
基于主题模型的短文本关键词抽取及扩展
2019-05-31 01:12曾曦阳红常明芳冯骁骋赵妍妍秦兵
山西大学学报(自然科学版) 2019年2期
曾曦,阳红,常明芳,冯骁骋,赵妍妍,秦兵
(中国电子科技集团公司第三十研究所,四川 成都 610000)
0 引言
关键词抽取一直以来都是信息抽取领域内一个重要的研究方向,如同摘要在长文本中所起的重要作用一样,关键词能准确地反映出短文本所要表达的内容,是人们快速了解文档内容、把握主题的重要方式。并且关键词对自然语言处理领域的文本分类和文本聚类任务有积极作用;同样关键词在信息检索领域也有重要的应用价值。然而在海量的互联网文档中又仅有少部分带有关键词标注,如何给短文本打上一个表意准确的关键词标签成为信息抽取领域的重要问题。
本文提出一种基于文档主题特征的关键词抽取及关键词扩展方法,系统框架如图1所示。首先对短文本进行分词及词性标注等预处理,然后采用TF-IDF算法计算出词的初始权重,并且训练短文本的主题模型,得到短文本的分类信息和类别特征词,再采用单语词对齐技术抽取出短文本中的词搭配,之后根据上述信息对关键词权重进行调整,通过阈值筛选出关键词,最后构建词的表示向量,通过计算词与短文本之间的相似度找到与内容信息最贴合的类别特征词作为扩展关键词,建立短文本的关键词集合。

Fig.1 Architecture of the system图1 系统框架图
1 相关研究概述
在关键词抽取研究初期,最常用的方法是通过词的出现频次来获得关键词,然而这种方法所取得的效果并不理想。之后人们采用有监督的机器学习方法来抽取关键词,1999年Turney将关键词抽取问题看成是一个分类问题[1],通过关键词的出现位置和长度等特征来训练学习,所抽取到的结果要明显优于统计方法得到的结果。Frank等人将朴素贝叶斯的方法应用在关键词抽取任务中[2],使得结果有了进一步提升。Hulth加入了更多的语言学知识[3-4],如句法特征,在实验结果上获得了一定的成功;但是随着网络数据规模的增加,人工标注数据的工作量变得异常巨大,目前人们主要采用基于图的方法来抽取关键词。2004年Mihalcea和Tarau将PageRank算法思想带入到了关键词抽取领域[5],提出了一种基于图的排序算法TextRank。Litvak和Last将同样用于网页排序的HITS算法用于候选关键词排序[6],在F值上取得了一定的提升。Wan等人通过聚类的方法将相似文档中的知识应用在图模型中[7-8]。Liu提出基于文档内部信息构建主题的关键词方法[11],通过计算语义相似度来对候选词进行聚类,再通过聚类中心词找到合适的关键词,之后Grineva将多主题文档的方法应用在构建语义图模型上[9]。Elbeltagy和Rafea创建的KP-Miner系统在关键词抽取结果上有着不错的效果[10]。该系统对关键词词频和反文档频率统计提出了更高的要求,并对关键词出现在文章中的位置与其重要性关系进行了分析。2013年You对现有关键词抽取系统进行了总结[12],并针对前人缺点进行了改进,对候选词的预处理提出了更高的要求。对于图模型的方法而言,训练时间相对较长,无法在短时间内构建索引满足用户需求。
