
在线社交网络用户分析研究综述
2016-12-02 06:14李春英贺超波汤志康黄泳航
华南师范大学学报(自然科学版) 2016年5期
李春英, 汤 庸, 贺超波, 汤志康, 黄泳航
(1. 华南师范大学计算机科学学院, 广州 510631; 2. 广东技术师范学院计算机网络中心, 广州 510665;3. 仲恺农业工程学院信息科学与技术学院, 广州 510225; 4. 广东技术师范学院计算机科学学院, 广州 510665)
在线社交网络用户分析研究综述
李春英1,2, 汤 庸1*, 贺超波3, 汤志康4, 黄泳航1
(1. 华南师范大学计算机科学学院, 广州 510631; 2. 广东技术师范学院计算机网络中心, 广州 510665;3. 仲恺农业工程学院信息科学与技术学院, 广州 510225; 4. 广东技术师范学院计算机科学学院, 广州 510665)
在对国内外在线社交网络用户分析相关研究归纳总结的基础上,综述了在线社交网络用户分析的最新进展,主要包括通过用户影响力和用户偏好进行用户行为分析、采用隐式和显式的分类方法对用户属性预测算法进行综述,简述了基于用户属性特征或(和)用户关系拓扑结构的用户分类研究进展,并分析了动态社交网络、并行算法及社交用户语义信息给在线社交网络用户分析所带来的机遇和挑战,对该研究方向上的发展趋势进行了展望.
在线社交网络; 行为分析; 影响力分析; 偏好分析; 属性预测; 用户分类
随着网络技术和智能终端的快速发展,在线社交网络(Online Social Network,OSN)已成为人们日常必不可少的工具之一. 截至2014年12月一些日常通用的主流社交网络(包括Facebook、Twitter、QQ、QQ空间、微信、Wechat、Amazon及新浪微博等)月活跃用户之和已经达到40亿人次,超过了目前世界总人口的一半. 另外,一些垂直社交网络(如用于旅游、饮食、购物、医疗、农业和学术研究等)通过提供优质便捷的专业服务也吸引了众多用户. 实际上,OSN平台在跨越时空限制、便捷共享信息、交友、娱乐、购物和商务合作的同时,产生了各种各样的海量数据. 这些迅速增长的海量社交信息为社会发展和经济建设提供了宝贵的资源. 因此,近些年OSN受到计算机科学、物理学、数学、生物学、管理学、心理学、社会学以及复杂性系统科学等多学科的广泛关注,成为科学研究者们关注的热点问题.
在线社交网络服务是典型的以人为中心的计算(Human Centered Computing,HCC),用户是在线社交网络的主体[1]. 在线社交网络以用户相互建立关系为基础,以实名或者非实名的方式自主构建社交关系网络服务. 在线社交网络在为用户提供便利的同时,也带来了用户隐私数据泄露的问题. 为了防止隐私数据泄露,一些社交用户隐藏了自己的个人信息. 研究表明,社交网络50%左右的用户选择了隐藏他们的用户信息,近70%的用户选择了隐藏他们的兴趣爱好[2]. 尽管社交网络用户隐藏了部分信息,但通过他们在线创建的内容、群体互动及信息传播等,仍可以挖掘用户隐藏的信息,并进一步跟踪用户的动向,对维护国家信息安全、社会稳定、经济发展以及改善人们的日常工作和生活等均具有积极作用. 例如,SANDRA等[3]基于在线社交网络大数据研究了网络抗议招募的动态变化规律,并揭示其对政治走向的影响. TUMASJAN等[4]使用文本分析软件LIWC(Linguistic Inquiry and Word Count)对Twitter上任何一个政党或者政客的参考信息进行分析,结果表明Twitter确实广泛用于政治协商,从一个政党少数的消息上便可以预测选举结果. 因此,分析在线社交网络用户数据,能够准确把握用户在社交网络上的行为规律和发展动态,有助于对网络事件进行分析、引导、监控和为OSN用户提供精确的个性化服务,对规范社交网络的管理和服务,保障国家政治、经济和社会安全具有重要的理论研究意义和现实应用价值.
社交网络用户分析是一个热门研究领域,同时也是多学科交叉研究领域. 《Science》发表了多篇论文阐述社交网络中用户的互动行为及其相互影响关系、社交网络的隐私行为特征和动机、社交网络用户行为预测等[5-7]. 在针对社交网络用户分析的研究中,代表性研究话题主要包括用户行为分析、属性预测及分类. 因此,本文将详细阐述这3个角度的研究现状,并指出目前该领域研究存在的问题和挑战.
1 用户行为分析
杨善林等[8]从在线社交网络的用户采纳与持续使用行为、用户个体使用行为和用户群体互动行为等3个方面对社交网络用户行为的影响因素、行为特征和一般行为规律等进行了详细的阐述,论述了用户为什么使用社交网络、如何使用社交网络和用户之间的互动机理等,指出了在线社交网络用户行为在用户行为一致性、用户间行为的相互影响、监管政策与用户行为间的相互作用等方面的研究机会. TANG等[9]研究OSN结构的演化规律和信息传播规律的理论基础,提出OSN用户行为的跨学科、跨领域、跨机构、跨组织的交叉研究是未来的研究模式. 实际上,社交网络用户(简称用户)行为主导着社交网络的发展和演变规律,分析用户的行为与特征,能够对复杂社交网络的发展与演变进行宏观分析. 分析结果能够进一步有效挖掘深层次的社交关系和社交网络的发展演变规律. 目前,用户行为分析可以粗略地分为用户影响力分析和用户偏好分析,用户影响力和用户偏好在社交网络演化、信息传播及推荐系统中扮演着重要角色.
