
类别不平衡的多任务人脸属性识别
2018-06-28 02:55张文
计算机与现代化 2018年6期
张 文
(南京航空航天大学计算机科学与技术学院,江苏 南京 210016)
0 引 言
属性作为物体的中层特征表示,对物体[1]和场景[2]的识别显得至关重要。而人脸属性识别中的属性主要是指头发颜色、性别、鼻子和脸型等,在人脸验证[3]、识别[4]以及检索方面[5]都有很多的应用,例如人脸表情的识别,这对于机器理解人的情绪至关重要;在人脸图片质量较差时进行身份验证,普通的人脸验证算法可能会失效,如在刑侦案件中,对犯罪嫌疑人通常只有一些物理属性的描述,可以通过这些属性在监控视频中检索相似的疑犯,或者在图片搜索中按照某个相似的属性进行检索,如黄皮肤的人。
识别自然场景中人脸属性是比较具有挑战性的任务,因为人脸容易受到光照、姿势和遮挡的影响,近些年来也受到很多的关注,例如大规模的属性数据集[6]的公开说明该问题得到了研究者的关注。属性识别的传统方法大致可以分成2类:全局和局部方法。全局方法从整个物体中抽取特征,该方法不需要物体关键点准确位置,但该方法对物体的变形扭曲不够鲁棒;局部方法首先检测物体的部件,对每个部件提取特征后,将这些特征连接起来训练分类器。例如文献[3]从人脸的10个块中抽取人工设计的特征识别人脸属性。Panda模型通过对齐人体,然后抽取上百个部件来识别人的属性[7]。这些局部的方法在无约束且有较大变形的人脸图片上通常失效,这是因为这些人脸的定位和对齐十分困难,所以提取的特征不准确。近几年来,在很多的计算机视觉任务上卷积神经网络[8-9](Convolutional Neural Network, CNN)替代了大部分传统的特征抽取方法,同样,在属性的识别[7,10-11]中该方法也被证明是有效的。然而这些方法存在着一些明显的问题:
1)现有很多的任务中都只是将属性识别当作简单的二分类,假设了属性之间是相互独立的,而该假设不符合实际的场景,例如有胡子的人几乎不可能是女性,戴耳环、项链、涂口红的也可能是男性。所以在实际应用中要同时利用这些信息,而现有算法忽略了它们之间的关系。
2)在实际场景中,某些属性所出现的概率比较小,会出现不平衡的状态,导致分类器将偏向于一类,例如光头的概率明显比有头发的概率小,络腮胡子出现的概率明显比较小,这类现象会导致分类器在某些类上失去价值。
本文提出了一个多任务的CNN框架,网络的底层共享特征和权重,与无差别对待属性方法不同,在高层根据属性的不同划分组,组内属性相关性强,这样可以保证属性网络学习到一定的属性相关性,且在设计损失函数时进行再缩放,缓解类别不平衡问题,笔者在2个大规模的公开数据集CelebA和LFWA上测试了该算法的有效性。本文采用最新的Dense net[9]网络结构设计了多任务的属性分类网络框架,针对数据不平衡的问题采取缓解方案,在公开数据集上验证该方法的有效性,结果表明该方法极大地减少了网络的参数,降低了训练时间。
1 相关工作
1.1 多任务学习
CNN广泛用于特征抽取,在很多问题上比人工设计的特征性能好很多,例如物体识别[12]、人脸检测[13]、人脸识别和验证[14]等。而很多的开源软件工具也极大促进了CNN的流行,其中Caffe、Pytorch、TensorFlow是使用比较多的软件包。CNN最早是在2012年的ImageNet竞赛[8]上,比现存的方法效果高出很多,自此以后,研究者针对不同的视觉任务提出了大量的CNN网络架构。在人脸识别和验证领域,王晓刚团队提出的Deep ID[14]在LFW上无约束的自然场景人脸验证精度首次超过人类,而在此以后,研究者关注于设计更加复杂更加高效的网络结构[9]。在本文中,笔者利用CNN强大的特征学习能力来识别属性,该特征能够作为下一步人脸识别和验证的中层特征表示。
多任务学习(Multi-Task Learning, MTL)是通过共享信息然后同时解决多个问题的一种方法。多任务学习在有着全局结构约束的问题上有着很多的应用,例如人脸关键点定位[15]、动作识别[16]等;在文本分类问题中,通过对整个单词中的字符同时推断比单独分类的效果要好很多;在多标号图像检索中,图片的内容通常是跨模态的(例如文本描述、声音描述),联合学习图片表示后能够生成图片的描述或者依据描述来检索图片[17]。在属性和对象类别同时学习比简单的对象分类效果好很多。Wang等[18]通过学习属性和对象的关系,然后利用多示例学习检测和识别对象,该方法可以有效提高识别和检测的精度。
