
一种基于ECVM的Tri-training半监督垃圾邮件检测算法
2016-02-23 05:51卜华龙郑尚志
宿州学院学报 2016年8期
卜华龙,夏 静,郑尚志
巢湖学院信息工程学院,安徽巢湖,238000
一种基于ECVM的Tri-training半监督垃圾邮件检测算法
卜华龙,夏 静,郑尚志
巢湖学院信息工程学院,安徽巢湖,238000
为提高垃圾邮件检测精度,提出一种基于ECVM的Tri-training半监督垃圾邮件检测算法,兼顾了Tri-training算法的准确性和ECVM算法处理大规模数据的高效性特点,可以降低算法的时间和空间复杂度,提高未标记数据的利用率,适应垃圾邮件数据的规模大、标记数据少、稀疏性强等特点。Matlab实验表明Tri-training+ECVM比传统的Tri-training+SVM在准确率和时间复杂度指标上都有大幅度的提升。
Tri-training;ECVM;垃圾邮件检测;半监督学习
垃圾邮件检测是网络安全的典型应用之一。通常根据邮件的内容,采用相应的分类学习算法将邮件归至某类别[1]。基于内容的文本分类方法可以分成数据预处理、维数约简和分类建模三个主要步骤[2]。其数据预处理的方式是根据邮件格式,剔除无关结构信息,保留核心内容,如邮件标题、邮件发送人和正文,并将其记录成一条特征向量;维数约简用于实现压缩此特征向量维数的目的;分类建模主要实现分类器的建模过程。传统的分类学习可分成监督、无监督学习和半监督学习[3]。其中半监督学习结合了监督和无监督学习的优点,同时利用标记和无标记数据,已经成为当前数据挖掘、机器学习等领域的主要研究方向[4]。
作为文本分类等领域的主流学习算法,支持向量机(support vectors machine,SVM)具有其他多数算法不具有的检测精度,因此,被广泛改造成半监督环境下的学习算法并取得了很好的效果,在文本、生物信息挖掘等领域中得到了广泛使用[5]。
然而,在现实环境下,垃圾邮件检测数据集规模庞大、标记样本少、特征稀疏等,具体表现为数据点数量极大,样本标签大部分未标记,特征空间维度高且很多特征值为0。由于SVM算法时间复杂度为o(n3),n是训练样本个数,导致SVM处理大规模垃圾邮件检测数据集时效率不够[6],给传统SVM分类学习器带来严重挑战。
本文提出基于Tri-training和ECVM的半监督垃圾邮件检测算法,试图运用Tri-training算法解决标记样本过少问题,并运用基于广泛内核CVM算法(extensive kernel core vector machine ,ECVM)来大幅缩减数据集规模的影响,节约SVM的求解时间。在仿真实验中,安排Tri-training和Co-training、CVM和ECVM算法比较等多个方案,探讨本文算法在垃圾邮件检测中的优势。
1 算法必要性分析
1.1 Tri-training算法分析
协同训练(Co-training)算法是基于已标记训练样本有限前提下的一类半监督学习算法,它强调利用易获取的未标记样本信息提高学习精度[7]。Co-training假设数据含有两个相异充分冗余视图,且每个视图的特征集都具有训练出足够精度分类学习器[8]的能力。Co-training具有较强的模型限制,当数据不满足充分冗余视图假设时,算法存在可用性缺陷。
对此,周志华等人提出Tri-training算法。该算法不需要充分冗余视图假设,利用三个分类器进行协同训练,既保留了Co-training的协同优势又避免了验证时间长、分类算法要求苛刻等问题[9]。Tri-training算法虽然比Co-training算法多了一个分类器,但不再需要交叉验证,降低了算法的时间复杂度。另外,增加一个分类器也会提高集成效果。该算法虽然对单个分类器的精度要求不高,但算法的结构决定其对分类器的时间复杂度要求很高,如前所述,支持向量机SVM在实际处理大规模数据集时,时间复杂度和空间复杂度较高,导致分类器因支持向量多而变慢[10](传统的SVM算法时间复杂度为o(n3),n是训练样本个数),造成SVM处理大规模垃圾邮件检测数据集时效率不够,对此,本文引入ECVM,以解决高维和数据稀疏问题。
1.2 支持向量机与基于广泛内核的CVM算法分析
SVM算法核心是将训练数据表示为S={(x,y)}⊆{Rn×(-1,1)}l,并定义分类判别超平面y=sgn(
作为一种主要的SVM计算方法,基于最小闭包球的CVM算法采用近似最优解的概念来求解SVM,大幅提高了支持向量机的学习精度,然而CVM算法要求核函数满足k(x,y)=K(‖x-y‖)的各方同性假设,从而限制了可用性,且时间复杂度较高[12-13]。王奇安等人提出基于最小闭包球的改进算法ECVM。该算法同样采用求解SVM的近似最优解,且消除了同向性核方法假设,简化了新球心的计算,不再需要解决每次迭代工程中的QP问题,ECVM的时间复杂度与样本集大小n呈线性关系,空间复杂度与样本大小无关[14]。
2 基于Tri-training和ECVM的垃圾邮件检测算法
垃圾邮件检测通过分类器判断正常邮件和垃圾邮件,数据的采集、分析和处理具有以下特点和困难:
(1)规模庞大,数据集规模经常达到上万级别;
(2)标记样本少,大部分样本没有事先标记过;
(3)特征空间维度高且稀疏性强。
本文利用ECVM解决规模庞大和特征稀疏问题,提高算法效率;通过Tri-training算法解决标记样本过少问题。主要框架如图1所示。
具体工作如下:
(1)数据规范和归一化,以防止数据特征间的数量级不一。首先采用Z_Score类方法规范化(公式1)样本特征,再设计归一化函数(公式2)将各特征值归一化至[0,1]区间:
(1)
xi=(xi-xmin)/(xmax-xmin)
(2)