1.1 用户影响力分析
在线社交网络用户影响力在虚拟网络社区、网络群体、信息传播以及话题发展趋势中发挥着巨大的作用,能够激发舆论、推动话题迅速扩散进而导致社交网络结构的发展和演变以及对真实世界产生实质性的影响. 近年来,研究人员对用户影响力进行了多方面的研究探索,并取得了丰富的研究成果:研究了用户在社交网络中的影响力,在130万Facebook用户数据集的实验结果表明:年轻人比老年人更易受到影响,男人比女人更有影响力,女人在男人中的影响力比在女人中的影响力强,已婚女士更易接受推荐的商品,有影响力的个人不易受到没有影响力的个人的影响,有影响力的社交网络用户很可能是传播网络产品的工具,以及具有影响力的用户更倾向于在彼此之间形成社交圈等[6];基于新浪微博大规模数据集,结合用户社会影响力在微博中的传播情况,分析用户行为因素之间的关系,提出了通过预测用户传播信息能力大小来分析和度量用户社会影响力的方法(该方法结合来自社交网络结构和用户行为因素两方面的信息进行研究),实验结果表明用户访问微博的时间分布、微博对用户来说的时效性以及用户转发微博的偏好等用户行为相关的因素会影响用户的转发行为,进而影响用户在微博平台上传播信息的能力[10];基于社会影响理论探讨了社会影响力的3个过程(顺从、认同和内化)和社会影响类型(信息性影响和规范性影响),结果表明服务提供商对这3个因素的处理情况和用户隐私保护问题对OSN用户持续使用意愿有显著的影响作用[11].
目前相关研究主要从用户在整个社交网络中的影响力和社交网络中用户间相互影响的能力2个方面来度量用户的影响力,可以从3个方面进行阐述:
(1)基于社交网络拓扑结构的度量. 主要采用节点度量法和节点间关系的度量法. 在节点度量法中,节点的度在一定程度上可以表示节点的影响力大小,它们的方向可以表示用户影响力或者信息传播的方向[12]. 节点的出度可以理解为该节点对他人的影响程度或节点的活跃度,节点的入度则可以表示节点的受欢迎程度[13].具体度量方法主要包括度中心度[14]、介数中心度[14]、紧密中心度[15]、特征向量中心度[16]、Katz中心度[17]、PageRank度量[18]及局部聚集系数度量方法[19]等. 节点间关系强弱的度量方法可以用Jaccard相似度[20]、边介数[21]、Overlap相似度和Cosine相似度等计算连接关系上的影响力[22]. 总体来讲,依靠网络拓扑结构对用户影响力进行度量的方法具有模型简单、计算效率高和易于应用等特点,但其忽略了个体的行为特征信息及个体间交互的频度情况,导致这种方法的度量结果准确性不佳.
(2) 基于用户行为的度量. 通过分析在线社交用户的行为轨迹数据(包括浏览/发布/转发信息、购买商品、话题评论和建立好友关系等),能够评估用户在社交网络平台上的影响力以及预测用户可能产生的行为. XIANG等[23]在Facebook和LinkedIn数据集上利用用户之间的交互信息和话题相似性,提出了潜在变分模型来评估用户之间的影响强度. SAITO等[24]将用户影响力模型转化成一种最大似然问题,并且利用期望最大化[25](Expectation Maximization,EM)算法进行求解[12]. YANG和LESKOVEC[26]基于影响力函数和信息的谈论次数建立了一种线性影响力模型LIM(Linear Influence Model)对用户的影响力进行度量. TAN等[27]综合使用网络拓扑结构、用户特征和用户行为数据预测当前时刻的用户行为. 虽然基于用户行为的方法比基于网络拓扑结构方法预测精度更好,但是由于一半以上的社交网络用户选择了隐藏个人的用户信息[2]以及基于商业上的原因很难获取社交网络用户的全部数据,导致这种模型的度量效果和精度受到影响.
(3)基于话题等的度量. 在社交活动中,大部分信息是以话题(Topic)的形式产生和传播的. 话题作为社交网络中信息存在的重要形式和传播基础,使用话题能够从多个角度对用户的影响力进行度量. 相关研究从话题内容和用户对话题的参与度构建用户和话题之间的关系. 这种模型无需使用社交网络拓扑结构作为模型的输入,解决了社交网络中孤立用户节点的影响力评价问题. 相关研究方法包括:TANG等[28]提出的话题因子图TFG(Topical Factor Graph)模型;LIU等[29]将用户和各种话题信息相结合进行建模,并利用文本内容的相似性挖掘用户之间的隐性影响;WENG等[18]提出PageRank算法的扩展算法TwitterRank,并基于用户和链接结构两部分信息去评估Twitter用户的影响力;TANG等[30]利用PageRank算法对网络用户进行打分,并将分值最高的1%的用户作为最具影响力的用户.
随着社交网络的快速发展,社交用户数量呈现快速增长的态势,导致用户之间形成的社交关系错综复杂、信息量非常庞大,加之涉及用户隐私保护等问题,对社交用户影响力进行分析和评测会受到很多因素的影响和干扰. 实际上,对于真实社交网络可以考虑采用两阶段选择策略,即先利用基于网络拓扑结构的算法筛选符合条件的影响力用户集合,在此基础上再利用基于用户行为数据或者基于话题等方法选取真正具有影响力的社交网络用户.
