
基于经验模态分解的煤炭消费量组合预测
2016-11-03 05:11鞠金艳祝荣欣
黑龙江科技大学学报 2016年1期
鞠金艳, 祝荣欣, 陈 玉
(黑龙江科技大学 机械工程学院, 哈尔滨 150022)
基于经验模态分解的煤炭消费量组合预测
鞠金艳,祝荣欣,陈玉
(黑龙江科技大学 机械工程学院, 哈尔滨 150022)
为了明确煤炭消费量的发展变化规律和趋势,科学引导煤炭行业健康、有序发展。针对煤炭消费量的时间序列变化具有增长性、波动性和非平稳性的特点,采用经验模态分解法对1978~2014年煤炭消费量进行多层次分解,得到其发展变化的趋势量和波动量。利用BP神经网络的非线性映射能力,分别对趋势量和波动量进行预测,最终二者相加求和得到煤炭消费量的预测值。误差分析表明,基于经验模态分解的煤炭消费量组合预测模型,拟合值的平均误差为2.18%,预测值的平均误差为1.24% 。该组合预测模型可以有效的提高煤炭消费量的预测精度,用该模型预测了2015~2020年煤炭消费量。预测结果表明,在未来几年煤炭消费量将保持低速增长趋势,到2020年将达到341 718.2万t标准煤。
煤炭消费量; 经验模态分解; 组合预测; BP网络; 时间序列
0 引 言
煤炭是我国重要的基础能源,经济发展、工业化和城镇化进程都离不开煤炭资源的支持。在未来一段时期,煤炭仍然是能源消费的主体,预测煤炭消费量的动态发展变化趋势,对科学测算煤炭开采规模,合理开发和利用煤炭资源,努力保持煤炭供需基本平衡,相关部门和机构更合理地制定煤炭工业发展政策、措施,加强对煤炭总量的宏观调控,确保煤炭行业平稳健康发展等具有重要的意义[1-2]。国外对煤炭消费的研究主要集中于研究煤炭消费量的波动情况、价格的变化及其主要影响因素等,研究的方法主要有向量自回归模型、小波分析、ADL空间分布模型等[3-5]。我国学者预测煤炭消费量相关的研究较多,主要分为三类:一类是对煤炭消费量时间序列进行预测,方法主要有指数平滑、弹性系数法、马尔科夫预测模型、灰色GM(1,1)模型、支持向量机、神经网络预测模型、组合预测等[6-7];第二类是通过分析影响煤炭消费的主要因素,然后采用灰色GM(1,n)模型,多元回归模型、自回归模型或神经网络模型等,建立煤炭消费量和主要影响因素之间的关系模型,进而预测出煤炭消费量的变化情况[8-9];第三类是通过分析主要消耗煤炭资源的各部门的发展变化情况,得出煤炭消费量变化情况[10]。这些方法各有其优点和不足,时间序列预测方法能很好的预测未来发展趋势,但难以准确预测出煤炭消费量系统中的非线性关系,导致预测精度不高;根据主要影响因素的变化,能预测未来的煤炭消费情况,但需要事先预测出各影响因素的未来发展变化情况,因此操作起来复杂,而且影响因素的选取直接影响分析结果的差异。
煤炭消费量受诸多因素的影响,发展变化既具有随时间推移的增长性趋势,又具有一定的波动性和非平稳性的特点。因此,直接对煤炭消费量时间序列进行预测很难得到准确的预测结果。为提高预测结果可靠性,笔者采用经验模态分解法分解出煤炭消费量时间序列的变化趋势量和波动量,分别对变化趋势量和波动量进行预测,最终将二者预测结果相加求和得到煤炭消费量的预测值。
1 建模思想与方法
1.1建模思想
煤炭消费量时间序列的增长性、波动性和非平稳性的变化特点,决定了直接采用时间序列预测方法很难准确预测出其未来发展情况。Huang N.E.等提出的经验模态分解法(Empirical mode decomposition,EMD),是一种处理非平稳、非线性信号的时频信号分析法,对时间序列信号的分解具有客观性和稳定性的优势[11-12]。经验模态分解法通过对信号序列进行逐级线性化和平稳化处理,分解出原信号序列的发展趋势量和所有包含原信号不同时间尺度特征信息的波动分量,即本征模态函数。文献[12]中详细介绍了经验模态分解法的基本原理和计算过程,文中不再详细介绍。采用经验模态分解法对煤炭消费量时间序列进行分解,得到煤炭消费的趋势量和波动量,再选择合适的方法分别对趋势量和波动量进行预测,可以提高煤炭消费量预测结果的准确度[13-14]。
