
移动医疗中个性化l-多样性匿名隐私保护模型*
2018-05-09 08:50黄丽韶罗恩韬
计算机与生活 2018年5期
李 文,黄丽韶,罗恩韬,2+
1.湖南科技学院 电子与信息工程学院,湖南 永州 425199
2.中南大学 信息科学与工程学院,长沙 410083
1 引言
随着移动医疗技术的迅猛发展,医疗数据共享范围的逐步扩大,以及数据挖掘技术、深度学习技术的不断更新,医疗数据在不同医院之间的共享越来越方便。数据、信息的挖掘和共享也创造出巨大的经济价值和社会价值。但是,在数据发布和共享过程中存在一个不容忽视的问题,那就是医疗患者的隐私泄露。如果医疗机构在共享数据的时候没有充分考虑数据隐私问题,那么非法用户(攻击者)就可以利用其他机构发布的数据进行串联推测,甚至利用同一医院不同时段发布的数据漏洞获取到医疗患者隐私敏感信息,从而对患者隐私造成不可预测的泄漏风险。
以往医疗机构在共享或者发布医疗数据时,出于隐私保护的目的,会选择将一部分个人识别信息去除,如姓名、地址和电话等,然而攻击者仍然可以通过其他手段获得用户某些不敏感信息,利用这些信息与用户的疾病诊断数据进行对应,从而获得病人关于其所患疾病的隐私,这种攻击也称为链接攻击[1]。
表1是一张医疗数据表,医院在发布时并没有显式地给出病人的姓名。然而,假设攻击者在网络中得到表2所示的用户所辖区选民投票表,那么攻击者就可以通过将两张表的共同属性,例如邮编(430056),进行链接推导,从而推断出病人的姓名(Kevin)及所患疾病“过度肥胖”。如果不法攻击者将这些信息出卖给减肥中心,就直接导致病人(Kevin)的隐私信息泄露。
2 基于匿名原则的隐私保护
基于匿名原则的隐私保护,主要是在数据发布或者共享前,通过数据泛化、数据抑制[1-3]等技术手段对数据表中的相关属性进行处理,不发布或限制发布某些数据,从而让个人标识信息与敏感属性失去关联,达到隐私保护的目的[4-6]。