1.2 属性学习
Kumar等[3]首次提出用65个二值的属性来描述人脸,然后利用这些人脸属性作为人脸的标识进行人脸验证。随后又增加了8个属性,将人脸属性用于人脸验证和按照属性检索[4]。Berg对数据集中的每对人脸学习分类器,然后用这些分类器构建特征用于人脸验证的分类器,与手动标注属性不同,每个人是通过和其他人的相似性来描述,该方法在大的数据集上可以自动构建属性集合而无需手动枚举属性。
近些年来,CNN也在属性分类上有所应用。Panda模型[7]通过选取很多的部件,然后用这些部件训练归一化的网络,将这些部件结合起来用于属性分类,在当时取得了最好的效果。为了更关注于年龄和性别的识别,Levi等[11]首次将CNN应用于大规模的年龄和性别数据集Adience上。而贡献比较大的是香港中文大学团队的工作[6],一方面公开了他们采集的大规模人脸属性数据集,这个数据集比LFWA大好几倍,且场景、姿态、光照等变化更好,更加贴合生活场景,另一方面,该工作中提出了一个结合2种网络来识别属性的方法,其中一个网络用于人脸关键点的定位,另一个网络用于属性识别,在数据集CelebA和LFWA上取得了很好的结果。Moon模型[19]同样使用CNN进行属性识别,与单独针对每个属性训练网络不同,该方法一次性预测所有属性,网络底部共享特征,与传统提取特征训练分类器不同,该方法是端到端的形式,且该方法针对类别不平衡问题提出了一种再平衡的方法,但该方法中没有考虑属性之间的关系,假设了属性相互独立。MCNN-AUX模型[20]虽然采用了多任务学习进行属性分类,并考虑了属性之间的关系,但该方法没有考虑类别之间的平衡性。本文所采用的方法是对以上二者缺点的改进,即针对类别不平衡进行再平衡,其次再对属性进行分组确定其关系。
2 方法与网络结构
2.1 网络结构

图1 多任务学习网络框架
网络框架如图1所示,该网络前部分即底层共享特征,在网络高层上对网络进行分支划组,每个组对应一组属性的集合,将人脸属性根据相关性划分成8组,具体划分如表1所示,其中组与组之间属性具有较强的相关性。每组内部采用上面描述的损失学习,这样可以保证强相关的属性之间的关系,能够更好地学习属性之间的联系。在全连接层前有个卷积层是为了保证各组之间的差异性。底层网络结构是在Dense net[9]上改进而来,主要由Dense Block和Transition构成,采用该结构是因为该Dense Block其密集的链接一方面可以学习更好的特征,另一方面,在达到同样效果时,模型的参数更少,运算效率会有所提高。网络的输入是原始图片根据关键点眼睛鼻子3个点进行对齐后,裁剪大小为218×178,进行归一化后输入。
表1 网络结构

Output SizeDenseADenseABG109×897×7 conv, stride 27×7 conv, stride 254×443×3 max pool, stride 23×3 max pool, stride 254×441×1 conv3×3 conv ×31×1 conv3×3 conv ×354×441×1 conv1×1 conv27×222×2 average pool, stride 22×2 average pool, stride 227×221×1 conv3×3 conv ×61×1 conv3×3 conv ×627×221×1 conv1×1 conv13×112×2 average pool, stride 22×2 average pool, stride 213×111×1 conv3×3 conv ×121×1 conv3×3 conv ×813×111×1 conv1×1 conv6×52×2 average pool, stride 22×2 average pool, stride 26×51×1 conv3×3 conv ×81×1 conv3×3 conv (普通卷积, 8组)1×16×5 global average pool6×5 global average pool40D fully-connectedfully-connected