BP神经网络具有较好的逼近非线性函数的能力,在预测领域应用得非常广泛[15-18]。采用BP神经网络对分解出的煤炭消费趋势量和波动量分别进行预测。BP神经网络由输入层、若干个隐含层和输出层构成,如图1所示。图1是含有两个隐含层I和J的BP网络结构。BP神经网络具有逼近非线性函数的能力,但有时会陷入局部极小值,影响泛化能力,进而影响预测精度。研究表明,直接采用BP神经网络对时间序列进行预测,必须采用滚动预测的方法,这种方法要求样本量大而且预测精度不是很高[15,17]。传统的时间序列预测方法能很好的拟合数据序列的发展趋势,但不适合逼近复杂的非线性函数。因此,可以将BP神经网络和传统的时间序列预测方法相结合,取长补短,采用组合预测的方法对时间序列进行预测。
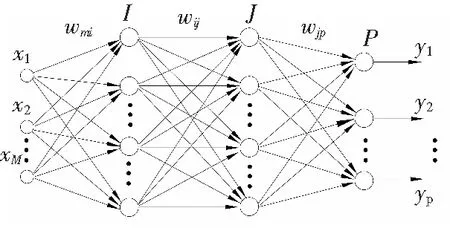
图1 两个隐含层的BP网络结构
1.2建模方法
基于经验模态分解法建立煤炭消费量组合预测模型,具体建模步骤如下:
(1)采用经验模态分解法对1978~2014年煤炭消费量进行分解,得到煤炭消费趋势量和波动量,然后选择预测方法分别对趋势量和波动量进行预测。
(2)为了准确的预测出煤炭消费趋势量的变化,采用传统预测方法对煤炭消费趋势量建立多种单一预测模型,并对建立的模型进行显著性和拟合优度检验,计算拟合值的平均绝对百分误差,为了保证预测精度,一般误差值应小于10%。
(3)用建立的各单一预测模型拟合1978~2014年煤炭消费趋势量的值,将其中1978~2011年煤炭消费趋势量的拟合值作为BP网络的输入向量(P),煤炭消费趋势量的实际值作为BP网络的输出向量(T),运用MATLAB7.6.0语言编写程序,确定网络参数,建立组合预测模型中各单一预测模型拟合值与实际值之间的非线性映射关系。
(4)判断BP网络的学习精度是否达到要求,并以2012~2014年煤炭消费趋势量的数据作为检验样本,来验证网络的泛化能力是否满足要求,若满足要求,运算停止;否则,重新设定网络结构的相关参数,继续训练学习。
(5)将各单一预测模型预测出的2015~2020年煤炭消费趋势量的数值输入训练好的BP神经网络,仿真后得到相应的煤炭消费趋势量预测值。
(6)预测煤炭消费波动量的发展变化,由于其波动的非平稳性,传统预测方法无法对其进行准确预测,因此,采用BP神经网络进行滚动预测,确定滚动预测模型的相关参数,实现非线性拟合,检验拟合精度和泛化能力,进而对煤炭消费波动量进行预测。
(7)将1978~2014年煤炭消费趋势量和波动量的预测值相加求和,得到总的煤炭消费量预测值,并计算预测值和实际值的误差,若满足要求,则用其对2015~2020年煤炭消费量进行预测。
2 煤炭消费量的预测
2.1数据的来源
文中主要使用1978~2014年煤炭消费量的数据,是折算成标准量(标准煤)后的数据,该数据不能直接查到,但可通过查阅能源消费总量的统计数据,并将其与煤炭消费量占能源消费总量的比重进行乘积,计算得到煤炭消费量的数据。1978~1985年数据来源为《新中国六十年统计资料汇编》,1986~2014年数据来源为《中国统计年鉴》。
2.2煤炭消费量的经验模态分解
煤炭消费量的发展变化受经济增长、煤炭价格、产业结构、能源结构和人口数量等多种因素的共同影响,煤炭消费量时间序列既有明显的增长趋势,又具有一定的波动性和非平稳性的特点。采用经验模态分解法,应用Matlab软件编程,对1978~2014年煤炭消费量时间序列进行分解,得到1个趋势量和1个波动量,分解结果如图2和表1所示。由图2可知,煤炭消费趋势量反映了各种影响因素所引起的煤炭消费量的长期增长趋势,波动量主要反映了煤炭消费量总体的波动情况,短周期的波动较普遍发生。煤炭消费趋势量的增长变化是煤炭消费总量变化的主导因素,煤炭消费波动量变化对煤炭消费总量的影响相对较小,因此,准确的预测煤炭消费趋势量的增长变化情况,直接影响煤炭消费总量预测结果的准确性。

