
基于聚类—因子分析的绿色经济发展评价指标体系构建
2018-01-10 13:21韩国莹李战江刘秀梅
商业经济研究 2017年24期
关键词:评价指标体系
韩国莹+李战江+刘秀梅

内容摘要:构建合理的绿色经济发展评价指标体系对评估各地绿色经济发展状况尤为重要。本文依据绿色经济发展内涵及其影响因素,通过对指标客观数据进行R聚类与因子分析,定量筛选指标,最终构建出绿色经济发展评价指标体系;实证结果表明所构建的评价指标体系涵盖了93.84%的海选指标信息。
关键词:绿色经济发展 评价指标体系 指标筛选 信息含量
全球经济飞速发展的今天,传统经济模式所带来的环境污染、资源浪费、效率低下等问题已不容忽视。“转型调结构”成为各国关注的热点,而发展绿色经济正是我们积极寻求的经济发展模式的新方向。建立恰当的绿色经济发展评价指标体系能够更加客观、科学地对我国各地区绿色经济发展水平进行评估,进而为合理规划各地绿色经济提供有价值的参考。
现有的国内外绿色经济评价指标体系中较为经典的有:经济合作与发展组织(OECD)构建的绿色增长指标体系、世界环境和发展委员会(WCED)建立的城市绿色发展评价指标体系、中国国际经济交流中心与世界自然基金会针对中国实际情况建立的中国省级绿色经济指标体系等。学术文献中常见的有:高春玲(2012)构建的湖北省绿色经济发展评价指标体系等。上述这些绿色经济评价指标体系一方面由于较为宏观不利于评价中的普适性,同时指标数据缺失情况较为突出,实际应用时难以进行定量测算;另一方面由于学术文獻缺少统一的限制条件,构建出的相关评价指标体系繁杂,反映同一信息的指标多有重复,操作难度较大,实际应用中存在诸多限制。
现有评价指标体系研究方法有:基于专家经验的主观筛选方法,如刘西明(2013)建立的包括人均废水废气排放量等指标的绿色经济测度指标体系等,但这种方法具有较强随意性和主观性,且没有考虑到指标间信息的重复性;基于定量测算的客观筛选方法,如郭玲玲等(2016)利用相关分析与变精度粗糙集结合的方法构建的绿色增长评价指标体系等,由于定量筛选是基于指标数据的客观特征,可能会因忽略指标的实际意义导致重要指标误删。
针对上述缺点,本文首先依据绿色经济发展内涵及指标数据的可观测性对指标进行海选与初选,再结合聚类与因子分析定量筛选指标构建出绿色经济发展评价指标体系。最后采用主成分-信息熵方法测算所构建的绿色经济发展评价指标体系的信息贡献,以证明构建指标体系的合理性。
