研究价值[1]。机器翻译的发展经历了萌芽期、受挫期、快速成长期和爆发期4个阶段,其方法已从基于规则的机器翻译、基于实例的机器翻译[2]、基于统计的机器翻译[3-5]发展为基于神经网络的机器翻译[6-9]。随着大数据时代的到来,低成本获取数据让神经机器翻译系统更快得以实现。因此最近神经机器翻译凭借其高质量的译文,受到越来越多研究者和开发者的青睐[10]。在机器翻译中,首先要构建词表,即统计文本中的词汇,然后设定一个阈值,将出现次数大于这个阈值的词汇放入词汇表中。但是如果不加以限制,机器翻译面对的词表就会很大,而且会出现OOV(Out of Vocabulary)问题。一种解决开放词表翻译问题的方法是改造输出层结构[11-12],但是这种方法仍然无法解决OOV问题,因此并不常用。
目前,字节对编码(Byte Pair Encoding, BPE)[13]是一种常用的子词词表构建方法。BPE方法最早用于数据压缩[14],机器翻译通过学习这种思想[15]来对源语言和目标语言进行子词切分,并且取得了很好的效果[16]。与BPE算法不同,基于Word Piece[17]和1-gram Language Model(ULM)的方法是利用语言模型进行子词词表的构造[18]。但是在这些方法中,词表的大小并没有得到充分重视。而有些工作表明词表大小也会影响下游任务的表现,尤其是在低资源任务上。近几年,有研究人员提出融合EMD(Earth Mover’s Distance)最小化双语词典的汉-越无监督神经机器翻译方法,首先分别训练单语词嵌入,再通过最小化它们的EMD训练得到双语词表[19]。2021年,Xu等人[20]提出了VOLT(Vocabulary Learning Approach via Optimal Transport)技术通过同时考虑信息熵和词汇表大小来探索自动词汇化,并引入经济学中信息边际效用(MUV)来衡量信息熵和词汇表规模的博弈收益,提出最佳运输理论来最大化MUV(MUV最大化时等同于找到最佳词汇表)。VOLT的好处在于可以极大缩小词表规模、不用人工定义BPE训练时的词表规模以及能够大幅度提高词表训练速度。
但在藏汉双向机器翻译领域,由于藏语和汉语的基本组成字符不同,二者词表需要分开构建。而藏文是拼音文字,音节之间的分隔符存在省略现象,有格助词、助动词等汉语文法不具有的语法单元,这种语言特点导致藏语中存在紧缩词和黏着词、虚词和实词的界限难以区分、词与词之间没有明显的间隔标记等[21],给藏语词表的构建带来了挑战。而且无论是传统的分词后统计词频来构建词表,还是分词后采用BPE以及直接使用BPE等方式相对于其他大语种翻译上的提升都略显不足。因此,本文旨在通过构建合适的藏汉词表来提升藏汉双向翻译性能。
1 基于词表拼接的词典改进方法
字节对编码主要思想是将数据中常见的连续字符串替换为一个不存在的字符,之后通过构建一个替换关系的对应表,最后再对压缩后的数据进行还原。BPE可以有效解决OOV问题,缩小词表规模,对低频词有很好的健壮性。而对于高频词来说,因为其本身在句子中出现频率较高,应该将其作为一个整体去看待,不适合分割成字符级。因此本文采用高频词使用直接构建词表,低频词使用字节对编码词表的思想,并通过迭代训练找到最佳词频阈值进行词表拼接。其中直接构建词表是指对分词后的语料进行词频统计,按照单词在语料中出现的频率由高到低的顺序来构建词表。
本文对2种方法的子词切分结果进行了差异分析和数据统计,结果如表1所示。

表1 2种方法子词差异分析和数据统计
本文词表拼接方法的主要思想如图1所示。

图1 词表拼接算法流程图
在百位词频阈值都被取完之后程序终止,记录最大保留分数以及采用的最佳百位词频阈值。
2 基于VOLT的词典改进方法