图2 煤炭消费量及其经验模态分解结果
Fig. 2Coal consumption and its empirical mode decomposition
2.3煤炭消费趋势量的预测
2.3.1单一预测模型的建立
利用SPSS软件对1978~2011年煤炭消费趋势量时间序列数据进行曲线拟合,得到拟合精度较高的预测模型,分别为指数函数模型和一元线性回归模型,如式(1)和(2)所示。指数函数模型的判定系数R2=0.979,一元线性回归模型的判定系数R2=0.865,两个模型都通过 检验,模型极显著。用式(1)和(2)对我国1978~2011年煤炭消费趋势量值进行预测,得到预测值。
Y=35 346.154e0.057x,
(1)
Y=2 042.373+6 267.658x,
(2)
式中:Y——煤炭消费趋势量值,万t;
x——时间变量,1978~2011年的对应取值分别为1~34。
2.3.2 BP神经网络组合预测模型的建立
(1)BP网络输入和输出向量的确定。BP网络输入向量(P)是指数函数模型和一元线性回归模型2种预测方法预测出的1978~2011年煤炭消费趋势量的预测值,因此BP网络输入层有2个输入节点,BP网络的输出向量(T)是煤炭消费趋势量的实际值,因此,输出层有1个输出节点,从而建立了2个预测模型的预测值与相应实际值之间的非线性映射关系。

表1 煤炭消费量分解及预测结果与误差
(2)隐含层及节点数的确定。逼近任何一个非线性函数可用含有一个隐含层的3层BP神经网络实现[13-15],文中选用1个隐含层的网络。隐含层节点数采用逐渐增加的方法确定为3最理想,即BP网络结构为2-3-1。
(3)BP网络隐含层转换函数为“Sigmoid”,输出层转换函数为“Purelin”,训练函数采用预测精度和速度上都优于其他算法的“Trainlm”,网络训练的相关参数为学习精度5×10-5,学习速率0.01,迭代步数2 000,对网络进行训练学习。
(4)判断BP网络的学习精度是否达到要求,并以2012~2014年煤炭消费趋势量的数据作为检验样本,来验证网络的泛化能力是否满足要求。若满足要求,运算停止,得到相应节点的权值和阈值;否则,重新设定网络结构的相关参数,继续训练学习。文中构建的BP网络在训练精度MSE为4.15×10-5时,精度达到要求,训练好的BP网络的煤炭消费趋势量的拟合值、预测值及其误差值e如表1。由表1可知,BP神经网络组合预测模型得到的1978~2011年煤炭消费趋势量拟合值的平均误差为2.7%, 2012~2014年煤炭消费趋势量预测值的平均误差为1.2%,可见,组合预测模型既有较好的拟合能力和预测能力,可以用此模型对2015~2020年煤炭消费趋势量进行预测。
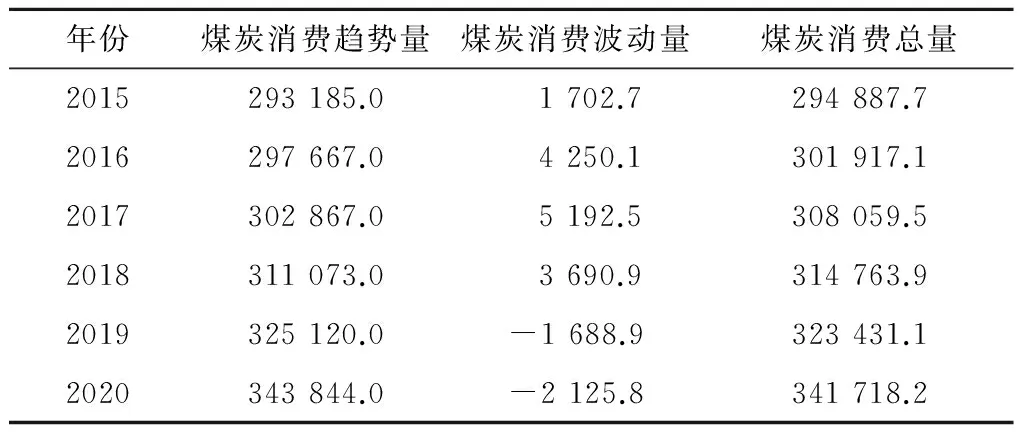
(5)将指数函数模型和一元线性回归模型预测出的2015~2020年煤炭消费趋势量的值输入训练好的BP神经网络预测模型,仿真后得到2015~2020年煤炭消费趋势量的预测值,预测结果见表2。
表22015~2020年煤炭消费量预测值
Table 2Predicted values of coal consumption from 2015 to 2020 万t
年份煤炭消费趋势量煤炭消费波动量煤炭消费总量2015293185.01702.7294887.72016297667.04250.1301917.12017302867.05192.5308059.52018311073.03690.9314763.92019325120.0-1688.9323431.12020343844.0-2125.8341718.2
2.4煤炭消费波动量的预测
