
面向散文的低频情感词语抽取与情绪标签确定
2019-05-31 01:53王素格程琦陈鑫
山西大学学报(自然科学版) 2019年2期
王素格,程琦,陈鑫
(1.山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006;2.山西大学 计算机与信息技术学院,山西 太原 030006)
0 引言
情感词语能够为情感分析提供丰富的信息,也为许多情感分析任务提供研究基础。根据情感粒度的不同,词语有两种分类方式,一种是粗粒度分为正面(褒义)或负面(贬义)的词语,每一个词都被赋予正面或负面的极性;另外一种是细粒度的分类,根据情感词语所包含的情绪,将词语标注为喜、怒、哀、乐等标签。本文将从情绪的角度抽取散文体裁的情感词语,并对抽取的词语标注情绪标签。由于情绪词语具有体裁相关性,词语的情绪标签因文本体裁不同而不同。因此,有研究表明[1],在特殊领域的情感词典比通用领域的情感词典在情感分析上有更好的表现。目前大部分构建情感词典的词语来源于新闻、产品评论和微博等社交媒体,而针对散文文本中的情绪词语鲜有人关注。已有的部分研究主要是面向高考散文阅读理解答案获取[2],该任务主要是考查学生对散文的理解,而机器阅读是希望机器理解散文中作者所描写的景、物和人等抒发的情感。因此,抽取散文中的情绪词语,在一定程度上可以提高阅读理解的答题准确率。
针对情感词语抽取任务,主要分为三种方法,基于词典的方法、基于语料库的方法和两者相结合的方法。基于词典的方法,主要有Rao等人[3]基于图的半监督学习方法,通过给出正、负面种子集和同义词图,从WordNet提取正面和负面的情感词。张璞等人[4]采用标签传播算法抽取情感词语,其中邻接矩阵采用Word2Vec和连词结合的方法。杨小平等人[5]提出了基于转换约束集的多维情感词语抽取,主要利用词分布密度的感情色彩消歧方法,抽取了包含10种情感标注的多维汉语情感词语。Choi[6]提出了基于FrameNet的感知层面的情感词语建立方法。Xu[7]使用英文情绪词典WordNet-Affect自动抽取中文情绪词语,首先将英文词典中的英文单词翻译为中文,再借助中文同义词词典《同义词词林》为每一种情绪标签构建双语无向图,构建了一个图算法用于获取种子情绪词集,最后通过同义词扩大情绪词语集。
基于语料库的方法。Yang等人[8]构建了一个情感词典,通过对情绪间的分析,对bug严重程度的预测进行了研究。Hamilton等人[9]使用了论坛Reddit中250个在线社区语料,展示了社区之间情感的重大变化。引用150年英语的历史情感词汇,发现了在这段时间内大于5%的词语交替极性。Yu等人[10]通过使用股市新闻的语料扩展情感词,对文本进行情感的正负性判定,并将其用于股票趋势的预测。Zhao[11]为中文情感分析创造出一个细粒度的语料库,通过分析注释语料库来探索新的情感分析任务。
基于语料库和词典相结合的方法。Zhang[12]使用了一种半监督框架模型在用户评论语料中抽取情感词。Yang[13]利用情绪感知LDA模型,使用一组领域无关的最小种子词作为先验知识,为预定义的情感抽取特定领域的情绪词语。Wu等人[14]提出一种基于数据驱动的微博专用情绪词语分类方法,该方法包含3种词典的情绪知识统一框架,不断将检测到的情绪新词加入到已有的情绪词语集中,从而扩展情绪词典的样本集。Song[15]认为在具有动态性领域(社交媒体等),词汇不仅需要适应领域中的变化,还需要提供更细粒度的定量估计,以获取词-情感关联。利用标记和弱标记情感文本来学习基于生成的模型,用于抽取情感特征进而进行分类。Mohammad[16]提出了一种从Twitter语料库中生成词汇之间的情感关联方法,第一个构建了词语之间具有情感关联分数的词典。Abdaoui[17]提出了基于英语情感词典的同义词的半自动翻译和扩展方法,考虑词语极性和情感的新语法扩展情感词语。马秉楠等人[18]提出一种基于社交网络中特殊情感符号的跨媒体多情绪(喜、怒、哀、乐)情感词语抽取方法。将图片与短文本内容相结合,利用表情符与文本词之间互信息的计算,筛选基于社交网络的情绪词语。
散文中的高频情感词语具有通用性,可以使用通用词典或者词共现等方法抽取[9],而对于散文中出现的低频词,源于其作者不同,写作内容及表达方式不一致,一切景语皆情语,不同的景,表达不同的情感。例如在史铁生的作品《合欢树》、朱自清的作品《荷塘月色》等散文作品中,不同作者将情感寄托在不同的景物中。仅从词典或词语共现的角度抽取散文中的低频情感词语难于获得理想的结果。因此,本文针对散文中低频情感词语抽取,提出了一种基于随机游走模型的情感词语识别方法。首先利用一般词典确定种子集词语,采用词典和语料库相结合、词语间的共现信息和Word2Vec的语义相似度相结合,构建了随机游走图,抽取情感词语并对情感词语进行情绪标签的标注,其中情绪标签分为喜、怒、哀、乐、惧五类。
1 词语间的相关性度量
散文中的词语在表达情绪时较为含蓄和深沉,因此,若要获取其情绪词语,需要考虑词语间的相关性。
例1 我孤傲的心境,我坦荡的胸襟,我直言不讳的稟性,我洁身自好的习性,我疾恶如仇的愤世。
在例1中,“孤傲”“坦荡”“直言不讳”“洁身自好”“疾恶如仇”五个词语共现时,用来称赞“我”的人生态度,犹如孤芳自赏的隐士,由“坦荡”等词与“孤傲”共现和上下文的环境中可以推断出“孤傲”一词与“坦荡”具有较大相近情绪标签,而在其他体裁中“孤傲”带有贬责色彩。为了定义词语之间的相关性,定义如下的共现关系度量。
定义1 共现关系度量(CRM),利用候选词语之间的互信息度量词语间的相关性,在词语频数高的情况下,两个词语间的共现信息和关联程度具有较好的效果。两个词语之间的共现关系度量见公式(1)。
(1)
其中,p(xi)表示某一个词在给定语料中出现的概率,p(xi,xj)表示两个词语xi与xj共同在一个句子中的概率。CRM值越高,两个词语情绪标签相同的可能性就越大。
例2 它们是一片朦胧的温馨与寂寥,是一片成熟的希望与绝望,它们的领地只有两处:心与坟墓。
在例2中,“温馨”和“寂寥”、“希望”和“成熟”、“心”与“坟墓”分别表示相对的情感倾向。仅使用共现关系,容易将此类的词语分类错误,因此,利用词语间的语义信息可为此类问题的解决提供支持。因此,给出如下的语义关系度量定义。
定义2 语义关系度量(SRM),Word2Vec中的Skip-gram模型是利用特定词对应的上下文词向量,用于刻画该词的分布表示。设词xi∈Rl和词xj∈Rl为l维向量,使用余弦相似度度量两个词语之间的语义关系,见公式(2)。
(2)
公式(2)计算的相似度越大,说明两个词语语义越相关。
2 基于随机游走模型的情感词语识别
根据第1节定义的两种相关性度量,共现关系度量主要是利用词语同时出现的概率,而本文的主要目标是抽取低频词语,即出现概率较少的词语。若使用公式(1)可能会导致度量关系较为稀疏。另外,语义关系度量使用词语间各自的词向量,而词向量生成是根据词语上下文的预测,然而,仅靠上下文的词向量也会使低频词语的信息不够丰富。因此,本文根据文献[19-20]中使用的两步传播算法,融合两种度量关系,构建随机游走模型中的随机游走图。最后根据候选词到种子集的游走概率判断候选词的情绪倾向。
2.1 种子集情感词语抽取