关键词扩展任务可以借鉴查询扩展任务,查询扩展主要为了改善资讯检索召回率,将原来查询语句增加新的关键字来提高查全率和查准率。查询扩展任务分为全局分析[13-14]、局部分析[15-19]、基于用户查询日志[20]和语义相似度计算[21]等几个方面;关键词扩展并不是针对单一的查询语句,而是对大量文本补充关键词,丰富其含义,在构建索引的时候就扩展了数据的内容,而不是在检索的时候扩展查询语句的含义。关键词扩展的方法类似于查询扩展中的全局方法,并采用局部分析中的一些优化策略,使用全部文档蕴涵的相关信息扩展关键词[22-25];2009年Wang将关键词抽取和扩展应用在聚类任务中[26],实验结果有一定提升。2014年Abilhoa[27]提出一种推文集合的关键字提取方法,它将文本表示为图并应用中心度量来查找相关顶点作为关键词。2017年Zhao[28]将神经网络的词向量特征应用于短文本关键词抽取系统,在Textrank的基础上其实验结果获得一定的提高。与长文本相比短文本的统计特性相对较弱,在抽取关键词任务中所遇到的困难更多。本文所提出的基于主题模型的关键词抽取及扩展方法上与前人有着本质的不同,考虑到了主题分类信息和词搭配信息,关键词抽取效果也更加精确。 并且通过构建词的表示向量来计算词和文本的相似度,从而扩展出关键词,丰富短文本含义。
2 关键词抽取
2.1 概述
本文所采用的基于主题模型的关键词抽取方法主要分为5个步骤:(1)预处理,获取初步的候选关键词;(2)关键词赋权,基于改进的TF-IDF方法给关键词一个初始权重;(3)LDA主题模型,根据类别特征词对关键词权重进行调整;(4)词搭配抽取,根据词搭配信息对权重进行调整;(5)根据阈值抽取关键词。图2为关键词抽取的一个实例图。
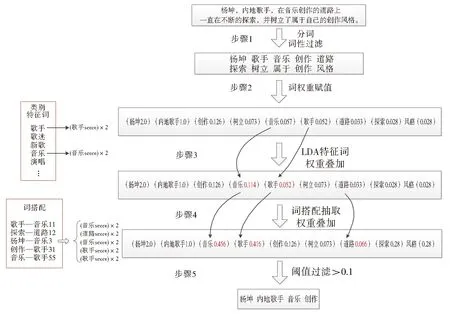
Fig.2 Process of the proposed keyword extraction图2 关键词的抽取过程
2.2 关键词初始权重赋值
本文首先通过文本分词,词性标注和停用词等方法获得候选关键词,如图2中步骤1,去掉“一直”“属于”等词。
2.2.1 基于TF-IDF的关键词赋权
TF-IDF是一种统计方法,用以评估字词对于一个文件集或一个语料库中的其中一份文件的重要程度。本文基于汉语中词语长度与词语重要程度存在一定关系,对原有TF-IDF算法做出了改进,通过公式(1)对候选关键词打分,获得候选关键词的基本权重值。
Scoreti=tfi,j×idfi×len(ti)
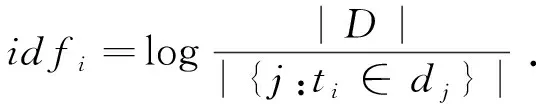
(1)
上式中Scoreti为ti的最终权重值,tfi,j表示词频,指的是某一个给定的词语在该文件中出现的频率。idfi表示逆向文档频率,表示是一个词语普遍重要性的度量,len(ti)为词语ti的字节长度。ni,j是词ti在文件dj中出现的次数,而分母则是文件dj中出现所有字词的出现次数之和;|D|是语料库中文件总和,|{j:ti∈dj}|表示包含词语ti的文件总数,计算结果如图2中步骤2所示。
2.2.2 基于规则的关键词赋权
通过观察数据发现,在每一条短文本中有一些特殊的字词可以直接作为关键词,这些字词往往可以直接表达该文本的某些特定信息,因此本文在TF-IDF的基础上采用下列规则抽取一些字词作为候选关键词,并直接打上一定分数,用以表达这类关键词的特殊性,规则如下:
(1)根据书名号或括号抽取书名、歌曲名等作为候选关键词,如“赵薇主演过《还珠格格》《情深深雨蒙蒙》”,其中“还珠格格”“情深深雨蒙蒙”的权重值如公式(2)所示:
Scoreti=2.0 .
(2)
(2)根据此类文本的特殊性,抽取一些短标题直接作为候选关键词,如图2中的“杨坤”,其权重值如公式(3)所示:
Scoreti=2.0 .
(3)
(3)根据共现信息将一些词合并成常见短语,常见短语就是人们在日常生活中经常能够看到或者使用到的短语,如图2中的“内地歌手”,其权值如公式(4)所示:
Scoreti=1.0 .
