
基于链路选择学习算法的无设备目标定位
2018-11-05 03:43金杰柯炜陆俊王彦力唐万春
电波科学学报 2018年5期
金杰 柯炜,2 陆俊 王彦力 唐万春,2
(1.南京师范大学物理科学与技术学院,南京 210023;
2. 江苏省地理信息资源开发与利用协同创新中心,南京 210023)
引 言
无设备目标定位(device-free localization, DFL)一般是通过在待检测区域周围设置若干无线收发节点来实现.无线节点间能够相互通信,在空间内形成许多无线链路,当一个目标进入该区域,便会衰减一部分链路,相应的这一部分链路的接收信号强度(received signal strength,RSS)值也会发生变化.因此,可以通过RSS值的变化来获得目标的位置信息.文献[2-3]中将DFL问题建模成一个机器学习问题并通过指纹匹配的方法将其成功解决,它通过当前链路测量值与训练数据库进行比较来估计目标位置.受计算层析成像算法的启发,文献[4-7]中将DFL问题转换成无线电层析成像问题,并使用正则化的方法进行求解.随后,Wang J等人将DFL推广到多维测量条件[8],并通过改进阴影衰减模型进一步提高了DFL的定位精度[9-11].常俪琼等人针对环境噪声对链路接收信号的影响提出了一种能够有效消除环境噪声的DFL方法[12];刘凯等人也就射频层析成像(radio tomographic imaging, RTI)方法的实时性问题提出了自己的改进方法[13].
随着压缩感知(compressive sensing,CS)[14-15]的迅速发展,根据目标的空间稀疏性,文献[16]将DFL成功建模成一个稀疏信号重建问题并提出了一种贪婪匹配追踪(greedy matching pursuit, GMP)算法来解决.GMP算法通过排查部署区域里所有位置来确定目标,但是如果部署区域太大,其计算复杂度也会大大提高,并不适用于实时定位.在GMP的基础上,文献[17]提出了贝叶斯贪婪匹配追踪(Bayesian greedy matching pursuit, BGMP)算法,充分利用先验条件加速了算法并过滤了部分误差位置,在运算速度和定位精度上都有了一定提高.
上述这些方法虽都成功地将CS应用到DFL,但由于CS模型中所采用的权重字典都是基于经验模型构建,与实际情况往往存在偏差,所以定位性能达不到预期的效果.针对权重字典的模型误差,文献[18-19]都提出了采用字典学习的算法来纠正原权重字典的模型误差.
此外,在DFL求解目标位置时,传统做法是将无线传感网中的所有链路的变化情况都考虑进计算,然而实际情况是目标仅会遮挡、衰减一部分的链路.如果计算所有链路的变化情况不仅会导致冗余的计算步骤,影响DFL系统的实时性,而且也会因为计算误差的累积和“无关”链路的扰动误差导致定位误差.
本文针对上述两方面问题,提出了一种基于链路选择学习(link selection learning,LSL)的DFL算法.不同于文献[18-19]中的字典学习方法,该算法在更新字典的过程中,不仅纠正了原权重字典的模型误差,而且结合位置的物理空间信息,完成了有效链路选取,实现了对字典维数的压缩以及对野值目标位置的过滤.
1 系统模型及问题描述
本节,我们首先介绍将RSS测量值与目标空间位置关联起来的CS系统模型,再讨论字典不匹配以及链路选取问题.
1.1 系统模型
假设定位区域周围布置了L个无线节点,并且将定位区域划分为N个网格,可以形象地将这些网格称为“像素”.假设区域中有K个待检测目标,如果网格足够密集,那么每一个目标都可以保证有一个像素点与它对应.如果K≪N,离散空间域中的目标位置可以精确地表示为稀疏向量x.如果目标位于定位区域的相应位置,向量x中对应位置的元素则有非零值,而向量x中其他元素等于零.如上所述,可将DFL转换为在稀疏向量x中确定非零元素及其特定位置的问题.则稀疏定位模型可以表示为
y=Dx+n.
(1)
式中:y是RSS测量值向量;D为权重字典;n为测量噪声.传统的做法是通过经验模型构建固定的权重字典D,再通过CS重构算法求解稀疏向量x,从而得到目标的位置信息.
