
基于多维度评价信息的在线服务信誉度量
2019-01-24 08:26杨体东付晓东刘利军
小型微型计算机系统 2018年12期
杨体东,付晓东,2,刘 骊,岳 昆,刘利军,冯 勇
1(昆明理工大学 信息工程与自动化学院, 昆明 650500)2(昆明理工大学 航空学院, 昆明 650500)3(云南大学 信息学院, 昆明 650091)
1 引 言
随着互联网和普适计算技术的不断发展,在线服务因获取便利、操作简单、成本低廉而得到广泛应用,并成为当今服务产业发展的主要驱动力[1].然而在面对大量相同功能的服务时如何做出合理选择,使得用户不仅要考虑功能方面的需求,而且还要考虑到非功能属性服务质量(Quality of Service, QoS)的需求[2,3].信誉作为衡量QoS的一个重要指标,在服务选择时已成为用户参考的主要信息之一.但由于网络环境的开放性、动态性和时空上分离等特征,不能保证所有在线发布的服务都是客观、真实、可信的[4,5].因此,研究一种客观的在线服务信誉度量方法来反映服务的实际信誉状况,受到行业许多研究者的广泛关注.
虽然目前提出的许多解决方案在信誉度量的准确性和客观性上已有很大的提升,但大多数在线服务信誉度量模型是单维度的[6,7],信誉度量只对历史交易给出单一的评价,并不区分服务的各维度属性质量,评价粒度较粗,难以客观反映服务的实际综合表现.其次,单维度信誉度量模型可识别的属性信息结构单一,对于属性质量描述方式不同,使其对数据异构的服务环境缺乏适应性.因此,综合服务的多维度评价信息进行信誉度量,可以获得更为客观、合理的信誉度量结果,增强信誉度量模型的适应性.
本质上,信誉度量可视为一个对不同信誉类别的服务分类,而机器学习的优势是可以利用训练样本,在多维空间中构造最优分类器模型,既可以综合服务的多维度评价信息做出信誉决策,又可以提高信誉度量模型在属性信息异构的服务环境中的适应性.由于在构造服务分类器模型时,假设事先已经存在一定数量的训练样本(具有明确信誉类标签的样本),但在实际网络环境中,很难获得大量的训练样本,人工标注数量有限,仅依靠少量的训练样本数据难以准确描述实际的数据分布规律,因而无法建立有效的信誉度量模型.而获取大量的未标注样本则相对容易,但它们不能体现数据的分布规律而且隐藏着服务的判别信息.因此,使用半监督机器学习方法,同时利用少量人工标注样本和大量未标注样本来训练分类器模型,可有效解决较少训练样本情况下分类器模型欠学习的问题.
根据以上分析,本文提出一种基于多分类SVM的在线服务信誉度量方法.该方法以支持向量机(Support Vector Machine, SVM)理论为基础,建立服务的SVM多分类器模型,通过半监督机器学习训练SVM分类器,同时,为提高模型的泛化能力对属性特征进行降维,最终获得具有较高分类性能的SVM多分类器模型对服务进行分类,以实现信誉度量综合多维度评价信息.最后,通过实验验证本文信誉度量方法的有效性和高效性.
2 相关工作
用户的反馈信息是用户对服务体验的直观表达,基于用户评价的信誉度量成为在线服务信誉评估的主要研究方向.常见的基于用户评价的信誉度量方式有简单/平均模型、贝叶斯模型、模糊模型和离散信任模型等,文献[8]对这些方法进行了全面的综述.例如,eBay 使用求和法,将用户反馈的评分进行求和运算计算服务信誉.Amazon 使用平均法,根据用户反馈评分进行平均值运算计算服务信誉.此外,文献[9]参考社会学的信任模型,利用量化主体能力属性提升信任评估的准确性.在此基础上,设计了Web服务信任评估模型(ServTrust),且提出了ServTrust的一种基于多代理的解决策略.文献[10]提出一种事件驱动和规则驱动的信誉管理框架.根据事物中发生的事件,利用规则确定使用的公式和参数.此外,还通过模糊逻辑确定信誉排序.文献[11]通过用户对服务评价获得直接信任值,由推荐用户得到间接信任值,最后整合直接信任值和间接信任值得到服务信誉.上述研究均只针对服务主体做出单一的评价,并不区分服务的各维度属性质量,得到的信誉度量结果不够客观.