1.2 用户偏好分析
用户偏好分析可以从计算用户与用户之间、用户与物品之间的相似性来考虑. 皮尔逊相关系数[31]、余弦相似度[32]、Jaccard系数[20]和斯皮尔曼排序相关系数[33]等方法可以用于计算用户间的相似性并将最近邻用户的偏好作为目标用户的行为预测结果. 通过在线社交网络平台用户间交换的文本信息,文献[34]提出B-LDA模型以深入挖掘用户兴趣和行为模式. B-LDA模型基于LDA(Latent Dirichlet Allocation)行为主题模型、联合模型用户主题兴趣和行为模式,在拥有丰富用户交互短文本内容的微博Twitter上的实验结果表明,B-LDA能够找到主导行为的主题以及描述行为驱动的追随者用户. 文献[35]基于改进的LDA模型研究了不同年龄段的用户与话题偏好之间的关系,发现了很多有意思的不同年龄阶段特定的话题,并据此预测社交网络用户的年龄. 文献[36]基于用户日常移动通信模式发现几个有趣的社交现象,如:年轻人更积极扩展自己的社交圈、女性比男性更注重跨代间的沟通交流,并首次发现在人的一生中同性三元模式更持久,而更复杂的异性三元模式仅在年轻人中有所体现. 并通过提取用户的个人特征,朋友特征和用户的朋友圈特征推断用户的年龄和性别. 文献[37]通过构造主题模型与语言模型相结合的双层模型,利用朋友关系与组织关系解决微博的个性化搜索问题. 文献[38]提出一种针对社交网络用户生成内容和用户关注信息的用户偏好挖掘方法:首先通过概率潜在语义模型PLSA训练得到贴近兴趣类别的话题模型,然后从训练结果中抽取可靠的话题并以此构建分类器,对用户的分享数据进行分类,并根据分类结果对用户的偏好进行分析. 现实生活中,兴趣相投的人们之间的交流更加密切,在社交网络中,这种密切的社交关系会体现在网络的拓扑结构上. 文献[39-41]单纯使用社交网络的拓扑结构信息挖掘社交用户的朋友圈(社区)去预测用户的偏好,取得了一定的效果. 另外,DEERWESTER等[42]利用潜在语义分析LSA(Latent Semantic Analysis)、HOFMANN[43]利用概率潜在语义分析PLSA(Probabilistic Latent Semantic Analysis)、BLEI等[44]提出LDA模型以及SAID等[45]针对用户冷启动问题将主题模型应用于标签系统中提出混合PLSA模型等研究方法去计算用户和资源之间的相似性,分析用户的偏好进而产生推荐目录. 目前,基于社交网络数据的用户偏好分析已经成为社交研究中的热点问题,其在电子商务、个性化产品推荐、舆情分析和预测等领域得到了广泛的应用.
2 用户属性预测
社交网络用户的属性信息能够为网络演化、用户群组划分、信息传播、内容分享及推荐系统等提供信息基础. 然而在许多真实的社交网络中,相当数量的社交网络用户只提供部分属性信息,或者故意隐藏自己的部分属性. 但是,基于社交网络现实应用需求,常常需要推测用户未知的信息. 通过直接或间接的方式获取用户已知属性、好友关系、群组关系和行为轨迹等数据来推测用户的未知信息(隐私数据). 实际上,在社交网络现实应用中,属性预测可以分为隐式方式和显式方式. 隐式属性预测指根据用户可能具有某种属性而提供精确的个性化服务,而显式属性预测则指直接通过某种方法预测用户可能具有的属性.
2.1 隐式属性预测
社交网络通常可以模型化为图结构G(V,E),其中V表示用户节点集合、E表示节点间的连接关系(边)的集合. 文献[39-40]对学术社交网络进行图结构的形式化描述,利用学术社交网络的拓扑结构信息及标签传播技术进行社区划分,认为具有相同标签的用户属于同一个社区. 这里的形式化标签指用户具有的属性信息,因此社区内用户具有相同属性(相似的兴趣). 据此对社区内的用户进行相关的推荐服务,并取得了较好的推荐效果. 此研究表面上看和研究用户属性预测不相关,但实际上推荐的动机是根据社区内用户具有相似属性(兴趣)的假设. 我们把这类研究称为隐式属性预测.
2.2 显式属性预测
本文提出的显式属性预测指直接挖掘用户属性的相关算法. 如文献[46]利用交友关系和可见的群关系等结构化数据来推测用户的属性,并指出了群组信息能够更高精度地发现用户的隐私属性,实验结果证明了交友关系和可见的群组关系包含了大量的用户潜在信息. 但在大部分社交网络中,除了结构化数据,每个用户还具有或多或少的属性数据,单纯利用网络拓扑结构信息往往不能满足社交网络用户的精确分析需求. 因此,文献[47]将用户的属性信息和网络拓扑结构信息进行结合,指出具有相同属性的用户更有可能成为朋友或者形成一个密集的社区团体,提出了一种基于用户已知属性的社区发现方法挖掘在线社交网络用户的潜在属性信息. 文献[48]利用朴素贝叶斯分类器推测社交网络用户属性,利用用户的节点信息和节点间的链接信息(好友关系)推测社交网络中用户的政治倾向. 该文指出同时利用用户属性信息和用户间的关系信息比单独使用属性信息具有更好的预见性. 文献[49]首次使用链接预测方法发现用户的属性信息,结果表明链接预测方法能够推断用户的未知属性.
