
汉语多位数词特点
2018-09-10 09:57彭家法
皖西学院学报 2018年4期
蔡 雨,彭家法
(安徽大学 文学院,安徽 合肥 230039)
汉语数词及相关应用研究范围十分广泛,前人较为重视研究数词文化的中外差异及汉外互译,如滕梅[1]、刘法公[2]、陈绂[3]、常敬宇[4](P40)等。朱德熙对汉语数词结构和数词特点作了开创性的研究[5]。本文尝试在前人研究基础上进一步研究汉语多位数词特点并运用系统性原则对相关特点作出解释。
一、汉语数词与其他语言数词的对比
沈家煊说:“一种语言的特点必须通过跟其他语言的比较才能看出来,这是毋庸置疑的。我们在讲汉语的特点的时候,往往是通过跟印欧语、特别是英语的对比。”[6]所以我们首先来对比着看汉语和英语中的数词特点。汉语中的数词和英语中的数词有很多不同,主要表现在以下几点。
(一)汉语和英语数词结构的分级各不相同
汉语数词采用四位分级制,从个位起,每四个数位为一级。个位、十位、百位、千位是个级,表示的是多少个一;万位、十万位、百万位、千万位是万级,表示多少个万;亿位、十亿位、百亿位、千亿位是亿级,表示多少个亿。英语采用的是三位分级法,从个位起,每三个数为一级,并且用逗号隔开,逗号从右到左依次表示为thousand(1000),million(1000000),billion(1000000000),trillion(1000000000000)。比如数词“6087900680”在汉语中可以表示为“60/8790/0680”,个级是“680”,万级是“8790”,亿级是“60”;在英语中则可以表示为“687,900,680”,个级是“680”,thousand级是“900”,million级是“687”。
由于读数分级不同,导致了不同语言计数方法的差异。具体来说,汉语中数词的计数单位是“个、十、百、千、万、亿”这些单位都是“十”的倍数。朱德熙说“十、百、千、万、亿”是位数词[5],即计数单位,并且他还认为应该把“两万万”分析为“两/万万”而不是“两万/万”,因为一旦分析为第二种“两万/万”,那么在“两万万两千万”里,“两万万”和“两千万”的位数都是“万”,这显然是不合理的。所以朱德熙认为“万万”也应该算位数[5],也是汉语数词的计数单位。而在英语的数词表达中,数词十对应的是“ten”,百对应的是“hundred”,千对应的是“thousand”。万则以千的倍数来表示,在英语中对应的是“十个千”即“ten thousand”;十万也以千的倍数来表示,在英语中对应的是“一百个千”,即“one hundred thousand”。百万对应的是“million”;千万用百万的倍数来表示,在英语中对应的是“十个百万”即“ten million”;亿(万万)也用百万的倍数来表示,在英语中对应的是“一百个百万”即“one hundred million”。十亿和万亿则分别有专门的单词来表示即“billion”和“trillion”。由此可见,在英语中找不到可以和汉语中的“万”“亿”直接对应的单词;汉语也没有million(1000000),billion(1000000000),trillion(1000000000000)对应的语素。用库藏类型学的术语就是,“万”“亿”是汉语的库藏,“million”“billion”“trillion”是英语的库藏,两者并不对应[7]。
(二)汉语和英语数词结构中“0”是否读出存在差异
朱德熙说系位构造是由系数和位数两部分组成的复合数词,两部分之间是相乘的关系[8](P45)。几个系位构造按照位数由大到小顺序排列造成的数词结构叫作系位组合。朱先生特别指出:两个不连续的系位构造组合时,当中要补一个“零”,例如“一千零八,五万零三百零三”。我们就数词“1808000”为例来说明。如果我们看“万”和“千”,那么1808000就是由两个连续的系位构造组合的,中间不需要补“零”,即读作“一百八十万八千”;如果看“百万”“十万”“万”和“千”,那么1808000就是由两个不连续的系位构造组合的,就要补“零”即“一百八十万零八千”。但是上文已经提到,朱德熙[8]所认为的计数单位即位数词只有“十”“百”“千”“万”“万万(亿)”,不含“十万”“百万”“千万”,所以1808000就是由两个连续的系位构造组合的,中间不需要补“零”就读作“一百八十万八千”。