2.2 随机游走模型的构建
随机游走模型是通过点与点之间的连通性刻画候选词之间的相关性。整个模型分为两部分,随机游走图和随机游走过程。这里的随机游走过程是在随机游走图基础上,从未知情绪倾向的词语x出发,开始游走,在词语x相连的所有词语中,如果某个词语在模型图上距离词语x越近,则游走到这个词语的概率就会越大,反之,游走到这个词语的概率就会越小。最后,通过游走到种子集词语的概率判断词语x的情绪倾向。
2.2.1 随机游走图
随机游走图是随机游走模型的基础,图中点与点之间连通的概率用于度量散文体裁中词语之间的相关性。如果游走图上连接两点之间的概率值越大,则表示两个词语之间相关的可能性越大,也就越有可能拥有相同的情绪。
假设候选词中的每一个词语映射为随机游走图上的一个点,则游走图记作G=(V,E),其中,V={xi|xi∈X}表示随机游走图上的点集合,X表示候选词集合,E={(xi,xj)|xi,xj∈X}表示图中两个点之间连接的概率集合,即词语间相关性集合。
为了便于词语之间情绪的传播,我们将游走图表示成邻接矩阵,其中,邻接矩阵中初始元素是由词语之间的共现关系构成。
(1)初始邻接矩阵建立
利用公式(1)共现关系的度量值CRM(xi,xj),构建初始邻接矩阵W∈R|m|×|m|,其中m表示候选词语的数量。矩阵W中元素wij见公式(3)所示。
(3)