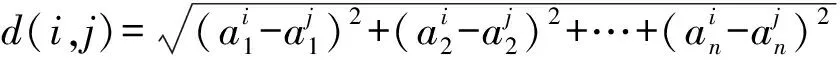
(1)

(2)
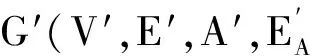

图1 属性-社交网络(SAN)示例图
(1)监督学习算法. 传统的社交用户属性预测采用监督学习算法.RAO等[54-55]提出了监督层次贝叶斯方法,从用户姓名和用户产生的文本内容数据中抽取特征数据进行用户潜在属性推测. 严格来讲,该研究属于文本分类问题,没有考虑社交网络的拓扑信息和社交关系信息.BACKSTROM和LESKOVEC[56]提出一种监督随机游走(SupervisedRandomWalk,SRW)算法,利用网络结构和边的属性信息进行链接预测. 但是这种方法没有充分利用节点的属性数据, 仅仅考虑相邻节点的信息,如果2个节点不相邻,则它们之间的属性信息无法被使用. 文献[57]采用几个主要的监督链接预测算法对SAN框架进行了扩展,指出预测用户的属性能够提高链路预测的准确性. 在SAN模型的属性预测监督算法中,属性预测被转换为属性链接预测问题. 算法通过为每一个正面的和反面的属性链接抽取一组拓扑特征. 而且,正面属性链接被作为正面的例子,反面属性链接被作为反面例子. 算法使用支持向量机SVM(SupportVectorMachine)训练一个二元分类器,并应用它推断属性链接. 但实际上,监督学习算法通常需要较多已知类别的标记样本,训练过程中不能有效利用大量未知类别标记数据改善训练效果. 对于用户属性数据不充分的社交网络,监督学习算法会受到一定程度的限制.
(2)无监督学习算法. 文献[58]把社交网络无监督链路预测算法粗略地划分为局部算法和全局度量算法. 局部算法包括CN(CommonNeighbor)[59]和AA(Adamic-Adar)[60]等. 其中,CN方法最直接的解释是把2个节点拥有共同邻居节点的数量定义为2个节点的链接预测评分:
score(u,v)=|Γ(u)∩Γ(v) |,
(3)
其中,Γ(u)表示节点u所有邻居节点的集合.
AA方法用于测量2个个人主页的相关程度,首先计算个人主页的特征进而以2个主页间的共同特征为基准进行计算,计算公式如下:

(4)
其中,z表示主页x、y的共同特征.
全局度量算法包括LRA(Low-rankApproximation)[61]和RWwR(RandomWalkwithRestart)[53]等.LRA度量方法采用邻接矩阵M表示一个图. 在M中,所有的链接预测方法都可以有一个等价的表示方式. 比如使用CN方法度量节点u、v之间链接预测的评分,并将评分结果作为邻接矩阵M相应行列的值.RWwR方法通过使用随机游走算法在增强社交图上预测2个节点间的链接相关性.
文献[57]在其基础上对代表性无监督链路预测算法进行了扩展,提出SAN框架下的局部算法、全局算法和局部全局混合算法. 在这些无监督SAN系列算法中仅仅使用正面的社交(属性)链接进行评分. 如,局部算法:CN-SAN算法和AA-SAN算法.CN-SAN算法使用节点u、v共同邻居的权重之和作为(u,v)之间社交链接或者属性链接的预测评分:
(5)
AA-SAN算法认为节点u、v的链接预测评分与它们共同邻居的权重之和成正比,而与它们共同邻居数的log函数成反比:

(6)
而对于其中的属性链接预测,则与节点间的链接预测方法类似:

(7)
其中Γ+(u)表示节点u所有邻居节点的集合,Γs+(u)表示所有通过社交链接(或正面属性链接)到节点u的邻居节点的集合.
SAN框架下的全局算法包括LRA-SAN算法和RWwR-SAN算法.LRA-SAN算法的相关评分计算采用奇异值矩阵分解方法(SingularValueDecomposition(SVD)). 在RWwR-SAN算法中,随机游走使用1个固定重启概率α返回节点u,从节点u重新启动并使用概率比例链接权重w(u,t) 迭代行走至节点t,节点t是节点u的邻居节点之一.SAN框架下的局部全局混合算法包括CN+LRA-SAN算法和AA+LRA-SAN算法,CN+LRA-SAN算法首先使用SAN模型的CN-SAN进行评分,然后在评分结果矩阵中使用LRA算法;AA+LRA-SAN算法则先使用模型AA-SAN进行评分,然后在评分结果矩阵中使用LRA算法.
由于用户隐私保护问题以及商业上的限制,很难获取社交网络用户非常丰富的属性特征,这为用户属性预测算法的研究带来了一定的影响和限制.
3 用户分类
社交用户属性预测问题实际上可以理解为是一个用户分类问题. OSN用户分类是一个有监督的机器学习问题,即需要首先确定用户的类别范围,然后通过训练分类模型预测用户的类别[62]. 在OSN中,用户通过维护个人Profile、社会化标签以及发布个人动态来积累文本内容数据. 此外,通过加好友操作可以扩大自己的关系网络. 文本内容以及关系网络信息都蕴含着用户的个性化特征,是进行用户分类的主要信息来源. 目前,有一些OSN用户分类方法基于文本内容信息,采用成熟的文本分类模型进行用户分类. 例如,ZUBIAGA等[63]通过采集用户的社会化标签数据,并应用支持向量机分类模型进行分类;RAO等[54]基于用户的Profile数据,利用改进的栈式支持向量机模型有效地对Twitter上的用户进行分类属性预测;PENNACCHIOTT等[64]则利用Latent Dirichlet Allocation (LDA)模型对Twitter用户的个人动态文本进行建模,并基于文本分类结果预测用户的分类属性. 与以上利用用户文本内容信息进行分类的方法不同,有一些综合利用文本内容和用户关系网络信息的分类方法则更多采用标签传播(Label Propagation)的思想进行用户类别标签预测,其基本原理是首先标注一定比例的用户类别标签,然后基于“OSN上2个互相连接的用户之间存在类别相似性”这种源于社会学的同质性原理(homophily)”进行类别标签传播,而这可以采用迭代推导算法(Iterative inference algorithm)框架实现. 例如,NEVILLE和JENSEN[65]、KAZIENKO和KAJDANOWICZ[66]、MACSKASSY和PROVOST[67]等均采用该框架学习用户的类别标签. 迭代推导涉及2个重要问题:用户类别标签初始化以及迭代收敛条件,其中类别标签初始化可以采用手工标注或者利用传统的文本分类模型确定,迭代推导可以在所有节点的类别标签分布都趋于稳定时收敛. 总的来说,综合利用用户文本内容以及关系网络信息进行分类的方法具有明显优势. 首先,只需要标注部分节点的类别标签就可以通过“同质性”原理预测其余节点的标签,这提高了用户分类的效率. 其次,一些没有文本内容信息或者关系网络信息的用户也可以通过本地文本分类模型或者标签传播获得分类标签,这提高了用户分类方法的鲁棒性. 此外,融合OSN用户文本内容以及关系网络信息进行分类的方法具有更好的分类精度. 例如,MLCMRW方法[68]、集体分类(Collective Classification)方法[69-70]均通过实验证明了综合利用2类信息可以显著提高分类精度.