1.2 问题描述
对于DFL问题中的权重字典,传统做法都采用一个固定的模型来描述.最常用的为椭圆模型[4],该模型假设目标只对链路所在直线为直径的椭圆区域产生影响,当像素中心到两个节点的距离的和大于椭圆直径加上短轴长度时,判断该像素有权值.根据该方法,权重字典中的元素Dij可表示为

(2)
式中:dij为节点i到节点j的距离;di、dj分别为像素中心到节点i和节点j的距离;ρ为椭圆的短轴长.该模型假设权重值与链路的长度成反比,缺乏理论依据,并且一个椭圆内所有格点对应的权重相同也不符合实际.因此,基于椭圆模型构造的字典D与实际字典D0之间不可避免地存在误差.为清楚起见,用一个误差字典矩阵Γ来描述数学解析字典与理想字典之间的差异,则CS框架下的稀疏定位模型可以表述为
y=Dx+n=(D0+Γ)x+n.
(3)
值得注意的是,误差矩阵Γ不仅是未知的,而且随着时间和环境的变化而变化.由于模型字典D与理想字典D0之间存在不匹配,所以在稀疏恢复过程中出现误差是不可避免的.为了获得准确的定位结果,本文算法采用自学习的方式来训练字典,减轻模型误差.
在解决DFL问题时,如何选择受到目标影响的有效链路也是影响定位结果的一个重要因素.传统的做法是考虑无线传感网(wireless sensor network, WSN)中所有链路的变化情况,如参考文献[4-7],或者为了满足CS扁矩阵的要求,随机选取一定的链路数参与计算[16].考虑所有链路的变化情况,不仅会导致冗余的计算步骤,影响DFL系统的实时性,而且也会因为计算误差的累积和“无关”链路的扰动误差导致定位误差.而随机选取一定的链路参与计算,则会因为有时链路选择的不准确性,导致较大的定位误差.为了规避两种链路处理方法的弊端,本文算法根据移动目标的位置相关性,在字典更新的同时,完成对参与计算链路的选取,不仅压缩了字典维度,加速了算法,而且也滤除了部分野值目标位置.
2 LSL算法
本节详细介绍LSL算法,算法包括两个阶段:训练阶段和定位阶段,如图1所示.在训练阶段中我们同时完成字典更新以及链路选择,得到降维后的匹配字典;在定位阶段,使用修正后的匹配字典作为权重矩阵,进行稀疏重构.