绿色经济发展评价指标体系构建
指标海选与数据处理。以绿色经济发展现状为参考,以绿色经济内涵为基础,结合文献海选出具有代表性的能够反映绿色经济发展的各个方面的指标。同时针对数据的可获得性原则,剔除难以得到数据的指标。进行定量筛选指标过程中各指标量纲的差异会对最终绿色经济发展评价结果产生影响,需对评价指标的原始数据进行标准化处理。
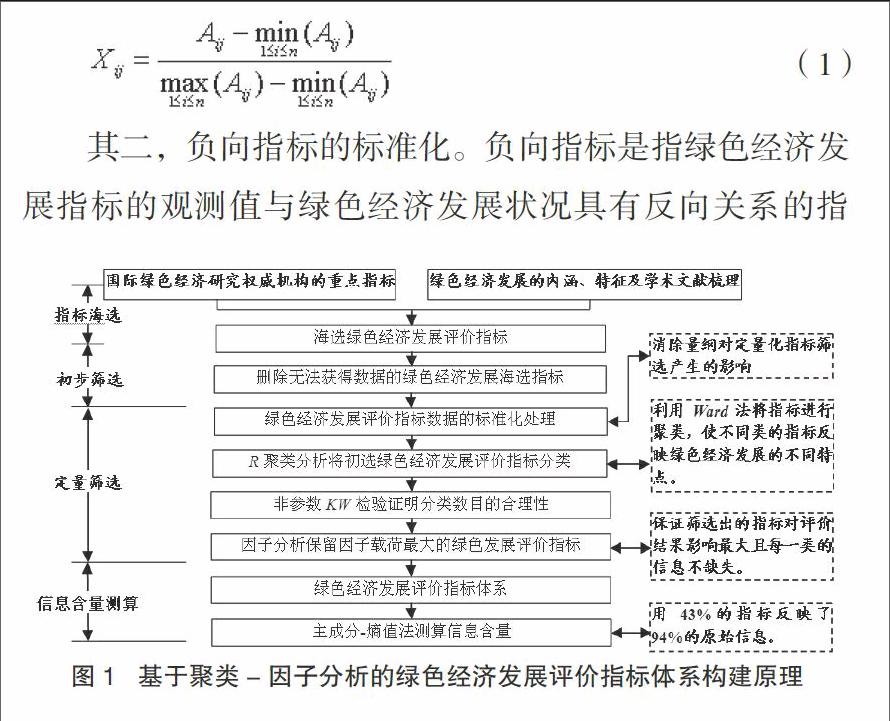
其一,正向指标的标准化。正向指标指数值越大说明绿色经济发展情况越好的指标。设:Xij为待判地区j对应绿色经济发展指标i标准化后的值;Aij为评价地区j对应指标i的观测值;n为绿色经济发展评价对象个数。正向绿色经济发展指标无量纲处理公式为:
其二,负向指标的标准化。负向指标是指绿色经济发展指标的观测值与绿色经济发展状况具有反向关系的指标。负向绿色经济发展指标无量纲处理公式为:
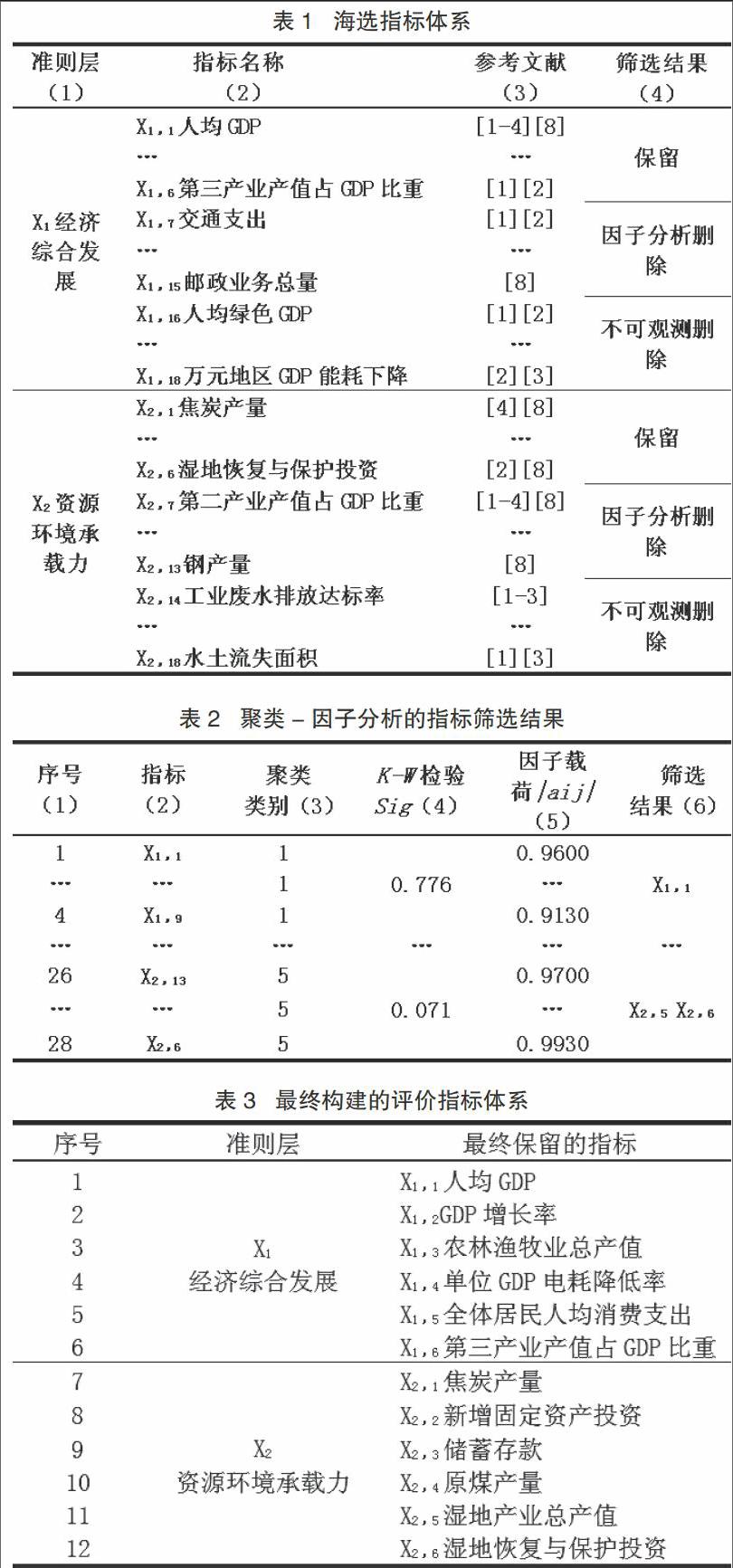
评价指标体系的构建原理。基于R聚类因子分析的绿色经济发展评价指标体系构建原理如图1所示。
绿色经济评价指标定量筛选的聚类分析
绿色经济发展指标聚类的目的在于,通过对初选后两个不同准则层的绿色经济发展指标分别进行R聚类,将反映相同或相近信息的绿色经济发展指标归为一类,保证所聚成的不同类别包含绿色经济发展不同方面的信息。
(一)聚类的一般原理及步骤
应用系统聚类中的Ward法对指标进行聚类,以同类指标的离差平方和较小、不同类间评价指标离差平方和较大为基础原理,所有类的总离差平方和最小为目标,确定聚类数目。具体步骤为:使n个绿色经济发展指标各自成一类;将n个评价指标两个离差平方和最小的先聚为一类,根据式(3)计算各类的离差平方和。设将n个绿色经济发展评价指标分为P类,Si为评价指标i的离差平方和(i=1,2,…,P),ni为第i类的评价指标个数,Xij为第i类中第j个标准化后绿色经济发展评价指标的样本值向量(j=1,2,…,ni),Xi为评价指标i的样本均值向量,第i类的离差平方和计算公式为:
每缩小一类,离差平方和就要增大,算出各合并方案的总离差平方和,按其最小原则进行聚类,则K类的总离差平方和S为:
重复上一步骤直到最终分类数目为P。
(二)聚类数目的合理性检验