由于OSN用户具有兴趣多样性特征,对其分类属于多标签分类问题,需要比传统的单一标签分类模型具有更复杂的性能评价准则,文献[69]提出了4种较为常用的多标签分类性能评价准则,包括Hamming loss、Subset 0/1 Loss、Micro F1和Macro-F1. 假设Dosn表示包含n个多标签节点(vi,yi)的OSN数据集,C(vi)表示使用某种分类方法对节点vi生成的预测标签集,各评价准则的定义如下.
(1)Hamming loss:Hamming loss是一种较频繁使用的分类评价准则,通过计算分类结果标签中没有被正确预测的数量来评价分类性能,计算公式如下:

(8)
(2)Subset0/1Loss:用于严格评价分类结果的预测标签集是否完全正确,计算公式如下:
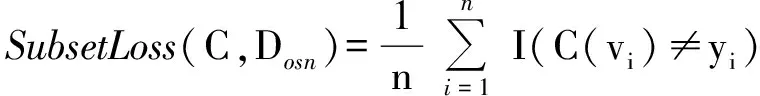
(9)
其中I(·)表示指示函数,当且仅当π成立时,I(π)=1,否则I(π)=0,该公式的计算结果越小则表示分类结果越好.
(3)MicroF1:通过综合考虑预测标签集预测精度和召全率的微平均来评估分类方法的性能,其计算结果越大则表示分类结果越好,计算公式如下:
micro-F1(C,Dosn)=

(10)
(4)Macro-F1:通过考虑在预测标签结果集上的F1 测度的平均值来评价分类器的性能,计算公式如下:
macro-F1(C,Dosn)=

(11)

4 存在的问题及挑战
随着以人为中心的在线社交网络的快速发展以及其对社会政治、经济等领域的重要作用,促使学术界和工业界广泛关注针对在线社交网络用户的分析和建模工作,并产生了大量的研究成果. 本文对社交网络用户的影响力分析、偏好研究、属性预测及用户分类等代表性研究话题涉及的理论和方法进行了简要分析. 虽然相关领域已经取得了丰硕的研究成果,但总体来说,在线社交网络用户分析的相关研究仍是一个充满问题与挑战的新兴研究领域. 随着社交网络的快速发展,需要处理的数据越来越庞大,社交用户的分析和挖掘工作将面临着新的问题和挑战. 我们认为可以深入研究并可能取得成果的方向主要包括以下3点.
(1)目前的算法都是基于静态社交网络的分析研究,而社交网络结构是无时无刻都在动态变化的,如何在动态变化的社交网络中进行分析挖掘并实时给出计算结果是需要解决的问题.
(2)面对快速发展的社交网络大数据,单机系统的性能受到考验,需要相关的并行算法对社交网络用户进行分析和挖掘.
(3)社交网络用户的信息数据通常存在模糊、歧义、二义性、信息不全等问题,需要综合利用自然语言处理技术、语义分析技术、机器学习和数据挖掘等进行综合分析和处理. 另外,对于真实在线社交网络,很难有事实上的评价标准. 因此,对这类算法优劣的客观评价存在一定的困难.
[1]TANGY.Scholar-centeredcomputing:researchandpractice[C]∥ProceedingsoftheInternationalConferenceonHumanCenteredComputing.Switzerland:Springer,2016:6-8.
[2] 丁宇新,肖骁,吴美晶,等. 基于半监督学习的社交网络用户属性预测[J]. 通信学报,2014,35(8):15-22.
DINGYX,XIAOX,WUMJ,etal.Predictingusers’profilesinsocialnetworkbasedonsemi-supervisedlearning[J].JournalonCommunications,2014,35(8):15-22. [3]GONZLEZ-BAILNS,BORGE-HOLTHOEFERJ,RIVEROA,etal.Thedynamicsofprotestrecruitmentthroughanonlinenetwork[J].ScientificReports,2011,1:Art197,7pp.
[4]TUMASJANA,SPRENGERTO,SANDNERPG,etal.Predictingelectionswithtwitter:what140charactersrevealaboutpoliticalsentiment[C]∥ProceedingsoftheFourthInternationalAAAIConferenceonWeblogsandSocialMedia.Washington:[s.n.],2010:178-185.
[5]VESPIGNANIA.Predictingthebehavioroftechno-socialsystems[J].Science,2009,325:425-428.
[6]ARALS,WALKERD.Identifyinginfluentialandsusceptiblemembersofsocialnetworks[J].Science,2012,337(6092):337-41.
[7]ACQUISTIA,BRANDIMARTEL,LOEWENSTEING.Privacyandhmanbehaviorintheageofinformation[J].Science,2015,347(6221):509-14.