(2)词语语义关系矩阵
为了反映词语间的语义关系,利用公式(2),构建语义关系矩阵D∈R|m|×|m|,矩阵D中的元素见公式(4)所示。
di,j=SRM(xi,xj) .
(4)
(3)词语情绪的传播
仅靠初始邻接矩阵只能刻画两个词间的直接关系,为了进一步利用词语间的语义关系,达到局部传播影响到整体情感候选词语[19],需要构建两步传播算法,包括列上的垂直传播和行上的水平传播。
① 列垂直方向情感传播
利用公式(3)和(4),构建列垂直方向情感传播迭代公式,见公式(5)所示。
Ev(t+1)=α·S·Ev(t)+(1-α)D,
(5)

利用公式(5),通过不断迭代,直到游走图趋于稳定,得到邻接矩阵Ev*。
② 行水平方向情感传播
在列垂直方向情感传播的基础上,构建行水平方向上情感传播迭代公式,见公式(6)所示。
(6)
利用公式(6),通过不断迭代,直到游走图趋于稳定,得到邻接矩阵Eh*,其中,Eh(0)=D.
上述① 和② 两步传播,获得词语间的游走图。其传播算法的收敛性分析见文献[19]。
2.2.2 随机游走过程
随机游走过程[20]是从一个或一系列顶点开始遍历一张游走图。对于游走图中的任意一个顶点x,以概率p(x,yi) 跳跃到图中的其他任何一个顶点yi,称p(x,yi) (i=1,2,…,m)为跳转发生概率。游走过程需要4个输入参数,邻接矩阵(Eh*)、初始概率分布向量s0、跳转发生的权重β∈(0,1)和随机跳转概率p.
假设游走后的词语xi∈X(i=1,2,…,m)输出概率分布向量si=(si1,si2,…,sim),每次游走后词语xi(i=1,2,…,m)的概率分布向量si的迭代计算见公式(7)。
(7)
其中,向量si(0)中的sij(0)为词语xj的初始情绪标签,对于未知情绪标签的词语设置为0.每次迭代之后,重置种子集中词语的标签为初始情绪标签。
本文假设词语概率分布p为均匀分布,随机跳转概率分布向量见公式(8)。
(8)
利用公式(7)的迭代过程,可以得到稳定的概率分布si*。
2.2.3 基于随机游走模型的词语情绪标签判断
利用2.2.2节构建的随机游走模型,设计如下判断词语的情绪标签方法。
设词语xi∈X(i=1,2,…,m),xi情绪标签的判别见公式(9)。
(9)
这里的N为种子集的个数,sij为词语xi游走到第j个种子词语的概率值,O(xi)为词语xi的情绪类别标签。
3 实验与分析
3.1 数据集和语料预处理
1)实验数据集。本文使用了80 190篇散文,数据来源于高考散文、散文网等相关网站,经过去重、去燥(网址)等处理。
2)分词。使用哈工大社会计算与信息检索研究中心研发的语言技术平台(LTP)进行分词。
3)候选词语的选取。
本文对收集的80 190篇散文进行分词。选取其中的名词、形容词、动词、俗语(成语)作为候选词语。实验选择词频500到7的低频词语,平均分为十组。在每组候选词中,《情感词汇本体》中的词语占候选词的比例如图1所示。

Fig.1 Proportion of words in “Emotional Vocabulary Ontology” under different word frequencies图1 不同词频下包含《情感词汇本体》中词语的比例
为了验证在第2节中提出的随机游走模型在散文体裁低频情感词语抽取作用,本文选取图1中比例最小的一组,即词频为20到16作为实验的候选词语,共选取候选词语1 140条,其中各种情绪词语所占比例如表1所示,在真实散文文本中情感词语各类别数量存在不平衡性,为符合真实文本情况,本文实验数据未做平衡处理。

