
基于拉普拉斯矩阵的K-mean聚类
2017-09-22 04:54潘正高路红梅李雪竹
绥化学院学报 2017年9期
王 超 潘正高 路红梅 李雪竹
(宿州学院信息工程学院 安徽宿州 234000)
基于拉普拉斯矩阵的K-mean聚类
王 超 潘正高 路红梅 李雪竹
(宿州学院信息工程学院 安徽宿州 234000)
谱聚类的方法被广泛用在模式识别各个领域。文章运用K-mean聚类方法,主要阐述了如何由样本的相似度矩阵构造的拉普拉斯矩阵来求解样本的低维映射谱,根据低维映射谱进行谱聚类。
拉普拉斯矩阵;谱聚类;K-means
样本聚类是无监督学习的一种重要分类方法。对于无标签的样本,要实现分类只能根据样本本身的相似度进行分类,度量样本相似度就是相似度聚类[1]。传统聚类方法要知道样本在N维空间的矢量[2]。但是拉普拉斯谱聚类的方法只需要知道样本的相似度矩阵就能进行聚类。
一、图谱理论到拉普拉斯矩阵
拉普拉斯矩阵式表示图的一种矩阵,给定一个n个顶点的图,则拉普拉斯矩阵被定义为:L=D-W
其中D为图的度矩阵,W为图的邻接矩阵。
举个例子,给定一个简单图,如下:

图1 一个邻接图
把该图转化成邻接矩阵的形式记为W则:
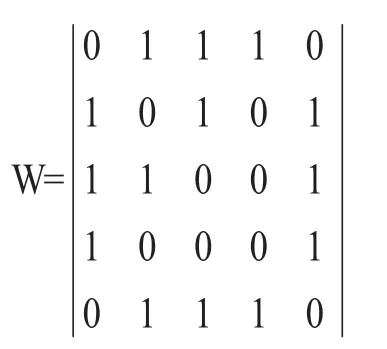
把W的每一列元素加起来得到n个数,然后把这个数放在对角线上其余位置都是零,组成一个n×n的对角矩阵,记为度矩阵D,如下所示:

根据拉普拉斯定义L=D-W可得拉普拉斯矩阵如下所示:
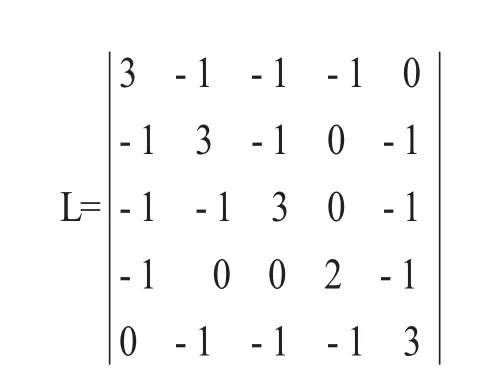
通过上面这个简单例子,我们明白了拉普拉斯矩阵在连接图上的定义。下面我们对于更一般的情况的数学描述如下:对于一个图中定义A子图和B子图[3],它们之间的所有边的权值之和可以由邻接矩阵W的一般形式求解如下:

其中,Wij定义为节点i到节点j的权值,如果两个节点不相连,则权值为零。与某个节点i邻接的所有边的权值之和定义为该顶点i的度di,多个di形成一个度矩阵D。
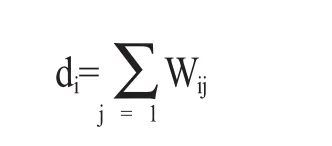
由以上定义可知拉普拉斯矩阵的性质如下:
(1)L是对称半正定矩阵;
(2)L·1=0·1,即L的最小特征值是0,相应的特征向量是1;
(3)L有n个非负特征值0=λ1≤λ2≤…λn;
(4)对于任何一个实向量υєRn,有以下表达式成立:
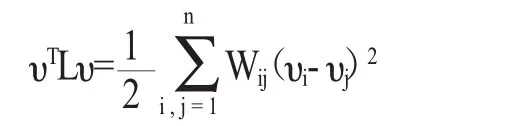
对性质(4)的证明如下:

二、聚类的图谱解释
聚类是把一堆样本合理地分成两份或份。从图论的角度看,聚类问题就是图的分割问题[4]。给定一个图G=(V,M),顶点集表示各样本,带权的边表示各样本之间的相似度,谱聚类的目的是要找到一种合理的分割图的方法,把图分割为若干个子图,使得连接不同子图的边的权重或者相似度尽可能的低,同一子图内边的权重或者相似度尽可能高。相似的聚集在一起,不相似的彼此远离。为了达到这样一个目的,就需要被切割的这些边的权值之和最小[5]。
假设图不相交的子图分别为A1,A2,…,AK,求其代价最小的分割的目标函数如下:
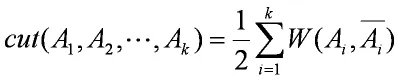
其中k表示分成了k个组,Ai表示第i组,Ai表示Ai的补集表示Ai,与Ai相连的所有边之和。综合上式就表示所有要切割的边的权重之和。就是分割成个组要使得上式取最小值。这个目标函数在实际的操作中,常常把图分割为一个点和其余n-1各点。为了让每个图都有合适的大小,上述的目标函数改写成如下式子:


下面对这个目标函数进行推导:

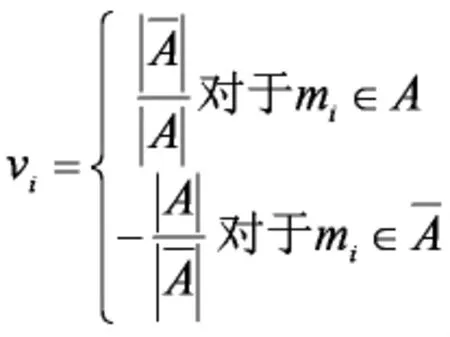
则上式可以化为:

我们从RatioCut推导出了vTLv,这也就是说拉普拉斯矩阵L和我们要优化的目标函数RatioCut有密切的联系。因为是一个常量。最小化RatioCut,也就是最小化vTLv。
又因为:
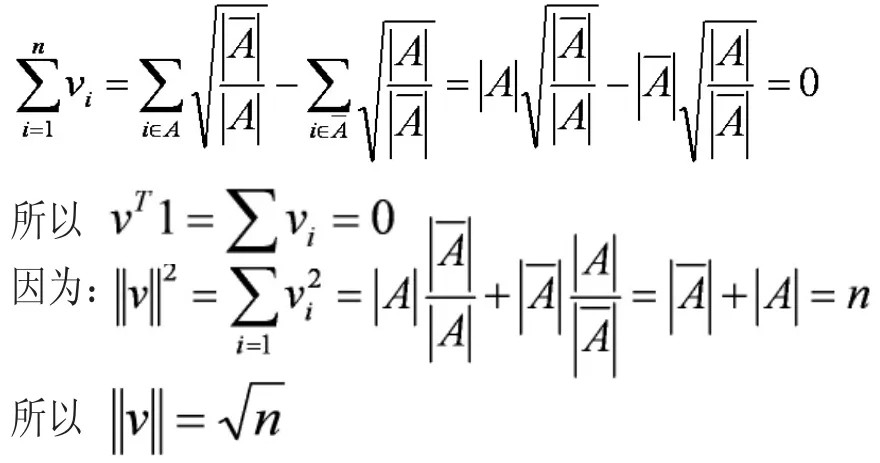
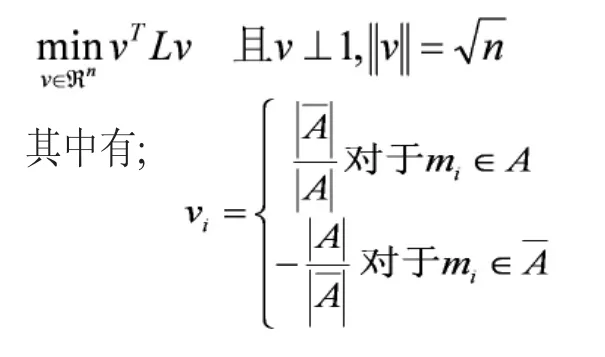
显然上式n是一个定值,要最小化vTLv也就是最小化λ。因此我们下面只有找到拉普拉斯矩阵L最小特征值是零,对应的特征向量就行了。这里有一个问题,就是我们讨论过的拉普拉斯矩阵最小特征值是零,对应的特征向量是1。不满足v⊥1的条件了,这里根据文献[2]所说理论。我们取第2小特征值对应特征向量。进一步,由于实际中的特征向量里的元素是连续的任意实数,所以可以根据v是大于0还是小于0对应到离散情况下的,决定vi是取还是取。而如果能求取v的前K个特征向量,进行K-means聚类,得到K个簇,便从二聚类扩展到了K聚类问题。而这里要求的K个特征向量就是拉普拉斯矩阵的特征向量。所以问题就转换成了:求取拉普拉斯矩阵的前K特征值对应的特征向量,然后用这前K个特征值对应的特征向量进行K-means聚类。
三、K-means聚类
(一)随机在图中取K个点作为中心点。
(二)然后计算图中所有点到K个中心点距离,假如P点离中心点S点最近,那么P点属于S点群。
(三)分完群计算点群中心,用新的中心点作为点群中心点。
(四)重复步骤(2)和(3),直到中心点不再移动,聚类完毕。
四、结语
基于拉普拉斯矩阵的K-means聚类,一般步骤如下:
(一)根据数据构造一个图,图中每一个节点对应一个数据点,将各个数据点连接起来,并且边的权重表示数据的相似度。把这个图用邻接矩阵W表示出来。
(二)把邻接矩阵每一列元素加起来得到n个数,把它们放在对角线上,其他地方补零构成一个的对角阵,记为度矩阵D,并构造拉普拉斯矩阵L且L=D-W。
(三)求出拉普拉斯矩阵的前K个特征值对应的特征向量,特征值由小到大顺序排列的。
(四)把这些特征向量(列向量)排列在一起组成一个nx·k的矩阵,将其中每一行看做k维空间的一个向量,并使用K-means算法进行聚类。聚类结果每一行所属类别就是图中节点也就是n个数据点分别所属类别。
谱聚类算法和传统聚类方法相比,谱聚类只需要数据之间的相似度矩阵就可以了,而不必想单纯K-means聚类需要数据在N维欧式空间中的向量。
[1]H.Zha,C.Ding,M.Gu,X.He,and H.D.Simon.Spectral relaxationfor K-meansclustering[C].AdvancesinNeuralInformation ProcessingSystems14,Vancouver,Canada.Dec.2001:1057-1064.
[2]Fouss,F.,Pirotte,A.,Renders,J.-M.,and Saerens,M.. Random-walk computation of similar-ities between nodes of a graph with application to collaborative recommendation[J].IEEE Trans.Knowl.DataEng.[J].2007,19(3):355-369.
[3]Kannan,R.,Vempala,S.,andVetta,A..Onclusterings:Good, badandspectral.JournaloftheACM[J].2004,51(3):497-515.
[4]Hagen,L.andKahng,A.Newspectralmethodsforratiocut partitioning and clustering.IEEE Trans.Computer-Aided Design [J].1992,11(9):1074-1085.
[5]Gutman,I.andXiao,W.Generalizedinverse of the Laplacian matrixandsomeap plications[J].Bulletindel’Academie Serbedes Sciencesatdes Arts(Cl.Math.Natur.),2004,129:15-23.
[责任编辑 郑丽娟]
TP391
A
2095-0438(2017)09-0153-03
2017-05-09
王超(1981-),男,安徽宿州人,宿州学院信息工程学院助教,硕士,研究方向:模式识别、人工智能、物联网、图像处理。
安徽省青年人才支持项目(gxfxzd2016256);安徽省科技厅科技攻关项目(1502052053)。
猜你喜欢
长春师范大学学报(2022年12期)2023-01-13
同济大学学报(自然科学版)(2019年2期)2019-04-02
电子科技大学学报(2016年2期)2016-08-31
网络空间安全(2016年3期)2016-06-15
现代计算机(2016年11期)2016-02-28
湖南师范大学自然科学学报(2014年3期)2014-09-07
中央民族大学学报(自然科学版)(2014年2期)2014-06-09
华东师范大学学报(自然科学版)(2014年1期)2014-04-16
郑州大学学报(理学版)(2014年3期)2014-03-01
上海理工大学学报(2012年5期)2012-03-20
