
基于WordNet的概念格间语义相似度计算方法
2015-11-01 09:18伍振兴
中国科技信息 2015年9期
伍振兴
基于WordNet的概念格间语义相似度计算方法
伍振兴
本文提出了一种基于WordNet的概念格间语义相似度计算方法,该方法利用WordNet中各词汇之间的结构关系,参考其各词汇间的距离、密度、深度来计算各概念间的语义相似度来反映概念间的语义关系,然后根据概念与其他的概念格中的语义相似度来计算两个概念格间的语义相似度,为以后的研究做准备。但是这种方法尚不完善,需进一步进行扩展与改进。
概念格具有良好的概念与概念之间的层次结构,已经被广泛应用于软件工程、信息检索、数据挖掘等领域。但现如今对于各概念格之间的相似度计算和匹配的研究则相对较少。本文提出了一种基于WordNet的概念格间语义相似度计算方法,该方法利用WordNet中各词汇之间的结构关系,研究两个概念格之间的语义相似度计算,为以后概念格间的语义匹配做准备。
概念格
概念格,又称为Galois格,是德国数学家Wille R.于1982年首次提的。概念格是根据数据集中对象与属性之间的二元关系建立的一种概念层次结构,体现了概念之间的泛化和特化关系。
定义 称(U,A,I)为一个形式背景,其中U={x1,x2,…,xn}为对象集,每个xi(i≤n)称为一个对象;A={a1,a2,…,am}为属性集,每个ai(i≤m)称为一个属性;I 为U 和A之间的二元关系,I⊆U ×A .若(x,a) ∈I ,则说x 具有属性a ,记为xIa 。
若用1表示(x,a )∈I ,用0表示(x,a)∉I ,这样的形式背景就可以表示为只有0和1的表格。
对于形式背景(U,A,I),在对象集X⊆U 和属性集B⊆A上 分别定义运算:

∀x∈U ,记{x}*为x*;∀a∈A, 记{a}*为a*.若∀x∈U ,x*≠∅,x*≠A, 且∀a∈A, a*≠∅,a*≠U则称该形式背景(U,A,I)是正则的。
定义 2 设(U,A,I)为形式背景。如果一个二元组(X,B)满足X∗=B ,且B∗=X ,则称(X,B)是一个形式概念,简称概念。其中X 称为概念的外延,B称为概念的内涵。
概念格的每个节点是一个形式概念,由两部分组成:外延,即概念所覆盖的实例;内涵,即该概念所覆盖实例的共同特征。概念格可以图形化形式表示为有标号的线图,图中的节点表示一个概念,节点间的连线表示节点间存在泛化与特化关系,这种线图也称为Hasse图。它是概念格的可视化表示。
WordNet简介
WordNet是一个大型的英语词汇数据库,它来源于美国Princeton大学GeorgeA.Miller教授所主持的一项知识工程的项目。WordNet是按照词汇的语义关系来组织词汇,它使用同义词集合来表示概念,而这些概念集合则通过其中的某一特定的关系或者结构来相互连接,形成一个大型的树形结构。目前WordNet中的词汇数量已经近20万条,并且每月超千条的速度不断的增长。
WordNet之间存在着两种关系:语义关系和词汇关系。其中词汇关系指词形之间所存在的关系,语义关系指词义之间存在的关系。这些关系中比较重要的是同义关系、近似关系、反义关系、上下位关系和部分整体关系。
(1)同义关系是WordNet中最基本的关系,它属于词汇关系,是形成同义词集的基础。在WordNet中,同义关系并不是说两个词汇在任何语境下都可以相互交换的,而是指在某一特定的语境下,这两个词可以交换。
(2)反义关系和近似关系是指形容词集之间的关系,它是语义关系。在WordNet中形容词集的组织结构主要依靠反义关系和近似关系。形容词集是按簇(Cluster)组织的,每个簇都包含一个主节点(Head Synset),大多数的主节点都有一个或多个附属节点(Satellite Synset),主节点和附属节点间通过近似关系连接。其中每个主节点中至少存在一个词和另外一个簇中的主节点所包含的词间存在反义关系。
(3)上下位关系是WordNet中最重要的关系之一,是属于语义关系,指在动词集和名词集上的关系,基于这种关系形成了动词集和名词集上的层次结构。相对于下位词,上位词是一个通用术语,它表示由所有实例构成的一个类的整体;相对于上位词,下位词是一个具体术语,它表示类中的一个实例。
(4)部分整体关系是WordNet中另外一种重要的关系,和上下位关系一样同属语义关系,是指在名词集上的关系。在WordNet中,部分整体关系通常被分成三类:即对于任意给定的两个名词集S1和S2,若S1是整体,S2是部分,则S2或者是S1的成员,或者是构成S1的材料,或者是S1的组成部分。
一种基于WordNet的概念格间语义相似度计算方法
概念间的语义相似度计算
从语义上讲,概念格中的概念关系主要有分为以下四种:(1)part-of关系,概念间整体与部分的关系;(2)kind-of关系,概念间的超概念和子概念的关系,(3)instance-of关系,概念中的具体和抽象的关系,(4)attribute-of关系;概念与属性的关系。但是也有些学者将概念间的语义关系拓展到概念间的行为关系和因果关系等。
依据参照WordNet本体来判断概念之间的语义和结构关系,利用概念间的关系组成的图形结构,参考概念间的距离、密度、深度来计算各概念间的语义相似度来反映概念间的语义关系为后期的工作做准备。概念间的距离越近、深度越深,密度越大,那么相似度越大。同等情况之下,离根远的概念间的语义相似度和结构肯定要比离根近的概念要大而且结构越相似。因此本文相似度的计算将深度、密度和距离作为参考因素之一。
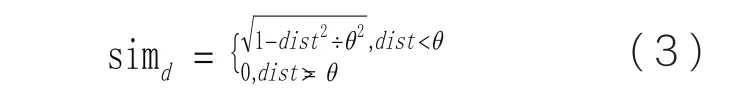
其中simd表示概念间距离的相似度计算,参数dist表示两个概念在WordNet中的距离,θ是一个阈值参数。距离越大,simd的值就越小,当两个概念间的距离超过θ时,那么就认为相似度为0。
其中simm表示概念间密度的相似度,NUM表示从当前两个概念往上找到最近的超概念,然后统计从超概念到当前两个概念间的所有概念的个数(含当前两个概念和超概念)。若当前两个概念与超概念间没有其他概念,则simm为1。