VOLT的核心思想是通过同时考虑语料库熵和词汇量大小在多项式时间内探索自动词汇化。主要过程可分为3步:1)引入经济学中信息边际效用(MUV)作为评估方法;2)通过将离散优化目标重新表述为最优转移问题,从而在可处理的时间复杂度中最大化MUV;3)则是从最佳转移矩阵中生成词表。
在第一步中,MUV在形式上被定义为熵对词汇量大小的负导数,MUV的计算过程如公式(1)所示。
(1)
其中,v(k+m)和v(k)分别表示包含k+m和k个tokens的词表,Hv表示的是语料库的熵,具体定义为:
(2)
公式(2)中lv表示词表v中的tokens的平均长度,P(i)则代表tokeni在训练语料库中的“相对频次”,计算公式为:
(3)
公式(3)中分子部分c(i)表示tokeni在训练语料库中出现的次数,分母部分为训练语料库中单词总数。
在第二步中,由于词表是离散的,搜索空间太大,因此通过从固定大小的词表中搜索最佳词表来简化原始的离散优化问题。给定变量S,每个时间步t表示一组数量为S[t]的词,对于任意一个词表,其MUV分数可以基于前一步的时间戳t-1上的词表递进计算得到。通过这种方式可以正式定义寻找最优词表v(t)的函数为:
(4)
公式(4)由于是指数搜索空间,因此需要优化上界:
(5)
其中,i是t-1词表和t词表size的差值,所以最终最大化MUV分数可以表达为最大化公式(5)。
具体实现过程总共可分为5步:1)对所有token按频率从大到小排序,采用BPE生成的token作为候选token;2)使用所有的token候选以及各自概率初始化算法;3)设置超参数S的大小,对于双语翻译设置为(1000,…,10000),多语翻译设置为(40000,…,160000);4)对于每一个时间步t,基于转移矩阵使用最大熵得到词表,同时删除频率低于0.001的token;5)枚举出所有时间步,选择出满足公式(5)的词表作为最终词表。生成词表后,与BPE类似,VOLT也使用贪婪策略对文本进行编码,即首先将句子切分成字符级,然后合并连续的2个token,直到没有token可以被合并为止。
通过上述方法,VOLT可以找到具有更高BLEU值和更小规模的词汇表,避免了人工定义词表规模所带来的缺陷,而且相比传统词表训练方法,能够大幅度减少词表训练时间。
对于VOLT的正常应用方式是在对语料使用分词和BPE后再使用VOLT。但是对于藏语来说,由于藏文本身存在紧缩词和黏着词等特点,现有的藏文分词系统不能达到很好的分词效果。其次,VOLT本身是根据句子信息熵生成词表(式(2)、式(5)),藏文进行分词后会导致句子信息熵发生改变。
因此,本文对藏文采用直接BPE方式加VOLT技术生成词表,中文仍使用分词加BPE再加VOLT技术生成词表。最后通过实验对比所提方法是否有效。
3 实验设计
3.1 语料库的来源
本文所使用的实验数据大部分来源于第十七届全国机器翻译大会(CCMT 2021)所提供的15万句左右藏汉平行语句,还有一部分来源于实验室收集到的3万条语句,共18万条平行语句。
3.2 数据预处理
首先利用规则的方法进行数据过滤,具体内容包括长度过滤、长度比限制、语种识别、去重。其次进行符号标准化,对数据中的字符表示或者大小写等进行统一,具体包括全角转半角、大小写转换和中文的简繁体转化等。最终得到清洗后的约17万条语句的数据集,再采用随机抽样方法从中随机选取1万条语句的数据集划分为验证集和测试集(各5千条左右)。这样做的目的是保证验证集和测试集的随机性以及防止数据泄露。之后对剩余16万条语句的数据集通过同义词替换[22]的方式进行数据增强,得到约50万条藏汉平行语句。其中基于同义词替换的数据增强方式经过实验证明对藏汉/汉藏翻译效果都有所提升,因此本文中也采用该方法扩充语料。