
机会网络中利用博弈论的可信路由协议
2019-07-16 12:29杨震,赵丽
重庆理工大学学报(自然科学) 2019年6期
杨 震,赵 丽
(1.四川省装备制造业机器人应用技术工程实验室, 四川 德阳 618000;2.山西大学 软件学院, 太原 030013)
在移动自组织网络(mobile ad hoc network,MANET)[1]中,节点的移动性、网络的划分、链路的不稳定性等都会影响网络性能,而机会网络(opportunistic network,OppNet)[2]的使用可以很好地解决上述问题。在OppNet中,由于不存在端到端的路径,节点之间通过可伸缩移动性、联系机会、节点协作以及存储转发机制,使得源或中间节点能够将所需的消息转发到目的地。为了应对端到端路径的缺失问题,OppNet有效地利用了现有的通信媒介,如WiFi、蓝牙和蜂窝等技术实现相关节点之间的消息交换。在OppNet中,节点之间只有在通信范围相同的情况下,或有机会互相接触时,才能进行通信和交换,否则节点的内部机制将把消息存储在缓冲区,直到出现进一步的机会。以这种方式,所需的消息分组从一跳转发到另一跳,并且最终更快地到达目的地。
在OppNet中由于缺乏对网络拓扑结构的先验知识以及定位参与节点的不确定性,网络安全性及路由选择是一个非常大的挑战。本文的目标是为OppNet设计一个有效的路由协议。该协议中可有效用于优化路由的可能信息包括:节点的移动性和方向、与目的节点的接触次数,以及相对于特定目的地的距离。此外,本文还提出使用博弈论[3]模型用来设计协议。使用博弈论的原因是可以从模拟网络中收集不同的案例研究,然后为冲突和合作情景制定一个优化的数学模型。利用博弈论处理决策参数之间的冲突情况,以便从可用的参数中找出最合适的响应策略。在本文中,节点的上下文信息被视为其战略配置,在此基础上构建战略博弈,实现信息上下文的稳定组合,然后选择获得的策略将消息转发到目的地方向的下一跳。
1 相关研究
目前,学者们设计出了很多用于OppNet的协议。文献[4]提出了Prophet路由协议,在该协议中,如果一个节点过去遇到过另一个节点,或者曾经多次访问过一个位置,那么在不久的将来,它被认为更有可能遇到同一个节点或访问同一个位置。关于每个已知目的地的传递概率度量由源节点估计。基于此,可获得节点向目的地成功传送消息的传送可预测性。文献[5]提出了基于历史的路由预测协议(HBPR),该协议基于网络中移动节点的历史。HBPR的3个特征阶段分别是:① 位置识别:在这个阶段,假定节点的移动与人类移动模型相似。在某些地方,节点的移动非常频繁,而在其他一些地方,节点的移动较少。可通过利用节点移动的历史预测该节点的下一个位置;② 消息生成和归属位置更新:在这个阶段为节点生成一组新的消息,然后记录每个新生成消息的目的地ID;③ 下一跳选择:为了识别下一跳,基于3个参数来考虑效用度量:节点移动的稳定性、未来移动的预测以及相邻节点距离源目的地的垂直距离。文献[6]提出了PRoWait的路由协议,该协议使用一个简单的转发策略:当两个节点处于相同的通信范围内时,在数据传输过程中,具有较低传送可预测性的节点与具有较高传送可预测性的节点交换数据包。根据Prophet协议的规则计算节点的传递可预测性,并将其用于下一跳节点选择,以减少资源消耗。文献[7]提出一种数据发送策略,它根据节点的特征优化路由,增强了数据传输性能。文献[8]根据时间序列参数和传输过程参数评价节点的优劣,以选择合适的转发节点。文献[9]提出了一种基于遗传算法的能量有效路由协议(GARE),利用遗传算法(genetic algorithm,GA)[10]将消息从源路由传递到目的地。
文献[11]提出了一种基于博弈论的路由协议(GTR)。它在有限的资源下将消息传输建模为多玩家Nash议价模型,并设计了一个效用函数。它决定了一个节点在传递概率方面的能力以及当前的剩余资源。文献[12]提出了一种消息转发机制,即利用基于概率的路由方案刺激自选节点参与路由选择。使用这种机制,每当转发源来自具有较低传送概率的节点的分组时,具有较高传送概率的节点就会被用来进行补偿。该协议被建模为一系列议价博弈,包括转发算法和传递概率计算。文献[13]提出了另一种基于博弈论的转发机制,该机制考虑了节点的上下参数,利用卡尔曼滤波器对这些参数进行预测,根据这些参数设计一个双机非合作博弈,然后用这两个参数来决定两个节点之间的数据转发。