底层特征学习网络结构如表1所示,包含DenseA(Dense Attribute)和DenseABG(Dense Attribute Balanced Group),其中DenseA是在Dense net结构上修改的,改动的方法是将每个Dense Block中的层的数量减少,防止过拟合问题,最后一个pooling层改为6×5,再有就是全连接层改为40;而DenseABG结构和DenseA底层差不多,唯一不同的是去掉最后一个Dense Block,将其改为8组普通的conv,对应于表2中的属性分组,且将第三个Dense Block的层数减少为8。
表2 属性分组
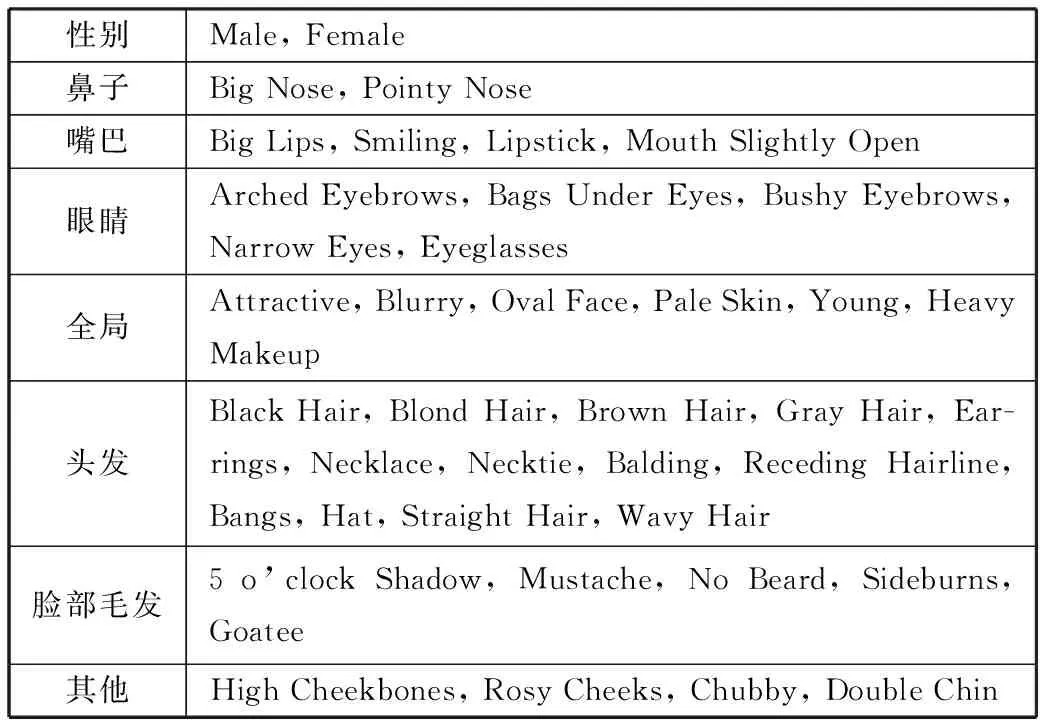
性别Male, Female鼻子Big Nose, Pointy Nose嘴巴Big Lips, Smiling, Lipstick, Mouth Slightly Open眼睛Arched Eyebrows, Bags Under Eyes, Bushy Eyebrows, Narrow Eyes, Eyeglasses全局Attractive, Blurry, Oval Face, Pale Skin, Young, Heavy Makeup头发Black Hair, Blond Hair, Brown Hair, Gray Hair, Ear-rings, Necklace, Necktie, Balding, Receding Hairline, Bangs, Hat, Straight Hair, Wavy Hair脸部毛发5 o’clock Shadow, Mustache, No Beard, Sideburns, Goatee其他High Cheekbones, Rosy Cheeks, Chubby, Double Chin
2.2 属性分组
人脸具有很多的属性,而属性之间很多是具有一定的相关性的,例如如果性别是女性,其极大可能性会化妆、穿戴配饰和涂抹口红,这些属性是强相关的;如果该人是个光头,根本没有谈论其头发颜色的需要,这种关系是互斥关系,按照这些关系,将人脸的属性分组,主要根据人脸位置相关性和局部与全局的关系,分组如表2所示。
2.3 损失函数与评价
多任务学习的目标是使所有的损失最小,而每个任务都有自己的目标函数。在本文框架里就是对应于每个属性分组,同时进行优化。在任务中就是识别属性,并使得整体识别精度最高。与普通的损失函数相比,本文采用了Rudd[19]提出的再平衡方法,不同在于,由于在实际的场景中某些属性样本出现的概率很小,比如在CelebA数据集中Bald、Eyeglasses、Gray Hair、Receding Hairline等属性所占图片总数不到0.1。所以需要考虑类别不平衡问题,使得模型不偏向于任何一方。
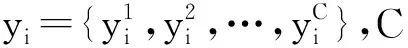
(1)
(2)
损失函数为:
(3)
为了比较方便,本文采用统一的准确率作为评价标准,即对每张人脸图片预测所有类别的属性,然后计算每个属性的正确率,再以属性的平均正确率作为方法比较的度量方式。
3 实 验
3.1 实验数据集
在实验中,主要使用了2个具有挑战性的公开数据集:CelebA[6]和LFWA[21]。这2个数据集原本都是为了人脸验证而收集的,最近增加了属性的标注。这2个数据集都是极具挑战性的,由于这些照片都是从自然场景中收集的,对象的姿态变化大,存在各种遮挡,照片质量也不一致,部分图片如图2所示。其中CelebA包含了约10000个名人的200000张照片,根据其数据集的划分,其中训练集160000张,验证集和测试集各约20000张,每张图片都标注了5个点(包括眼睛、鼻尖、嘴角),以及对应的40个二值属性。属性如表2所示,该数据集也提供了对齐并裁剪后的图片,在实验中采用该版本数据集。而LFWA数据集中仅包含了13143张照片,其中训练集6263张,测试集6880张,由于该数据集较小,在训练时可采用数据扩增的方法。主要是在这2个数据集上汇报属性识别的性能,计算每个属性的正确率,整体性能用平均正确率衡量。

图2 CelebA(上面一行)和LFWA(下面一行)部分图片
3.2 训练方法