最后进行分词,在本文中,汉文直接构建词表或使用北大pkuseg[23]分词,并在此基础上使用BPE。藏文按照实验需要,分别采用了TIP-LAS分词[24]以及在TIP-LAS基础上使用BPE,其中TIP-LAS是李亚超等人[24]提出的基于条件随机场模型的藏文分词系统,该系统首先需要训练一个分词模型,再对需要分词的藏文语料应用分词模型进行切分,词与词之间以空格作为分隔符。其中,藏文分词后使用BPE方式与汉文相同,都是通过先学习词表再对语料进行应用的方式进行,本文所使用的BPE开源地址为https://github.com/rsennrich/subword-nmt。
3.3 模型架构与参数设置
本文使用近年来神经机器翻译方法中主流的编码器-解码器(Encoder-Decoder)框架,统一采用百度飞浆开源的PaddleNLP中完全基于自注意力机制的Transformer-big模型训练。模型有16层编码器和解码器,每个输出大小为1024个隐藏单元,使用16个注意头和正弦位置嵌入,最后前馈网络中隐藏层大小为4096。其中Transformer-big的网络参数与文献[25]中的参数设置保持一致,解码时使用束搜索算法[26]来生成翻译的目标语句,beamsize设置为5。优化策略使用Adam优化器[27]。Dropout参数值设置为0.1,以防止过拟合。所有实验均在Ubuntu操作系统下使用RTX 2080Ti显卡完成。
本文使用BLEU-4[28]值作为评测指标,其采用n-gram匹配的方式来评定翻译结果与参考译文之间的相似度,即机器翻译的结果越接近人工参考译文就认定它的质量越高。n-gram是指n个连续单词组成的单元,n越大表示评价时考虑的匹配片段越大,比如本文所使用的BLEU-4值就代表4-gram。BLEU值计算公式为:
(6)
公式(6)中BP代表长度惩罚因子,避免短句子得到更高的值。Pn表示修正后的n-gram精度得分,Wn表示权重值。
3.4 总体框架介绍
本文主要研究2种藏汉词表改进方法在藏汉双向翻译上的改进效果,本文方法的总体框架如图2所示。其中词表拼接和VOLT部分是本文重点,将在第四章词表改进实验结果与分析中详细展开说明。

图2 总体框架流程图
3.5 基线实验的选择
为了方便后续实验对比,分别对分词后直接构建词表、分词后采用BPE以及直接使用BPE这3种传统藏文词表构建方法在藏汉和汉藏上进行实验对比,BPE参数统一设置为32 k,从中选择最优作为基线实验,实验结果和词表大小分别如表2和表3所示。
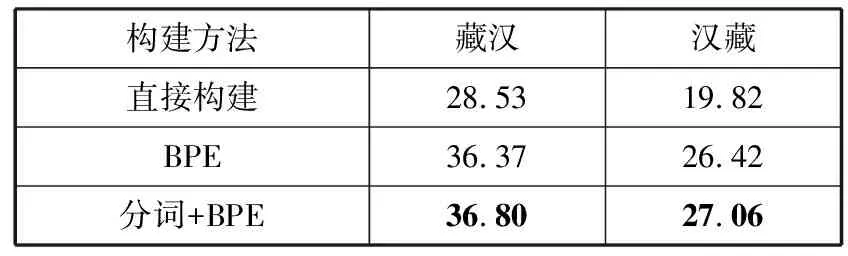
表2 传统藏文词表构建方法实验效果BLEU值对比

表3 传统藏文词表构建方法词表大小对比 单位:个
由表2可知直接构建方法效果最差,并且词表规模也过于庞大,不利于训练。分词后采用BPE效果最佳。表3表明直接使用BPE可以在一定程度上缩小藏文词表规模。词表规模越小,词表中每个单词所代表的语义更少且易于区分,出现稀有token的概率也会更低。同时训练和预测时间也会减少,有利于训练。这是由于藏文本身语言特点所决定的,但是本文既希望达到最佳实验效果,又希望能减小词表大小,从而有利于训练。因此本文以分词后采用BPE作为基线实验,分别从词表拼接和VOLT这2个方面进行实验对比,研究最佳词汇表的生成。
4 词表改进实验结果与分析
4.1 词表拼接
对于词表拼接,词频阈值每次迭代大小设置为100。实验表明,当词频阈值为4300时,效果提升最明显。表4展示了当词频阈值为100、1000、5000、4300(最佳)时的实验效果,对应的词表大小如表5所示。
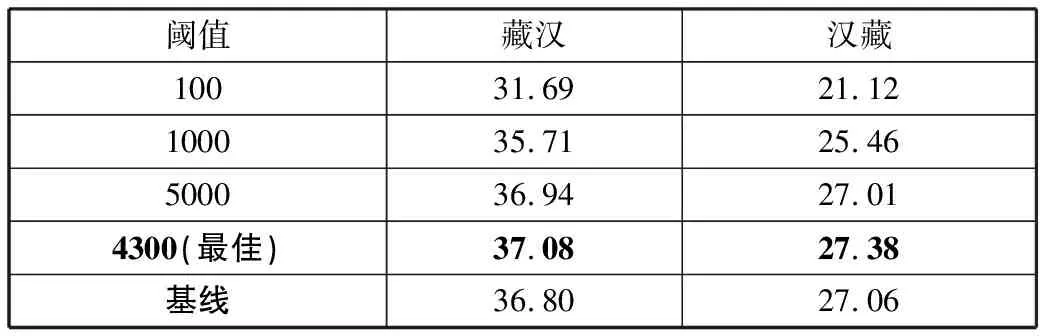