检验目的。通过对R聚类后所聚各类的指标数据进行非参数K-W检验,以同类指标数据是否存在差异的概率P值是否大于0.05这一阈值为标准判断所聚数目是否合理,若不合理则需要重新聚类。
检验标准。非参数K-W检验的原假设为不同指标在数值上无显著差异。对各个类绿色经济发展评价指标分别做检验,若同一类指标数据的相似性检验显著性水平Sig>0.05,则接受原假设。即该类评价指标的数据相似性明显,表明聚类数目合理;否则就要拒绝原假设,表明聚类并不合理,需要对指标进行重新聚类直到所聚数目合理。
因子分析遴选信息含量最大的评价指标
(一)因子分析基本模型
因子分析的实质是将观测指标进行约减,即用少数具有实际意义的公因子的线性组合来表示。因子分析模型为:
筛选评价指标,公因子代表了评价指标的主要信息,因子载荷|aij|反映指标Xi与公因子的相关程度;|aij|越大该评价指标包含越多的信息,越应保留该指标。|aij|越小越表明该指标不具代表性,所含评价信息较少应该予以删除。因子分析主要是用少量具有代表性的指标最大限度地反映所构建评价指标体系的原始信息,用因子载荷最大标准筛出的指标符合其信息含量最大的要求。endprint
(三)主成分-信息熵法测算信息贡献
构建有效且能够应用于实际的评价指标体系是本文的核心目的。所构建的评价指标体系相对其海选指标体系的信息贡献,能够较为明确地说明构建的评价指标体系是否合理。计算步骤如下:
模型应用实证
评价指标的海选与初选。本文以内蒙古盟市作为实证对象,构建评价指标体系,研究内蒙古绿色经济发展的现状。本文数据均来自《内蒙古统计年鉴2015》,将数据不可观测的指标剔除,GDP增长率、第二和第三产业产值占GDP比重这三个重要指标可通过间接计算得到;部分指标数据缺失,本文采用中位数法补全。海选指标体系如表1所示。
绿色经济发展海选指标数据的标准化。本文绿色经济发展海选指标中只有“城镇失业率”为负向指标,其余均为正向指标。通过计算完成所需指標原始数据的无量纲化。
绿色经济发展评价指标的筛选过程。首先,对绿色经济发展指标进行R聚类。本文应用SPSS软件,选择Ward法分别对两个不同准则层中的绿色经济发展指标进行R聚类,聚类结果见表2所示。其次,对R聚类结果进行非参数K-W检验。分别对聚类结果中每一类的指标数值进行相似性检验,利用SPSS软件完成K-W检验过程,获得的检验结果见表2。K-W检验表明同一类的评价指标数值的相似显著性Sig都大于临界值0.05,表明同类评价指标无显著差别,R聚类结果是有效的。