除此之外,国内各版本小学数学教材中对多位数读法的规定基本一致。如人民教育出版社《小学数学(四年级上册)》指出:计数单位按照一定顺序排列起来,它们所占的位置叫作“数位”,分别是:个位、十位、百位、千位,万位、十万位、百万位、千万位,亿位……[9](P14)。按照我国的计数习惯,从右边起,每四个数位是一级,称为“数级”,个位、十位、百位、千位为个级,万位、十万位、百万位、千万位为万级,亿位、十亿位、百亿位、千亿位为亿级。含有两级的数先读个级,再读万级;万级的数,要按照个级的数的读法来读,再在后面加上一个“万”字;每级末尾不管有几个0,都不读0,其他数位上有一个0或连续几个0,都读一个0。又如《小学生学习实用词典(数学)》中规定:万以上数的读法:先从右往左,每四位分为一级,再从高位起一级一级往下读;读亿级或万级的数,先按照个级数的读法读,再在后面加上一个“亿”或“万”字;级中间有一个0或连续几个0都只读一个“零”;每级末尾不管有几个0,都不读[10](P85)。但是,也有些图书里面多位数的读法稍有差异。比如在《锻炼学生创造力的智力游戏策划与项目》这本书里有这样一段话“唐僧又写出:130567。孙悟空马上说:‘这太容易了,读作十三万零千五百六十七。’唐僧又摇了摇头,说:‘遇到0,要特别注意,当一串数中间有0时,只要读零就可以了,它后面的数位不要读出来。所以这个数应该读作十三万零五百六十七。’”[11](P55)也就是说,这些书里并没有提到“分级”这个概念,只要是数词中的“0”,不管有几个,都要读出一个。但总的来说,汉语数词中间的“0”是要读出一个的,每一级末尾的“0”是不需要读出来的。那么英语数词中间的“0”如何表达呢?我们据搜集的相关资料做一番考察。
英语中数词的读法与汉语有很大区别。章振邦《新编英语语法教程》中对数词的读法作了详细的说明并且给出了例子[12](P65),我们主要来看下列例子:
230,000,032 two hundred and thirty million and thirty-two
689,000,001 six hundred and eight-nine million and one
111,654,400 one hundred and eleven million six hundred and fifty-four thousand four hundred
8,000,000,000 eight thousand million/eight billion
从例子中我们可以看出,英语中不管是数词中间的“0”或者是数词末尾的“0”都不用读出,这与汉语确实有很大不同,汉语数词某些位置的“0”必须读出。
(三)汉语和英语数词结构中位数是否省略存在差异
在汉语中,位数是否省略有以下几种情况:1)数词个位上的单位“个”可以省略,如“三万零八”;2)两个连续的系位构造组合时,靠后的系数位数可以省略不读,如“三万八千”可以读为“三万八”;3)两个不连续的系位构造组合时,靠后的系数单位(位数)不可以省略,如“三万零八百”不能读为“*三万零八”。朱德熙特别指出:连续的系位构造的末一项的位数可以略去不说[8]。例如“五百二(十),一万三千六(百)”。
而在英语中也有很大区别,仍用上述例子来说明:
230,000,032 two hundred and thirty million and thirty-two
689,000,001 six hundred and eight-nine million and one
分析例子我们发现,英语数词的位数跟汉语相比,除了没有个位上的单位“个”之外,还有一个重要不同,即英语中只要是存在的位数都要读出来,无论是否出现在末尾。
综上所述,汉语中的数词与英语中的数词主要有三点不同:数词分级不同、是否读“0”存在差异和是否省略单位存在差异。这三个特点是相关的,体现出语言的系统性:由于汉语允许某些位置读“0”,所以允许省略单位;由于允许省略单位,所以允许某些位置读“0”;哪些位置读“0”,是由汉语数词四位分级的特点决定的。
这样,我们可以把汉语和英语数词的差异用下面的方式表示:
60 / 8709 / 0680
↓ ↓
亿 万
读作:六十亿八千七百零九万零六百八。
6 , 087 , 090 , 680
↓ ↓ ↓
billion million thousand
读作:six billion eighty-seven million ninety thousand six hundred and eighty.
我们还把汉语数词和韩语、日语数词作了对比。韩语读法如下:

三万八千

三万零八
日语读法如下:
38000: さんまんはっせん
san man ha sei
三万八千
三万八千
30008: さんまんはち

三万零八
经过比较,本文发现在韩语日语中也是存在着“万”这个计数单位的。但是韩语日语与汉语也有很大区别,第一,韩语日语的数词中所有的“0”都不会读出来;第二,在位数的省略方面,韩语日语中除了个位上的单位“个”可以省略之外,其余位数都不可以省略。而汉语某些位置需要读“0”,同时存在位数省略规则。
除此之外,笔者还对其他语言数词的读法做了一些调查,调查发现除了英语之外,西班牙语、俄语和蒙古语的数词里都是没有“万”这个单位的:
西班牙语读法如下:
38000:

三十连接词八千
三万八千
30008:

三十千 八
三万零八
俄语读法如下:
38000: тридцать восемьтысяч
tritzad vosem tisach
三十八千
三万八千
30008: тридцать тысяч восемь
tritzad tisach vosem
三十千八
三万零八
蒙古语读法如下:
38000:
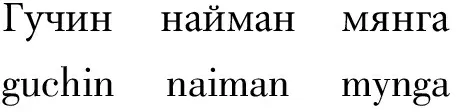
三十八千
三万八千
30008:

三十 千 八
三万零八
调查发现,韩语、日语、蒙古语、俄语、西班牙语的数词和英语数词是一样的,不会读出数字中间的“0”,并且不会像汉语一样省略最末尾的位数,比如在日语和韩语的数词中,“三万八”和“三万八千”是不一样的。但汉语数词除了跟韩语日语相同采用四位分级之外,还具有两个特点:第一,必须读出数字中间某些位置的“0”(级中间而不是级末尾有一个或连续几个0都读一个“零”);第二,可以省略最末尾位数,所以“三万八”就是“三万八千”。
二、优选论与汉语中含“0”多位数的不同读法
上文已经粗略地提到了汉语中大数词读法的相关规则,但是在研究过程中,我们发现一个奇怪的现象,即便都是中国人,都受过类似的中国式教育,可是在大数词的读法上面仍然存在着一个很大的差异,那便是关于数词“0”在大数词中的读法。仍然用上文中的例子“1808000”来说明,我们发现,一部分人读作“一百八十万八千”,但是也有相当一部分人读作“一百八十万零八千”。为了更深入研究,我们做了一份针对以汉语为母语的人群的调查问卷,问卷如下:
汉语含“0”多位数读法调查
选择题(可多选)
1.18000读作( )
A.一万八千 B.一万八
2.10800读作( )
A.一万八百 B.一万零八百
3.108000读作( )
A.十万八千 B.十万零八千
4.1008000读作( )
A.一百万八千 B.一百万零八千
5.10008000读作( )
A.一千万八千 B.一千万零八千
本次问卷的有效填写人次共计59人。我们用SPSS卡方独立性检验将五道题的统计结果进行独立性检验,首先我们给出零假设H0:汉语含“0”多位数的读法习惯与学生的专业年级无关。
根据统计得到最后数据,我们得到五道题的X2的统计量均小于自由度df为4的X2的临界值,所以我们接受零假设:汉语含“0”多位数的读法习惯与学生的专业年级无关。
其中,第3题统计结果显示只选择A选项的人数和只选择B选项的人数以及同时选择A和B的人数都比较接近只得出了一个模棱两可的结果。第4题和第5题的统计结果和第3题的统计结果相似,但是选B的频次有所增加。
这是什么原因呢?访谈发现实际上有两个规则,上文已经提到汉语关于数词“0”在多位数中的读法有两个规则在起作用,即:汉语数词四位一级,每级中间有一个0或连续几个0都只读一个0,每级末尾不管有几个0都不读。我们把它命名为“规则一”。不管分级,一个数词中间只要有0就要读出来。我们把它命名为“规则二”。
我们认为汉语数词的两个规则存在一种“优选”的过程,需要用“优选论”(Optimality Theory)来解释说明。
优选论是90 年代出现的一种新的音系学理论。最初系统地提出这一理论的是McCarthy &Prince[13](P451)。之后优选论被大量运用于生成句法学。Grimshaw把优选论的核心归纳为以下四点[14]:
(1)制约条件是普遍的(universal)。
(2)制约条件可以违反。
(3)不同语法是制约条件的不同排列的结果。
(4)优选项是合句法的,其他的都是不合句法的。
根据McCarthy & Prince的假设[13](P451),衍生模也就是生成装置(generator,简称Gen.)是普遍语法的组成部分,固定在每一种语言里,它的作用是为特定的输入项(input)制造在数量上无限的表层表达形式,优选论把它们称为候选项集合(set of candidates),所有的候选项必须经过制约条件层级体系的评估(evaluation)和选择(selection),看哪一个候选项能够最大限度地满足制约条件体系的要求和限制。经过评估,最大限度地满足制约条件的候选项就被确定为优选项(optimal candidate, optimal output, optimal form),也就是符合语法的那一项被输出。所以,制约条件和制约条件的层级排列是优选论的核心概念。
根据优选论的假设,制约条件在不同的语言中有不同的排列模式。没有明确规定层级之分的制约条件在同一种语言中的不同使用者的语感中也存在不同的排列模式。熊仲儒在研究汉语主语选择时曾经指出:“母语说话者的语感差异是客观存在的,像不同的语言之间可以存在差异一样。”[15]
为何在同是中国人又接受过相似的义务教育的前提下,汉语多位数的读法还是会有差异?本文认为这一现象可以在优选论的理论框架下来进行解释。我们仍然以1808000为例来说明。上文我们已经描述过规则一和规则二,现在我们就将规则一与规则二看作两个制约条件,将其放入评选模中,下表反映了两种结果。表中的符号是借鉴国外已经发表的相关优选论的论文,“*”表示对规则的违反,“”表示优选项。