[8] 杨善林,王佳佳,代宝,等. 在线社交网络用户行为研究现状与展望[J]. 中国科学院院刊,2015,30(2):200-215.YANGSL,WANGJJ,DAIB,etal.Stateoftheartinsocialnetworkuserbehaviorsanditsfuture[J].BulletinoftheChineseAcademyofSciences,2015,30(2):200-215. [9]TANGJ,CHANGY,LIUH.Miningsocialmediawithsocialtheories:asurvey[J].ACMSIGKDDExplorationsNewsletter,2014,15(2):20-29.
[10] 毛佳昕,刘奕群,张敏,等. 基于用户行为的微博用户社会影响力分析[J]. 计算机学报,2014,37(4):1-10.
MAOJX,LIUYQ,ZHANGM,etal.Socialinfluenceanalysisformicor-bloguserbasedonuserbehavior[J].ChineseJournalofComputers,2014,37(4):1-10.
[11]ZHOUT,LIH.UnderstandingmobileSNScontinuanceusageinChinafromtheperspectivesofsocialinfluenceandprivacyconcern[J].ComputersinHumanBehavior,2014,37:283-289.
[12]吴信东,李毅,李磊. 在线社交网络影响力分析[J]. 计算机学报,2014(4):735-752.
[13]WOLFEAW.Socialnetworkanalysis:methodsandapplications[J].ContemporarySociology,1994,91(435):219-220. [14]FREEMANLC.Centralityinsocialnetworksconceptualclarification[J].SocialNetworks,2012,1(3):215-239.
[15]SABIDUSSIG.Thecentralityindexofagraph[J].Psychometrika,1966,31(4):581-603.
[16]BONACICHP.Someuniquepropertiesofeigenvectorcentrality[J].SocialNetworks,2007,29(4):555-564.
[17]KATZL.Anewstatusindexderivedfromsociometricanalysis[J].Psychometrika,1953,18(1):39-43.
[18]WENGJ,LIMEP,JIANGJ,etal.TwitterRank:findingtopic-sensitiveinfluentialtwitterers[C]∥Proceedingsofthe3rdACMInternationalConferenceonWebSearchandDataMining.NewYork:ACM,2010:261-270.
[19]WATTSDJ,STROGATZSH.Collectivedynamicsof‘small-world’networks[J].Nature,1998:440-442.
[20]JACCARDP.Distributiondelaflorealpinedanslebassindesdransesetdansquelquesrégionsvoisines[J].BulletinDeLaSocieteVaudoiseDesSciencesNaturelles,1901,37(140):241-72.
[21]GIRVANM,NEWMANMEJ.Communitystructureinsocialandbiologicalnetworks[J].ProceedingsoftheNationalAcademyofSciences,2002,99(12):7821-7826.
[22]CRANDALLD,COSLEYD,HUTTENLOCHERD,etal.Feedbackeffectsbetweensimilarityandsocialinfluenceinonlinecommunities[C]∥Proceedingsofthe14thACMSIGKDDInternationalConferenceonKnowledgeDiscoveryandDataMining.NewYork:ACM,2008:160-168.
[23]XIANGR,NEVILLEJ,ROGATIM.Modelingrelationshipstrengthinonlinesocialnetworks[C]∥Proceedingofthe19thInternationalConferenceonWorldWideWeb(WWW2010).NewYork:ACM,2010:981-990.
[24]SAITOK,KIMURAM,OHARAK,etal.Selectinginformationdiffusionmodelsoversocialnetworksforbehavioralanalysis[J].JournaloftheOpticalSocietyofAmericaB,2010,20(1):91-96.
[25]MCLACHLANGJ,KRISHNANT.TheEMalgorithmandextensions:wileyseriesinprobabilityandstatistics[J].JournalofClassification,2007,15(1):154-156.
[26]YANGJ,LESKOVECJ.Modelinginformationdiffusioninimplicitnetworks[C]∥Proceedingsofthe2010IEEEInternationalConferenceonDataMining.Washington:IEEE,2010:599-608. [27]TANC,TANGJ,SUNJ,etal.Socialactiontrackingvianoisetoleranttime-varyingfactorgraphs[C]∥Proceedingsofthe16thACMSIGKDDInternationalConferenceonKnowledgeDiscoveryandDataMining.NewYork:ACM,2010:1049-1058.
[28]TANGJ,SUNJ,WANGC,etal.Socialinfluenceanalysisinlarge-scalenetworks[C]∥Proceedingsofthe15thACMSIGKDDInternationalConferenceonKnowledgeDiscoveryandDataMining.NewYork:ACM,2009:807-816.
[29]LIUL,TANGJ,HANJ,etal.Miningtopic-levelinfluenceinheterogeneousnetworks[C]∥Proceedingsofthe19thACMInternationalConferenceonInformationandKnowledgeManagement.NewYork:ACM,2010:199-208. [30]TANGJ,LOUT,KLEINBERGJ.Inferringsocialtiesacrossheterogenousnetworks[C]∥Proceedingsofthe5thACMInternationalConferenceonWebSearchandWebDataMining.NewYork:ACM,2012:743-752.
[31]RESNICKP,IACOVOUN,SUCHAKM,etal.GroupLens:anopenarchitectureforcollaborativefilteringofnetnews[C]∥ProceedingsoftheACMConferenceonComputerSupportedCooperativeWork.NewYork:ACM,1994:175-186.
[32]BREESEJS,HECKEMIAND,KADIEC.Empiricalanalysisofpredictivealgorithmsforcollaborativefiltering[C]∥Proceedingsofthe14thConferenceonUncertaintyinArtificialIntelligence.Madison:[s.n.],1998:43-52.