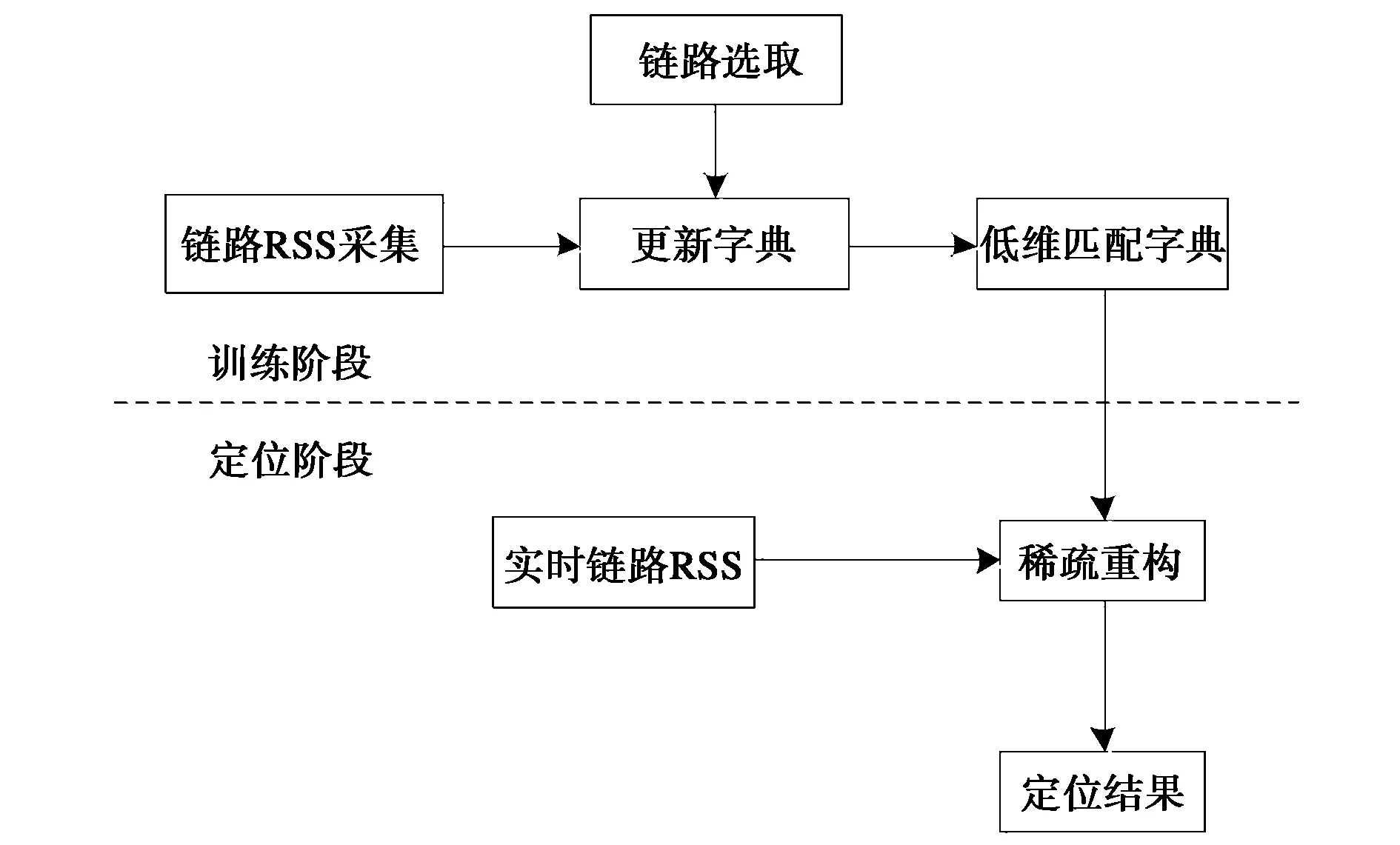
图1 LSL算法流程图Fig.1 Flowchart of LSL algorithm
2.1 训练阶段
2.1.1 字典学习
1996年,Olshausen发表了著名的Sparsenet字典学习算法[20],该算法奠定了字典学习理论的基础,随后许多改进的字典学习算法也相继出现了.Lee等提高了Olshausen字典学习算法的速度[21];受广义聚类算法的启发,Engan等对Olshausen的Sparsenet字典学习算法进行了改进,提出了最优方向(method of optimal directions, MOD)字典学习算法[22];为减小MOD算法的复杂度,Aharon等又提出了逐列更新字典的KSVD算法[23].本文借鉴上述字典学习的思路,对模型字典进行更新.
由于有L个无线节点,一共可以组成M=(L-1)L/2条无线链路,这意味着一次测量可以得到M维的测量矢量yi=[y1,y2,…,yM]T.考虑到训练要求,我们一共采集P个这样的测量矢量,组成训练矩阵Y;其对应的稀疏矢量xi(i=1,2,…,P)组成稀疏矩阵X.根据字典学习理论,要寻找权重字典的最优表示D,我们仅需求解

(4)
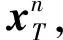


(5)
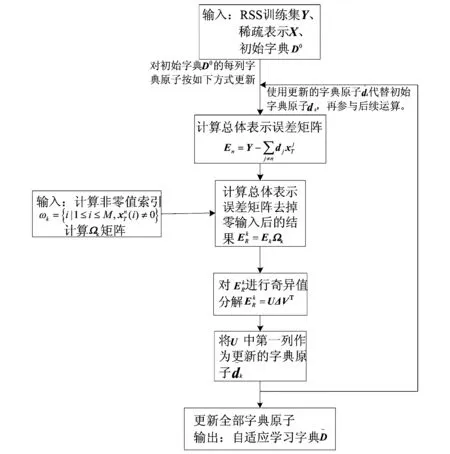
图2 LSL算法字典学习阶段流程Fig.2 Dictionary learning stage process of LSL algorithm
式(5)中,DX被分解为N个秩为1的矩阵的和,假设其中N-1项都是固定的,剩下的第n列就是需要处理更新的.矩阵En表示去掉原子dn的成分在所有N个样本中造成的误差,称为误差矩阵,如下所示:

(6)

(7)


(8)

2.1.2 链路选取
为了加速字典学习过程,同时消除野值链路的影响,提出一种链路选取方法.根据移动目标的时空相关性,可以依据目标上一时刻位置来判定下一时刻目标可能出现的区域,仅选取通过该先验区域中的链路参与计算.
