
面向户外增强现实的地理实体目标检测
2017-10-16 03:30乔延军饶锦蒙王骏星杜清运
地理信息世界 2017年5期
乔延军,饶锦蒙,王骏星,杜清运,任 福
(武汉大学 资源与环境科学学院,湖北 武汉 430079)
0 引 言
增强现实(Augmented Reality,AR)是一种借助虚拟现实技术来增加对现实世界认知的热门技术,它将各种电子计算机存储的虚拟信息叠加到现实世界中,这些虚拟信息主要是由绘制的虚拟物体、虚拟场景和提示信息组成。传统增强现实应用采用基于标志(Marker)的方法实现跟踪注册,使用场景局限于可控环境(如室内环境等),难以应用于户外大范围地理场景中。随着全球定位系统(Global Positioning System,GPS)、传感器技术和计算机视觉(Computer Vision,CV)技术的发展,针对户外场景的户外增强现实(Outdoor Augmented Reality,OAR)技术得到了长足的进步。早期的户外增强现实系统通过GPS定位和惯性、磁性传感器等辅助确定位置和姿态来实现户外场景中的跟踪注册[1-2],但受制于精度与误差,效果一般,并且功能有限。如今,更多的户外增强现实系统采用计算机视觉技术与传感器技术相结合的思想来实现混合跟踪注册,取得了不错的效果[3-4]。随着移动互联网的快速发展,户外增强现实系统有越来越多的使用场景,如社交、购物、娱乐等。典型的案例是2016年春节期间支付宝的“扫福”和QQ的“天降红包”活动。增强现实的关键点是设计跟踪注册算法[5],主要是采用混合跟踪注册算法,而基于视觉识别的算法是其核心,以提取特征点为核心的视觉识别算法存在计算量大且精度不高等问题,而以卷积神经网络为核心的图像识别算法能够较大地提高图像识别与目标检测的效率和精度[6]。
1 深度学习研究进展
在计算机视觉领域中,深度学习的工作应用领域有图像分类、目标识别、姿态估计、图像分割和人脸识别等,众多研究已经尝试设计深度学习模型(CNN模型)来实现图像识别与目标检测[7-8],并提高了计算机识别的精度和效率,优化的深度学习模型也越来越丰富。
卷积神经网络(Convolutional Neural Network,简称CNN)[9]是通过训练多层神经网络来识别输入为多维信号的信息,在图像分类、目标检测等机器学习难题中发挥着重要作用[10],本文尝试结合CNN模型来设计增强现实系统中视觉识别的算法。CNN是一个由多个神经元组成的感知机,不同网络间的局部连接和权值共享降低过拟合风险,并减少了权重的数量,降低了复杂度使得网络更容易优化[11],简化结构图如图1所示。

