
基于Spark的土地利用矢量数据空间叠加分析方法
2016-05-14 09:12靳凤营张丰杜震洪刘仁义李荣亚浙江大学浙江省资源与环境信息系统重点实验室浙江杭州310028浙江大学地理信息科学研究所浙江杭州310027
浙江大学学报(理学版) 2016年1期
靳凤营,张丰,杜震洪*,刘仁义,李荣亚(1.浙江大学浙江省资源与环境信息系统重点实验室,浙江杭州310028;2.浙江大学地理信息科学研究所,浙江杭州310027)
基于Spark的土地利用矢量数据空间叠加分析方法
靳凤营1,2,张丰1,2,杜震洪1,2*,刘仁义1,2,李荣亚1,2
(1.浙江大学浙江省资源与环境信息系统重点实验室,浙江杭州310028;2.浙江大学地理信息科学研究所,浙江杭州310027)
摘 要:针对海量土地利用矢量数据空间叠加分析的效率问题,提出了基于Spark的土地利用矢量数据空间叠加分析方法,通过弹性分布式数据集实现索引过滤与叠加计算,为解决空间叠加分析的瓶颈问题做了新的尝试.实验结果表明,相较基于Oracle数据管理的叠加分析方法,该方法显著提高了空间叠加分析效率,更适合面向海量土地利用矢量数据的叠加分析.
关 键 词:Spark;土地利用;叠加分析;矢量数据
0 引 言
土地利用矢量数据是土地调查产生的主要成果数据,其数据量随着一年一度变更调查工作的开展而逐年增加.以浙江省为例,自第二次全国土地调查以来产生了200G左右的土地利用矢量数据,并以每年30G左右的速度增加.空间叠加分析是土地利用现状系统的重要功能,是在相同空间坐标系下,将2个空间上有重叠的图层相互套合,并按照一定规则(如Union,Intersect,Identity等)产生一个新图层的过程[1].
关于空间叠加分析,很多学者开展了相关研究.文献[2]提出了基于GPU的并行MBR过滤算法与多边形剪裁算法;文献[3]在现有点面、线面和面面叠加分析算法的基础上,提出了矢量数据叠加分析算法;文献[4]在均匀网格索引叠加分析算法的基础上,提出了基于非均匀多级网格索引叠加分析算法,包括索引构建、网格过滤、叠加计算、拓扑构面4个部分;文献[5]通过引入四叉树索引,实现了新的基于改进四叉树的矢量地图叠加分析双重循环算法;文献[6]提出了基于计算几何的矢量数据叠加分析算法.
这些研究工作大多基于单台计算机,计算能力有限,无法有效满足海量土地利用矢量数据高效叠加分析的需求.
针对上述难题,本文将云计算[7]技术引入土地利用矢量数据管理分析领域,利用云计算技术强大的、可弹性扩展的计算能力[8]开展土地利用矢量数据高效空间叠加分析研究.提出了一种基于Spark的土地利用矢量数据空间叠加分析方法,包括索引过滤与叠加计算.该方法通过改变数据的底层存储,以WKT模型在HDFS分布式文件系统上存储土地利用矢量数据,并构建四叉树[9]索引,在叠加分析方法的执行过程中过滤掉不需要参与叠加计算的空间对象,以提高计算效率.
第1节,设计了云环境下的土地利用矢量数据存储方法;第2节,基于Spark实现土地利用矢量数据四叉树索引的批量并行构建算法并设计了基于Spark的土地利用矢量数据空间叠加分析方法;第3节,实例测试空间叠加分析方法,并与基于Oracle的系统作了对比,最后对研究内容进行了总结.
1 基于HDFS的矢量数据存储
采用WKT模型在HDFS分布式文件系统上存储土地利用矢量数据.空间要素采用ID字段作为唯一标识符,属性数据以普通文本格式存储,空间数据以WKT格式存储.本文采用TSV格式,以TAB键分隔字段,将空间数据与属性数据存储为一行.