(4)
2.3 基于LDA主题模型的关键词赋权
LDA(Latent Dirichlet Allocation,隐含狄利克雷分配[29])主题模型是近年来在中文信息处理领域发展起来的一种生成主题概率模型,它基于一定的常识性假设:文档集中所有文档均按照一定比例共享隐含主题集合,而隐含主题集则是由一系列相关特征词组成。LDA模型定义每篇文档均为隐含主题集的随机混合,从而可以将整个文档集特征化成隐含主题的集合。
本文将大规模短文本用LDA主题模型进行聚类,通过类别信息来进行关键词表示,为关键词扩展中的相似度计算提供数据;并通过主题模型得到每个类别下的主题特征词,将这些特征词作为关键词抽取中的一个权重打分标准,其具体公式如下:
Score1ti=2τ1(ti)×Scoreti
S=
(5)
其中Score1ti为词语ti当前权重,Scoret为上一节中给词语ti所赋的权重,S为类别特征词集合。如果候选关键词ti是类别特征词,则权重加倍。权重修改结果如图2中步骤3所示。因为“音乐”和“歌手”都出现在特征词列表中,所以其权重加倍。
2.4 基于词搭配的关键词赋权
搭配(Collocation)一般被定义为词和词在一起的概率要远大于一般随机出现的概率,在汉语中常用的搭配“影视明星”“室内装修”等等。本文认为搭配对中的两个词往往具有一定的语义联系,例如“影视”和“明星”间是存在一定的潜在联系,这些词可以互相表达、相互支持,希望通过这些搭配来形成一种新的关键词抽取方法。
本文采用的搭配抽取模型为单语词对齐模型(MWA,monolingual word alignment),单语词对齐是仿照双语词对齐的一类计算任务,通过统计计算出同一语言中关系相近的不同搭配。Liu[30]分别修改了IBM model 1,model 2以及model 3,使得相同的词之间不能互译,最终抽取出的搭配,来自于三种翻译模型词互译结果的融合。
本文将通过词搭配对关键词权重再次进行调整,因为词搭配中蕴含着一定的语义关系,若一条文本中如果两个候选关键词构成词搭配关系,并且该词搭配的频次超过一定阈值,则认为该词搭配中的候选关键词相比于其他词语更加重要,因为词搭配中的词是存在先后关系的。当一条文本中出现两个候选关键词组成词搭配时,则只对第二个候选关键词的权重进行加倍,通过找到文本中的不同词搭配,使得部分候选关键词权重发生变化,经过再次排序可以将排名靠前的候选关键词作为关键词输出。其权重变化如公式6所示。
Score2tj=2η×Score1tj
T=
(6)
其中ti和tj是文本中的候选词,τ1(ti,tj)为一个二值函数,如果ti和tj构成以tj为第二个词的词搭配,则tj的权重就增加一倍,如果不构成词搭配,则权重无变化。T为与tj构成搭配对关系的候选关键词集合。
权重修改结果如图2中步骤4所示,文本中“歌手”和“音乐”组成词搭配,因为词搭配具有先后关系,本文只对词搭配中的第二个关键词进行权重调整,所以“音乐”的权重加倍一次,并且“杨坤”和“音乐”也组成了词搭配关系,所以“音乐”的权重再次翻倍,通过不断叠加,“音乐”的权重变为最初的8倍。
最后重新排序,根据阈值将排序结果靠前的词作为关键词输出。
3 关键词扩展
3.1 词向量表示
词向量表示一直是机器学习问题在自然语言处理领域中的一个重要研究方向,最常用的词表示方法是Bag-Of-Words,该方法把词表示成一维向量。这个向量的维度是词表大小,其中绝大多数元素为 0,只有一个维度的值为 1,这个维度就代表了当前的词,该表示方法相对简单,但是该方法存在着两个主要问题,一是所需存储的向量维度相对较大;二是存在很严重的数据稀疏问题。使用该方法计算相似度时还需要统计共现信息,较为烦琐。本文给出一种不同于上述方法的词向量表示机制,并且包含一定的语义信息。
本文所提出的词向量表示方法主要是根据文本类别信息得到的,对文本使用2.3节的LDA主题模型进行分类,之后将每个Topic下的类别特征词用一维特征向量进行表示,该一维向量的维度即文本的分类个数,其元素的含义表示该词是否为该文本类别下的特征词,对于赋值而言,若该类别不含该特征词,则向量中的该元素为0,若类别特征词中含有该词,则对应的向量维度为该类别下的特征词的概率,基于上述表示机制可以得到所有特征词的向量表示:
(7)
其中i是指LDA模型的类别体系,w为主题分类下每个类别中的特征词,pi(w)表示词w出现在LDA模型类别i中的概率。
如果只对类别特征词进行词向量表示,所能够被表示的词数量太少,因此本文提出一种词向量传递机制,通过词搭配将类别特征词的向量传递到候选关键词上,使更多的词可以被表示,即
l(w,v)=<(w,v0),(w,v1),…,(w,vn)> ,
(8)

3.2 关键词扩展
通过2.3节训练的LDA模型,可以知道每一条文本所属的具体类别,并且每一个类别含有一些特征词。本文所提出的关键词扩展策略是计算文本关键词与类别特征词之间的相似度,再根据排序结果和一些统计规律将相似度排名靠前的类别特征词作为该文本的扩展关键词输出,具体方法如下:
wi∈Ti,Ti=
(9)

4 实验