本文的网络实现采用开源框架Pytorch,所采用的GPU是TitanX,显存12 GB,内存32 GB的工作站。网络都是采用随机梯度下降来训练。本文选取的初始学习率为0.01,然后在每10次迭代后除以10递减学习率,同时设置动量系数为0.9,同时为了提高模型的泛化性,设置了权重衰减系数为10-4。一共训练30轮,batch的大小设置为256。在LFWA数据集上,由于该数据集的数据量较少,可采用数据扩增的方法,通过填充像素和对称翻转,可以得到训练集约为75000张,并且本文设置网络中drop-rate为0.5,防止过拟合。
3.3 实验结果及分析
为了验证方法的有效性,笔者做了3组实验,第一组是DenseA,单纯采用欧氏距离作为度量,第二组是在欧氏距离度量的基础上加入了类别再平衡DenseAB(Dense Attribute Balanced),第三组是在上面基础上增加类型分组DenseABG。实际训练过程中,网络在接近第10轮迭代的时候已经收敛,这时候可以采用早停止(early stop)的策略,时间不到一个小时就可以停止训练,该网络的收敛和训练速度相比之前的方法都有很大的提升。
从表3可以看出,在数据集CelebA上,本文的结果要比以往的方法要好。其中和Liu经典方法[6]相比,DenseA在很多属性上要高出很多,这是由于该网络采用的是端到端的学习方法,一次性学习所有的属性,底部共享信息,例如Bags Under Eyes、Arched Eyebrows、Chubby、Straight Hair等属性上效果提升明显,这是由于本文的网络结构采用了Dense Block[9]的结构,每个Dense Block增加了卷积层与卷积层之间的密集连接,这说明了本文网络的特征学习能力强。而在DenseA基础上的DenseAB采用了再平衡的损失函数,整体性能有所提升,尤其在Bald、Blurry、Bushy Eyebrows、Chubby等属性上性能有明显的提升,这是由于这些属性在训练样本中该属性所占的比例通常特别小,在加入了类别再平衡后,不至于导致分类器偏爱于一方的数据,也证明了该再平衡策略一定程度上缓解了类别不平衡问题。DenseABG的方法是在DenseAB的基础上将属性依据表2的划分方法将属性分组,其中组与组之间的属性是具有相关性的,从最后一列可以看出加入分组后,性能有所提升。而从方法的比较上来看,相比于Moon[19]和MCNN-AUX[20],本文的3组实验都比其效果要好,原因主要有3个方面:1)从DenseA超过二者可以看出网络结构的优越性;2)从DenseAB、DenseABG与Moon的对比可以看出,虽然Moon也采用了再平衡策略,但其没有对属性分组,将所有属性同等对待,认为属性的独立性假设太强;3)MCNN-AUX虽然也采用了属性分组的多任务学习框架,但是该方法没有考虑类别不平衡的问题,所以本文的方法比其有所提升。本文的方法与最好方法MCNN-AUX的1600万的参数相比,本文模型的参数数量仅有200万,在训练时间和计算效率上要远远超过其方法,更具实用性。
表3 CelebA数据集(每个属性的最高准确率用粗体表示)

AttributLiu et alMOONMCNN-AUXDenseADenseABDenseABG5 o’clock Shadow91.094.0394.5194.6794.6995.21Arched Eyebrows79.082.2783.4284.1184.1584.15Attractive81.081.6783.0682.9082.0983.05Bags Under Eyes79.084.9284.9285.5384.9384.91Bald98.098.7798.9099.0399.2199.23Bangs95.095.896.0595.9395.996.1Big Lips68.071.4871.4771.957272.13Big Nose78.084.084.5384.5784.5884.55Black Hair88.089.489.7889.6589.8989.95Blond Hair95.095.8696.0196.0296.0796.07Blurry84.095.6796.1796.1696.2296.25Brown Hair80.089.3889.1589.3589.4189.56Bushy Eyebrows90.092.6292.8492.7392.8292.84Chubby91.095.4495.6795.6795.6995.54Double