图1 算法框架图
(2)初始化标记数据集U和未标记数据集L,将U分成标记训练数据集SLtrain和测试集SVtrain,令SLtrain=L。
(3)协同训练,该过程主要基于Tri-training协同训练三个ECVM分类器,为体现分类器差异,这里的分类器核函数分别采用Gauss、Poly和Rbf,具体过程如下表1所示。

表1 算法步骤
(4)垃圾邮件检测,分别使用训练好的C1、C2和C3分类器对新未标记数据进行预测,采用少数服从多数的原则进行协同投票,以决定最终标签。
3 实验与分析
实验数据集采用2005-Jul,包含20308个垃圾邮件和9042个正常邮件[15]。为模拟半监督学习环境,首先合并这29400个样本,并打乱分布结构得到数据集C,再将C的1/10作为标记训练集SUtrain,剩余部分4/5作为未标记数据集SLtrain,1/5用作测试分类器的SVtrain。
检测评价准则采用最常用的召回率R和准确率P[16],垃圾邮件检测只有表2中4种结果。

表2 系统检测分类表
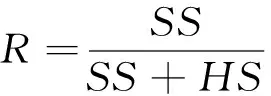
本文主要研究算法相对Co-training算法和CVM算法的效果,因此,限定参数为Matlab工具箱中的默认参数,实验环境为Matlab。Tri-training算法中的迭代次数K=10,β=5%,ECVM中参数ε值(半径选取)=10-7。
首先,对比Co-training+ECVM与Tri-training+ECVM的检测准确率,表3所示为平均值,共重复3次。从分类检测的召回率和准确率两个指标都可以看出Tri-training+ECVM能提高精度2%~3.4%。

表3 Co-training与Tri-training(召回率与准确率)
其次,对比了ECVM与CVM的检测准确率,共分成Co-training+ECVM,Co-training+CVM,Tri-training+ECVM和Tri-training+CVM四种情况,表4所示为召回率和准确率的平均结果。从分类检测的召回率和准确率两个指标反映出ECVM至少比CVM提高精度1.4%以上。

