
面板数据下序贯模型变点的渐近检验法
2018-07-16 12:08陈卓恒胡亦钧
数学杂志 2018年4期
陈卓恒,胡亦钧
(1.华侨大学数学科学学院,福建泉州 362021)
(2.武汉大学数学与统计学院,湖北武汉 430072)
1 引言
变点问题起源于工业质量控制的领域,在质量控制中非常重要的一点是如何快速检测出生产线上不合格产品比例的增加.在建模和数据挖掘中,一个很常见的问题是,如何根据现有的样本数据,来判断我们感兴趣的一些量是否发生变化.这种问题在统计中我们称其为变点问题.关于变点问题的建模和分析始于Page 1954年发表在《Biometrika》上的文献[1],文献主要考虑了利用分位数构造的简单检测方法去检验生产线上观察到数据的稳定性.在此之后,关于变点问题的研究变得日益活跃,各种研究文献也日益增多.而且随着学科的发展和深入,变点问题在经济、金融学、生物医学、气候学、导航系统、图像处理、信号探测、计算机等很多领域都有广泛的应用背景.
很久以来大多数的变点检测的文献都是基于这样的背景:对于一组固定容量的历史数据集,我们设计一些检验方法来判断这组数据内我们感兴趣的参数是否发生变化.这种检验即为我们常说的“事后检验”.在这种检验中,样本是静态的,这种数据我们称为是离线数据.离线数据分析主要在譬如历史文本分析,图像分析等领域有应用.但是在更多的领域譬如质量控制,医疗监测,金融风险控制,我们使用的都是在线数据,也就是样本采取连续抽样的方式得到的.采取连续抽样的方式来得到样本进行检验,这种检验称为“序贯检验”.序贯检验也是最近几年变点检测中的研究热点.具体来说,在序贯检验中,一般假定静止期的长度为m,也就是在m个观察数据X1,X2,···,Xm内不存在变点,这m个观察数据也常称为历史数据.在考虑渐近性质的时候一般令m→∞.在原假设成立即认为没有变点存在的情况下Xm+1,Xm+2,···的参数是相同的;若备则假设成立即认为变点存在的情况下,则存在一个整数 k∗≥ 0,使得 Xm+1,Xm+2,···,Xm+k∗ 的参数与历史数据相同,而 Xm+k∗+1,Xm+k∗+2,···的参数不同,这里k∗为未知变点.接下来要做的就是如何构造合适的检验统计量并制定合理的停止规则,从而判断变点是否存在以及在认为变点存在的情况下推断出变点的位置,使得变点从产生到被检测出需要的时间尽量的短,并尽量消除误报,即快速准确检测出变点.
文献[2]是较早提出并研究变点检测中序贯检验的代表性文献之一,文中提出了两种检测方案,一种利用波动差,一种利用残差的累积和,并拓宽了经典的不变原理得到所需要的收敛结果,最后确定了临界值和停止规则,找到最优停时,并在模拟中得到了检验.文献[3]进一步推广了文献[2]的结果,同样对于线性回归模型,文献[3]提出了两类检验统计量,第一类统计量是建立在回归系数β取最小二乘估计时残差的加权累积和,第二类是利用回归系数构造的迭代残差的部分和得到的统计量.并制定了合适的检验规则,使得在历史数据个数m→∞时错误预报率在约定的水平内,且检验功效趋于1.学者Aue在变点的序贯检验中也做了一系列工作,譬如率先开展研究停止时刻τn的极限分布,得到了文献[4],后续工作有文献[5–7],另外文献[8]得到了在对ARMA时间序列中结构变点进行序贯检验时,停止时刻的极限分布.在近几年中,也有把自助抽样技术引入到序贯模型中的变点检测问题中,可参考文献[9,10]和[11].
目前来说,现有的文献主要研究单序列情形下的序贯模型,那么,如何在面板数据下研究序贯模型的变点,这是一个崭新的问题.在本文中,我们主要对这个问题进行研究.本文剩余部分的结构是这样的:第2节将描述模型并得到相关的理论结果,即检验统计量的大样本性质;第3节基于前面的理论结果提出面板数据下关于变点的渐近检验法,并进行了Monte-Carlo模拟计算;第4节给出了前面引理和定理的证明过程;第5节对前面的结论进行了总结.
2 模型及相关理论结果
考虑面板均值变点模型