1.1 点数据存储
点数据的属性字段采用文本格式存储,空间字段采用WKT模型中的POINT(X Y)存储.点的X坐标和Y坐标之间以空格分隔,具体存储结构如表1所示.

表1 点数据存储Table 1 The storage of point
1.2 线数据存储
线数据的属性字段存储同点数据,采用文本格式,空间字段的存储则采用WKT模型中的LINESTRING(X1 Y1,X2 Y2)存储.整条线由点坐标对的形式组成,坐标X和Y之间以空格分隔,2个点之间以“,”分隔,具体存储结构如表2所示.

表2 线数据存储Table 2 The storage of polyline
1.3 面数据存储
面数据的属性字段同样采用文本格式存储,由于面要素比较复杂,有包含离散面多边形的情况,因此统一采用WKT模型中的MULTIPOLYGON(((X1 Y1,X2 Y2,X3 Y3,X1 Y1),(X4 Y4,X5 Y5,X6 Y6,X4 Y4)),(X7 Y7,X8 Y8,X9 Y9,X7 Y7))存储空间字段.MULTIPOLYGON可以表示多个分离的空间面多边形,同样采用点集的形式表示,坐标点的X和Y值之间采用空格分隔,坐标点之间采用“,”分隔.如果一个面要素含有多个离散面多边形,则属于同一个环的点集采用“()”与其他点集分隔,离散面多边形之间也采用“()”分隔,具体存储结构如表3所示.

表3 面数据存储Table 3 The storage of polygon
2 基于Spark的空间索引构建与叠加分析
2.1 基于Spark批量并行构建四叉树索引算法
采用Spark技术批量并行构建土地利用矢量数据空间索引的方式,以提升空间索引的构建效率.在四叉树索引中,为了快速检索空间对象,其节点存储的数据为原始空间对象的最小边界矩形.
Spark批量并行构建土地利用矢量数据四叉树索引算法流程如下:
首先循环遍历全部行政区的土地利用矢量数据,将每一行政区的土地利用矢量数据图层作为Spark输入数据源;在Map函数中读取空间对象数据并转换为Geometry,获取Geometry的最小边界矩形;在Reduce函数中将空间对象的BSM及最小边界矩形插入四叉树并序列化到HDFS,其中每一土地利用矢量数据图层对应一个四叉树索引文件.
Spark在运行阶段将土地利用矢量数据读入内存,以RDD(弹性分布式数据集)的形式存储,并通过MapReduce并行计算框架,实现空间索引的并行构建,加快了空间索引的构建速度.
Spark批量并行构建土地利用矢量数据四叉树索引的关键伪代码如下:
Map阶段:
Input:〈土地利用矢量数据〉
Output:〈FileIndex〈BSM,minX,minY,maxX,maxY〉〉
begin
Geometry Geom=GeometryFromWkt();
Envelope Env=new Envelope();
Env=Geom.QueryEnvelope();
Context.write(FileIndex,BSM,env.minX,env.minY,env.maxX,env.maxY);
end;
Reduce阶段:
Input:〈FileIndex〈BSM,minX,minY,maxX,
maxY〉〉
Output:〈FileQuadTree〉
begin
QuadTree Quadtree=new QuadTree();
f
or(Text val:values)
{
String[]arr=val.toString().split(“,”);
Quadtree.insert(arr[0].toInt(),new Envelope(arr [1].todouble(),arr[2].todouble(),arr[3].todouble(),arr [4].todouble()));
}
end for
SaveQuadTree(Quadtree);end;
2.2 基于Spark的空间叠加分析方法
下文将以土地利用矢量数据的空间相交(Intersect)为例详细描述基于Spark的土地利用矢量数据空间叠加分析方法的执行过程,框图见图1.
基于Spark的土地利用矢量数据Intersect运算过程包括索引过滤与Intersect计算.