[33]HERLOCKERJL,KONSTANJA,BORCHERSA,etal.Analgorithmicframeworkforperformingcollaborativefiltering[C]∥Proceedingsofthe22ndAnnualInternationalACMSIGIRConferenceonResearchandDevelopmentinInformationRetrieval.NewYork:ACM,1999:230-237.
[34]QIUMH,ZHUFD,JIANGJ.Itisnotjustwhatwesay,buthowwesaythem:LDA-basedbehavior-topicmodel[C]∥Proceedingsofthe2013SIAMInternationalConferenceonDataMining.Texax:[s.n.],2013:794.
[35]LIAOL,JIANGJ,DINGY,etal.Lifetimelexicalvariationinsocialmedia[C]∥Proceedingsofthe28thAAAIConferenceonArtificialIntelligence.Québec:[s.n.],2014:1643-1649. [36]DONGY,YANGY,TANGJ,etal.Inferringuserdemographicsandsocialstrategiesinmobilesocialnetworks[C]∥Proceedingsofthe20thACMSIGKDDInternationalConferenceonKnowledgeDiscoveryandDataMining.NewYork:ACM,2014:15-24.
[37]VOSECKYJ,LEUNGWT,NGW.Collaborativepersonalizedtwittersearchwithtopic-languagemodels[C]∥Proceedingsofthe37thInternationalACMSIGIRConfe-renceonResearch&DevelopmentinInformationRetrie-val.NewYork:ACM,2014:53-62.
[38] 何炎祥,刘续乐,陈强,等. 社交网络用户兴趣挖掘研究[J]. 小型微型计算机系统,2014,35(11):2385-2389.
HEYX,LIUXL,CHENQ,etal.Userinterestminningresearchbasedonsocialnetworkservice[J].JournalofChineseComputerSystems,2014,35(11):2385-2389.
[39] 黄泳航,汤庸,李春英,等. 基于社区划分的学术论文推荐模型[J]. 计算机应用,2016,36(5):1279-1283;1289.
HUANGYH,TANGY,LICY,etal.Academicpaperrecommendationmodelbasedoncommunitypartition[J].JournalofComputerApplications,2016,36(5):1279-1283;1289.
[40]HUANGYH,TANGY,LICY,etal.Amethodforlatent-friendshiprecommendationbasedoncommunitydetectioninsocialnetwork[C]∥Proceedingin12thWebInformationSystemandApplicationConference.Washington:IEEE,2015:3-8.
[41]KIMHN,SADDIKAE.Exploringsocialtaggingforpersonalizedcommunityrecommendations[J].UserModelingandUser-AdaptedInteraction,2012,23(2/3):249-285.
[42]DEERWESTERS,DUMAISST,FURNASGW,etal.Indexingbylatentsemanticanalysis[J].JournaloftheAmericanSocietyforInformationScience,1990,41(6):391-407.
[43]HOFMANNT.Probabilisticlatentsemanticindexing[C]∥ProceedingoftheInternationalACMSIGIRConferenceonResearchandDevelopmentinInformationRetrieval.NewYork:ACM,1999:56-73.
[44]BLEIDM,NGAY,JORDANMI.Latentdirichletallocation[J].JournalofMachineLearningResearch,2003,3:993-1022.
[45]SAIDA,WETZKERR,UMBRATHW,etal.AhybridPLSAapproachforwarmercoldstartinfolksonomyrecommendation[C]∥ProceedingsoftheRecSys’09WorkshoponRecommenderSystems&theSocialWeb.NewYork:[s.n.],2009:87-90.
[46]ZHELEVAE,GETOORL.Tojoinornottojoin:theillusionofprivacyinsocialnetworkswithmixedpublicandprivateuserprofiles[C]∥Proceedingsofthe18thInternationalConferenceonWorldWideWeb.NewYork:ACM,2009:531-540.
[47]MISLOVEA,VISWANATHB,GUMMADIKP,etal.Youarewhoyouknow:inferringuserprofilesinonlinesocialnetworks[C]∥ProceedingsofthethirdACMinternationalconferenceonWebsearchanddatamining.NewYork:ACM,2010:4-6.
[48]HEATHERLYR,KANTARCIOGLUM,THURAISINGHAMB.Preventingprivateinformationinferenceattacksonsocialnetworks[J].IEEETransactionsonKnowledge&DataEngineering,2013,25(25):1849-1862.
[49]MILLERKT,GRIFFITHSTL,JORDANMI.Nonparametriclatentfeaturemodelsforlinkprediction[J].NeuralInformationProcessingSystems,2009:1276-1284.
[50]MOM,WANGD.Exploitofonlinesocialnetworkswithsemi-supervisedlearning[J].LectureNotesinComputerScience,2010,6443:1-8.
[51]DINGYX,YANSL,ZHANGYB,etal.Predictingtheattributesofsocialnetworkusersusingagraph-basedmachinelearningmethod[J].ComputerCommunications,2016,73:3-11.
[52]YINZ,GUPTAM,WENINGERT,etal.Linkrec:aunifiedframeworkforlinkrecommendationwithuserattributesandgraphstructure[C]∥ProceedingoftheInternationalConferenceonWorldWideWeb.NewYork:ACM,2010:1211-1212.
[53]YINZ,GUPTAM,WENINGERT,etal.Aunifiedframeworkforlinkrecommendationusingrandomwalks[C]∥Proceedingsofthe2010InternationalConferenceonAdvancesinSocialNetworksAnalysisandMining.Washington:IEEE,2010:152-159.
[54]RAOD,YAROWSKYD,SHREEVATSA,etal.Classifyinglatentuserattributesintwitter[C]∥Proceedingsofthe2ndInternationalWorkshoponSearchandMiningUser-GeneratedContents.NewYork:ACM,2010:37-44.
