
电商评论中细粒度主题情感混合模型建构
2018-01-10 12:28张帆
商业经济研究 2017年24期
张帆
内容摘要:本文对细粒度观点挖掘的相关理论做了深入探讨,详细研究了LDA模型,又对该模型加以改进,提出了细粒度主题情感混合模型,该模型能对实体提取、意见词识别、情感倾向分析、评论信息自动汇总分析、用户评价等提供评价分析,为用户提供直观的信息。
关键词:细粒度挖掘 电商评论 主题模型
研究的背景
用户网络购物时常常先查阅商品的评论信息,把消费者对产品或服务使用后的真实评价作为重要参考,商家也把评论作为反馈机制,自身产品与服务的不足之处可以从评论中得以发现,进而对产品进行改进或者对销售策略进行调整。
近几年来,网络购物深入到青年、中年、老年等各个人群,购物结束后人们也越来越习惯于对商品做出评论,如此网站中电商评论的信息巨增,对于一件商品其评论信息会达到几千甚至上万条。消费者和商家都不可能对评论信息逐条阅读,但仅看其中的一部分评论得到的结果却又很片面。因此,从大量的评论信息中帮助消费者或商家提取有价值的信息成为当前最为迫切的问题,传统的观点挖掘方法对整条评论或对句子的层次做情感分析,这种方法不能反映产品或服务某种属性的评价具体情况,只是对产品或服务的优劣情况做反馈。
针对电商评论的细粒度观点挖掘,采用建构细粒度主题情感混合模型的方法对某个方面进行的挖掘,一方面能够反映评论信息的整体评价,另一方面还可反馈用户对产品或服务每个方面的评价褒贬情况,从而对消费者和商家提供更重要的、有价值的信息。消费者所关心的产品的某个或某些方面的评价从中可以直接地了解,进而在综合考虑的基础上,制定和自身利益相符的决策。产品和服务在具体方面的优缺点商家也可以从中获得,在此基础上对产品进行进一步改进,形成更合理、更合适的营销方案。
细粒度观点挖掘理论与相关个性化技术
(一)观点挖掘的概念
观点挖掘涉及到实体和观点两种相关术语,下面分别对其进行定义和解释。
实体:实体通常由E(t,w)表示,E表示实体,T表示实体组件的层次结构,或子组件的层次结构,w表示实体E属性的集合。以华为P10手机为例,它是一个实体,电池、屏幕、充电器等是这个实体的组成部件,大小、机身内存等是手机的属性,每一个组成部件也有其自己的属性,比如屏幕的属性有可操作性、像素大小、屏幕大小等。其组成部分屏幕也有自己的属性如颜色、可操作性。