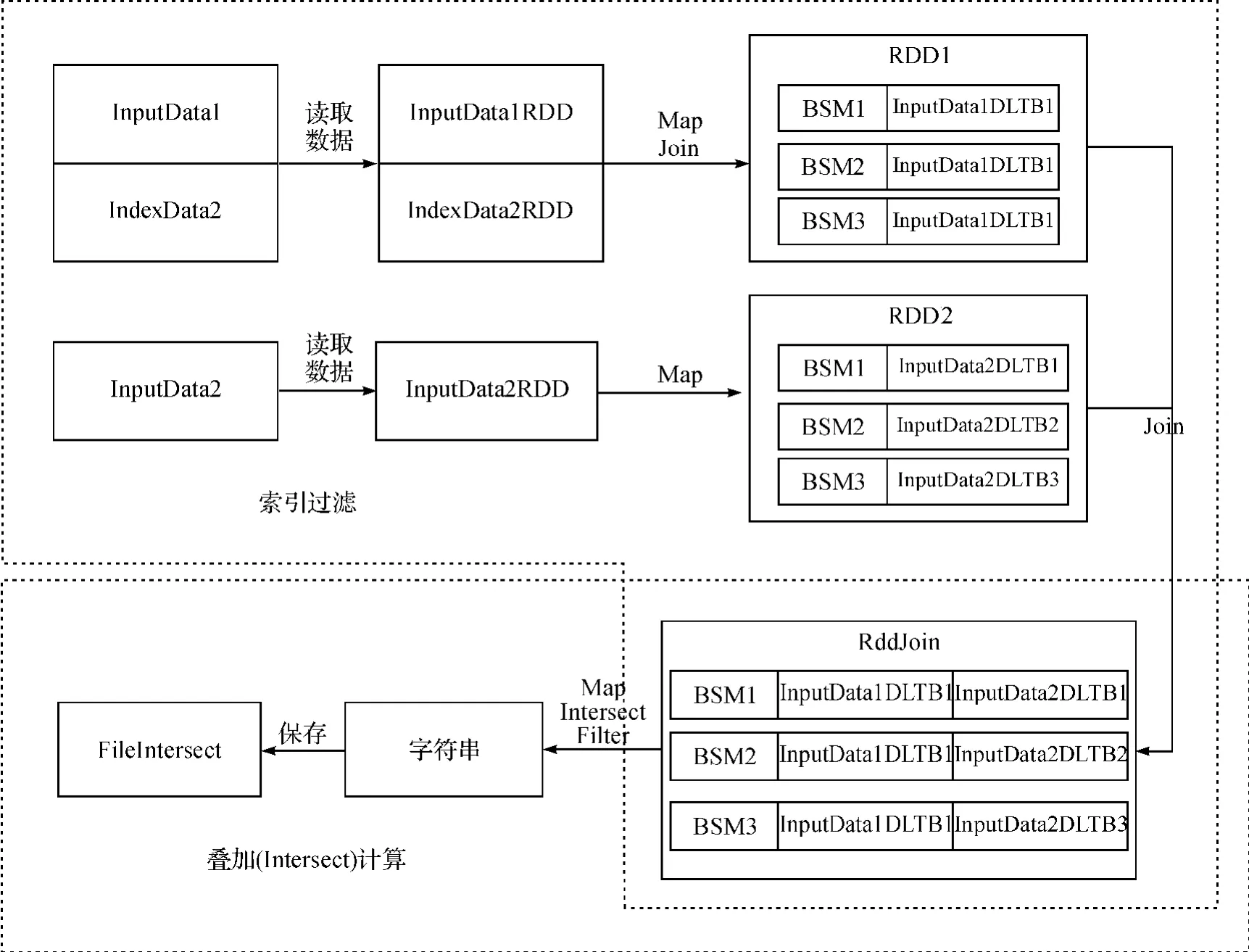
图1 基于Spark的矢量数据空间叠加分析Fig.1 Vector data spatial overlay analysis based on Spark
索引过滤:首先循环读取输入数据源InputData1和InputData2下的文件夹,将每一相应文件夹下的地类图斑数据以及InputData2地类图斑数据的四叉树索引文件分别读入RDD中,然后调用flatMapToPair函数处理InputData1,遍历Input-Data1地类图斑数据并与InputData2地类图斑数据的四叉树索引相比较.对于每一条InputData1地类图斑数据,从InputData2地类图斑数据的四叉树索引中取出与其相交的InputData2数据的BSM,并对两者做Join操作,其结果为多条InputData2数据的BSM与每一条InputData1的数据连接.对于InputData2的地类图斑数据则进行mapToPair操作,获取其BSM与空间列.将Map处理后的InputData1与InputData2地类图斑数据的RDD做Join操作,其结果为多条InputData2数据与每一条Input-Data1数据连接.