假设目标初始位置位于像素j处,下一时刻目标可能出现的位置一定是在以像素j为圆心,半径为h的圆内.半径h设置如下:
h=Vmax×tint.
(9)
式中:Vmax为定位目标的最大速度;tint为两次定位算法运行的时间间隔.由于目标只可能出现在先验区域内,因此只有经过先验区域的链路才可能真正被目标所影响.为了判断链路是否经过置信区域,可以将链路看作一条直线,于是上述问题便转化为直线是否经过圆的数学问题.如图3中节点6到节点19的链路所示,要判断该条链路是否经过置信区域,只需判断圆心到直线的距离H是否小于圆的半径h.由于在DFL问题中,像素点到无线节点的距离及无线节点间的距离都是容易获得的,因此对于这个问题我们可以根据海伦公式和三角形面积公式很方便地求得H,即
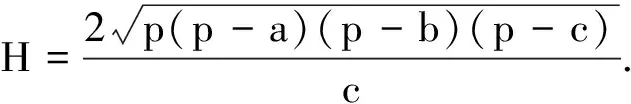
(10)
式中:a、b、c为三角形的三边长;p为三角形的半周长;H为三角形c边上的高.凡是满足H 但对于边界链路,这种判定方法会产生误判,如图3中节点4到节点5的链路所示.从图上直观地看到,从先验区域圆心处到无线节点4、5之间链路所在直线的垂直距离明显小于先验区域半径,但节点4到节点5这条链路却不经过先验区域.不过,由于DFL通常只考虑边界内的目标定位,目标出现在边界上的特殊情况实际中一般不会出现,因此边界链路可以直接排除,所以并不影响上述链路选取方法. 图3 链路选取Fig.3 Link selection 在完成训练阶段后,我们得到一个更新后的匹配字典;稀疏恢复阶段,我们用该字典替代原始权重字典,并从链路索引表index中挑选对应的RSS变化值,最后使用CS稀疏重构算法求解目标位置.文献[16]中提出了一种BGMP算法得到了较好的定位效果,因此本文也延用了这种方法. 为了体现本文提出算法的性能,本文分别在室外和室内环境下进行实验验证.为了便于与文献[17]的结果进行比较,其中室外实验数据采用犹他州大学SPAN实验室提供的数据;室内实验数据则由本实验室搭建的DFL系统测量得到.实验中,我们先采集目标在各个位置处的RSS值作为训练数据,根据本文所提的链路选择学习方法,自适应学习得到匹配字典;再使用匹配字典以及实时采集的RSS数据,求解目标位置.另外,参考文献[24]的做法,不失一般性,我们假设目标的初始位置是已知的,首先保证了起点不会出现偏差,但为了保证统计结果的有效性,起点位置坐标不参与统计. 3.1.1 实验设置 室外实验直接采用SPAN实验室提供的数据进行[数据来源:http://span.ece.utah.edu/rti-data-set].该实验的定位区域大小为6.3 m×6.3 m,在定位区域边缘以0.9 m的间隔共部署了28个无线节点,为了与文献[17]中的方法进行比较,本文也将区域划分为49个小网格,数据集给出了目标位于其中35个参考位置的RSS值,即P=35,并且数据集中也给出了采集这35个参考位置数据时目标的移动轨迹,如图4所示(我们可以根据移动轨迹来进行链路选取).其他参数设置如下:初始字典采用椭圆模型构造,链路选择区域阈值设置为h=1.5 m. 图4 室外实验目标移动轨迹图Fig.4 Target track map of the outdoor experiment 我们将所提LSL算法与文献[17]中所提算法进行比较,将文献[17]所提算法记为算法A,为了比较不同算法间的重构性能差异,还与最小化l1范数算法进行了比较,将其记为算法B.我们采用真实位置和估计位置之间的均方误差作为评估算法定位精度的标准. 3.1.2 实验结果分析 为了直观反映定位效果,本节先给出目标在一个位置的定位结果对比图,然后给出统计分析结果. 图5为当目标位于(0.9,2.7)m位置时,三种算法的定位结果比较.可以看到:算法B效果并不理想,不仅目标估计位置与真实位置间相差较大,并且会伴随有伪目标的情况;而算法A对于某些位置的目标定位结果会出现一至两个格点的偏差,如图5(a)所示;而本文算法能够实现准确的定位. (a) 真实位置(单位:m) (b) 算法A定位结果 (a) Real location(m) (b) Location result of algorithm A (c) 算法B最小化定位结果 (d) LSL定位结果 (c) Minimized location result of algorithm B (d) Location result of LSL 图5 室外环境三种算法定位结果对比Fig.5 Comparison of positioning results of three algorithms in the outdoor environment 图6给出了在单目标情况下,本文算法和算法A、算法B的定位误差累积概率分布图.