为解决信誉度量评价维度单一的问题,文献[12]在计算直接信任度时,综合服务的多维度属性评价进行信誉度量,使用交易评体系和评价权重体系较好地体现了个人主观偏好、风险态度等因素.文献[13]提出了一种基于用户属性的细度化声誉的评价体系,使得用户可以对其他用户的属性进行评价,而不对用户身份进行评价,避开了身份的影响,提高了评价的可信度.文献[14]将服务不同方面的反馈评价作为推理证据,基于证据推理的方法计算服务的直接信誉度和服务声誉的间接信誉度,综合直接信誉度和间接信誉度对服务的信誉值进行整合计算.上述研究在信誉度量的客观性和合理性上获得一定的提高,但信誉度量方法只针对用户评分进行信誉计算,不能对反馈信息中其他形式的评价进行识别和处理,使得可考虑的属性特征受到一定的限制.
基于服务QoS历史表现的信誉度量,是服务信誉评估的另一个方向.文献[15]认为在线服务信誉是由用户评分、QoS依从性和真实性组成的向量,其中依从性反映服务提供者履行其服务协议的能力,真实性反映服务提供者持续提供一定QoS的能力.文献[16]在服务选择中提出一种结合服务提供者承诺QoS值、用户反馈QoS值以及可信代理监控到QoS值的信誉模型.文献[17]基于QoS属性在服务管理中的角色,将信誉度划分为领域无关QoS属性的配置管理类型,同时给出信誉度的计算方式.上述方法基于服务QoS质量进行信誉评价,而均未考虑服务功能方面的属性特征,评价粒度较粗,信誉度量不够合理.
综上所述,已有在线服务信誉度量方法的局限性,使得信誉度量评价维度单一,粒度较粗,不能客观地反映服务的实际信誉状况.由于机器学习可利用训练样本,在多维空间中构造最优分类器模型,通过考虑服务的多维度属性特征而不是特定的属性维度进行信誉度量,为此,本文提出的基于多分类SVM的在线服务信誉度量方法可有效弥补已有研究中的不足.
3 问题描述
本文研究的主要问题是:如何根据服务的多维度评价信息度量服务的实际信誉状况.而信誉度量可视为一个对不同信誉类别的服务分类问题,所以本文将基于多维度评价信息的信誉度量问题转化为在多维空间中的服务分类.通过机器学习方法利用训练样本,在多维空间中构造最优分类器模型对服务分类,以实现信誉度量综合多维度评价信息,相关定义如下:
定义1.服务样本.在线服务数据可表示为Service=〈X,A,Y〉,X={x1,x2,…,xi,…,xm}(1≤i≤m)为服务的有限集;A={a1,a2,…,ad,…,an}(1≤d≤n)为属性的有限集;Y={y1,y2,…,yj,…,yq}(1≤j≤q)为类标签的有限集.其中,一个服务样本实例可表示为:xi={a1,a2,…,ad,…,an}.
定义2.多维度评价信息.是指用户通过服务体验后,对服务各维度属性A={a1,a2,…,ad,…,an}作出的评价,可表示为xi(A)={xi(a1),xi(a2),…,xi(ad),…,xi(an)},其中xi(ad)代表用户对服务xi的第d个属性的评价.
定义3. 信誉.信誉是众多服务QoS属性中的一种属性,它是对服务表现的综合度量,通过综合服务的多维度评价信息xi(A)={xi(a1),xi(a2),…,xi(ad),…,xi(an)}对所提供服务xi可信赖程度较为全面的一个量化表达,记为Y.