实体是一棵倒树型的层次结构。实体本身等同于树的根结点,实体的组成部分或子组成部分处于树的各个非根结点,每一个结点之间分别具有其联系的属性。
观点:五元组结构表示法(ej,ajk,soijkl,hi,tl)常常用来表示观点,其中每一个元素含义为:ej实体;aj实体的特征或方面;soijkl在特定的时间,观点持有者的情感评价;hi做评论的用户即观点持有者;tl表述观点的时间。这种五元组描述方法设计了一种框架,该框架能够把无结构的文本转化为结构化的数据,使用该框架可以完成对信息量众多的数据实现量化分析。
(二)相關个性化推荐技术
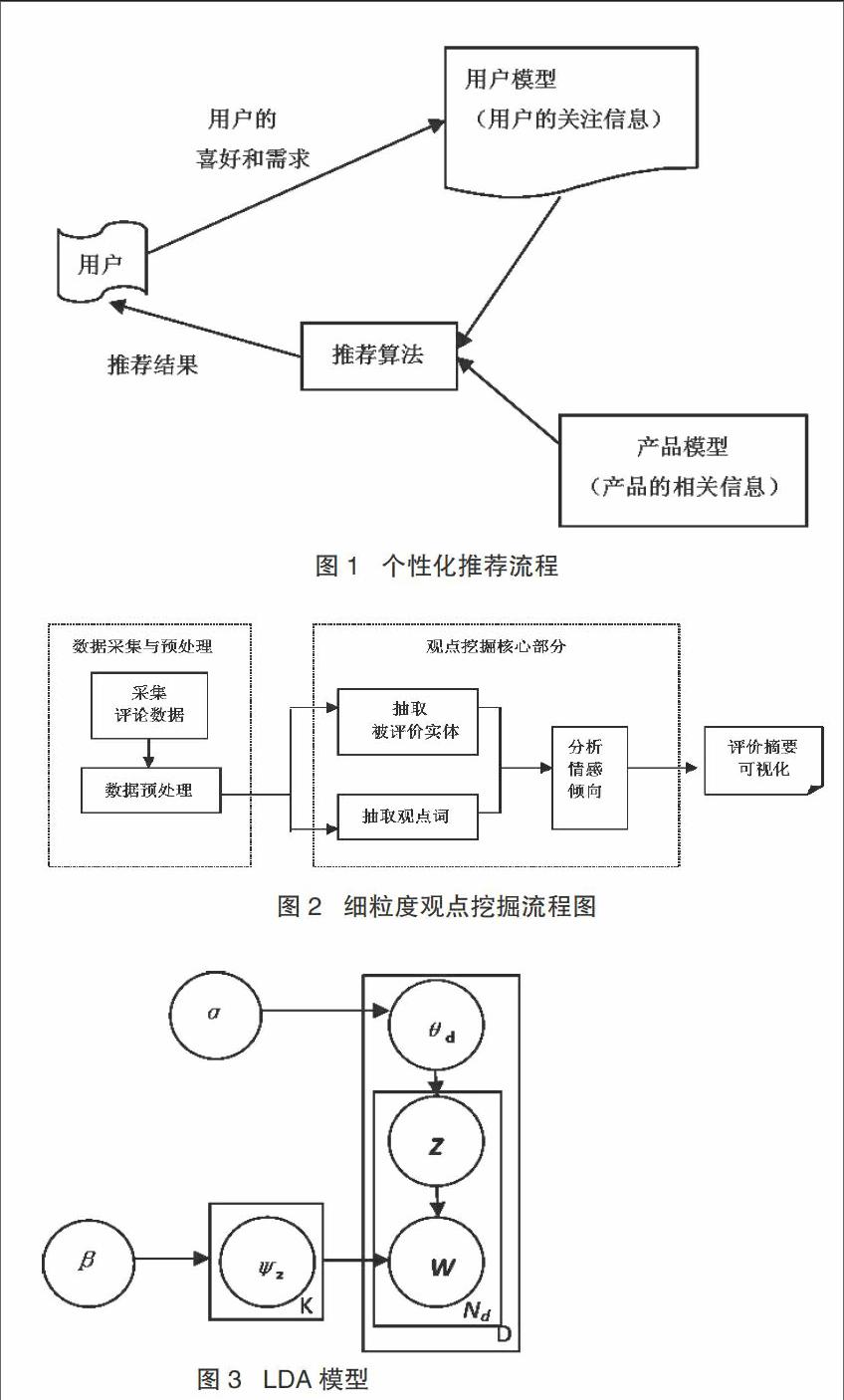
个性化推荐技术是在推荐技术基础上发展和改进的结果,是目前被用来解决评论信息量过大的有效处理办法。参考用户的爱好及用户日常的浏览足迹,个性化推荐系统综合考虑推荐对象的特点,将推荐对象列表以个性化的方式向用户推荐。个性化推荐如图1所示,其过程为:根据用户浏览历史,对用户的喜好、兴趣与需求做出判断;在众多的用户推荐对象信息中建设推荐对象模型;利用最佳推荐算法形成个性化推荐结果,并将推荐结果呈现给用户。
当前,在处理评论内容信息量过大过程中,个性化推荐技术作为最有效的技术手段被普遍应用。该技术手段多采用基于内容的推荐算法、协同过滤算法和混合推荐算法。基于内容的推荐算法。此算法可以在用户对推荐对象不做评价的情况下,能够抽取出推荐对象内容的特征,还能够依据用户确定的对象的内容特点取得用户的爱好,从而使用户获得与其爱好匹配率最高的对象。协同过滤推荐算法。此算法的推荐原则是:购物与生活习惯或喜好相近的用户所需要的信息也是相同的。该推荐方法以过滤和选择具有相似购物习惯的用户为目标,统计用户之间爱好的最大相似性。混合推荐。混合推荐算法综合应用了基于内容的推荐算法和协同过滤推荐算法。
现在所使用的个性化推荐方法源于基于推荐的方法,用户的评分信息评论被作为所使用的数据。由于用户有时不是完全用心地给商品做出评价与评分,所以个性化推荐方法得出的结果不是特别有用。