由图2可知,1978~2014年煤炭消费波动量时间序列的波动性较强,采用曲线回归、自回归模型和灰色预测等方法很难对其进行准确预测,因此,利用BP神经网络具有逼近非线性函数的特点,对其进行预测。采用BP神经网络对时间序列进行预测必须采用滚动预测的方法[13],即用前几年的数据预测下一年的数据。
BP神经网络的煤炭消费波动量预测模型的建模过程与预测趋势量的建模过程基本相同。根据图2的煤炭消费波动量变化规律及文献[19]中采用BP 滤波对 1953~2012 年煤炭消费需求波动曲线的变化特征分析可知,煤炭消费波动量时间序列的波动周期为3~6 a,因此将BP网络输入层节点数分别确定为3个、4个和5个进行对比试验,最终确定BP网络输入层节点为4个最理想,输入向量(P)是1978~2010年煤炭消费波动量的实际值,随着时间序列逐年滚动,每4年为一组作为输入向量, BP网络的输出向量(T)是煤炭消费波动量输入向量的下一年的实际值,即应为1982~2011年煤炭消费波动量的实际值,因此输出层有1个输出节点。例如:将1978~1981年煤炭消费波动量的实际值输入网络,可预测出1982年煤炭消费波动量的值,逐年滚动,共有30组训练样本。BP网络的隐含层数选择1,采用逐渐增加节点的方法确定隐含层节点数为4,BP网络结构为4-4-1。BP网络各层函数的选择与趋势量预测相同,网络训练的参数为学习精度10-6,学习速率0.01,迭代步数3 000,对网络进行训练。以2012~2014年煤炭消费波动量的数据作为检验样本,验证网络的泛化能力是否满足要求,用训练好的BP网络预测煤炭消费波动量,拟合值、预测值及其相对误差值如表1。
由表1可知,BP神经网络预测得到的1982~2011年煤炭消费波动量拟合值的平均误差为6.6%,2012~2014年煤炭消费波动量检验样本预测值的平均误差为3.7%,可见BP网络预测的煤炭消费波动量拟合效果一般,短期预测效果很好。由于煤炭消费波动量在整个煤炭消费总量中所占的比重较小,预测精度稍低不会对整个模型的预测效果产生大的影响。将2011~2014年煤炭消费波动量的值输入训练好的BP神经网络,编写Matlab程序,采用滚动预测的方法对2015~2020年煤炭消费波动量进行预测,预测结果见表2。
2.5煤炭消费量的预测
采用经验模态分解法将煤炭消费量分解为煤炭消费趋势量和波动量,并分别对二者进行了预测。煤炭消费趋势量和波动量的预测结果相加求和即可得到煤炭消费总量的预测值,见表1。由表1可知,1982~2011年煤炭消费量拟合值的平均误差为2.18%,2012~2014年煤炭消费量检验样本预测值的平均误差为1.24%,因此组合模型精度较高。
为了证明组合模型的预测效果更佳,采用BP神经网络对1978~2014年煤炭消费量时间序列数据建立滚动预测模型,将时间序列分为训练样本和检验样本。BP神经网络输入层节点为4个,网络结构为4-4-1,训练函数为“Trainlm”。 网络训练的参数为学习精度0.007、学习速率0.01、迭代步数1 000。训练样本为时间序列组成的前30组数据,检验样本为最后3组数据,通过对BP网络训练精度和检验精度的控制,得到BP网络满足泛化能力要求的权值。用训练好的BP网络对煤炭消费量进行预测,拟合值、预测值及其相对误差值见表1最后两列。由表1可知,BP网络滚动预测得到的1982~2011年煤炭消费量拟合值的平均误差为4.18%,2012~2014年煤炭消费量检验样本预测值的平均误差为3.45%,因此BP网络模型精度低于文中提出的基于经验模态分解的组合预测模型。故该组合预测模型可用于对2015~2020年煤炭消费量进行预测,预测值见表2。