其中sims表示概念间深度的相似度计算,参数DeepTotal表示在WordNet整棵语义树中深度,参数deepth是两个概念的深度最深的那个值。深度越大,sims的值就越大。

综合考虑概念间的密度,深度和距离三个因素,根据(3)(4)(5)三个计算方式,基于WordNet中的两个概念的语义相似度为:

其中α+β+µ=1,α、β、µ分别为距离、密度和深度的权重。
概念与另外概念格语义相似度的计算
根据上述公式(3)(4)(5)(6)来计算两个概念格中的概念基于WordNet的语义相似度计算方法,本文可以计算得出概念格L1中的概念Ci到另外一个概念格L2中所有概念的相似度,找出相似度最大的语义相似度的候选概念结点,根据概念格的特性,可以找出与其最近的候选概念的子结点,层层迭代,可以得出概念Ci到概念格L2关系最紧密的一条路径Ri,那么该概念结点Ci到概念格L2的相似度计算如下:
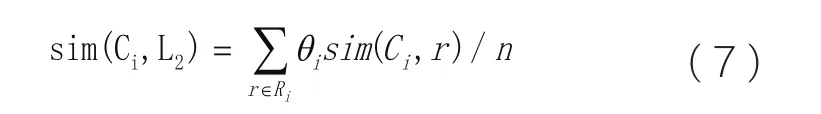
其中n为路径Ri上各概念结点的个数,θi为路径Ri上各概念结点的权重。越是概念相似度越高的概念,两结点之间的语义关系或词汇关系越近,θi的值越大,其中
概念格间的语义相似度计算
本文可以根据公式(7)得出的概念Ci到另外一个概念格L2中的相似度计算度,而后将此计算方法扩展到概念格L1中的所有概念结点,然后选取所有相似度的平均值作为概念格L1和L2的相似度。

其中n为概念格L1上概念结点的个数。
结束语
本文提出了一种基于WordNet的概念格间语义相似度计算方法,该方法利用WordNet中各词汇之间的结构关系,参考其各词汇间的距离、密度、深度来计算各概念间的语义相似度来反映概念间的语义关系,然后根据概念与其他的概念格中的语义相似度来计算两个概念格间的语义相似度,为以后的研究做准备。但是这种方法尚不完善,需进一步进行扩展与改进。
10.3969/j.issn.1001-8972.2015.09.011
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
中学生数理化·八年级物理人教版(2022年5期)2022-06-05
电子制作(2022年1期)2022-01-28
客联(2021年5期)2021-09-10
电子制作(2021年14期)2021-08-21
开放教育研究(2020年2期)2020-03-31
中国修辞(2017年0期)2017-01-31
长江学术(2016年4期)2016-03-11
中国医学影像学杂志(2015年9期)2015-12-15
导航定位与授时(2014年2期)2014-04-27