其中,可将信誉Y按需要划分为q个区间来代表不同的信誉类别.例如:当q=5时,表示将信誉划分为5个类别,信誉类标签1~5分别表示信誉很差、差、一般、好和很好.因此,q个区间的划分可得到q个不同的信誉类标签,记为Y={y1,y2,…,yj,…,yq}(1≤j≤q).
定义4.训练样本.为服务样本xi指定一个信誉类标签yj∈Y,形成一个具有明确信誉类标签的样本实例s={xi,yj},该样本实例可作为训练样本加入到训练样本集中,所有训练样本的集合记为S.
定义5.服务分类.对于所有的服务xi都有一个唯一确定的信誉类标签yj,根据不同的信誉类标签可以将服务分为不同的类别,进而实现信誉度量.
机器学习可以利用训练样本{xi,yj},在多维空间中构造最优分类器模型,实现对服务的最优分类.考虑到获取训练样本比较有限,当训练样本较少时,样本不足以反映数据的实际分布,训练出的分类器性能将受到较大的影响.本文使用半监督机器学习,从大量未标注样本中获取新的训练样本来扩充训练集,进一步提高分类器模型性能.
根据定义,由训练样本集训练出的分类器模型对服务进行分类时,所考虑的是整个服务的属性信息而不是某个选定的属性特征,从而能较好地进行服务分类.因此,在线服务信誉度量问题描述为:给定服务样本集和机器学习方法构建服务的多分类器模型,通过半监督机器学习训练分类器模型,根据最终得到的服务多分类器模型对服务进行分类,获得服务的信誉类标签.
4 基于多分类SVM的在线服务信誉度量
由于单维度信誉度量方法的局限性,不能客观反映服务的实际信誉状况,综合多维度评价信息进行信誉度量,可有效提高信誉度量的客观性和合理性.为此,本文提出一种基于多分类SVM的在线服务信誉度量方法,将基于多维度评价信息的信誉度量转换为在多维空间中对不同信誉类别的服务分类.基于机器学习的方式,利用训练样本在多维空间中构造服务的SVM分类器模型对服务分类,以实现信誉度量综合多维度评价信息.
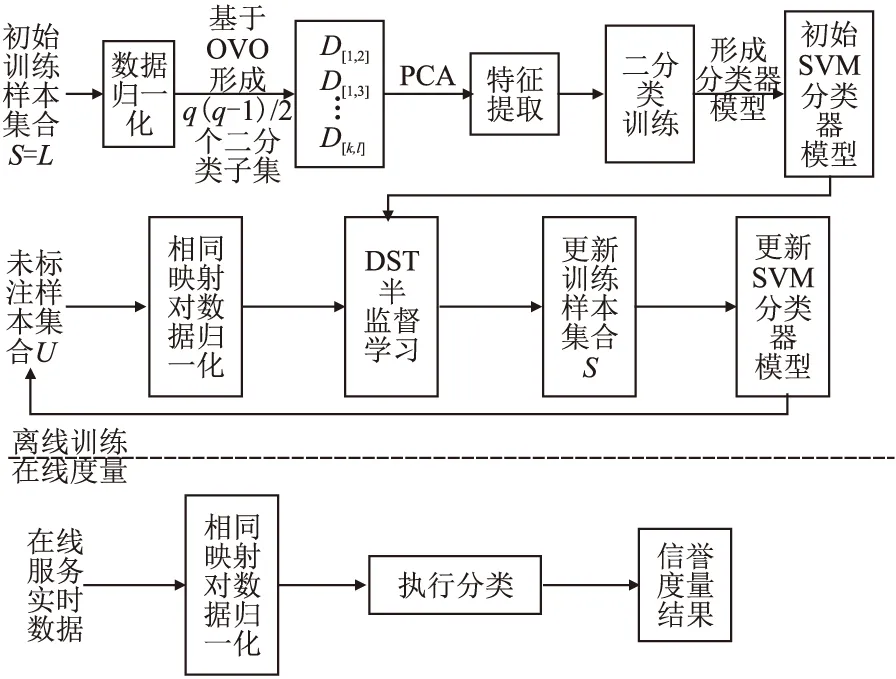
图1 基于多分类SVM的信誉度量框图Fig.1 Framework of reputation measurement based on multi-classification SVM
SVM作为机器学习中一种常用的构造分类器算法,其通过结构风险最小化原理提高泛化能力.引入核函数将样本映射到线性可分的高维空间,最终可以转化为凸优化问题,获得全局最优解[18],成为解决分类问题的有效方法.将SVM应用于在线服务信誉度量中,较之常规的信誉度量方法主要有两方面的优势:首先是易于增加更多的信誉判别特征,获得更多包含重要信誉决策信息的支持向量,使得信誉度量结果更加客观、合理.其次,由于服务样本往往具有维数高、样本数小和数据多源异构等特点,与常规信誉度量算法相比,SVM可以更好地解决小样本、非线性、信誉数据多源异构等问题,实现对服务的最优分类,更适合被应用于信誉度量中.