索引过滤的关键伪代码如下:
Input:〈InputData1,InputData2,IndexData2〉
Output:〈RddJoin〈BSM,Geom1,Geom2〉〉
begin
RDD Rdd1=Featureclass1.flatMapToPair({
QuadTree Quadtree=ReadQuadtree(FileQuad);
QuadIterator Quaditer=Quadtree.Iterator();
QuadTreeQuery();});
RDD Rdd2=Featureclass2.mapToPair();
RDD RddJoin=Rdd1.join(Rdd2);
end;
Intersect计算:对索引过滤后的RDD做Map操作,在Map阶段,将结果中的空间列取出并转换成Geometry,然后对其做Intersect操作.由于空间索引存储的是图形的最小边界矩形,进行Intersect操作存在2个图形不相交的情况,因此对于不相交的图形,将其返回结果设为“null”,并在做完Map操作后统一处理.最后,开启一个新进程执行结果数据写入功能,以使当前主进程继续执行下一个MapReduce操作.
Intersect计算的关键伪代码如下:
Input:〈RddJoin〈BSM,Geom1,Geom2〉〉
Output:〈FileIntersect〉
begin
RDD JoinMap=Rddjoin.map({
Geomerty GeoIntersect=Intersect(Geom1,Geom2,SpatialReferece);
If(!GeoIntersect.is Empty())
Stringutils.join(arr);
else return“null”;});
RDD JoinFilter=JoinMap.filter();
List Results=JoinFilter.collect();
SpatialIntersectWriteThread Writethread=new SpatialIntersectWriteThread(Results);
Writethread.start();
end;
3 实验与分析
采用云计算技术管理土地利用矢量数据,设计了基于Spark的土地利用矢量数据空间叠加分析方法,并与基于Oracle+ArcSDE的系统进行了性能对比.本次测试的硬件环境为:1个主节点、4个数据节点,每个节点配置Intel i7 950@3.07GHz处理器、16G内存、1T硬盘.软件环境为:操作系统SUSE Linux Enterprise Server 11SP2(x86_64),运行环境Hadoop 2.4.0、Spark 1.0.1.
本次实验以2个年份土地利用矢量数据地类图斑层的Intersect为例测试图层叠加分析的性能,实验数据为浙江省2010和2012年多个县级行政区土地利用矢量数据中的地类图斑数据.
图2为Spark与Oracle+ArcSDE的性能对比图.由图2可知,Spark的性能明显优于Oracle+ArcSDE,其所需的时间与数据量也呈线性关系,并且消耗时间要远少于Oracle+ArcSDE.
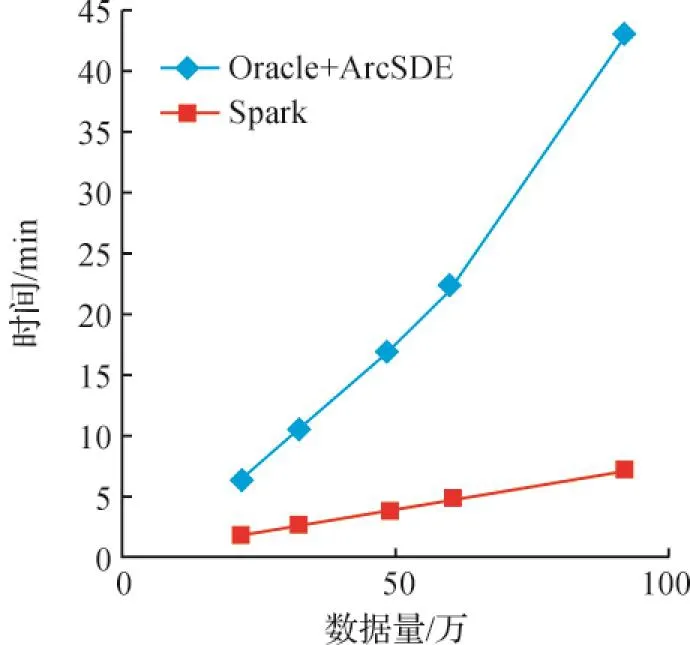
图2 空间Intersect时间对比图Fig.2 Time comparison chart of Intersect
图3所示为2个节点和4个节点下的土地利用矢量数据Intersect对比图.由图3可知,Spark在2个节点上与在4个节点上运行,所需的时间与数据量均线性相关,并且2个节点的效率与4个节点的效率呈一定比例关系.