本文使用100万微信公用账号简介作为短文本数据,该数据包含微信公用账号名称及相关简介。
4.1 关键词抽取实验
对于从内容中抽取关键词的实验结果,本文采用人工构建测试集方法进行评价,依然按照准确率、召回率和F值进行评测。这里将传统的TF-IDF算法作为Baseline,将实验结果与Wang[26]和TextRank[5]进行对比,随机抽取500条短文本作为测试数据,并人工标注了4 135个关键词作为关键词抽取的测试集,其实验结果如表1所示。

表1 关键词抽取对比实验
通过上表可以看到,在准确率、召回率和F值三个测试指标中,本文方法均取得了最优的实验效果,其中Average是指一条短文本平均能抽取几个关键词;从表1可以看到,本文方法所取得准确率和F值基本上都比第二名高出10%左右,并且召回率也有小幅提高;从上述实验结果可以看出,本文所提出的基于词搭配信息的关键词抽取方法是真实有效的,在运用统计知识的基础上考虑到了具有语义联系的词搭配信息,因此取得了相对好的实验结果。最终在1 009 713条实验数据中,共对978 716条文本抽取到关键词,对于没有获得关键词的文本主要是因为其描述采用英文或者繁体字。
4.2 关键词扩展实验
本文方法KEK(KEYWORD-EXPEND-KEYWORD)扩展出来的关键词,依然采用准确率、召回率和F值进行评测,但是有所不同的是并不构建测试集,因为一篇文本人们通过想象扩展出来的关键词会存在很大的差异性,所以采用人工的方法来看文本扩展出的关键词是否正确;由于不存在测试集,在召回率上则更加偏重对扩展能力的评价,在召回率上随机抽取一定量的文本数据,通过统计这些短文本中有多少扩展出新的关键词来计算召回率,公式如下:
(10)
expend(id)为扩展出关键词的短文本数量,all(id)为参与实验的短文本数量,Recall(id)本节召回率计算结果。在本文实验中将all(id)设为500。针对不同规模的短文本进行对比实验,实验结果如表2所示。
通过表2可以看到,在随机抽取的500篇文档中给275篇短文扩展出了关键词,并且共扩展出795个关键词,正确的652个,通过人工测评的方法计算了准确率。可以看出,准确率曲线和召回率曲线均呈上升趋势,因为训练数据越多,主题模型训练的越充分,分类更加准确,所以关键词扩展的效果越好。
本文还与Wang的方法进行了对比,他的方法主要是文本中找到同义词进行替换,在英文领域采用的是Word-Net上的同义词替换资源,将同样的方法移植到中文上,由于Word-Net上没有中文资源,这里采用哈尔滨工业大学构建的《同义词词林》进行替换;为了说明关键词抽取的重要性,将本文的关键词扩展策略进行修改,提出了一种基于全文本的关键词扩展方法AWEK(ALL-WORD-EXPEND-KEYWORD),该方法与前述的扩展方法略有不同,不再只与文本中的关键词计算相似度,而是将所有候选词作为扩展依据计算相似度,将本文方法与上述两种方法相对比,将100万条短文本作为训练语料进行对比实验,实验结果如表3所示。

表3 关键词扩展对比实验
上表可以看出,在三组实验中,本文方法取得了最优的准确率,并且F值也要高出其他方法5个百分点,通过该实验说明短文本中如果只采用简单的同义词来扩展关键词,虽然会对很多短文本都打上扩展标签,但是由于同义词扩展出的关键词并一定能具有文本所要表达的含义,所以准确率并不高;而第二种基于全文本的相似度计算扩展方法,由于文本存在着大量噪声词,这些词在做关键词扩展任务中具有很强的干扰作用,使得扩展结果与原文语义发生很大偏差,所以所取得扩展结果也并不理想;而本文方法之所以取得了相对较好的结果,是因为只基于文本关键词计算相似度,文本中的关键词基本上都与文本语义保持一致,所以扩展出来的关键词不会有太大偏差,效果相对理想。表4给出了本文方法的相关实例。

表4 关键词抽取与扩展实例
5 结论
本文介绍了短文本关键词抽取和扩展的具体方法。在关键词抽取任务中,采用主题分类和词搭配信息抽取关键词,取得了较好的实验结果;在关键词扩展任务中,定义了一种基于LDA主题分类结果的词向量表示机制,这种表示机制具有一定的语义信息,并且更加节约空间开销,最终的关键词扩展结果也非常理想;而且本文对搜索引擎系统提出了一条新的改善思路,不同于传统的查询扩展工作,不再只对文本内容构建索引,而是通过关键词标签对其内容进行语义上的丰富,扩大索引集合,以提升搜索引擎系统的查全率和查准率。
猜你喜欢
计算机系统应用(2021年9期)2021-10-11
时代英语·高二(2018年7期)2018-12-03
计算机技术与发展(2018年8期)2018-08-21
时代英语·高二(2018年3期)2018-06-06
民族古籍研究(2018年1期)2018-05-21
中国机械工程(2017年22期)2017-12-02
西夏学(2016年2期)2016-10-26
中文信息学报(2015年4期)2015-04-21
浙江大学学报(工学版)(2015年1期)2015-03-01
中国中医药现代远程教育(2014年16期)2014-03-01