表1 各类情绪词语数量分布情况
由表1中可知:在候选词中,“喜、怒、哀、乐、惧”五类情绪标签的词语占总候选词数量为74.1%,说明在散文低频词语中,这五类情绪词语比例较高,因此,本文仅考虑这五类标签的词语。其中“乐”比例最高,其次是“喜”,说明在散文数据中,较多的散文是属于缅怀、赞扬、祝愿等主题,而“惧”所占比例最小,说明恐惧一类的词语的散文篇章较少。
3.2 种子集的选取
情感词语的种子集是随机游走模型实现的基础。本文选择《情感词汇本体》与候选词语的交集,每种情绪标签选择10个词语作为种子集,如表2所示。

表2 随机游走模型中的各个情绪标签的种子集
3.3 实验结果评价指标
实验结果评价指标采用准确率(P)、召回率(R)和F1值。每一类情绪的实验结果指标分别见公式(10)、公式(11)、公式(12)。
(10)
(11)
(12)
其中,TPemoi表示某种情绪emoi预测正确的数量,FPemoi表示将其他类别的情绪预测为情绪emoi,FNemoi表示情绪emoi未预测正确的数量。Pemoi(i=1,2,…,N)表示情绪emoi的准确率,Remoi(i=1,2,…,N)表示情绪emoi的召回率,F1emoi(i=1,2,…,N)表示情绪emoi的F1值。
所有情绪的实验结果指标分别见公式(13)、公式(14)、公式(15).
(13)
(14)

(15)

3.4 实验结果及分析
本文实验的词向量维度l=70,第2.2.1节传播参数α=0.1[20]
实验1:不同数量的情感词语种子集对情绪类别判别的影响
为了分析随机游走模型,在不同数量的情感词语种子集对情绪类别判别的影响,本实验选取6组不同的种子集,分别进行了对比实验,实验结果如表3所示。

表3 不同数量的种子集词语的实验结果
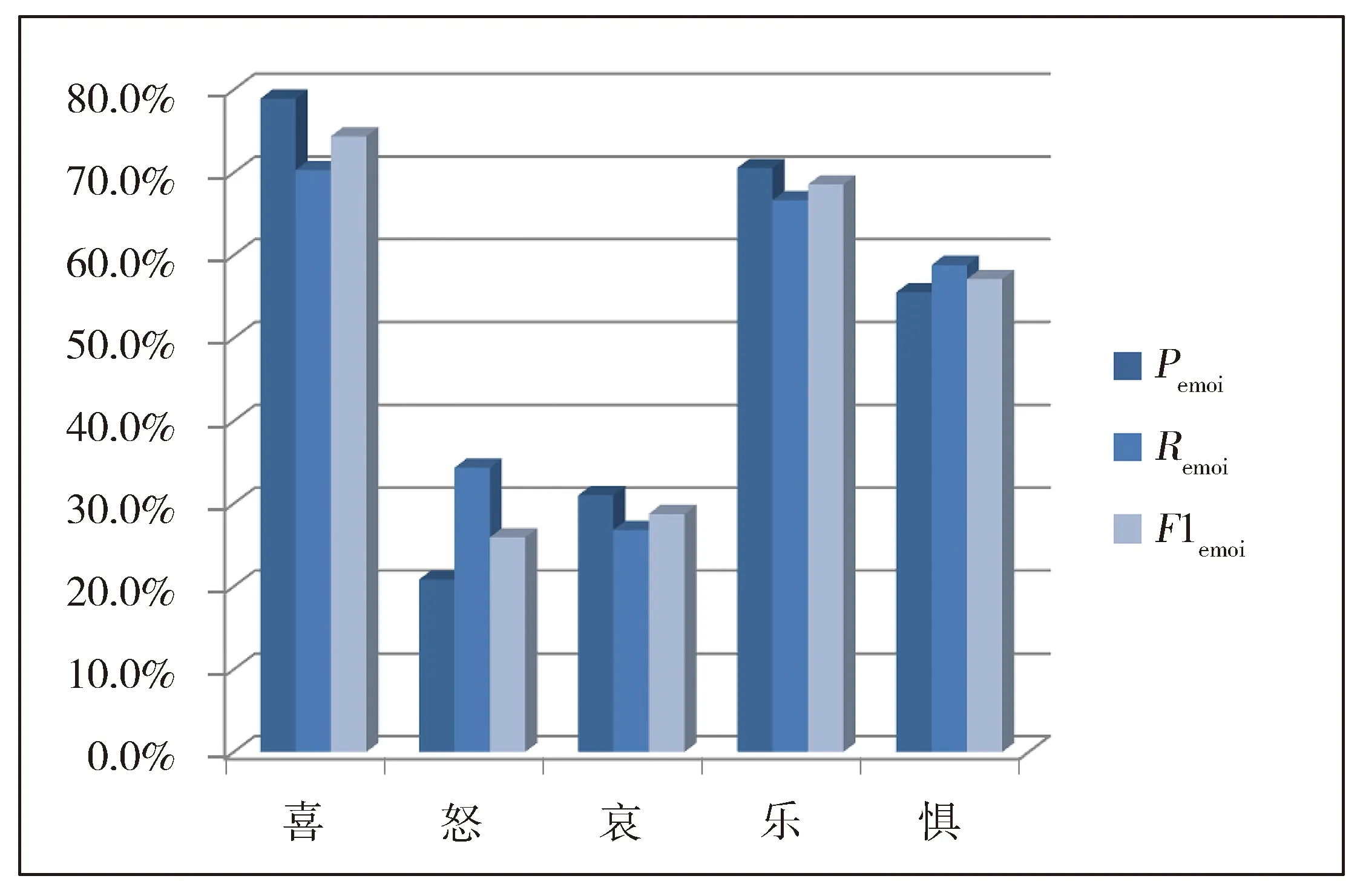
Fig.2 Emotional tendency discrimination results of various emotional words图2 各类情感词语情绪倾向判别结果
由图2可知:“怒”和“哀”情绪类的各项评价指标均低于另外三种。其原因是在情绪标签判别中,这两种情绪关系紧密,某个词语可能同时含有两种情绪,但是根据模型,词语的判别更偏向于概率大的这种情绪。例如,“尔虞我诈”既包含“怒”的情绪,也包含“哀”的情绪,在本文中人工判别其为“哀”情绪,而在实验结果中,判别其为“怒”情绪。因此,模型判别“哀”的情绪标签时,有26.5%的词语被判别为“怒”的情绪。
实验2:不同权重β下的随机游走模型抽取情感词语的结果