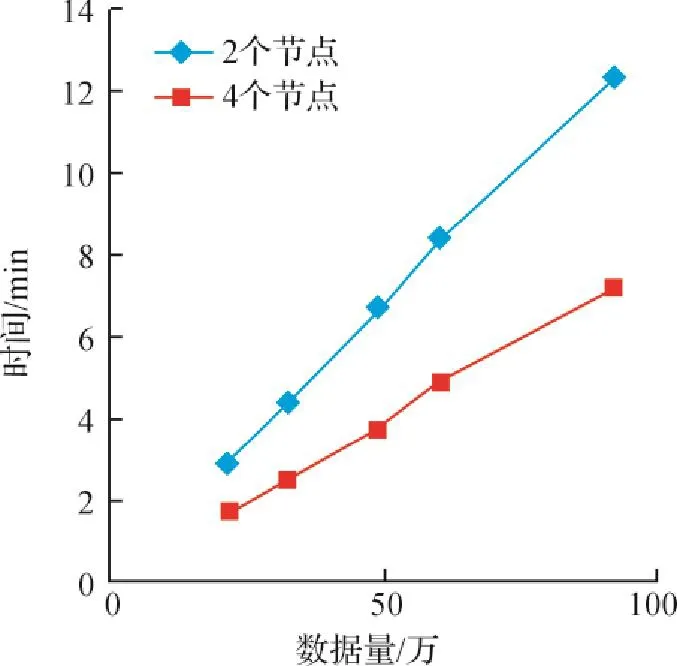
图3 空间Intersect节点对比图Fig.3 Nodes comparison chart of Intersect
通过以上实验测试,可以得到如下结论:在海量土地利用矢量数据叠加分析方面,Spark性能明显优于Oracle+ArcSDE,并且随着节点数量的增加,Spark性能呈一定比例提高.
4 结 语
将云计算引入土地利用矢量数据管理分析领域,尝试解决现有海量土地利用矢量数据叠加分析中效率低的问题.首先,基于HDFS提出了一种矢量数据存储方法,实现了海量土地利用矢量数据的分布式存储;其次,结合Spark技术研究土地利用矢量数据空间索引的批量构建算法,提出了基于Spark的土地利用矢量数据叠加分析方法,较好地完成了索引过滤和叠加计算,显著提升了叠加分析效率.对比实验表明,本文提出的叠加分析方法更适合海量土地利用矢量数据.
本文基于四叉树索引实现空间对象的过滤,但四叉树在数据空间分布不均匀的情况下,存在检索效率低的问题,下一步笔者将引入R树索引,以提高索引过滤效率.
参考文献(References):
[1] 陈述彭,鲁学军,周成虎.地理信息系统导论[M].北京:科学出版社,1999.CHEN Shupeng,LU Xuejun,ZHOU Chenghu.Introduction to Geographic Information Systems[M].Beijing:Science Press,1999.
[2] 赵斯思,周成虎.GPU加速的多边形叠加分析[J].地理科学进展,2013(1):114-120.ZHAO Sisi,ZHOU Chenghu.Accelerating polygon overlay analysis by GPU[J].Progress in Geography,2013(1):114-120.