(三)细粒度观点挖掘
从研究对象层次方面划分,观点挖掘可分为三种层次类型,各类型及其研究层次如下:第一,把文档作为分析基础的挖掘即基于文档级的观点挖掘,在这种方法应用中整个评论信息在情感方面被分类处理。第二,基于句子级的观点挖掘,这种方法与文档级层面的区别是在于情感分类时基于评论信息中的句子级。不能获得具体的细节信息是第一、二种挖掘方法的相同点。第三,基于方面级的观点挖掘。前两种观点挖掘方法不能得到具体的细节信息,基于方面级的观点挖掘又称为细粒度观点挖掘,使用过程中评论中的被评价实体方面被这种方法细节化,实体所有方面的详细观点和情感倾向都能被分析得出。实现较深层次的任务是细粒度观点挖掘的一大优势,另一优点是向消费者或商家提供被评价实体与之相关的情感观点信息,细粒度观点挖掘获得的信息可以满足用户更高层次的需求。
(四)细粒度观点挖掘承担的主要任务
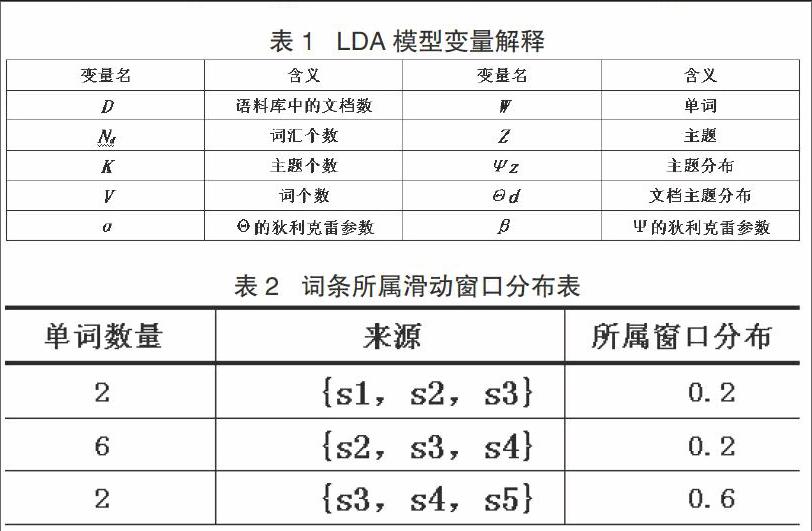
细粒度观点挖掘的目标定在被评价实体方面的抽取,抽取过程中注重情感分析,即从众多的评论中生成评价摘要。提取实体、提取意见词和分析情感倾向是细粒度意见挖掘的三个主要任务。图2展示了细粒度观点挖掘的流程。
挖掘过程为:采集电商网上消费者的评论数据→过滤无用数据(数据预处理)→删掉停用词等→转化数据,生成可识别的格式供算法使用→抽取被评价实体方面和观点词,在此基础上从情感倾向角度进行分析→生成评价摘要且评价摘要可视化。endprint
细粒度主题情感混合模型
(一)主题模型
文档中常常有一些隐含的主题,对于这些主题的建模采用主题模型的方法实现,每一个文档的生成模型称为主题模型。若干个词语组成了文档,文档的形成包括以下过程:词语确定主题;在这个主题中选择词语;不断重复前两步的选择过程,从而生成文档。
主题模型在上述选择主题或词的过程中均以采取相应的概率为前提,PLSA和LDA是电商评论中被普遍采用的两种主题模型,这两种模型在应用过程中的使用情况如下:PLSA模型容易出现过拟合,应在文档层和主题层之间增加概率模型;LDA模型在PLSA模型基础上做了改进,在文档和主题层之间设置了超参数,解决了PLSA模型过拟合现象。
(二)LDA模型