这里 µij和 εij分别表示均值和面板扰动项.{µij,j=1,2,···,m+Tm}i和 {εij,j=1,2,···,m+Tm}i是相互独立的.Tm与m 有关而且假定Tm≤ ∞,序列{εij}关于i相互独立,εij∼ (0,σ2)且在概率空间(Ω,F,P)上关于j是独立同分布的(i.i.d.).假定0<σ2<∞而且对于某个υ>2有E|εij|υ<∞.
假定对于每个1≤i≤N,已经观察到长度为m的历史数据,它没有变点发生,即对于1≤i≤N,

现在我们感兴趣的是接下来到来的数据里是否存在均值发生变化的共同变点,即想检验原假设

和备则假设
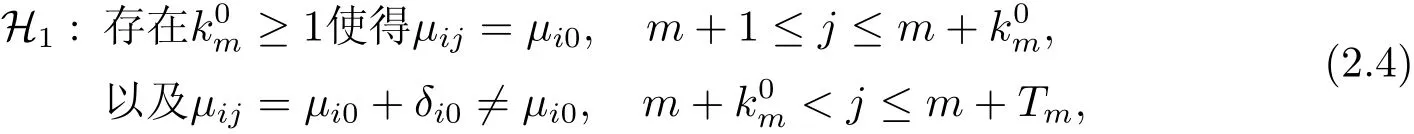
这里σ2,µi0,δi0,k0m的值均为未知.检测变点的方案是基于CUSUM型检测统计量Γ(m,k,N)和一个边界值,这里

此处


此外,基于历史数据集 {Yi1,Yi2,···,Yim}i=1,2,···,N使用以下的方差估计

关于检验法则,在

处停止并拒绝H0.τN(m)也被称为停时,而且这里的c应该被选择成使我们能够控制错误预报率.即在原假设H0下,对于某个给定水平0<α<1,

在备则假设H1下,要求

定理2.1对于面板数据模型(2.1),在原假设(i.e.(2.3)式)的假定下,当m,N→∞时,有
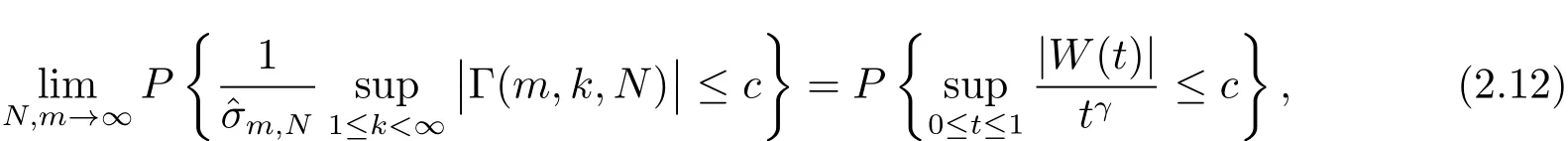
这里{W(t),0≤t<∞}是一个Wiener过程,γ见(2.6)式.

3 渐近检验法及其模拟计算
根据定理2.1知,在原假设成立即没有变点时,若m,N→∞时,

的极限分布为
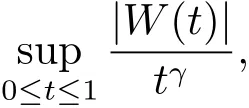
这里{W(t),0≤t<∞}是一个Wiener过程.因此可以通过此处已知的极限分布求出在给定的显著性水平下检验的临界值c,然后利用这里的临界值c以及检验法则来确定是拒绝还是接受原假设,并在原假设被拒绝,即认为变点存在的情形下估计出变点的位置.这种方法我们称它为“渐近检验法”.
关于渐近检验法,首先要计算检验的临界值.由于临界值只与γ有关,所以可记作cγ.为了计算经验检验水平,考虑一个不带变点的模型,并且计算

的次数,这样就得到了这个次数和Monte-Carlo模拟次数之比.进一步,为了计算经验检验功效,考虑带一个变点的模型,并进行M 次Monte-Carlo模拟.在这M 次模拟中,计算出检验统计量

超过临界值cγ的频率,然后来计算经验检验功效.同时,|Γ(m,k,N)|超过临界值cγ的最早出现的那个k被认为是变点位置的估计值.
一般来说,作为一个好的检验方法,经验检验水平应该小于或等于给定的水平,而且经验检验功效应该足够大.另外,在变点后的停时应该足够的短才好.因此首先按照定理2.1来计算临界值cγ.
第二步 在这M 次模拟的基础上,计算临界值cγ,使得P[Uγ>cγ]=α.