[55]RAOD,PAULM,FINKC,etal.Hierarchicalbayesianmodelsforlatentattributedetectioninsocialmedia[C]∥ProceedingsoftheFifthInternationalAAAIConferenceonWeblogsandSocialMedia.California:theAAAIPress,2011:598-601.
[56]BACKSTROML,LESKOVECJ.Supervisedrandomwalks:predictingandrecommendinglinksinsocialnetworks[C]∥ProceedingsoftheACMInternationalConferenceonWebSearch&DataMining.NewYork:ACM,2010:635-644. [57]GONGNZ,TALWALKARA,MACKEYL,etal.Jointlypredictinglinksandinferringattributesusingasocial-attributenetwork[J].ACMTransactionsonIntelligentSystemsandTechnology,2014,5(2):1-20.
[58]LIBEN-NOWELLD,KLEINBERGJ.Thelinkpredictionproblemforsocialnetworks[J].JournaloftheAmericanSocietyforInformationScience&Technology,2010,58(7):1019-1031. [59]NEWMANMEJ.Clusteringandpreferentialattachmentingrowingnetworks[J].PhysicalReviewE,2001,64(2):025102.
[60]ADAMICLA,ADARE.FriendsandneighborsontheWeb[J].SocialNetworks,2003,25(3):211-230.
[61]MARKOVSKYI.Structuredlow-rankapproximationanditsapplications[J].Automatica,2008,44(4):891-909.
[62] 贺超波,汤庸,麦辉强,等. 在线社交网络挖掘综述[J]. 武汉大学学报(理学版),2014,60(3):189-200.
HECB,TANGY,MAIHQ,etal.Asurveyononlinesocialnetworkmining[J].JournalofWuhanUniversity(NaturalScienceEdition),2014,60(3):189-200.
[63]ZUBIAGAA,KÖRNERC,STROHMAIERM.Tagsvsshelves:fromsocialtaggingtosocialclassification[C]∥Proceedingsofthe22ndACMConferenceonHypertextandHypermedia.NewYork:ACM,2011:93-102.
[64]PENNACCHIOTTIM,POPESCUAM.Amachinelearningapproachtotwitteruserclassification[C]∥Proceedingsofthe5thInternationalAAAIConferenceonWeblogsandSocialMedia.California:AAAIPress,2011:281-288. [65]NEVILLEJ,JENSEND.Iterativeclassificationinrelationaldata[C]∥ProceedingoftheAAAI2000WorkshoponStatisticalRelationalLearningoftheNationalConferenceonArtificialIntelligence.Washington:[s.n.],2000:42-49.
[66]KAZIENKOP,KAJDANOWICZT.Label-dependentnodeclassificationinthenetwork[J].Neurocomputing,2012,75(1):199-209.
[67]MACSKASSYSA,PROVOSTFJ.Asimplerelationalclassifier[C]∥ProceedingsoftheSIGKDD2002WorkshoponMulti-RelationalDataMining.California:ACM,2003:64-76.
[68] 贺超波,杨镇雄,洪少文,等. 应用随机游走的社交网络用户分类方法[J]. 计算机科学,2015,42(2):198-203.
HECB,YANGZX,HONGSW,etal.Userclassificationmethodinonlinesocialnetworkusingrandomwalks[J].ComputerScience,2015,42(2):197-203.
[69]KONGX,SHIX,YUPS.Multi-labelcollectiveclassification[C]∥ProceedingsoftheEleventhSIAMInternationalConferenceonDataMining.Arizona:OmniPress,2011:618-629.
[70]SHIX,LIY,YUP.Collectivepredictionwithlatentgraphs[C]∥Proceedingsofthe20thACMInternationalConferenceonInformationandknowledgeManagement.NewYork:ACM,2011:1127-1136.
【中文责编:庄晓琼 英文责编:肖菁】
A Survey of Online Social Network Based Users Analysis
LI Chunying1,2, TANG Yong1*, HE Chaobo3, TANG Zhikang4, HUANG Yonghang1
(1. School of Computer Science, South China Normal University, Guangzhou 510631, China; 2. Computer Network Center, Guangdong Polytechnic Normal University, Guangzhou 510665, China; 3. School of Information Science and Technology, Zhongkai University of Agriculture and Engineering, Guangzhou 510225, China; 4. School of Computer Science, Guangdong Polytechnic Normal University, Guangzhou 510665, China)
The latest development of online social network user analysis based on the related domestic and foreign research is reviewed,including user behavior analysis by user influence and user p
, user attribute prediction algorithm using implicit and explicit classification methods. The research progress of user classification based on user attributes or (and) user relationship topology is briefly described.Finally,the opportunities and challenges brought by the dynamic social network, parallel algorithms and social user semantic information to online social network users are analyzed,and the development trend of online social network user analysis is proposed.
online social network; behavior analysis; influence analysis; preference analysis; attribute forecast; users catalog
2016-07-07 《华南师范大学学报(自然科学版)》网址:http://journal.scnu.edu.cn/n
国家自然科学基金项目(61272067,61502180);广东省重大科技专项项目(2014B010116002);广东省自然科学基金项目(2014A030310238);广东省科技计划项目(2015B010109003,2015A020209178,2016A030303058)
TP391
A
1000-5463(2016)05-0107-09
*通讯作者:汤庸,教授,Email:YTANG@m.scnu.edu.cn.
猜你喜欢
意林彩版(2022年2期)2022-05-03
好日子(2021年8期)2021-11-04
数学小灵通(1-2年级)(2021年4期)2021-06-09
第一财经(2020年4期)2020-04-14
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
文苑(2018年17期)2018-11-09
NBA特刊(2018年14期)2018-08-13
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
人大建设(2017年11期)2017-04-20