由于划分的像素点的尺寸为0.9 m,并且当目标位于某个像素点时,都默认为该目标在这个像素点的中心位置,因此,定位误差的累积分布函数图会呈现折线的形状.从图中可以看到,由于LSL与算法A最大定位误差较小,所以累积分布函数图呈现一种陡峭的上升趋势.而LSL相比于算法A其优势体现在,由于学习字典不仅纠正了传统权重矩阵的模型误差并且也过滤部分误差位置,从而使得绝大部分点都能够准确定位.定位误差的详细统计结果如表1所示,我们可以看到,本文所提的LSL算法在室外环境下,定位平均误差以及均方根误差上都有米级以上的提升. 图6 室外环境三种算法定位误差的累积分布函数Fig.6 CDF of three algorithms in the outdoor environment 表1 室外环境定位误差对比Tab.1 Comparison of positioning error in the outdoor environment 3.2.1 实验设置 室内实验在南京师范大学行健楼一楼大厅进行,实测环境布局如图7所示,该定位环境三面为砖墙,一面为全玻璃墙面.实测数据采用的是TI CC2530无线节点,采用IEEE802.15.4协议和2.4 GHz频率.此实验定位区域为5 m×5 m,在区域边缘以1 m的间隔共部署了20个无线节点,我们将该定位区域以1 m为边长划分为25个小网格点.采集目标位于各位置时的RSS数据,并记录目标移动轨迹,如图8所示. 图7 室内实验环境Fig.7 Indoor experiment environment 图8 室内实验目标移动轨迹图Fig.8 Target movement track map of indoor experiment 3.2.2 实验结果分析 图9为当目标位于(1,1)m位置时,三种算法的定位结果比较. (a) 真实位置(单位:m) (b) 算法A定位结果 (a) Real location(m) (b) Location result of algorithm A (c) 算法B最小化定位结果 (d) LSL定位结果 (c) Minimized location result of algorithm B (d) location result of LSL 图9 室内环境三种算法定位结果对比Fig.9 Comparison of positioning results of three algorithms in the indoor environment 从图9我们可以得出和室外环境一致的结论:本文所提的LSL算法,能够有效修正原传统权重字典的模型误差,并且能够过滤部分误差位置,因此对于大部分目标位置都能够实现较准确的定位.现给出在室内情况,目标位于各个位置,多次实验的统计结果(其中每个位置我们都进行了110次实验):图10为在单目标情况下,本文算法和已有算法的定位误差累积概率分布.本文算法,无论是能准确定位到目标点的概率,还是最大定位误差,都优于其他算法.本文算法在定位精度上有较大幅度的提升.室内环境定位误差的详细统计结果,如表2所示,本文所提算法相比算法B在平均误差上提高了1.9 m左右,相比算法A平均误差大致提高了0.5 m;所提LSL算法的均方根误差也相比算法B、算法A,分别提高了29.7%和14.5%. 图10 室内环境三种算法定位误差的累积分布函数图Fig.10 CDF of three algorithms in the indoor environment 表2 室内环境定位误差对比Tab.2 Comparison of positioning error in the indoor environment 综上所述,本文所提的LSL算法无论是室外环境,还是室内环境,其定位精度都大幅优于其他算法,因此具有很好的定位性能. 图11给出了算法B、算法A与LSL算法在室外和室内情况下的运行时间对比. 图11 三种算法的运行时间Fig.11 Running time of three algorithms 如图11所示,尽管本文算法增加了字典学习环节,但由于LSL算法在训练阶段完成了对链路的筛选,学习字典的维度大大下降,使得在稀疏重构阶段,计算量大大减少,因此算法运行速度较其他算法非但没有下降,相反还有较大的提升. 本文针对CS框架下DFL的传统模型权重字典存在字典不匹配问题,提出了一种链路选择学习算法(LSL),能够在字典更新过程中进行链路选取,同时解决了字典不匹配以及有效链路选择的问题.经室外及室内实验验证,这种算法不仅很好地解决了传统方法的字典不匹配问题,而且能够过滤部分误差位置,在定位精度和算法运行时间上都有优异的表现.下一步将考虑该方法误差的克劳美·罗界,并将该方法推广到多目标DFL定位.