表1:由50000次Monte-Carlo模拟计算出的临界值cγ
接下来,在表2–8中,利用表1中计算出的临界值cγ,分别计算了在γ,Tm,N,m 取不同值,变点k0m在不同位置(左端,中间或右端)时,渐近方法的经验检验水平,检验功效以及停止时刻的各数字特征.具体来说:

表2:利用cγ经1000次Monte-Carlo模拟计算出的经验检验水平,N=200,Tm=500

表3:利用cγ经1000次Monte-Carlo模拟计算出的经验检验水平,Tm=500,m=100

表4:利用cγ经1000次Monte-Carlo模拟计算出的检验功效,N=200,Tm=500,k0m=25

表5:利用cγ经1000次Monte-Carlo模拟计算出的检验功效,N=200,Tm=500,m=100
从表2可以看出,当m固定时,随着γ的增大,经验检验水平越小.当γ固定时,随着m的增大,经验检验水平越小.从第一行和第二行的数据可以看到,当γ=0和0.25时,若历史数据集m较少,得到的经验检验水平是会超过给定水平的.从而可以考虑在[0,1/2)的范围内选取较大的γ,来降低检验犯第一类错误的概率.而m越大,即没有变点的历史数据越多,得到的经验检验水平越小,这与我们的直观感觉也是相符合的.
从表3可以看出,γ的大小对经验检验水平影响很大,类似表2的表现.当N 固定时,随着γ的增大,经验检验水平是降低的.在γ=0时,经验检验水平甚至超过了给定的水平.同时注意到,N的大小对经验检验水平的影响不大,不过比较而言,中等大的N似乎能产生相对较低的经验检验水平.
通过模拟得到的列出的,譬如表4,以及一些未列出的表格发现,当变点发生在m个经验数据之后不久时,则无论m和N 值如何变化,对于不同的α和γ,检验的功效都达到了1.
从表5可以看出,在变点k0m在m之后不久或者是更远一些,检验的功效都是1.但是,在变点靠近右端点时,检验的功效会降低,最高不超过0.35.在k0m固定时,随着γ的增大,功效是越来越低的.因此,基于检验水平和检验功效的考虑,应该选取不大不小的γ,譬如取γ=0.25,从而使两者能达到一种平衡.
表6:N=200,Tm=500,=25,模拟次数1000次计算出的停止时刻的各数字特征

表6:N=200,Tm=500,=25,模拟次数1000次计算出的停止时刻的各数字特征
γ m=30 m=100 τm ↓;α → 0.025 0.05 0.10 0.025 0.05 0.10 0 Min 9.00 8.00 6.00 26.0 16.00 13.00 Q1 28.00 27.00 27.00 28.0 28.00 27.00 Median 28.00 28.00 28.00 28.0 28.00 28.00 Mean 28.44 28.06 27.58 28.5 28.22 27.92 Q3 29.00 29.00 29.00 29.0 29.00 29.00 Max 32.00 32.00 31.00 32.0 31.00 31.00 0.25 Min 5.00 4.00 4.00 26.00 26.00 11.00 Q1 28.00 28.00 27.00 28.00 28.00 27.00 Median 28.50 28.00 28.00 29.00 28.00 28.00 Mean 28.51 28.17 27.73 28.53 28.27 27.94 Q3 29.00 29.00 29.00 29.00 29.00 29.00 Max 33.00 32.00 31.00 32.00 31.00 31.00 0.45 Min 26.00 20.00 10.00 27.00 26.00 26.00 Q1 28.00 28.00 28.00 28.00 28.00 28.00 Median 29.00 29.00 29.00 29.00 29.00 29.00 Mean 29.21 28.84 28.5 29.12 28.83 28.55 Q3 30.00 30.00 29.00 30.00 29.00 29.00 Max 33.00 33.00 32.00 32.00 32.00 31.00 0.49 Min 27.00 26.00 19.00 27.00 26.00 26.00 Q1 29.00 28.00 28.00 29.00 28.00 28.00 Median 30.00 29.00 29.00 29.00 29.00 29.00 Mean 29.57 29.17 28.88 29.47 29.12 28.83 Q3 30.00 30.00 30.00 30.00 30.00 29.00 Max 34.00 33.00 33.00 32.00 32.00 32.00
从表6看出,如果以停止时刻τm的中位数和均值作为判断标准的话,在γ固定时,m值的变化对停止时刻的影响不大,也就是说,对变点的估计值影响不大.但是,在m值固定时,随着γ的增大,变点估计值与真实值的偏差是越来越大的.
从表7可以看出,在N 固定时,随着γ的增大,变点值的估计偏差也是越来越大的,不过这些偏差的相差量不会很大,不超过1或者2.若γ固定,当N 从50变到300时,变点估计值的精确度明显提高了,在真实变点=25时,精确度提高了4∼5个值.从这里可以看出,增大面板数据的横截面个数N,是可以明显提高变点估计的精确度的.
表7:Tm=500,m=100,=25,模拟次数1000次计算出的停止时刻的各数字特征

