
一种结合NoSQL与RDBMS的存储模型研究
2016-01-18 11:49李欣
电脑知识与技术 2015年33期
关键词:大数据
李欣
摘要:大数据的出现,使数据的存储需求有所改变,仅使用传统的关系型数据库已经不能满足大数据的需求,因此NoSQL应运而生,然而NoSQL放弃对关系操作的支持,使得系统的移植变得困难。该文提出的存储方案,不仅可以满足大数据的需求,而且能支持大多数关系操作。
关键词:大数据;RDBMS;NoSQL
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2015)33-0006-02
随着云计算和Web2.0技术的兴起,大数据成为了并行计算、分布式计算领域的热点问题。传统的数据库管理系统利用分布式的事物和锁机制实现数据处理的一致性和容错性,但是这样使得数据库管理系统不能获得良好的可扩展性和可用性。为了应对处理大数据的挑战,非关系数据库通过对关系数据库中一致性、事物、关联、索引等功能进行弱化或去除的手段达到了更好的水平可扩展性,但它无法对数据进行复杂处理,不支持SQL查询。因此NoSQL并不能完全取代关系数据库,而是作为解决大数据问题的一种方案,与关系数据库相辅相成。
1 RDBMS与NoSQL的简介
1.1 RDBMS
关系数据库是一门成熟的、同时仍在不断演进的主流数据管理和分析技术。其主要采用shard-nothing 结构,将关系表在节点间横向划分,并且利用优化器来对执行过程进行调度和管理[1]。并行数据库的最大优势在于性能,但是,并行数据管理技术在大数据时代丧失了互联网搜索这个机会,其主要压力表现在:扩展性差、对多类型数据管理以及对若模式数据管理的能力、设计理念的冲突[2]等几个方面。
1.2 NoSQL
NoSQL是Not SQL的简称,是不严格遵循二维表范式模型的数据库管理系统。NoSQL数据库采用灵活的、分布式的、对扩展开放的数据存储方式管理数据,一般不支持SQL语言接口,也不支持ACID的事物原则[3]。但是NoSQL采用的是基于扫描的处理模式并且对中间结果步步物化,从而导致较高的I/O代价。在NoSQL中,每个查询都是直接从文件系统中读入原始数据文件,而非传统的重数据库中读入经过处理过的文件,因此其元组解析代价远高于关系数据库[4]。
2 NoSQL与RDBMS的结合
2.1 非结构化数据结构化
非结构化信息管理系统体系结构[5]是一种采用面向对象的方式对非结构化数据进行类型定义,本文参考这种方式和面向对象的思维模式,同时引入继承的概念,对原始的非结构化元数据进行抽象。类似类的继承,一个类可以改变部分父类的特性而其他特性保持不变。通过继承树这样的结构来组织类型相似的非结构化数据,通过三维模型来表示数据与数据间的关系。数据与数据、数据与属性间的关系通过E-R模型在水平方向上描述;同类数据间的层级关系通过继承树在垂直平面描述。
通过DBMS可以自动管理垂直平面的扩展与映射,通过使用简单统一数据接口完成对整个垂直平面的遍历;同时,根据实际数据类型,DBMS可以自动选择对应的处理流程来处理数据,因此同一垂直平面内不同的数据类型可以屏蔽其具体差异,使用完全的不同的操作流程来处理,可以实现数据类型的变化对上层应用的透明性。
2.2 非结构化数据存储方案设计
2.2.1 数据的存储方案
非结构化数据有两个特性:原子性和大小不确定性。在关系数据库存储中有多种存储此类数据的方法,本文是使用数据库系统提供的大数据类型来存储,因为在多态机制下,原始数据本身也可以作为元数据的一种,参与数据管理过程。这种方式不会有安全性问题和数据一致性问题,但是它增加了数据库查询过程中的IO工作,因而查询效率较低。