Chin92.096.3296.3296.4196.4696.46Eyeglasses99.099.4799.6399.6899.6799.68Goatee95.097.0497.2497.5397.5397.56Gray Hair97.098.198.2098.3298.2198.36Heavy Makeup90.090.9191.5591.6191.691.62High Cheekbones87.087.0187.5887.6987.6887.65Male98.098.198.1798.1998.298.2Mouth Slightly Open92.093.5493.7493.8193.8193.84Mustache95.096.8296.8896.9897.0297.04Narrow Eyes81.086.5287.2387.4387.4787.49No Beard95.095.5896.0596.0696.0396.08Oval Face66.075.7375.8476.4076.6276.62Pale Skin91.097.097.0597.1197.2197.26Pointy Nose72.076.4677.4777.5277.4977.61Receding Hairline89.093.5693.8193.8094.8294.89Rosy Cheeks90.094.8295.1695.1095.1295.1Sideburns96.097.5997.8597.9497.9697.97Smiling92.092.692.7393.09392.98Straight Hair73.082.2683.5883.8683.8983.95Wavy Hair80.082.4783.9184.2284.4584.52Wearing Earrings82.089.690.4390.5390.5890.62Wearing Hat99.098.9599.0599.1799.2499.28Wearing Lipstick93.093.9394.1194.0494.0594.07Wearing Necklace71.087.0486.6387.4987.5287.51Wearing Necktie93.096.6396.6396.989797.05Young87.088.0888.4888.4988.5288.53Average87.390.9491.2991.4491.4791.54
最后,笔者也在LFWA上测试了该框架的有效性,如表4所示,同样与经典的Liu方法和MCNN-AUX进行比较,但由于MOON没有在该数据集上测试,本文方法与CTS-CNN[22]方法进行比较,由于该数据集较小,提升的效果并不是很明显,性能相当,但在DenseABG上可以看出,该方法依旧有所提升。
表4 LFWA上结果

方法平均正确率/%Liu et al[6]84CTS-CNN[22]86MCNN-AUX[20]86DenseA86.2DenseAB86.7DenseABG87.2
4 结束语
本文设计了一个基于类别不平衡的多任务学习框架,针对属性正负样本的不平衡进行了加权再平衡,同时与之前的无差别对待所有属性的方法相比,通过对属性划分上加入先验知识,同一组内属性的相关性强,在网络中共享特征,可以保证在深度模型学习的时候学习到这种关系。同时本文采用的网络结构也是由最新的Dense net上演化而来,该结构具有训练速度快和特征学习能力强的优点,通过在2个比较大的公开数据集上进行的对比实验验证了该框架的有效性,比之前的方法有所提升。当然,该方法还存在一些问题,比如现在所使用的分组是由人工设计,如何通过网络自动学习这种关系也是接下来要研究的问题,另一个问题是在这些公开数据集中存在着很多的噪声,如何在有噪声的情况下提高算法的精度,也是值得研究的方向。
参考文献:
[1] Duan K, Parikh D, Crandall D, et al. Discovering localized attributes for fine-trained recognition[C]// 2012 IEEE Conference on Computer Vision and Pattern Recognition. 2012:3474-3481.