2.2 稀疏恢复阶段
3 实验验证
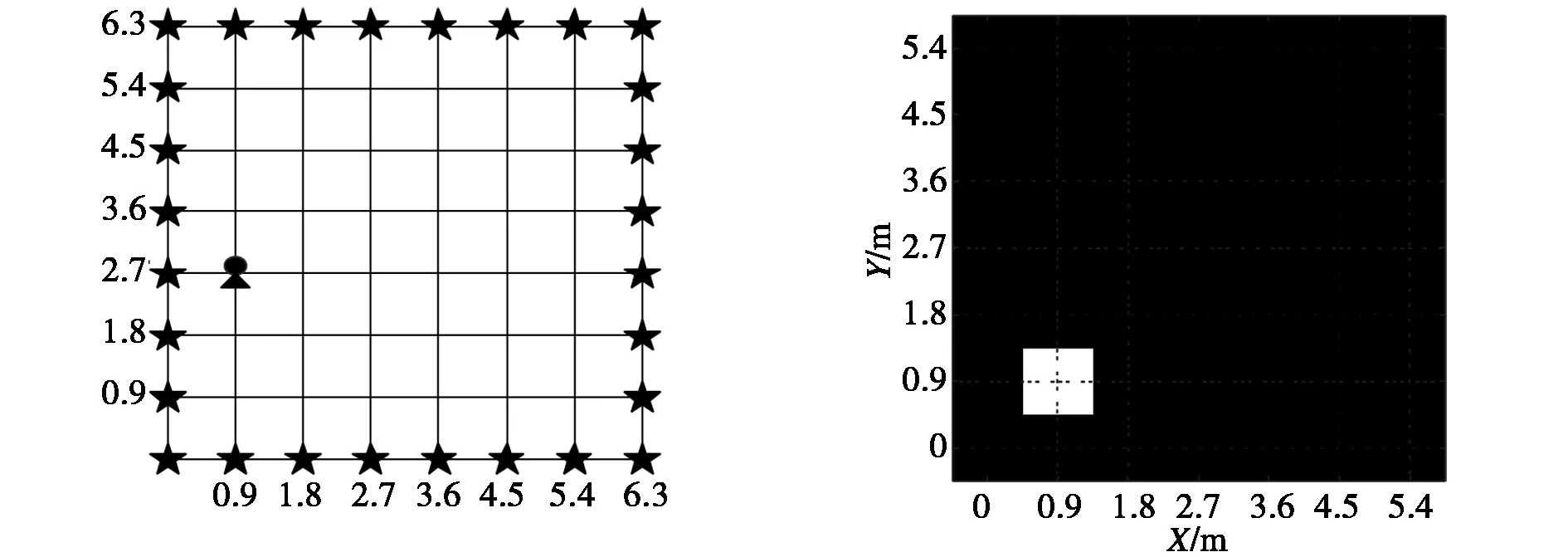
3.1 室外情况




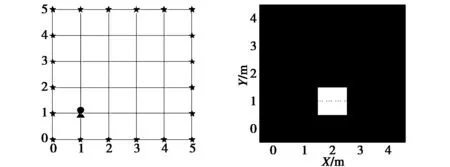
3.2 室内情况





3.3 算法运行时间分析

4 结 论
猜你喜欢
移动通信(2021年5期)2021-10-25
无线互联科技(2021年4期)2021-04-21
小学阅读指南·低年级版(2019年11期)2019-07-01
小猕猴智力画刊(2019年3期)2019-04-19
电子制作(2018年23期)2018-12-26
数字通信世界(2017年1期)2017-02-13
电子制作(2016年15期)2017-01-15
创新作文(小学版)(2016年19期)2016-08-22
读者(2016年14期)2016-06-29
中国交通信息化(2014年3期)2014-06-05