表4 不同阈值大小的实验效果BLEU值对比

表5 不同阈值大小的词表规模对比 单位:个
通过表4可以看出,采用高频正常、低频BPE拼接词表的思想是有效果的,采用最佳词频阈值相比基线实验分别在藏汉/汉藏上提升了0.28/0.32个BLEU值。同时表5中对应的词表规模也小于基线实验,与表3中藏文只使用BPE方式生成的词表规模相近,不仅缩小了藏汉词表规模而且提升了藏汉双向翻译性能。由于模型训练所产生的开销较大,无法将迭代阈值位数继续缩小,因此很难找到个、十位数的最佳阈值。
4.2 VOLT
对于VOLT,实验参数与论文中保持一致。本节分别对藏文传统分词策略(分词+BPE)以及本文专门针对藏文使用VOLT所提的方法(直接BPE)在应用VOLT前后进行实验对比。实验结果如表6所示,2种方法生成词表规模如表7所示。
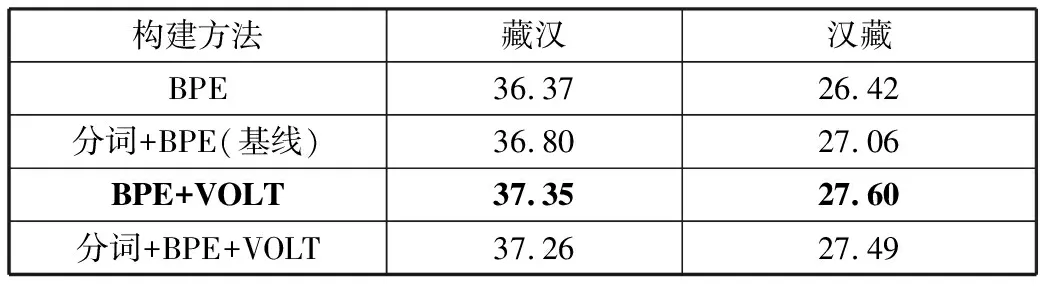
表6 2种方法使用VOLT前后效果BLEU值对比

表7 2种方法使用VOLT前后生成词表规模对比 单位:个
表6和表7的实验效果验证了本文方法的有效性。观察表6最后2行,藏文直接BPE方式相比于分词加BPE,在藏汉和汉藏上分别提升了0.09/0.11个BLEU值。观察2种方法在使用VOLT前后效果提升程度,分词加BPE方式在使用VOLT后在藏汉上提升了0.46个BLEU值,在汉藏上提升了0.43个BLEU值。直接BPE方式在使用VOLT后在藏汉上提升了0.98个BLEU值,在汉藏上提升了1.18个BLEU值。前者提升效果只有后者一半。观察2种方法在使用VOLT前后词表大小,因为汉文生成词表方式未变,所以二者汉文词表规模相同,并且相比基线词表规模降低了45.8%。而在藏文词表规模上,相比使用VOLT前,直接BPE词表规模降低了73.3%,分词加BPE词表规模降低了70.2%。
实验结果表明,使用VOLT可以在极大缩小词表规模的同时提升翻译效果。虽然直接BPE相比分词加BPE方式提升幅度较小,平均只有0.1个BLEU值,但直接BPE在使用VOLT后提升幅度是分词加BPE的一倍多。这主要是由于藏文句子信息熵改变导致的,对于分词后使用BPE,句子本身经过分词后,信息熵就已经发生了变化,而使用VOLT生成词表主要依据之一就是信息熵,因此导致直接BPE方式提升幅度较大。其次是由于目前藏文的分词系统并不如汉文的分词系统完善,对藏文虚词和实词的划分并没有达到较高的精确度,导致去掉分词步骤后,经过VOLT生成的词表反而效果更好。对于词表规模,表3和表7表明藏文语言特点决定了直接使用BPE方式生成的子词粒度更小,从而导致词表规模更小,而在使用VOLT后将这一差距进一步扩大。
5 结束语
本文选取在神经机器翻译中经典的Transformer-big模型,通过改进字节对编码和VOLT的方式探索藏文最佳词汇表,最终分别通过拼接词表和根据藏文自身语言特点合理运用VOLT提升了藏汉双向翻译性能。笔者希望本文能对其他低资源语种翻译有所启发。下一步笔者将计划构建相对应的藏汉人名、地名词表,以此提高藏汉翻译中对专有名词的识别率。
猜你喜欢
辞书研究(2022年4期)2022-07-20
内江科技(2021年8期)2021-09-13
西藏研究(2021年1期)2021-06-09
英语世界(2021年13期)2021-01-12
布达拉(2020年3期)2020-04-13
西夏学(2019年1期)2019-02-10
亚太教育(2018年5期)2018-12-01
中央民族大学学报(自然科学版)(2018年1期)2018-06-27
读者·校园版(2015年7期)2015-05-14
心理学报(2014年4期)2014-02-02