本文提出的基于多分类SVM的在线服务信誉度量总流程如图1所示.方法分为离线训练和服务信誉在线度量两个阶段.在离线训练过程中,首先基于SVM的服务多分类问题建模;然后,使用半监督机器学习训练SVM分类器模型,提高SVM分类器模型的分类性能.而服务信誉在线度量过程利用前者离线训练的结果,计算量小,保证了在线服务信誉实时度量的快速性.
4.1 基于SVM的服务多分类问题建模
由于服务信誉标签不止两种(Y>2),所以本文中的服务分类是一个多分类问题,而SVM分类算法是针对二分类问题提出的,因此,需要将服务多分类问题转化为二分类问题.
根据定义4,可知训练样本集为S,假设训练样本集中有i个训练样本实例,则S={s1,s2,…,si}.对于一个训练样本实例s={xi,yj},xi={a1,a2,…,ad,…,an}为n维的特征向量,yj∈{y1,y2,…,yq}.
SVM在解决多分类问题时需要构造多个二分类器,常采用的方法有:一对一分类(One Versus One,OVO)、一对多分类(One Versus All,OVA)[19].由于OVA方法会导致样本集中不同类标签分布的非均衡性,本文采用OVO方法实现多分类.对于本文中服务q分类(q>2)问题,按下式构造服务二分类训练样本集D.
D[k,l]={(xi,yj′=2yi=k-1)|yi=k或yj=l}
(1)
式(1)中:k,l=1,2,…,q.算子·根据等式是否成立返回1或0.因此,对于服务的q分类问题需要构造q(q-1)/2个二分类训练样本集.例如,用于信誉标签为1和2的二分类训练样本集D[1,2]是从训练样本集S中剔除信誉标签为3,4,…,q的样本,保留信誉标签为1,2的样本组成.另外其他信誉标签组的二分类训练样本集D[k,l](k,l=1,2,…,q)以同样的方式形成.
根据以上所述,对于服务q分类训练样本集将训练生成q(q-1)/2个二分类器,记为C[k,l](k,l=1,2,…,q).针对每个未知服务样本,每个二分类器都将得到一个预测类标签.通过投票法组合这些二分类器预测结果,即累积次数最多的类标签就是该未知服务的最终预测类标签,从而得到该服务的信誉度量结果.
4.2 半监督机器学习训练SVM分类器模型
由于在实际运用中,获取大量具有明确信誉类标签的训练样本比较困难,考虑到当训练样本较少时,样本不足以反映服务数据的实际分布,并且训练出的SVM的决策函数在多维空间中容易产生过拟合,使得SVM分类器性能受到较大的影响,为解决该问题本文基于半监督机器学习训练SVM分类器模型.首先由人工标注获取少量的初始训练样本训练SVM分类器模型,然后通过自学习方法在大量未标注样本中进一步获取新的训练样本来扩充训练样本集,重新训练SVM分类器模型,并对整个自学习过程进行循环迭代,不断提高SVM分类器模型性能.为尽可能减少错误训练样本的加入影响分类器模型性能,本文对自学习方法加以改进,提出一种带距离约束条件的自学习方法DST(Distance Self-Training,DST).