由表2可知,在今后一段时期内,煤炭消费量还将保持低速增长态势,煤炭仍将是经济社会发展和人民生活水平提高中的重要能源之一。近年来,我国经济低速增长,宏观经济进入转型期,所以能源需求增长幅度不大,煤炭消费的增长速度渐缓,加上各城市环境污染问题日益突出,为改善环境质量,煤炭消费面临越来越大的压力,煤炭行业由快速发展时期转入低速发展期。“十三五”时期,我国经济社会发展呈现新趋势,煤炭工业发展机遇与挑战并存。一方面,从宏观经济发展趋势看,随着我国工业化、信息化、城镇化、农业现代化持续推进,能源需求仍将保持增长,煤炭作为我国能源的主体地位不会改变。另一方面,我国经济发展进入新常态,经济结构不断优化,能源结构不断优化,非化石能源比重上升,替代煤炭作用增强。同时,随着科技进步,煤炭利用方式、利用领域不断拓展,煤炭将由燃料向燃料和原料并重转变。
3 结 论
(1)从提高煤炭消费量预测精度的目的出发,针对煤炭消费量时间序列具有增长性、波动性和非平稳性的特点,采用经验模态分解法分解出煤炭消费量时间序列中的趋势量和波动量,由分解结果可知煤炭消费趋势量增长趋势明显,波动性较小,并且其发展变化是影响煤炭消费总量变化的主要因素,煤炭消费波动量的波动性较大,其发展变化对煤炭消费总量的影响较小。
(2)煤炭消费趋势量占煤炭消费总量的比重较大,为了较准确的对煤炭消费趋势量进行预测,分别建立了煤炭消费趋势量预测的指数函数模型和一元线性回归模型,并利用BP神经网络的非线性映射能力,综合利用指数函数模型和一元线性回归模型提供的有效信息,确定组合预测模型中各单一预测模型的权重,并利用建立的组合预测模型对煤炭消费趋势量进行了预测。通过预测精度分析可知,组合预测模型的拟合平均误差为2.7%,预测平均误差为1.2%,模型具有较好的预测效果。
(3)煤炭消费波动量的波动性较大,用传统预测方法很难对其进行准确预测,因此利用BP神经网络具有逼近非线性函数的特点,采用滚动预测的方法,BP网络结构为4-4-1,对其进行预测。预测结果表明,模型拟合值的平均误差为6.6%,预测值的平均误差为3.7%,模型的预测精度稍低,但满足预测精度要求。由于每年的煤炭消费波动量占煤炭消费总量的比重较小,因此其对煤炭消费总量的预测结果影响不大。
(4)提出的基于经验模态分解的煤炭消费量组合预测模型,对1982~2014年煤炭消费总量进行了预测,1982-2011年煤炭消费量拟合值的平均误差为2.18%,2012~2014年煤炭消费量预测值的平均误差为1.24%,模型预测精度较高。
(5)研究结果为煤炭消费量预测提供了一种新的方法,应用该方法对2015~2020年煤炭消费量进行了预测。预测结果表明,2015~2020年煤炭消费量将保持低速增长的态势,研究结果为有关部门掌握煤炭消费量的短期发展趋势,颁布煤炭工业发展的相关政策、措施等提供参考。
[1]高峰.我国煤炭需求总量分析与预测[J].煤炭经济研究,2014, 34(4): 10-14.
[2]刘满芝,高晓峰,屈传智,等. 中国煤炭需求波动规律研究[J].资源科学, 2013, 35(4): 681-689.
[3]MUDIT K, JYOTI K P. Modeling demand for coal in India: vector autoregressive models with cointegrated variables[J]. Energy, 2000, 25(2): 149-168.
[4]GUDARZI FARAHANI YAZDAN, VARMAZYARI BEHZAD, MOSHTARIDOUST SHIVA. Consumption in Iran: past trends and future directions[J]. Economics and Management, 2012, 62(1): 12-17.
[5]CRISTINA CATTANEO, MATTEO MANERS, ELISA SCARPA. Industrial coal demand in China: A provincial analysis[J]. Resource and Energy Economics, 2011, 33(1): 12-35.