表7:Tm=500,m=100,=25,模拟次数1000次计算出的停止时刻的各数字特征
γ N=50 N=300 τm ↓;α → 0.025 0.05 0.10 0.025 0.05 0.10 0 Min 23.00 8.00 8.00 26.00 12.00 10.00 Q1 30.00 30.00 29.00 27.00 27.00 27.00 Median 32.00 31.00 31.00 28.00 28.00 28.00 Mean 31.79 31.13 30.56 27.94 27.66 27.44 Q3 33.00 32.00 32.00 28.00 28.00 28.00 Max 41.00 40.00 39.00 30.00 30.00 30.00 0.25 Min 26.00 23.00 18.00 26.00 26.00 12.00 Q1 31.00 30.00 30.00 27.00 27.00 27.00 Median 32.00 31.00 31.00 28.00 28.00 28.00 Mean 32.08 31.52 30.98 27.99 27.78 27.58 Q3 33.00 33.00 32.00 28.00 28.00 28.00 Max 42.00 41.00 41.00 30.00 30.00 30.00 0.45 Min 27.00 27.00 26.00 26.00 26.00 26.00 Q1 32.00 31.00 30.00 28.00 28.00 27.00 Median 33.00 32.00 32.00 28.00 28.00 28.00 Mean 33.29 32.59 32.01 28.44 28.18 27.98 Q3 35.00 34.00 33.00 29.00 29.00 28.00 Max 45.00 44.00 42.00 31.00 31.00 30.00 0.49 Min 27.00 26.00 26.00 27.00 27.00 26.00 Q1 32.00 32.00 31.00 28.00 28.00 28.00 Median 34.00 33.00 33.00 29.00 28.00 28.00 Mean 34.14 33.30 32.65 28.75 28.45 28.21 Q3 36.00 35.00 34.00 29.00 29.00 29.00 Max 46.00 45.00 43.00 31.00 31.00 31.00
最后看下在N,Tm,m都固定,而变点在不同位置时,变点位置估计值的情况.在表8中,若=25,这种情形在前面已经探讨过.我们来看下=390,即变点处于右端点的情形.从表格中的数据可以发现,对于这种变点最好以变点的中位数而不是均值作为变点的估计值,因为中位数会离真实变点接近的多,估计的偏差在5到6之间.同时γ的大小与估计量的精确度的关系类似表7中的表现,在N固定时,γ越大,估计的偏差也会相对大一些.
通过以上表格的具体分析,发现参数γ该如何选取是个很有趣的事情.从表2看出,较小或者中等大的γ(γ=0,0.25)且m取较小或中等大(m=30,100)时,数据表明经验检验水平与给定的水平接近.类似地,在表3中,γ=0,N=100同样可使得经验检验水平接近给定的真实值α.我们再来看看参数γ与检验功效的关系.表4中的检验功效对应着变点较早发生的情形,这时,无论γ在区间取何值,对应的检验功效均为1.从表5看,在变点靠近右端点时,γ越小(其它参数都固定)时,检验功效越大.同样,对表6–8的模拟结果进行分析可知,越小的γ可使变点的估计值与真实值的偏离程度越小.根据以上这些分析,若从经验检验水平,检验功效以及变点估计的精确度三方面来综合考虑,我们倾向于选取区间中较小的γ,从而达到最佳的检验和估计效果.