4.2.1 初始训练样本选择及分类器模型训练
已知训练样本集为S(S=Ø),假设未标注样本集为U,在初始分类时从U中随机选择z个服务样本,由用户对其进行人工标注,将该服务样本集合记为L={(xi,yj)}(i=1,2,…,z,yj∈Y).更新训练样本集S和未标注样本集U:S=L,U=U-L,得到初始训练样本集S=L={(xi,yj)}(i=1,2,…,z,yj∈Y).使用初始训练样本集S训练SVM分类器模型.同时,对未标注样本集U中的样本类标签进行预测.
在少量训练样本的情况下,直接学习SVM分类器属于欠学习问题[20],得到的分类器模型性能较差.因此,通过自学习进一步在大量未标注样本下训练SVM分类器提高分类器性能.
4.2.2 DST半监督学习
自学习是半监督学习中一种常见的技术,首先由人工标注少量的初始训练样本训练得到分类器,然后,通过这个分类器对未标注样本信誉类标签进行判断,将分类结果最确定的未标注样本,连带其对应的由分类器预测得到的类标签一起,加入到当前的训练集中.用扩充后的训练样本集重新训练分类器,并对分类结果进行更新[21].
由于添加到训练样本集中的样本类标签是由分类器预测得到的,因此得到的预测样本类标签与真实类标签就有不一致的风险,即预测错误风险,那么该错误会在迭代的过程中不断累积增加,对分类器准确预测样本类标签造成严重影响.为了尽可能减少自学习过程中错误样本的加入,提高分类器的分类性能,本文对自学习方法进行改进,提出一种带距离约束条件的自学习方法DST.在分类器预测样本类标签的同时加入样本间距离的约束条件来共同判断,提高自学习选出的训练样本类标签的准确性.对于当前的每个未标注样本xu(xu∈U)作如下判断:
1) 使用当前的SVM分类器对样本xu的信誉类标签判断,得到样本xu的信誉类标签yu,即yu/xu.
2) 基于欧式距离计算xu与训练样本集S中所有样本的距离D(xu,xi),寻找与xu最邻近的点记为N:
N=argminxi∈SD(xu,xi)
(2)
将该临近点N的信誉类标签记为yn,即yn/N.
3) 比较未标注样本xu的信誉类标签yu和最临近点N的信誉类标签yn,对样本xu做出决策:
(3)
如果yu=yn时,将样本xu连带信誉类标号一起添加到训练样本集合S中;如果yu≠yn时,将样本xu返回到未标注样本集U.
从距离相关性的自学习过程中可以看出,未知样本的信誉类标签不仅由分类器预测得到,还通过样本间距离的约束条件来共同判断,从而保证了自学习添加到训练集里的样本类标签具有较高的准确率.
4.2.3 训练样本集及分类器模型更新
用新选出来的训练样本xu对训练样本集S和未标注样本集U进行更新,即S=S∪xu,U=U-xu.用更新后的训练样本集S重新训练SVM分类器模型,并对整个距离相关性的自学习过程进行循环迭代.
直观上来说,虽然带距离约束条件的自学习选择出的训练样本所包含的信息量可能不高,但能有效降低引入错误类标签的概率,提高分类器模型的分类性能.同时,随着循环迭代过程不断从未知样本中获取新的样本加入到训练样本集中,样本的信息量也将不断得到完善,因此,带距离约束条件的自学习可有效提高分类器性能.
基于以上分析,得到半监督机器学习训练SVM分类器模型的算法如下:
算法1.半监督机器学习训练SVM分类器模型算法
输入:L:人工标注样本集;U:未标注样本集;
输出:SVM分类器模型model.