再次,分别对各类的评价指标进行因子分析。利用SPSS软件对每类指标进行因子分析,用最大方差法进行因子旋转得到因子载荷|aij|如表2。保留每类中|aij|最大的绿色经济指标,即完成对评价结果影响最显著指标的筛选。第四,评价指标筛选结果的信息贡献测算。应用SAS软件完成主成分分析,用主成分-熵法计算出绿色经济发展海选指标和筛选后指标的信息含量分别为2.422和2.273。将其代入式(11)得到信息贡献率r为0.9384。表明筛选出的绿色经济发展评价指标保留了93.84%的海选指标信息。最后,最终确定的绿色经济发展评价指标体系。通过对评价指标进行R聚类与因子分析最终确定了包含原煤产量、湿地产业总产值等12个重要指标的绿色经济发展评价指标体系,如表3所示。
参考文献:
1.OECD. Towards Green Growth: A Summary for Policy Makers [R]. 2011
2.World Commission on Environment and Development (WCED). The brundtland report,our common future [M]. Oxford: Oxford University Press,1987
3.WWF.China Ecological Footprint Report 2012: Consumption,Production and Sustainable Development [R]. 2012
4.高春玲.基于熵值法的湖北省绿色经济发展综合评价研究[J].科技管理研究,2012(19)
5.刘西明.绿色经济测度指标及发展对策[J].宏观经济管理,2013(2)
6.郭玲玲,卢晓丽,武春友.中国绿色增长评价指标体系构建研究[J].科研管理,2016(6)
7.迟国泰, 李战江.基于主成分-熵的评价指标体系信息贡献模型 [J].科研管理,2014(12)
8.内蒙古自治区统计局.内蒙古统计年鉴(2015)[M].中国统计出版社,2015endprint
猜你喜欢
都市家教·下半月(2016年11期)2016-12-29
吉林省教育学院学报(2016年8期)2016-12-26
商场现代化(2016年29期)2016-12-23
青春岁月(2016年20期)2016-12-21
职教论坛(2016年22期)2016-11-19