表8:N=200,Tm=500,m=100,模拟次数1000次计算出的停止时刻的各数字特征
4 定理的证明
在这一节中,将给出所有引理和定理的证明.
引理2.1的证明 注意到

那么

而且

经过计算可得
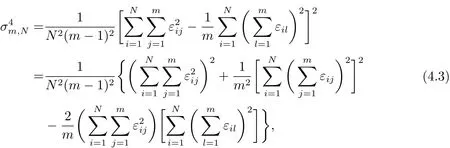
于是有
和
以及
由(4.2)–(4.6)式以及Chebyshev不等式,得到

定理2.1的证明 借用文献[3]中的思想来证明定理2.1.对于面板数据模型(2.1),在原假设(i.e.(2.3)式)下,注意到

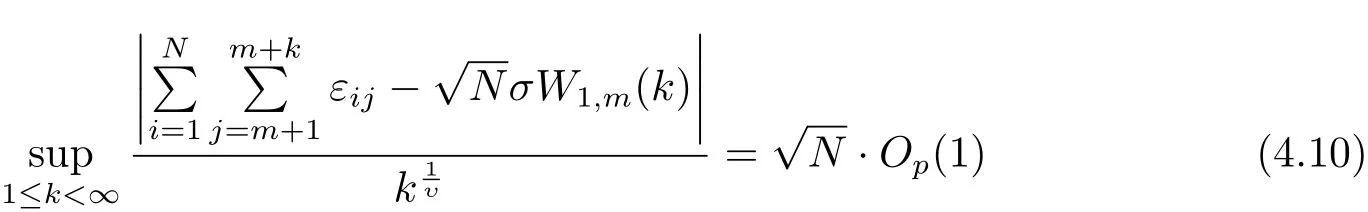
和

此处{W1,m(t)}和{W2,m(t)}是相互独立的Wiener过程,且v>2.从而推得

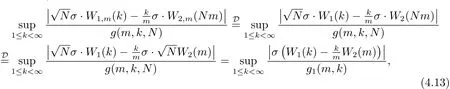
接下来,利用
由文献[3]中的定理2.1的证明,有

以及

于是定理2.1得到了证明.

由定理2.1以及Chebyshev不等式,得到

5 结论
本文针对面板数据的序贯模型下的可能变点,提出了CUSUM型检验统计量并制定了检验规则.随后得到了检验统计量的大样本性质,并基于相关理论结果构造了一种检验方法:渐近检验法.接下来,对渐近检验法进行了Monte-Carlo数值模拟,在模拟中对检验方法的经验检验水平,检验功效进行了考察,并在变点存在的情况下估计出变点的位置.模拟显示渐近检验法是一种优良的检验估计方法.最后给出了理论结果的证明.
猜你喜欢
能源工程(2022年1期)2022-03-29
数学物理学报(2021年4期)2021-08-30
湖北第二师范学院学报(2020年8期)2020-10-13
河南科学(2020年4期)2020-06-03
安徽师范大学学报(自然科学版)(2020年1期)2020-03-28
临床医药文献杂志(电子版)(2017年11期)2017-05-17
中国惯性技术学报(2016年5期)2016-12-23
中国塑料(2016年9期)2016-06-13
火炸药学报(2014年3期)2014-03-20
中国石油大学学报(自然科学版)(2013年6期)2013-03-11

- 数学杂志的其它文章
- RELATIONSHIPS BETWEEN VECTOR VARIATIONAL-LIKE INEQUALITIES AND MULTI-OBJECTIVE PROGRAMMING INVOLVING GENERALIZED ARCWISE CONNECTED FUNCTIONS
- NABLA-HUKUHARA DERIVATIVE OF FUZZY-VALUED FUNCTIONS ON TIME SCALES
- FROM LEIBNIZ SUPERALGEBRAS TO LIE-YAMAGUTI SUPERALGEBRAS
- ON THE UNIT GROUPS OF THE QUOTIENT RINGS OF IMAGINARY QUADRATIC NUMBER RINGS
- THE APPLICATION OF THE SECOND KIND CHEBYSHEV WAVELETS FOR SOLVING HIGH-ODER MULTI-POINT BOUNDARY VALUE PROBLEMS
- ON THE LOCAL WELL-POSEDNESS FOR THE KDVKS EQUATION