Table 1 Sheet of medical data表1 医疗数据表

Table 2 List of voter poll表2 选民投票表
2.1 k-匿名思想
在众多基于匿名原则的隐私保护方法中,k-匿名思想因其在保护隐私信息的同时也保证数据可用性,成为数据发布中进行隐私保护的重要技术手段[7-12]。其核心思想是通过概括和隐匿技术,发布精度较低的数据,使得每条记录至少与数据表中其他k-1条数据具有完全相同的准标识符属性值,从而减少链接攻击所导致的隐私泄漏。
定义1k-匿名(k-anonymity):给定数据表T{A1,A2,…,An},T的准标识符为QI,当且仅当T[QI]中每一个值序列在T[QI]中至少出现k次,称表T满足QI上的k-匿名。T[QI]表示表T的元组在QI上的投影。
2.2 k-匿名实质
k-匿名实质就是要求数据集中每一条记录都要与至少k-1条记录在准标识符上的投影相同,因此,个体所在记录被确定的概率不超过1k。而泛化[13]是典型的实现匿名化隐私保护的技术手段,其实质是用一般化的值或区间来替代具体值,通过降低数据精度增加攻击者获取个体隐私信息的难度。
表3是经过泛化后的一张满足k=2的匿名医疗数据表。
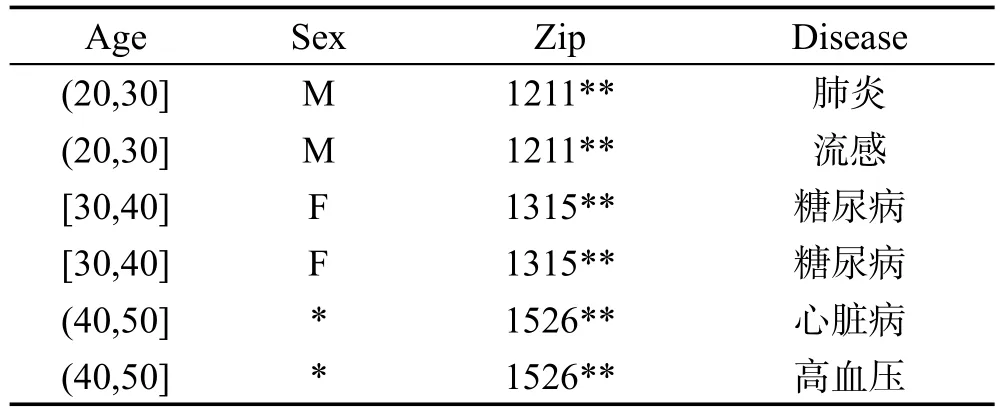
Table 3 Meeting 2-anonymous data sheet表3 满足2-匿名数据表
2.3 k-匿名缺点
虽然k-匿名算法提高了发布信息的安全性,但是由于需要对数据表的某些属性进行泛化和隐匿,损失了一部分数据的可用性。同时k-匿名算法在运算过程中,存在查询结果不精确的缺点,尤其是在用户稀少的场景下,将产生较大的匿名区域,从而增大通信开销。
3 信息熵l-多样性模型
经过泛化后的数据表满足k-匿名,保证了某个用户处于k个同类别的个体集合之中,使得拥有相同准标识符的用户个体不可区分,从而达到一定的匿名性保护。然而,如果处于同一等价类中的k个元组在敏感属性上的取值相同,则用户个体记录会受到同质性攻击而造成属性泄露,例如表3中第二个等价类。
为了解决同质性攻击带来的隐私泄露问题,文献[13]提出了l-diversity模型,即l-多样性模型,要求每个等价类至少含有l个表现良好(well-presented)的敏感属性值,考虑了对敏感属性的约束。如果数据表中每个等价类中含有l个不同的敏感属性值,那么就称该数据表满足l-多样性规则。文献[7]还给出了一种信息熵l-多样性规则。
定义2信息熵l-多样性(entropyl-diversity):给定数据表T{A1,A2,…,An},准标识符属性为QI{Ai,Ai+1,…,Aj},敏感属性为SA,S={Si,Si+1,…,Sj}为敏感属性值。表T满足k-匿名,并且其等价类集合为E={E1,E2,…,En},当且仅当对每一个等价类Ei=1,2,…,n⊆E,都满足式(1)时,则称数据表T满足信息熵l-多样性。
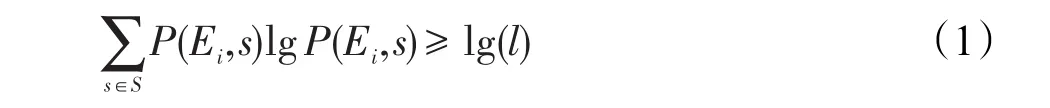
其中,P(Ei,s)为等价类Ei中敏感属性值s出现的频率;为等价类Ei的信息熵,又称信息熵多样性,记作Entropy(Ei)。信息熵反映了属性的分布情况,信息熵越大,意味着等价中敏感属性值分布越均匀,推导出具体个体的难度也就越大。由式(1)可知,要想等价类满足信息熵l-多样性,那么等价类的信息熵至少为lg(l)。表4是匿名数据表中的一个等价类。