图1 CNN的简化结构Fig.1 A simplified structure of CNN
在2012年ImageNet,深度学习开始初露锋芒,AlexNet首次用于解决大规模图像分类问题,并比传统的提取特征点算法(如SIFT)降低了接近一半的错误率。在2013年ILSVRC,在AlexNet的基础上,引入反卷积网络,并可视化卷积层来获取特征,从而降低了错误率。在2014年ImageNet,GoogleNet模型基于Network in network 思想提出了Inception模型,用稠密组件替代最优局部稀疏结构,从而有效降维并降低过拟合的影响,其错误率降低到了最佳纪录的一半。2015年,一种改进激活函数的PReLU-Nets在ILSVRC数据集上做分类测试,top-5错误率降低到4.94%,首次超过人眼识别效果。在2015年ImageNet,一种基于深度残差的学习模型,通过加深结构(152层),达到更好的效果。在2016年ImageNet,多种模型在以往优秀模型的基础上进行了组合优化,并提升了各项评判指标,从而推进了深度学习思想的应用[12]。
随着深度学习思想的迅速发展,基于CNN的模型被用于解决图像中复杂的目标检测问题[12]。Ross Girshick等提出R-CNN深度学习模型,尝试利用CNN解决目标检测难题。微软亚洲研究院研究人员将SPPNet(空间金字塔网络)解决目标检测难题。Ross Girshick在R-CNN的最后一层网络优化,设计了Fast R-CNN模型,加入了Region of Interest(RoI)池化层。Ren Shaoqing等对候选区域做了进一步改进,提出了Faster R-CNN。YOLO(You Only Look Once)[13]和SSD(Single Shot Detector)[14]尝试用线性回归思想找到与图像中目标最为接近的预测框,并提高了计算速度,准确率也能够满足使用要求。
2 简化模型的设计与训练
Google Research收集与研究解决图像分类与目标检测问题的CNN模型[15],有Faster R-CNN、R-FCN、SSD、YOLO,并设计了多种使用场景,如车辆行驶,利用海量数据进行了实验,并且从效率、精度等上做了分析。实验结果表明,SSD模型效率比Faster R-CNN、R-FCN更高,精度相近,SSD模型与YOLO模型的效率相近,但精度更高。
本文所研究的对象主要是一些具有空间特征的地理实体,显著特点是目标大、结构棱角明显,SSD模型对于大目标有良好的识别效率和精确度,但原模型由于前置网络计算量较大,因此,在SSD模型的基础上做了简化,主要是前置网络更换为具有18层的残差网络(ResNet-18)、调整SSD网络结构与卷积层选择,最终针对每个输入图像生成3682个检测框(类别置信度和边框坐标)。具体地,我们将ResNet-18网络的全局平均池化层和全连接层去掉后,接入SSD网络结构中以替换其原本的VGG-16基础分类网络。ResNet-18网络中每一层的卷积滤波器数量都减少了一半,以达到降低计算量、加速计算的目的。我们从ResNet-18网络中选取Conv3_2、Conv4_2和Conv5_2卷积层中计算出的不同空间分辨率的特征映射(feature map),连同原有的SSD附加卷积层计算出的特征映射一并作为目标检测的特征输入,从而实现在单一图片上进行多尺度目标检测。受益于残差神经网络的特征提取能力,我们的简化版模型得以在网络参数极大减少的情况下仍能够实现高精度的识别与检测。同原版SSD模型相同,我们使用VOC2007和VOC2012的训练数据集进行训练,并在VOC2007的测试数据集上进行精度与速度评估。结果表明,我们的简化版模型在NVIDIA GTX750Ti GPU上能够达到33FPS的运行速度,远远快于原版模型,同时也能保持58.2% mAP(mean Average Precision)的高检测精确度。简化版模型结构如图2所示。
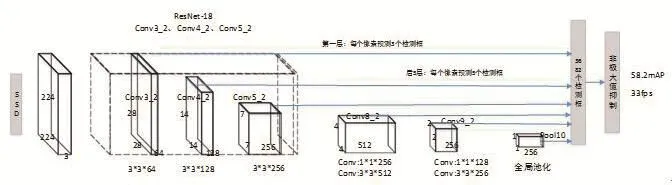
图2 简化的SSD结构Fig.2 The simplified structure of SSD
本文的数据集是参考了ImageNet与Pascal VOC 2007的数据集设计规则,建立了户外地理实体的数据集,分为6个类别:资源与环境科学学院大楼、3S雕像、教学实验大楼、校门牌坊、梅操舞台和樱顶老图书馆,设置对应的英文编码为SRES、3SM、TEB、GT、MCS、LIBO。数据采集在上午9-11点进行,天气状况良好。数据采集工作共由3人同时进行,使用手机从多个角度、距离来对上述6类目标进行拍摄,每类目标拍摄有约300张照片,共得到约1800张采样图片,采样图片样例如图3所示。图像采集完成后,经过数据预处理再对数据组织真实目标项信息获取目标类别与位置,并生成对应的xml文件。

图3 采集图像样例Fig.3 Samples of the collected images
我们结合第三方深度学习开源工具MXNET实现网络的构建,MXNET的核心代码由C++语言编写,并提供Python接口。系统核心代码有前置网络的构建、激活函数的构建、检测层实现、训练网络的构建、测试网络的构建等。利用MXNET提供的函数接口,我们得以快速实现网络中的大量卷积操作、Softmax分类函数、损失函数、ReLU激活函数等。先前获取的图片可以作为输入来训练网络,每迭代一次,网络越趋近于收敛,直到模型的精度不再变化,训练过程结束。
训练过程历时24个小时,共迭代500次,模型达到收敛。通过在测试图片上进行评估,我们发现模型达到了98%的mAP,在NVIDIA GTX750Ti GPU上处理一张图片的时间约为0.03s,模型的参数文件大小约为20MB。对训练后的模型进行识别的结果如图4所示,能获取到地理目标的边框、类别及置信度,置信度达到97%以上。本模型参数文件体积相对较小,再加上处理图片速度较快,可以移植到移动设备中实现轻量级近实时目标检测。