表1 将规则一排列在规则二之上的使用者
表1中,使用者认为规则一高于规则二,所以对规则一的违反比对规则二的违反更加致命,即认为分级更重要,从而得出优选项“一百八十万八千”。

表2 将规则二排列在规则一之上的使用者
表2中,使用者认为规则二高于规则一,所以对规则二的违反比对规则一的违反更加致命,即认为读零更重要,从而得出优选项“一百八十万零八千”。
在汉语多位数的读法中,规则一和规则二一直以来都有着很大的竞争,在义务教育阶段,由于老师授课方式的不同,生活中与多位数接触频率的不同,导致了不同使用者的语感也有所区别,最终决定了多位数不同的读法。
三、相关应用
本研究在多方面具有应用价值。汉语数词相关规范、中小学教育、对外汉语教学、辞书编写等方面应该反映汉语数词特点。
国家标准《出版物上数字用法的规定》指出“非科技出版物中的数值一般可以‘万’‘亿’作单位。示例:三亿四千五百万可写成34500万或3.45亿。”“数值巨大的精确数字,为了便于定位读数或移行,作为特例可以同时使用‘万’‘亿’作单位。示例:我国1982年人口普查人数为10亿817万5288人。”这种规定就充分注意到汉语特点,体现了区分适用场合和使用人群的规范原则。科技文献、用于国际交流可以采用“每三位数字一组”的写法。非科技出版物、面向汉语人群则应该使用“万”“亿”汉语单位而不采用“每三位数字一组”的写法,比如写成“34500万”“3.45亿”或“3亿4500万”;不宜写成“345,000,000”,这样写不仅不便于理解,不便于“定位”,还给汉语使用者理解带来障碍。
我们注意到目前中小学教育中已经停止采用“每三位数字一组”的写法,人民教育出版社等很多教材中介绍了汉语每四个数位是一级的“数级”概念,这种处理对汉语儿童学习多位数词读写无疑会起到很好的促进作用。但是我们也注意到由于师资力量不足,很多学生还没有得到很好指导,不能充分汉语“数级”特点,有待汉语研究和中小学教育工作者进一步努力。
外国留学生初学汉语时常常会出现“*十千”这样的偏误。有首歌叫作《一万个伤心的理由》,留学生会说成《*十千个伤心的理由》,待老师讲解留学生了解了“万”的使用方法之后,他们才能正确使用。无疑这种偏误是由于留学生没有掌握汉语多位数词四位分级这一特点,将母语三位分级迁移到中介语中造成的。再观察韩国留学生使用汉语数词的偏误(以下偏误均来自于安徽大学国际教育学院中级二班的韩国留学生):
10800:*一万八百(应该为“一万零八百”)
1080: *一千八十(应该为“一千零八十”)
10080:*一万八十(应该为“一万零八十”)
很显然,韩国留学生在读数词的时候正确掌握了汉语四位分级的特点,可是在是否读“0”这一方面出现了偏误,这也是学习者未能掌握汉语数词特点(某些位置的“0”必须读出)导致的。汉语教师要充分认识汉语多位数词特点,采取必要措施纠正这种偏误,帮助学习者尽快习得汉语特点。
四、结语
通过与其他语言的对比,我们不仅发现数词在各国语言中的库藏有所差异,也发现了世界语言在系统性方面表现出的共性。刘丹青提出应该研究语言库藏类型学[16]。句法制图理论认为虽然不同语言的功能语类是显性还是隐性实现可能存在不同,同时不同语言可能会存在不同的“移动”(movement)从而导致语言成分显性位置的差异,但是不同语言也存在共性(Cinque and Rizzi[17],彭家法[18])。本文汉语多位数词研究显示,语言研究不能只局限于狭隘的个别语言个别现象研究,需要有一定的系统观念和宏观视野,进一步分析语言库藏和相关结构句法制图中的共性和差异,这样才有可能真正发现语言机制和汉语特点。
猜你喜欢
小学生学习指导(低年级)(2021年3期)2021-07-21
小学生学习指导(低年级)(2021年6期)2021-07-19
读写算·小学中年级版(2017年8期)2017-08-09
新课程(2016年3期)2016-12-01
新高考·高二数学(2015年4期)2015-08-20
对联(2011年24期)2011-09-19
对联(2011年22期)2011-09-19
阅读(中年级)(2009年5期)2009-06-23
数学大世界·小学中高年级辅导版(2009年4期)2009-05-04
学苑创造·B版(2009年12期)2009-01-15