表4 CVM与ECVM对比(召回率与准确率)
最后,虽然理论研究已证明了ECVM和传统的SVM的时间效果,但此处还是统计了实验的时间复杂度(表5)。通过对比CVM和ECVM的CPU使用时间,可以明显发现ECVM比CVM消耗时间要低,考虑到ECVM的时间复杂度是样本规模的线性函数,这个现象是非常正常的。

表5 CVM与ECVM对比(CPU时间,单位s)
4 结束语
针对垃圾邮件数据集规模大、标记数据少和稀疏性强等问题,本文提出使用Tri-training算法的协同训练方法提高未标记数据的利用率,并结合ECVM算法处理大规模数据的高效性来处理半监督垃圾邮件检测问题,试图通过Tri-training算法解决标记样本过少问题,并通过基于广泛内核CVM算法以大幅缩减数据集规模的影响,节约SVM的求解时间。基于Matlab的多个实验对比说明准确率和降低时间复杂度都有所提高,验证了算法的有效性。
[1]陈凯.反垃圾邮件技术的研究与实践[D].北京:北京邮电大学软件学院,2006:2-19
[2]苏金树,张博锋,徐昕.基于机器学习的文本分类技术研究进展[J].软件学报,2006,17(9):1848-1859
[3]林冬茂.数据挖掘技术在垃圾邮件检测中的应用[J].计算机仿真,2012,29(2):120-125
[4]牛罡,罗爱宝, 商琳.半监督文本分类综述[J].计算机科学与探索,2011,5(4):313-321
[5]李红莲,王春花,袁保宗,等.针对大规模训练集的支持向量机的学习策略[J].计算机学报,2004,27(5):715-719
[6]袁鼎荣,钟宁,张师超.文本信息处理研究述评[J].计算机科学,2011,38(12):9-13
[7]周志华.机器学习及其应用[M].北京:清华大学出版社,2006:1-201
[8]邬书跃,余杰,樊晓平.基于Tri-training的入侵检测算法[J].计算机工程, 2012,38(6):158-160[9]Zhou Zhihua,Li Ming.Tri-training:Exploiting Unlabeled Data Using Three Classifiers[J].IEEE Transactions on Knowledge and Data Engineering,2005,17(11):1529-1541
[10]李昆仑,张伟,代运娜.基于Tri-training的半监督SVM[J].计算机工程与应用,2009,45(22):103-106
[11]Cristianini N.支持向量机导论[M].李国正,王猛,曾华军,译.北京:电子工业出版社,2004:1-189
[12]庞雄昌,王吉吉,韩鲲.基于CVM的入侵检测[J].微计算机信息,2008,24(18):45-46
[13]Tsang I W,Andras K,James T,et al.Simpler core vector machines with enclosing balls[C]//New York:Proc of the Twenty-Fourth International Conference on Machine Learning(ICML),2007:911-918
[14]王奇安,陈兵.基于广泛内核的CVM算法的入侵检测[J].计算机研究与发展,2012,49(5):974-981
[15]Quang-Anh Tran.2005-Jul dataset[DB/OL].[2016-02-03].http://www.ccert.edu.cn/spam/sa/datasets.htm
[16]秦玉平,耿姝,孙宗宝.基于C-SVM和KPCA的垃圾邮件检测研究[J].计算机工程与应用,2010,46(19):94-96
(责任编辑:汪材印)
10.3969/j.issn.1673-2006.2016.08.029
2016-03-18
安徽省教育厅自然科学研究重点项目“基于deepweb 数据集成的企业情报个性化推送系统”(KJ2012A205);安徽省教育厅自然科学研究重点项目“半监督冗余特征检测技术”(KJ2016A502);巢湖学院“计算机图形学”课程开发项目(ch15yykc05)。
卜华龙(1980-),安徽巢湖人,硕士,讲师,主要研究方向:机器学习。
TP181
A
1673-2006(2016)08-0105-04
猜你喜欢
英语文摘(2021年10期)2021-11-22
潍坊学院学报(2020年2期)2021-01-18
中国惯性技术学报(2019年6期)2019-03-04
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
现代计算机(2016年11期)2016-02-28
火控雷达技术(2016年3期)2016-02-06
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01
电测与仪表(2014年15期)2014-04-04