Table 4 Meeting 5-anonymous equivalence class表4 满足5-匿名等价类
表4中等价类的信息熵l-多样性计算结果如下:
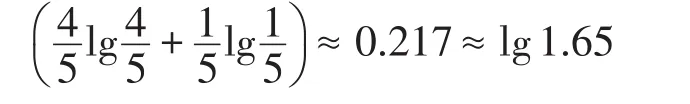
从结果来看,对于该等价类来说,其信息熵多样性为lg1.65,参数l的取值不能超过1.65,那么只能取1,考虑到l-多样性的定义,也就是说等价类中至少有1个不同的敏感属性值,对于实际发布的数据表而言,这种结论显然意义不大。
并且该等价类中的敏感属性,有4个是“流感”,对于很多病人来说,显然这并不是敏感属性,如果等价类中包含4个如“肺结核”这种敏感程度很高的敏感属性,假设攻击者知道某人处于该等价类中,那么攻击者有很大把握推测该人有“肺气肿”的疾病倾向特征,这对于病人来说是不可接受的。实际上,医疗信息中包含着大量的诸如“流感”或者“发烧”这些非敏感属性值,这些属性值的公开并不会侵犯到个体隐私。因此,信息熵l-多样性模型没有区分敏感属性值,不能反映出这种情况下隐私泄露的风险。本文提出一种个性化信息熵l-多样性模型来保护用户的医疗数据隐私。
4 个性化信息熵l-多样性模型
4.1 个性化信息熵
多样性模型定义针对信息熵l-多样性模型存在的不足,一方面需要提高等价类的信息熵值,另一方面需要区分敏感属性值,降低敏感属性强的信息泄露概率。
因此,可以将敏感属性值分为强敏感值SV(sensitive value)和弱敏感值DV(don't care value),修改信息熵l-多样性规则后得到新的个性化信息熵l-多样性规则。
定义3个性化信息熵l-多样性:给定数据表T{A1,A2,…,An},QI{Ai,Ai+1,…,Aj}为T的准标识符,SA为敏感属性,S={Si,Si+1,…,Sj}为敏感属性值集合,SV表示强敏感值,DV为弱敏感值,|SV|为强敏感值的个数,|DV|为弱敏感值的个数。表T满足k-匿名,并且其等价类集合为E={E1,E2,…,En},当且仅当对每一个等价类Ei=0,1,…,n⊆E,都满足式(2)时,则称数据表T满足个性化信息熵l-多样性。
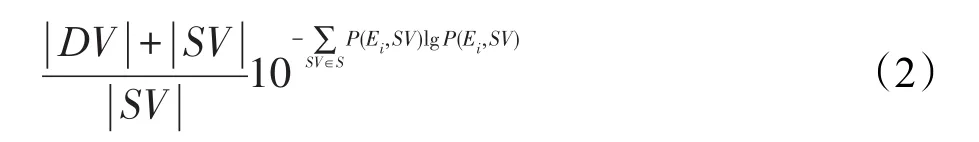
其中,P(Ei,SV)为强敏感属性值在等价类中出现的频率;为个性化等价类的信息熵多样性。
由式(2)可知,需要计算等价类中强敏感属性值的频率P(Ei,SV),而不需要计算会降低P(Ei,SV)lgP(Ei,SV)值的弱敏感属性值出现的频率。用式(2)计算表4中等价类的信息熵,有DV={流感},SV={肺气肿},|DV|=1,|SV|=1,SV在等价类中出现的概率为1/5,那么改进后的信息熵多样性为:

根据计算结果,l的取值不超过2.282 8,则l为2,该等价类满足2-多样性。个性化信息熵l-多样性相比较信息熵l-多样性,提高了等价类信息熵,降低了从等价类中链接推导出隐私信息与身份信息的对应关系。
4.2 信息损失度量
基于k-匿名以及在其基础上改进的匿名隐私保护模型在保护隐私信息的同时,不可避免地会产生信息损失,从而对数据精度造成影响,这就是匿名代价(anonymization cost)。匿名代价是在对原始数据进行泛化和抑制预处理操作时产生的,匿名代价度量是衡量数据匿名化后信息损失的指标,同时也可以判断匿名后的数据集的优化程度。信息损失越小,数据精度越大,数据可用性越高。反之亦然。因此,在进行匿名化操作过程中,应尽量降低匿名代价。
本文采用基于泛化层级的方法度量匿名代价,而使用该方式度量匿名代价,则需要构建属性的域泛化层级。处于域泛化层级中每一层包含的信息量是不同的。通常,对于同一属性来说,处于泛化高层的数据比处于低层级数据所包含的信息量较少。计算公式如下:

其中,Prec表示数据精度,为原始数据表;RT为泛化后的数据表;N表示数据表中属性个数;NA为数据集的记录数;|DGHAi|为属性Ai泛化层级结构的高度;h表示属性Ai在泛化层级结构中处于的高度。
定义4域泛化层级(domain generalization hierar-chy):设A为数据表T的属性,存在函数fh:h=0,1,…,n-1,使得,并且A=A0,|An|=1,那么属性A在fh:h=0,1,…,n-1上的泛化域层级可表示为,记作 |DGHA|。
{Z0,Z1,Z2,Z3}展示的是Zip属性自下而上的泛化过程,每一层表示该属性的一个泛化域。随着DGH一直往上,属性的泛化程度越来越高,直到最后达到抑制的状态,泛化过程描述如下:

5 实验结果及分析
本实验采用文献[14]提出的Incognito算法完成匿名操作过程。Incognito算法的基本思想是采用全局重编码技术,按照自底向上的宽度优先方式对原始数据集执行泛化操作,同时对泛化图(generalization graph)进行必要的剪枝、迭代操作,使原始数据集逐步优化,从而达到匿名效果。本文方案主要考虑算法执行时间与数据表的信息损失。
5.1 实验数据与实验环境
实验所采用的数据集为UCI中的Adult数据库[15],该数据库是用于k-匿名研究最常用的数据源。该数据库共有32 206条数据,大小为5.5 MB,数据集共含有15个属性。选取其中的8个属性作为准标识符的属性集,选取Disease属性作为敏感属性。表5描述了实验数据集的结构。
实验采用MySQL 5.5存储数据;算法用Java语言实现;实验运行环境是CPU为3.3 GHz Intel®Core i5处理器,4 GB RAM。
选取Disease作为实验敏感属性。Disease属性含10个值,随机产生疾病种类,用敏感权重来衡量敏感度,值越大,说明敏感度越高,见表6。实验中将敏感权重低于0.5的疾病设为弱敏感属性。

Table 5 Structure of adult data set表5 Adult数据集结构

Table 6 Weight of disease表6 Disease权重
5.2 时间复杂度分析
本文方案首先需要计算强敏感值|SV|和弱敏感值|DV|的个性化信息熵l-多样性×,因此计算开销是线性的,时间复杂度为O(n)。其次需要对信息损失度量进行计算,,计算过程中有两次和的累乘运算,因此在该阶段的计算开销为O(n2)。最后需要对属性进行域泛化层级处理,每次泛化的计算开销为线性的,因此计算复杂度为O(n)。
5.3 执行时间分析
从图1可知,随着QI个数增加,3种模型的执行时间都会增加。这是因为随着QI值增大,等价类中要求记录更多的准标识符属性,这就需要更多的泛化次数,这个过程也就需要算法执行更多次的循环,所以执行时间会增大。
同时,可以看到,随着QI值增大,本文方案相比较信息熵l-多样性模型执行时间更短一些。这是因为信息熵l-多样性模型判断等价类中强敏感属性和弱敏感属性需要更长的时间。
图2描述的是QI记录数目从0到1 000递增时,3种匿名模型中数据精度随k或l值的变化。横坐标为记录个数,纵坐标是执行不同算法的时间,可以看到本文方案在提高数据精度的同时,减少了算法的执行时间。

Fig.1 Comparison of execution time with the number of quasi identifiers图1 准标识符个数变化执行时间比较

Fig.2 Comparison of execution time with the number of records图2 记录个数变化执行时间比较
5.4 精确度分析
图3 描述的是QI记录数目从1 000到3 500递增时,3种匿名模型中数据精度随k或l值的变化。横坐标为记录个数,纵坐标是匿名数据集的数据精度,可以发现随着记录个数的增加,本文方案的精度高于其他方案。
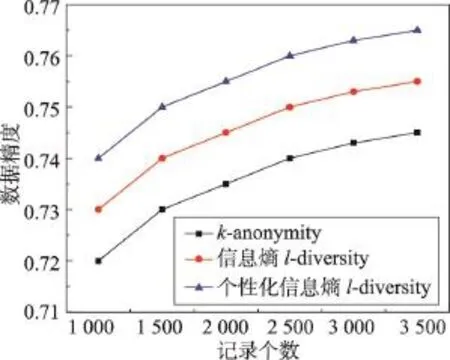
Fig.3 Comparison of data accuracy with the number of records图3 记录个数变化数据精度比较
5.5 信息损失分析
图4 描述的是QI个数为0~8时,3种匿名模型中数据精度随k或l值的变化。横坐标为k、l值,纵坐标是匿名数据集的数据精度。