1.S=Ø;
2.S.add(L);
//选择初始训练样本选择
3.WHILEU≠ØDO
4.model=Learn(S); //初始SVM分类器训练
5.FORxu∈UDO
6.yu=mdoel(xu);
7.FOReveryxi∈SDO
8.D(xu,xi)=EuclideanDistance(xu,xi)
//公式(2)
9.ENDFOR
10.N=argminD(xu,xi);
//公式(2)
11.yn=examplelabelofN;
12.IF(yu==yn)THEN//距离约束条件(3)成立
13.S.insert(xu);
14.ELSEU.back(xu);
15.ENDIF
16.ENDFOR
17.ENDWHILE
18.RETURNmodel;
4.3 提高SVM分类器的泛化能力
提高服务多分类器模型的分类精度和泛化能力是机器学习原理能够在信誉度量中得以应用的关键.文献[22]指出,SVM中的VC(Vapnik-Chervonenkis)维越小,模型的泛化能力越强,减少特征数量是降维的有效方法,并通过实验证明了,使用主成分分析法(Principal Components Analysis,PCA)降低特征维数和交叉验证联合优化的方式,可有效提高分类器模型的泛化能力.因此,本文应用PCA进行特征提取实现降维,结合交叉验证来提高分类器模型的泛化能力.
4.3.1 特征提取
由定义1可知,已知服务xi的属性有限集为A={a1,a2,…,ad,…,an}(1≤d≤n),为n维特征向量,然后使用PCA方法对属性特征A={a1,a2,…,ad,…,an}进行降维.从得到的各主成分子集中选择影响信誉变化的主成分,剔除与信誉变化无关的主成分达到降维的目的.
PCA是一种经典的数据降维算法,用尽可能少的相互独立的数据表示原始数据的主要信息.通过PCA降维后不仅可以提高SVM分类器模型的泛化能力,同时还可以降低服务样本的特征维数、简化数据结构、有效降低分类器模型创建的时间复杂度和空间复杂度,进而提高SVM分类器模型的效率.
4.3.2 交叉验证
如果分类和测试都来自同一数据集,会出现过于乐观的训练误差.为了提高服务多分类器模型的泛化能力,交叉验证将服务样本集分为训练集和测试集,分别用作模型的生成和测试,以此作为评价SVM分类器性能的指标.
核函数参数以及惩罚系数对SVM分类器模型的泛化精度有着很大的影响.交叉验证的核心思想是从原始数据集中寻找优化核函数参数的有用信息.本文采用的SVM核函数为径向基核函数:K(xi,x)=e-γ‖x-xi ‖2.利用网格搜索法[23],结合10折交叉验证对RBF核函数中的惩罚参数C和核函数参数g进行寻优.
5 实验与分析
为验证本文提出的基于多分类SVM的在线服务信誉度量方法的有效性,对测试样本集进行信誉度量实验,分别从测试集每个类别各自的度量准确率、总体度量准确率、特征提取有效性3个方面对本方法的性能进行评估,并将本文方法SVM+DST与单维度信誉度量方法TMMRN(Trust Management Model Based Reputation Nodes)[11]、多维度信誉度量方法RMDT(Reputation-Based Multi-Dimensional Trust)[12]以及本文方法自学习时不考虑距离约束条件的方法SVM+ST这3种方法的性能进行比较.
5.1 实验环境及数据集
本实验爬取了中国最大的网购零售平台淘宝网中1632个在线商家最近6个月交易的评价统计量,整个数据集包括10个商品种类商家的16维属性特征评价.为了准确评估机器学习算法的有效性,测试样本独立于训练样本.其中,从数据集中随机抽取80%的数据作为未标注样本集,20%的数据作为测试样本集.需要说明的是,为保证实验方案的合理性,测试样本的信誉类标签与人工标注的类标签应具有一致的主观偏好性,因此对测试样本集进行人工标注,实验数据如表1所示.