2.2.2 继承与多态的实现方案
本文中使用不仅包含原有E-R模型的关联关系,还有使用继承树表示继承关系。继承树实际是实体关系模型的一种特例,但是与传统E-R模型的区别是,该模型对父类的所有操作都要映射到子类中,在继承树中,存在一个中间件来表示继承树的继承关系,该中间件存在于数据存储之上,因此具有继承关系的两个实体间不存在任何关系。
2.2.3 海量数据的存储
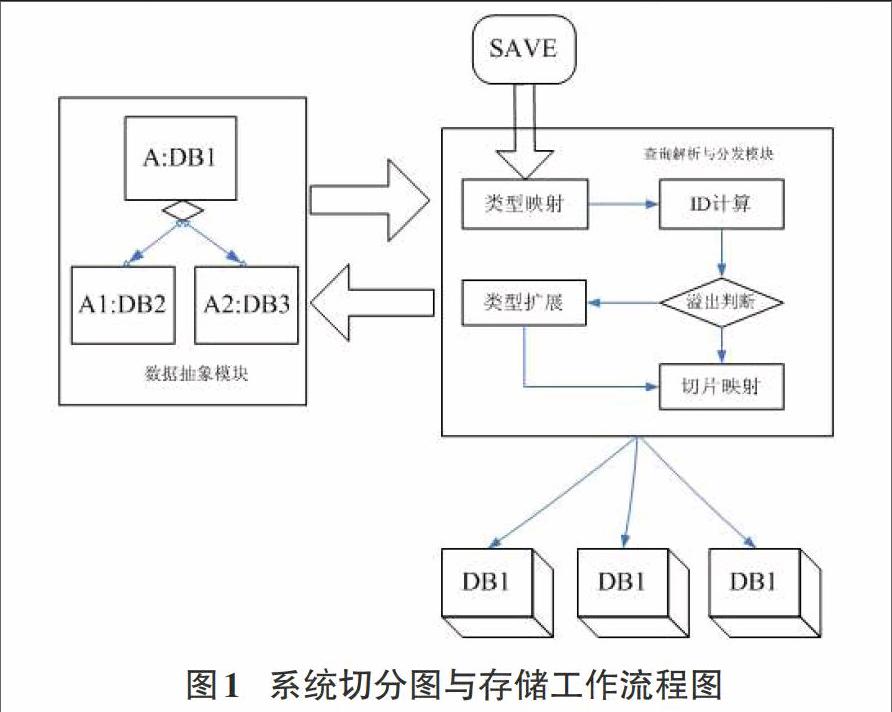
关系数据库通常通过数据复制和数据切分来扩展集群的计算能力。本系统采用继承树,各个类在数据存储层面不需要定义关系,因此可以分开来存储,因此采用按照列表进行划分切片,这种方式需要切分健是枚举类型,根据切分健的枚举值进行划分。但是关系数据库中,不同实体间可能存在关联关系,整个数据库的不同数据表之间也可能存在关联关系,为了解决上述问题,我们在类的基础上再划分,当某个类的大小超过一定值时,系统会自动扩展出一个新类,扩展的类在物理存储中按照一个普通子类来处理。类的扩展可以使用户控制的,因此用户可以根据数据本身的特点获得最佳的性能。
下图为对海量数据实现数据切分和存储的方案示意图:
2.3 并行处理
并行计算的实现实际就是查询的分发过程与结果的汇总。本文对并行处理的过程分为以下几个步骤:
首先,系统将用户对数据的每次操作都精确到每个子类,系统可以得到该子类对应的物理数据库,对该子类的所有操作都会是直接操作该数据库。
其次,数据抽象模块会收集所有数据格式,包括子类间的关系,因此当用户对两个类进行连接查询时,系统会细化到最小的子类来完成。
最后,引入MapReduce[6]技术实现查询结果的汇总。通过使用Map函数将大量数据划分为多个组,然后通过在不同主机上并行处理这些组,通过Reduce函数将不同主机的结果进行汇总,形成统一结果。
3 总结
本论文通过对大数据的基本特征的分析,指明关系数据库难以实现大数据的存储和使用NoSQL处理大数据的技术难点后,提出一种支持继承关系的关系树模型,该模型可以提高关系模型的扩展性,并引入多态机制,满足非结构化数据的存储要求。
参考文献:
[1] 王珊,王会举,覃雄派,等.架构大数据:挑战、现状与展望[J].计算机学报,2011,34(10):1741-1752.
[2] 孟小峰,慈祥.大数据管理:概念、技术与挑战[J].计算机研究与发展,2013,50(1):146-169
[3] 姚林,张永库.NoSQL的分布式存储与扩展解决方法[J].计算机工程,2012,38(6):40-42.
[4] 李冯筱,罗高松. NoSQL 理论体系及应用[J].电信科学,2013,28(12):23-30.
[5] 李艳,季新生,项君.基于UIMA 的知识发现框架研究及实现[J].计算机工程,2010,36(21):277-279.
[6] Afrati F N, Ullman J D. Optimizing joins in a map-reduce environment[C]. Proc. Thirteenth Intl. Conf. on Extending Database Technology,2010.
猜你喜欢
中国市场(2016年36期)2016-10-19
中国市场(2016年36期)2016-10-19
中国市场(2016年35期)2016-10-19
商(2016年27期)2016-10-17
今传媒(2016年9期)2016-10-15
今传媒(2016年9期)2016-10-15
新闻世界(2016年10期)2016-10-11
科技视界(2016年20期)2016-09-29
中国记者(2016年6期)2016-08-26