Fig.4 Comparison of data accuracy withk,lvalue图4 数据精度随k、l值比较
从图4可知,随着k、l值的增加,数据精度呈下降趋势。这是因为随着k、l值的增大,等价类中需要泛化的元组数也就越多,泛化层级越高,信息损失也越大,从而数据精度就会降低。同等情况下,个性化信息熵l-多样性的信息损失高于信息熵l-多样性。这是因为个性化信息熵l-多样性对匿名约束性强于信息熵l-多样性,需要对准标识符进行更高层级的泛化,所以信息损失相对多一些。
6 结束语
针对信息熵l-多样性模型中没有区分强弱敏感属性的问题,本文提出了个性化信息熵l-多样性模型并进行实验。实验结果表明,本文方案在执行时间和数据精度方面的表现优于信息熵l-多样性模型与k-匿名模型,且有更好的隐私性,可以运用到移动医疗系统中来保护医疗用户的隐私数据不被泄漏。
[1]Gong Qiyuan,Yang Min,Luo Junzhou.Data anonymization approach for incomplete microdata[J].Journal of Software,2013,24(12):2883-2896.
[2]Janpuangtong S,Shell D A.Helping novices avoid the hazards of data:leveraging ontologies to improve model generalization automatically with online data sources[J].AI Magazine,2016,37(2):19-32.
[3]Komishani E G,Abadi M,Deldar F.PPTD:preserving personalized privacy in trajectory data publishing by sensitive attribute generalization and trajectory local suppression[J].Knowledge-Based Systems,2016,94:43-59.
[4]Vu K,Zheng Rong,Gao Jie.Efficient algorithms forkanonymous location privacy in participatory sensing[C]//Proceedings of the 31st Annual IEEE International Conference on Computer Communications,Orlando,Mar 25-30,2012.Piscataway:IEEE,2012:2399-2407.
[5]LeFevre K,DeWitt D J,Ramakrishnan R.Incognito:efficient full-domaink-anonymity[C]//Proceedings of the 2005 ACM SIGMOD International Conference on Management of Data,Baltimore,Jun 14-16,2005.New York:ACM,2005:49-60.
[6]Rebollo-Monedero D,Forné J,Soriano M,et al.k-anonymous microaggregation with preservation of statistical dependence[J].Information Sciences,2016,342:1-23.
[7]Xin Tingting,Liu Guohua.Top-kqueries underK-anonymity privacy protection model[J].Journal of Frontiers of Computer Science and Technology,2011,5(8):751-759.
[8]Wang Danli,Liu Guohua,Song Jinling,et al.Problem of finding the optimal value on quasi-identifier fork-anonymity model[J].Journal of Frontiers of Computer Science and Technology,2010,4(11):1010-1018.
[9]Dai Jiazhu,Hua Liang.Method of anonymous area generation for sensitive location protection under road networks[J].Computer Science,2016,43(3):137-144.
[10]Söderström-Anttila V,Miettinen A,Rotkirch A,et al.Shortand long-term health consequences and current satisfaction levels for altruistic anonymous,identity-release and known oocyte donors[J].Human Reproduction,2016,31(3):597-606.
[11]Moja L,Friz H P,Capobussi M,et al.Implementing an evidence-based computerized decision support system to improve patient care in a general hospital:the CODES study protocol for a randomized controlled trial[J].Implementation Science,2016,11(1):89.
[12]Fields L,Arntzen E,Nartey R K,et al.Effects of a meaningful,a discriminative,and a meaningless stimulus on equivalence class formation[J].Journal of the Experimental Analysis of Behavior,2012,97(2):163-181.
[13]Zhou Changli,Ma Chunguang,Yang Songtao.Research of LBS privacy preserving based on sensitive location diversity[J].Journal on Communications,2015,36(4):125-136.
[14]Zhang Xiaojian,Meng Xiaofeng.Differential privacy in data publication and analysis[J].Chinese Journal of Computers,2014,37(4):927-949.
[15]Blake E K C,Merz C J.UCI repository of machine learning databases[EB/OL].(1998).http://www.ics.uci.edu/~mlearn/MLRepository.html.
附中文参考文献:
[1]龚奇源,杨明,罗军舟.面向缺失数据的数据匿名方法[J].软件学报,2013,24(12):2883-2896.
[7]辛婷婷,刘国华.K-匿名隐私保护模型下的Top-k查询[J].计算机科学与探索,2011,5(8):751-759.
[8]王丹丽,刘国华,宋金玲,等.k-匿名模型中准标识符最佳值的求解问题[J].计算机科学与探索,2010,4(11):1010-1018.
[9]戴佳筑,华亮.路网环境下敏感位置匿名区域的生成方法[J].计算机科学,2016,43(3):137-144.
[13]周长利,马春光,杨松涛.基于敏感位置多样性的LBS位置隐私保护方法研究[J].通信学报,2015,36(4):125-136.
[14]张啸剑,孟小峰.面向数据发布和分析的差分隐私保护[J].计算机学报,2014,37(4):927-949.
猜你喜欢
计算机应用(2022年8期)2022-08-24
新高考·高三数学(2022年3期)2022-04-28
西南大学学报(自然科学版)(2022年4期)2022-04-15
台湾农业探索(2020年4期)2020-10-29
党员生活·下(2020年3期)2020-04-20
党员生活·下(2020年2期)2020-04-20
党员生活(2020年2期)2020-04-17
计算机系统应用(2020年8期)2020-03-22
台湾农业探索(2019年5期)2019-09-10
中文信息(2017年12期)2018-01-27