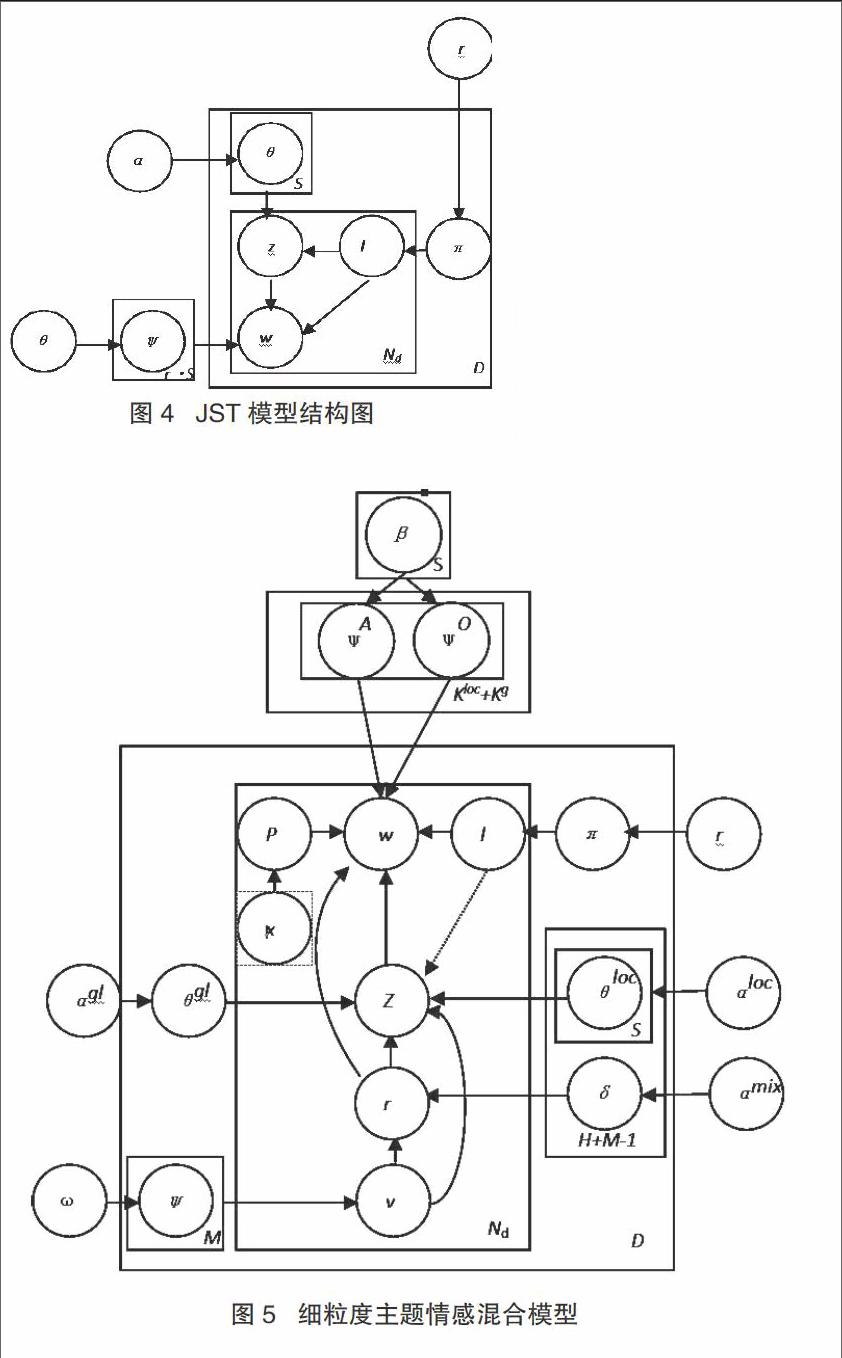
文本文档的LDA模型被认为是由多个主题组成的概率分布,如图3所示,它是由文档、主题和词组成的三层模型,每个主题的概率分布由多个词组成。图3中各变量的含义如表1所示。LDA模型先确定评论文档的主题分布,再选择一个主题,接着选择一个词语,从上一步骤生成的对应主题词条分布中进行选择,反复进行上述两个过程,完成文档的编辑后过程结束。
(三)细粒度观点挖掘主题模型设计
细粒度观点挖掘的实现目标有以下四个方面:在众多的评论信息中进行抽取,获得被评价实体方面和与其相对应的情感;生成评价摘要;为消费者和商家提供信息所需;为商家提供决策性支持。传统的LDA模型由于使用文档级的词共现信息识别主题,因此聚类得到的主题粒度较粗,不能对被评价实体方面进行识别,另外LDA模型把词和观点词集为一体,不能一目了然地呈现描述方面的词和观点词,情感也没有做建模处理,不能实现情感倾向分析。由于上述缺陷,对主题模型进行拓展和设计的重点应充分考虑被评价实体,应把评价实体方面的抽取做为改进工作的核心,兼顾考虑如何分离描述词和情感词。
细粒度观点挖掘主题模型拓展设计如下:第一,引入滑动窗口。一篇评论文档由若干个滑动窗口组成,使用拓展模型,对滑动窗口进行主题的抽取,局部主题被抽取后将几个句子组成一个滑动窗口,例:一篇评论有5个句子,滑动窗口大小为3,则将有7种窗口,分别是{s1}、{s1,s2}、{s1,s2,s3}、{s2,s3,s4}、{s3,s4,s5}、{s4,s5}、{s6}。如果句子s3有10个单词,各个词的来源窗口分布如表2所示。由表2可知,同一个句子不仅仅只包含在相同的窗口中,不同的滑动窗口也可以包括相同的句子,处理单个句子级别词共现缺乏时可以用这种方法。
第二,充分考虑用户的情感倾向。在细粒度观点挖掘中,不仅要识别被评价实体,还应了解用户的情感倾向,解决这一问题的方法是将情感层加在文档层与主题层之间,同时对主题和情感建模,从而实现对被评价实体方面的情感分析。增加情感层的主题模型相对于传统的方法而言,充分考虑了情感倾向,各种主题与情感中的词语分布情况都能够通过被分析而获得,情感所呈现出的正面与负面的情绪因素也可以被判断,这样便能够达到观点挖掘的目的。