Fig.3 Different weights β downstream walking model to discriminate emotional tendency图3 不同的权重β下游走模型判别情感词语情绪倾向结果
由图3可知:随着β的变化,各项评价指标出现波动,说明游走过程中跳转发生概率的权重会影响散文情感词语的识别。当β值为0.15时,准确率、召回率和F1值均取得了最优结果,在后续的实验中均选取β=0.15.
实验3:为了验证本文提出的随机游走模型(RWM)的有效性,设置了五个baseline方法进行对比。
(1)标签传播算法(LPA)[22]:该方法与本文的核心游走模型有相似之处,其基本思路是用已标记节点的标签信息去预测未标记节点的标签信息。
(2)CRM:基于词语间共现关系度量的词语情绪标签判断。
(3)SRM:基于词语间语义关系度量的词语情绪标签判断。
(4)CNN:基于文献[23]提出的卷积神经网络,本文抽取候选词所在句子作为卷积网络的特征进行分类,实验中参数均采用文献[23]中参数。
(5)LEX:基于词典《情感词汇本体》的方法对词语情绪标签判断。
以上五种方法和本文所提出的方法进行比较实验,实验结果见表4所示。

表4 各类词语情绪判别方法的实验结果比较
由表4中结果可知:
(1)本文方法RWM比LPA方法在抽取面向散文体裁词语情绪标签的三项指标结果均好。LPA算法要求每个节点的标签按照相似度传播给相邻节点,在节点传播的每一步,每个节点根据相邻节点的标签来更新自己的标签,与该节点相似度越大,相邻节点对其标注的影响权值越大。本文的RWM方法,是由未知情感倾向的词语进行随机跳转,根据迭代收敛之后跳转到种子集的概率,判断未知词语的情绪标签。由于散文情感最大的特点是由景抒情,将心情看作一种抽象的事物,使用相应的具体景物描写出来,因此随机游走模型更适合于散文体裁的情感词语抽取。
(2)RWM方法在各项评价指标上均大于CRM方法和SRM方法,说明融合了两种方法的随机游走模型比单一的任一种方法能够更好地抽取面向散文体裁的低频情感词语。主要原因是当候选词中部分词语与种子集中的词语未产生共现时,PMI方法和WS方法将无法对其判断,因此,单独使用任一种方法均不能将所有候选词语的情绪标签进行判别,仅能判断候选词语中的53.4%和50.4%的情绪倾向。
(3)CNN方法适用于数据均衡且数据量较大的情况,而本文中候选词是低频词,每个词语只抽取10个句子作为CNN训练集,将数据按照9∶1的比例,分为训练集和测试集,实验结果进行了五倍交叉验证。另一方面,各类情绪词语的数据分布不均衡,每类情绪的评价指标平均后均低于RWM方法。
(4)由于词典中的情感词语不够完善,LEX方法只能抽取到词典有的词语,不能很好地包含面向散文体裁的情感词语,仅能判断候选词语中的25.5%的情绪倾向。LEX方法的实验指标均低于RWM方法。
实验4:为了验证本文实验方法在其他频次的候选词语中的效果,分别对不同频次的候选词进行实验。实验结果如表5所示。