[3] 朱效民,赵红超,刘焱,等.矢量地图叠加分析算法研究[J].中国图象图形学报,2010(11):1696-1706.ZHU Xiaomin,ZHAO Hongchao,LIU Yan,et al. Research on vector map overlay[J].Journal of Image and Graphics,2010(11):1696-1706.
[4] 王少华,钟耳顺,卢浩,等.基于非均匀多级网格索引的矢量地图叠加分析算法[J].地理与地理信息科学,2013(3):17-20,69.WANG Shaohua,ZHONG Ershun,LU Hao,et al.Vector map overlay analysis algorithm based on non-uniform multi-level grid index[J].Geography and Geo-Information Science,2013(3):17-20,69.
[5] 董鹏,李津平,白予琦,等.基于改进四叉树索引的矢量地图叠加分析算法[J].计算机辅助设计与图形学学报,2004(4):530-534,609.DONG Peng,LI Jinping,BAI Yuqi,et al.Vector map overlay algorithm based on improved quadtree indexing[J].Journal of Computer Aided Design &Computer Graphics,2004(4):530-534,609.
[6] 毛定山.基于计算几何的矢量数据叠加分析算法研究[D].济南:山东科技大学,2007.MAO Dingshan.Algorithm Study of Vector Data Overlaying Analysis Based on Computational Geometry[D].Jinan:Shandong University of Science and Technology,2007.
[7] HAYES B.Cloud computing[J].Communications of the ACM,2008(5):23-25.
[8] 李乔,郑啸.云计算研究现状综述[J].计算机科学,2011(4):32-37.LI Qiao,ZHENG Xiao.Research survey of cloud computing[J].Computer Science,2011(4):32-37.
[9] FINKEL R A,BENTLY J L.Quad trees a data structure for retrieval on composite keys[J].Acta Informatica,1974,4(1):1-9.
Spatial overlay analysis of land use vector data based on Spark
JIN Fengying1,2,ZHANG Feng1,2,DU Zhenhong1,2,LIU Renyi1,2,LI Rongya1,2(1.Zhejiang Provincial Key Lab of GIS,Zhejiang University,Hangzhou 310028,China;2.Department of Geographic Information Science,Zhejiang University,Hangzhou310027,China)
Journal of Zhejiang University(Science Edition),2016,43(1):040-044
Abstract:To increase the spatial overlay analysis efficiency of massive land use vector data,we proposes a method of land use vector data spatial overlay analysis based on Spark.The method realizes index filtering and overlay calculating of land use vector data by resilient distributed datasets(RDD),which is a basic data structure of Spark.It makes a new attempt to overcome the bottleneck of land use vector data spatial overlay analysis.Comparing with the traditional overlay analysis based on Oracle data management,the approach increases the spatial overlay analysis efficiency significantly,which is more suitable for spatial overlay analysis with massive land use vector data,and can help us to manage and analyse the massive land use vector data.
Key Words:Spark;land use;overlay analysis;vector data
通信作者*,E-mail:duzhenhong@zju.edu.cn.
作者简介:靳凤营(1990-),男,硕士研究生,主要从事国土资源地理信息系统基础研究.
基金项目:国家自然科学基金资助项目(41471313,41101356);浙江省科技攻关计划项目(2013C33051);国家海洋公益性行业科研专项经费资助项目(2015418003,201305012);国家科技基础工作专项(2012FY112300);中央高校基础科研业务费专项(2013QNA3023).
收稿日期:2015-05-06.
DOI:10.3785/j.issn.1008-9497.2016.01.007
中图分类号:P 208
文献标志码:A
文章编号:1008-9497(2016)01-040-05
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化·高一版(2021年11期)2021-09-05
农业资源与环境学报(2021年4期)2021-07-30
重型机械(2020年2期)2020-07-24
中国航海(2019年2期)2019-07-24
中国神经再生研究(英文版)(2018年6期)2018-06-21
中国资源综合利用(2017年4期)2018-01-22
现代防御技术(2016年1期)2016-06-01