[2] Phillips P J, Zheng Jingjing, Jiang Zhuolin, et al. Submodular attribute selection for action recognition in video[C]// Advances in Neural Information Processing Systems. 2014:1341-1349.
[3] Kumar N, Berg A C, Belhumeur P N, et al. Attribute and simile classifiers for face verification[C]// IEEE International Conference on Computer Vision(ICCV). 2009: 365-372.
[4] Kumar N, Berg A C, Belhumeur P N, et al. Describable visual attributes for face verification and image search[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011,33(10):1962-1977.
[5] Wu Zhong, Ke Qifa, Sun Jan, et al. Scalable face image retrieval with identity-based quantization and multireference reranking[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011,33(10):1991-2001.
[6] Liu Ziwei, Luo Ping, Wang Xiaogang, et al. Deep learning face attributes in the wild[C]// 2015 IEEE International Conference on Computer Vision. 2015: 3730-3738.
[7] Zhang Ning, Paluri M, Ranzato M, et al. Panda: Pose aligned networks for deep attribute modeling[C]// 2014 IEEE International Conference on Computer Vision. 2014:1637-1644.
[8] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C]// Advances in Neural Information Processing Systems. 2012:1097-1105.
[9] Huang Gao, Liu Zhuang, Weinberger K Q. Densely connected convolutional networks[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition. 2017:2261-2269.
[10] Abrar H A, Wang Gang, Lu Jiwen, et al. Multi-task CNN model for attribute prediction[J]. IEEE Transactions on Multimedia, 2015,17(11):1949-1977.
[11] Levi G, Hassner T. Age and gender classification using convolutional neural networks[C]// 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops. 2015:34-42.
[12] Ren Shaoqing, He Kaiming, Girshick R B. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015,39(6):1137-1149.
[13] Yang Shuo, Luo Ping, Loy C C, et al. From facial parts responses to face detection: A deep learning approach[C]// 2015 IEEE International Conference on Computer Vision. 2015:3676-3684.
[14] Sun Yi, Wang Xiaogang, Tang Xiaoou. Deep learning face representation from predicting 10,000 classes[C]// 2014 IEEE Conference on Computer Vision and Pattern Recognition. 2014:1891-1898.
[15] Devries T, Biswaranjan K, Taylor G W. Multi-task learning of facial landmarks and expression[C]// 2014 Canadian Conference on Computer and Robot Vision. 2014:98-103.
[16] Zhou Qiang, Wang Gang, Jia Kui, et al. Learning to share latent tasks for action recognition[C]// 2013 IEEE International Conference on Computer Vision. 2013:2264-2271.
[17] Huang Yan, Wang Yan, Wang Liang. Unconstrained multimodal multi-label learning[J]. IEEE Transactions on Multimedia, 2015,17(11):1923-1935.
[18] Wang Yang, Mori G. A discriminative latent model of object classes and attributes[C]// The 11th European Conference on Computer Vision. 2010:155-168.
[19] Rudd E M, Gnther M, Boult T E. MOON: Amixed objective optimization network for the recognition of facial attributes[C]// The 14th European Conference on Computer Vision. 2016:19-35.
[20] Hand E M, Chellappa R. Attributes for improved attributes: A multi-task network utilizing implicit and explicit relationships for facial attribute classification[C]// Proceedings of the 31st AAAI Conference on Artificial Intelligence. 2017:4068-4074.
[21] Huang G B, Ramesh M, Berg T, et al. Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments[R]. University of Massachusetts Amherst, 2007.
[22] Zhong Yang, Sullivan J, Li Haibo. Face attribute prediction using off-the-shelf CNN features[C]// 2016 International Conference on Biometrics. 2016:1-7.
猜你喜欢
北京大学学报(自然科学版)(2022年1期)2022-02-21
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
中国生物医学工程学报(2019年6期)2019-07-16
动漫星空(2018年9期)2018-10-26
自动化学报(2016年3期)2016-08-23
军事运筹与系统工程(2016年4期)2016-07-10
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
智能系统学报(2015年4期)2015-12-27
中国交通信息化(2015年7期)2015-06-06