表1 训练样本集和测试样本集Table 1 Training sample set and test sample set
实验采用MATLAB 2014a+LibSVM工具包实现,在一台配置为Inter(R) Core(TM) i3-2120 3.3 GHz CPU、8 GB RAM的PC机上运行,操作系统为Windows 10专业版.LibSVM作为实现SVM的一种常用工具包,采用OVO的方式来解决多分类问题,并提供多种核函数选择和交叉验证参数寻优[24],能快速、有效地实现所设实验方案.针对实验数据存在噪声的问题,本文通过剔除数据不完全的样本、对样本进行PCA降维、均衡各类别样本数目等方法进行数据预处理.
5.2 评价标准
本文将基于多维度评价信息的在线服务信誉度量问题建模为对不同信誉类别的服务分类,通过机器学习方法利用训练样本,在多维空间中构造最优SVM分类器模型对服务分类,以实现信誉度量综合多维度评价信息.因此分别使用平均准确率P、平均召回率R、平均综合指标F值来衡量方法的有效性.其中,平均准确率P反映模型精度,平均召回率R反映召回目标类别的比率、而F值则综合准确率和召回率反映SVM+DST整体的性能,具体定义如下:
设测试样本集为T={x1,x2,…,xn},信誉类标签yj∈{y1,y2,…,yq}为q个类别,TPj表示第j类被分类正确的个数,FPj为第j类分类错误的个数,则3个指标的计算公式如下:整个算法的平均准确率:
(4)
整个算法的平均召回率:
(5)
整个算法的平均综合指标:
(6)
5.3 信誉度量准确率
本文首先对测试样本集中每个类别各自的度量准确率进行实验.图2~图4分别给出了采用本文方法SVM+DST和其他3种方法,在测试集上各类别样本(1~5个类别)获得准确度量的样本数比较.图中,横轴表示样本类别,纵轴表示信誉度量正确的样本数量,柱状代表采用SVM+DST方法与对比方法在各个类别上的度量准确样本数的差,正数代表SVM+DST在该类别上的度量准确样本数多于该对比方法.

2824201612840样本数量样本类别12345图2 SVM+DST与RMDT在各类别上度量准确数量的比较Fig.2 Compare SVM+DST and RMDT to measure the exact number of each type2824201612840样本数量样本类别12345图3 SVM+DST与SVM+ST在各类别上度量准确数量的比较Fig.3 Compare SVM+DST and SVM+ST to measure the exact number of each type2824201612840样本数量样本类别12345图4 SVM+DST与TMMRN在各类别上度量准确样本数的比较Fig.4 Compare SVM+DST and TMMRN to measure the exact number of each type
从图2~图4中可以看出,SVM+DST方法与其他三种方法相比,在所有类别上的度量准确数量都有一定程度的提升.其中,SVM+DST相对于TMMRN和SVM+ST两种方法的度量准确数量提升幅度较大,证明SVM+DST方法通过考虑服务的多维度属性特征而不是特定的属性维度进行信誉度量,能有效提高信誉度量的准确率.同时证明SVM+DST方法,在自学习时加入距离约束条件选择出的训练样本能够有效地提高当前分类器模型的分类性能.此外较之RMDT方法,SVM+DST获得准确度量的样本数量也有少量的提升,证明SVM+DST方法在信誉度量准确率上优于RMDT方法.
根据以上实验结果,对4种方法的总体信誉度量准确率进行分析比较,如表2所示.

表2 SVM+DST和TMMRN、RMDT、SVM+ST的准确性比较Table 2 Comparison of Accuracy of SVM+DST,RMDT and SVM+ST
由表2可知,本文方法SVM+DST在准确率P、召回率R、综合指标F值方面都要优于RMDT、SVM+ST和TMMRN.经过分析,主要是因为TMMRN评价维度单一,只针对服务属性中的某一特征进行评价,因此计算出的信誉仅局限于该属性的质量,而忽略了其他属性对信誉的影响,导致信誉度量不够客观、全面.而SVM+ST在选择训练样本时,由于未考虑预测错误风险,使得自学习过程中加入了大量的错误训练样本,造成分类器分类性能下降.而RMDT方法主要适用于用户的反馈评分,不能对服务属性中包含的数字信息、标签信息等进行识别、处理,相对SVM+DST信誉判别特征较少,因此准确率和召回率有所下降.