[6]孙涵, 付晓灵, 张先锋. 基于支持向量回归机的中国煤炭长期需求预测[J].中国地质大学学报, 2011, 11(9) :15-18.
[7]杨俊祥, 程盛芳.灰色-周期外延组合模型在煤炭需求预测中的应用[J]. 统计与决策, 2010, (13): 162-163.
[8]樊爱宛, 潘中强, 王巍. 灰色 GM(1,N)模型在河南省煤炭需求预测中的应用[J].煤炭技术,2011, 30(10): 7-9.
[9]丁宏飞, 黄福玲, 吴建乐. 基于GA-SVR 的煤炭需求预测模型研究[J].西南民族大学学报, 2010, 36(3): 402-404.
[10]林伯强, 毛东昕. 煤炭消费终端部门对煤炭需求的动态影响分析[J].中国地质大学学报, 2014, 14(6): 1-12.
[11]鞠金艳, 赵林, 王金峰. 农机总动力增长波动影响因素分析[J]. 农业工程学报, 2016, 32(2): 84-91.
[12]HUANG N E, SHEN Z, LONG S R, et al. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis[J]. Proc R Soc Land A,1998, 454(3): 899-955.
[13]郭书琴. 基于经验模态分解的短期电力负荷预测[D].北京: 华北电力大学, 2010.
[14]蔡吉花, 张世军, 杨丽. EMD-SVM在南京市月平均气温预测中的应用, 2014, 44(22): 103-111.
[15]鞠金艳, 王金武. 黑龙江省农业机械化作业水平预测方法[J].农业工程学报, 2009, 25(5): 83-88.
[16]杨娟丽, 徐梅, 王福林, 等. 基于BP神经网络的时间序列预测问题研究[J].数学的实践与认识, 2013, 43(4): 158-164.
[17]鞠金艳. 黑龙江省农业机械化发展的系统分析与对策研究[D].哈尔滨: 东北农业大学, 2011.
[18]AMINIAN F, SUAREZ E D.Forecasting economic data with neural networks[J].Computational Economies, 2006, 28(1): 71-88.
[19]张洪潮, 王泽江, 李晓利, 等. 中国煤炭消费需求波动规律及成因分析[J].中国人口资源与环境,2014, 24(1): 94-101.
(编辑徐岩)
Combined prediction method of coal consumption based on empirical mode decomposition
JUJinyan,ZHURongxin,CHENYu
(School of Mechanical Engineering, Heilongjiang University of Science & Technology, Harbin 150022, China)
This paper aims to investigate the law behind how coal consumption tends to develop in an effort to guide the healthy and orderly development of coal industry. In response to the growth, volatility, and instability inherent in the time series of coal consumption, the research using empirical mode decomposition method consists of the multi- level decomposition of the time series of coal consumption from 1978 to 2014 to obtain its development trend quantity and fluctuation quantity; the prediction of the trend quantity and fluctuation quantity using the nonlinear mapping ability of BP neural network and ultimate achievement of the forecasting results of coal consumption by summing the two forecast results. The error analysis shows that combined prediction model of coal consumption based on empirical mode decomposition gives an average error of 2.18% for fitted values and the average error of 1.24% for predicted values. The model enables an effective improvement in the forecast accuracy of coal consumption and works better for predicting coal consumption between 2015 and 2020. The prediction show that the coal consumption tends to keep a moderate growth in the coming years, and is expected to reach 3.417182 billion tce by 2020.
coal consumption; empirical mode decomposition; combination forecast; BP network; time series
2015-12-06
鞠金艳(1982-),女,黑龙江省哈尔滨人,讲师,博士,研究方向:生产管理与系统工程,E-mail:ju_jinyan@163.com。
10.3969/j.issn.2095-7262.2016.01.024
F407.21
2095-7262(2016)01-0110-07
A
猜你喜欢
英语文摘(2021年3期)2021-07-22
矿山安全信息(2020年12期)2020-01-05
小学科学(学生版)(2019年11期)2019-12-09
今日农业(2019年12期)2019-08-13
中国外汇(2019年23期)2019-05-25
文学少年(原创儿童文学)(2019年1期)2019-05-23
中国化肥信息(2019年3期)2019-04-25
能源(2018年4期)2018-01-15
印刷技术·数字印艺(2015年6期)2015-08-31
能源(2015年8期)2015-05-26