第三,使用指示变量将情感与方面进行分离。分析结果中所有描述方面的词和表述情感方面的词构成了一个集合,称之为词聚类的集合,该集合作为主题模型的结果被输出。为了将其分离,将模型中的词进行分类,分为:方面词和观点词。描述被评价实体某一方面的词定义为方面词,例如手机的“电池”方面上有“待机时间、耗电”等词;观点词被用来描述或表达被评价实体方面,“高、低”、“长、短”都属于观点词,模型中通过两个增加变量可以将两方面的词分离,变量一决定词是否存在情感字典中,变量二代表词的类型。
(四)常用的情感主题混合模型
JST模型在LDA模型上进行进一步改进,增加了情感分析的功能,该模型的结构如图4所示。由图4JST模型结构图可以看出:JST模型中,每个词分别具有两个属性即主题和维度;JST模型为了实现情感分析的目标,在模型设计上充分顾及两种关系:一种是情感与主题的关系,一种是情感与文档的关系;每个情感的主题不是单一的,而是多个不相同的主题共存;情感维度决定了主题的生成;情感与主题两个方面的信息生成词。
(五)细粒度主题情感混合模型描述
细粒度主题情感混合模型如图5所示。模型在LDA模型基础上在以下几个方面有了创新:第一,融入了情感信息,增加了情感层,每一个情感标签用l表示,在模型中局部主题下两种类型词分布分别是ψ loc,AZ,l和ψ loc,OZ,l,它们分布在情感标签l。第二,模型引入了滑动窗口,注重词在文档中局部共现,过而识别细粒度的主题。第三,为了便于区分方面词和观点词,将两个变量p和x引入模型,其中p是詞类型变量,x是指示变量,这两个变量通过情感字典来构造,在整个过程中不必人工对其进行再标注。
参考文献:
1.[美]刘兵.情感分析:挖掘观点、情感和情绪.机械工业出版社,2017
2.老A电商学院.淘宝网店大数据营销:数据分析、挖掘、高效转化者.人民邮电出版社,2015
3.李进华.电子商务数据库基础与应用.首都经济贸易大学出版社,2010
4.杨伟强.电子商务数据分析:大数据营销、数据化运营、流量转化.人民邮电出版社,2016
5.张鑫,朱振中.在线评论有用性影响因素研究综述.商业经济研究,2017(6)endprint