表5 不同频次候选词语情绪判别的实验结果比较
由表5中结果可知:
随着候选词的词频减少,词语之间的相关性刻画程度减少,实验指标有小幅度降低,但变化幅度不大,证明了本文提出的随机游走模型,在高频和低频词语中都能取得不错的结果。其中频次在499~115候选词的实验结果指标最好,是由于词频高的词语,语义关系和共现关系足够丰富,在模型游走中,能更好地传递词间关系的信息。而词频在12~10之间的候选词实验结果指标最差,实验结果中,未检测到“惧”类情绪的情感词语,即此类的准确率和召回率均为0,各类情绪结果指标求平均之后,低于其他频次的候选词。
3.5 示例展示
为了展示第2.2节两步传播算法的性能,选取部分词语,通过词语实验过程中情绪的变化,直至最后情绪倾向判断正确,其示意图见图4、图5、图6所示。

Fig.4 Shows the co-occurrence relationship between candidate words and seed sets图4 表示候选词语与种子集之间的共现关系度量
图4表示第1节中词语之间的共现关系度量。连线上的数字表示两个词语之间的共现关系度量值,若没有连线,说明两个词语没有共现关系。

Fig.5 Shows the semantic relationship between candidate words and seed sets图5 表示候选词语与种子集之间的语义关系度量
图5表示第1节中词语之间的语义关系度量。连线上的数字表示两个词语之间的语义关系度量值,值越大说明其与种子集的关系越密切。

Fig.6 Probability of emotional tendency of candidate words in the two-step propagation algorithm图6 两步传播算法过程中候选词的情绪倾向的概率
图6中,图6a表示在经过列的垂直方向传播情感之后,候选词的情绪标签概率;图6b表示在行的水平方向传播情感后,候选词的情绪标签概率。
从图4和图5中可以看出,单独使用共现关系度量和单独使用语义关系度量不能很好地识别候选词语的情绪倾向,经过在列的垂直方向上传播情感之后部分情感词语可以分配正确的标签。当经过在行水平方向上情感传播之后,候选词语的情绪倾向能够判断正确,且原先正确的词语的情绪倾向的概率也有小幅度增加。例如“萎缩”一词在图6a上分配了正确的情绪标签,在图6b上情绪类别的概率增加。
4 结论
本文针对散文体裁的低频情感词语抽取任务,提出了一种融合词语相关性和相似度的随机游走模型。首先基于一般的词典选取种子集,确定候选词语和种子集范围,然后根据两种度量词语之间共现关系和相似度的方法,融合构建随机游走模型图,最后在模型图上实现随机游走过程,再根据游走到种子集的概率判断词语的情绪类别。最后通过实验验证了本文所提出方法的有效性。
由于散文是一种抒发作者情感,写作方式灵活的记叙类的文学体裁,是作家反映各自复杂而微妙的情感载体。由于散文中的一些名词,往往带有特殊的情感,比如2016年高考题《老腔》中的“老腔”,对于读者来说,老腔是一种文化,但是对于作者而言,不仅是一种文化,更是一种感动和感慨,因此,在未来工作中,将考虑针对名词性的情感词语及其寓意的识别。
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
五邑大学学报(自然科学版)(2019年3期)2019-09-06
英语文摘(2019年5期)2019-07-13
江西教育B(2019年2期)2019-04-12
中国诗歌(2018年6期)2018-11-14
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
Coco薇(2015年11期)2015-11-09