5.4 特征选择有效性验证
实验目的在于验证PCA特征提取可提高服务SVM多分类器模型的效率,分别从SVM分类器模型的分类准确率和模型创建的开销时间两方面进行验证.为避免半监督自学习加入后影响实验效果,从训练样本集中选择250个样本作为训练样本集,并对其进行人工标注,其中每个类别样本各50个.通过对测试样本集进行分类预测,对比分析特征提取前后的分类准确率和分类器模型的开销时间,证明特征提取可有效提高模型的效率,实验数据如表3所示.

表3 特征选择有效性实验数据集Table 3 Feature selection effectiveness experimental set
依据表3中训练集的16维属性特征,采用SPSS19.0软件实现PCA主成分分析,从16个属性特征集中提取10个主成分,累积贡献率达到87.5%.分别使用PCA特征提取前后的数据集进行分类预测.在分类准确率方面:如果不进行特征提取,利用16维属性特征的数据集进行分类,分类准确率为91.4%,经过PCA特征提取后,使用10维属性特征的数据集进行分类,得到的分类准确率为90.6%.而在模型的时间开销方面,如果不进行特征提取,模型创建的时间开销为254.77s,经过PCA特征提取后,模型创建的时间开销为92.68s.
从上述实验结果可以看出,特征提取后分类器的分类准确率有所下降,但所下降的幅度并不大.这是因为PCA进行特征提取后,找到一组最能描述服务样本数据且特征维数较少的正交潜在变量,简化了样本内在统计结构特征,势必会丢失原始特征空间中可以区分不同类标签的微弱信息,造成SVM分类器分类精度下降.然而,特征提取后分类器模型创建的时间开销被极大地缩短,由此可见,PCA+SVM是通过牺牲一定的分类准确率来缩短开销时间的,在小样本数据分类的时候可能PCA+SVM的效率不是很明显,但在大样本分类的环境下这种代价交易就会变得非常可观,能极大的缩短运算时间,减少成本.考虑到本文中信誉度量所面对的在线服务环境,综合考虑PCA降维后的分类准确率和模型的时间开销,PCA降维可有效提高服务SVM多分类器模型的效率.
6 总结与展望
基于多维度信息的信誉度量模型对提高信誉度量的准确性和合理性有重要影响.本文将信誉度量问题转换为信誉多分类问题,使用支持向量机进行服务多分类.由于获取大量的训练样本比较困难.我们将自学习方法引入到支持向量机分类器的服务分类中,并对自学习方法进行改进,确保自学习过程获得准确的训练样本,通过循环迭代整个自学习过程,不断优化分类器模型,并由该分类器模型对服务进行多分类,实现信誉度量综合多维度属性信息.实验验证该方法在服务分类时具有较高的准确度.
由于自学习中的初始训练样本由人工标注获得,因此得到的训练样本可能不是最优的,如何确保获得高质量的初始训练样本成为下一步工作中需要考虑的问题.其次,使用PCA主成分分析法虽然可以有效降低样本数据维数和模型开销时间,但是会造成分类器分类精度的损失,考虑引入其他降维方法来有效减少样本数据维数的同时,可优化分类模型的开销时间和分类准确率将是今后工作的一个重要方向.
猜你喜欢
计算机应用文摘·触控(2022年8期)2022-05-25
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
科技创新与应用(2020年6期)2020-02-29
华人时刊(2019年13期)2019-11-26
计算机测量与控制(2019年4期)2019-05-08
现代电子技术(2016年23期)2017-01-12
北京理工大学学报(2016年6期)2016-11-22
金桥(2016年4期)2016-10-14
华人时刊(2016年19期)2016-04-05