图4 测试图片及其检测结果Fig.4 The tested images and their corresponding detection results
3 移动端原型系统的设计与实现
针对户外地理实体,本文主要使用混合跟踪注册方法[16],利用安卓相机获取图像输入源,将SSD模型导入手机中用于目标检测,实时计算出边框和类别信息,实现视觉识别,利用Canvas 2D绘图绘制边框。3D增强信息为基于OpenGL ES开发的有纹理可旋转的3D图形,我们通过虚拟3D图形与视频流的叠加达到增强现实展示的效果[17]。
原型系统采用纯客户端的技术架构模式,SSD检测模型打包后存储在本地,所有地理目标的空间、属性信息以及增强信息存储在本地数据库Sqlite3中。原型系统主要包括4个模块,即图像处理、位置姿态计算、空间数据查询、增强信息[18-19]。图像处理模块包括获取图像、运行SSD模型、输出检测结果,位置姿态计算模块包括获取GPS和计算姿态,空间数据查询模块包括查询周边及计算方位,增强信息模块包括显示属性信息、显示虚拟物体信息及实现人机交互,如图5所示。

图5 原型系统总体设计Fig.5 The overall design of the prototype system
图像处理模块是整个原型系统的关键,功能主要是3个:获取图像、运行SSD模型、输出检测结果。过程如图6所示。利用安卓相机捕获场景图像,主要用于两部分,一是用于将此图像输出到组件上,二是作为SSD引擎的输入信息,检测完成后利用Canvas绘制2D图形显示检测信息。在3D模型的注册与显示过程中,我们将预先存储于手机端本地数据库的、基于OpenGL ES开发的有纹理可旋转的3D图形作为增强信息提取出来,通过建立OpenGL ES的XY坐标系与手机屏幕的UV坐标系之间的转换算法,依据检测框坐标来将其注册到OpenGL ES坐标系中,从而绘制出来,实现增强现实的展示效果。

图6 图像处理过程Fig.6 The procedure of image processing
本文的户外增强现实原型是在安卓平台下实现,基带版本是4.4.2,SDK为25版本,JDK为Java7版本,IDE是Android Studio,数据库为SQLite3。流程图如图7所示,从图像处理、获取手机信息、关联空间数据、信息增强4个过程逐步实现。

图7 原型系统流程图Fig.7 The prototype system process flow chart
4 移动端原型系统的展示
考虑到不同的光照条件对跟踪注册的影响,我们在一天内的不同时间段下做了测试,记录当前时间、检测出的类别及概率和检测所用时间等,统计见表1。我们设计了一个数据表来存储测试信息,每检测一次就存储测试信息,最后分时间段进行统计。

表1 测试结果统计表Tab.1 The statistics of the test results
记录信息统计后见表1,实验结果表明,在不同的时间段下,平均置信度在90%左右,平均检测时间在1.5s以内,简化后的SSD模型在移动端上的图像分类与目标检测置信度依然很高,速度也很快,光照条件对结果影响较小。系统运行的效果如图8、图9所示。

图8 多个目标的检测结果Fig.8 The detection results of multiple objects

图9 地理信息的叠加Fig.9 Superposition of geographic information
5 结束语
本文使用计算机视觉技术来对地理实体进行检测,将深度学习模型SSD应用在户外增强现实中的跟踪注册上,提出了一种不同于传统算法进行图像识别与目标检测的新思路。在安卓手机平台上,实现了户外移动增强现实原型系统,采用纯客户端模式,提高了实时性和准确性。相比于传统的图像识别与目标检测技术,我们采用的深度学习模型能够达到更高的识别与定位精度,在户外场景复杂的视觉光照条件下始终能够保持良好的鲁棒性,并且对网络依赖少;然而,由于深度学习模型计算量较大,手机端的计算能力往往不足,导致运行速度比较有限。因此,我们将在深度学习模型优化、目标检测算法与高速跟踪算法相结合等方向展开进一步的研究。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
文苑(2020年11期)2021-01-04
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
电子制作(2019年11期)2019-07-04
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
北京航空航天大学学报(2018年1期)2018-04-20
现代计算机(2016年12期)2016-02-28
中国卫生(2014年12期)2014-11-12