以上协议大多数会因为网络拥塞造成性能下降,因此需要更多的网络资源。另外,就下一跳选择而言,计算上下文信息需要额外的时间,并且在制定基于博弈论的传播和基于上下文情景的解决方案时没有考虑除能量和安全性之外的任何参数。本文提出一种机会网络中基于博弈论的可信路由协议,从而以最小的延迟和开销比传递消息。
2 本文协议
2.1 本文协议假设及相关术语定义
本文假定一个由N个移动节点组成的机会网络场景,所有移动节点之间存在合作意识。另外,假定这些节点具有足够的缓冲区来存储它们各自的上下节点信息。一旦源或中间节点产生并广播HELLO分组,每个节点就相对于相应的目的地动态地计算它的相遇值和欧几里德距离,这些数据被存储在节点的缓冲区中。节点特定的上下文信息进一步用于制定战略博弈,以便从下一跳选择中找到可用的最佳策略。在这里,战略博弈被假定为一个有限的、合作的和非零合作博弈。最后,本文还假定参与消息转发的每个节点都有足够的能量,没有恶意节点的行为。
本文相关术语定义如下:
1)G代表博弈。{S}、f(u)和z分别表示博弈的策略、实用功能和收益价值。
2) {N}和{M}分别表示网络中的节点和源或中间节点的邻居节点。
3)K和L表示从{N}和{M}中选择的一组节点。
4)P表示从{K}和{L}中选择的节点集合。
5)σ表示相遇的阈值,ω表示距离的阈值,λ是相遇的常数值,μ是距离的常数值。
6) 相遇转发参数:该参数用于根据相关节点和目的地之间相遇的次数选择下一跳。α表示N个节点的相遇转发参数;α1表示M中节点的相遇转发参数。
7) 距离转发参数:该参数用于根据相关节点和目的地之间的距离来选择下一跳。β表示N个节点的距离转发参数;β1表示M中节点的距离转发参数。
8) 最佳转发参数:该参数用于根据相遇和距离参数选择下一个最佳跳跃。γ表示N个节点的最佳转发参数;γ1表示M中节点的最佳转发参数。
9) Sum Encounter和Sum Encounter1分别表示N中节点的相遇次数总和以及M中所有节点的相遇次数总和。
10) Sum Distance和Sum Distance1分别表示N中所有节点与目的节点的距离之和,以及M中所有节点与目的节点的距离之和。
11)T表示用于选择集合K和L的阈值。
2.2 博弈模型
本文协议倾向于将博弈定义为一个元组G={N,S,U},其中N是移动节点集合,S={Si}是可用策略集合,U={Ui}是同一个博弈的一组实用参数。设E是节点从源或中间节点相对于目的节点的相遇值,D为节点相对于同一目的地的欧几里德距离,则S={E,D}为该博弈的策略配置集合。类似地,di, j是相邻节点i相对于目的地j的欧几里德距离,ei, j是相邻节点i相对于目的地j的相遇值。在制定的战略博弈中,博弈是在源节点或中间节点与邻居节点i之间进行的,i=1,2,3,…,m。 这里,邻居节点是位于源节点或中间节点的通信范围内的节点。
根据制定的战略博弈的结果,源或中间节点将选择来自邻居节点i的下一跳将消息转发到其目的地。对于两个合作者而言,制定的战略博弈是一个非零和博弈,可根据纳什均衡[14]导出结果。纳什均衡的详细推导和证明如下。
在博弈中,协议根据节点的相遇值E=(ei, j)和距离D=(di, j)来考虑4种可能的策略,这些策略如下:
1) 大的相遇值(eh)和大的距离值(dh);
2) 大的相遇值(eh)和小的距离值(dl);
3) 小的相遇值(el)和大的距离值(dh);
4) 小的相遇值(el)和小的距离值(dl)。
在上述策略中,效用函数表述如下:
f(u)=ei, j×λ+di, j×μ
(1)
其中ei, j和di, j由下式给出:
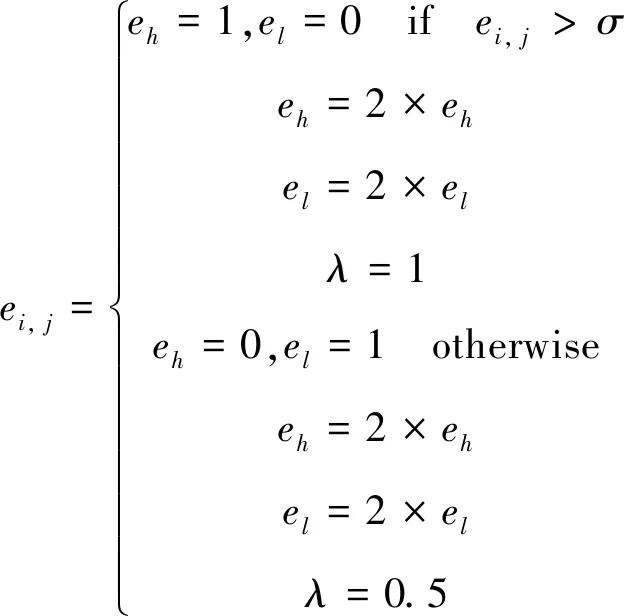
(2)

(3)
其中:σ和ω是阈值;λ和μ是在效用函数的公式中分别考虑相遇值和距离的恒定值。类似地,基于这个效用函数,玩家/节点的收益值z计算如下:
zhh=eh+dh
(4)
zhl=eh+dl
(5)
zll=el+dh
(6)
zlh=el+dl
(7)
节点的收益矩阵如表1所示。同样,如果z和Z分别是两个移动节点/玩家的收益值,则其博弈收益矩阵表如表2所示。

表1 节点的收益矩阵

表2 博弈收益矩阵
2.3 最佳跳跃选择
本文协议的主要目标是基于α、β和γ从网络中选择消息的下一个最佳跳跃,该选择过程包括:① 从网络中选择最佳转发参数γ;② 从源节点的邻居中选择最佳转发参数γ1。
2.3.1从网络中选择最佳转发参数γ
希望传达消息的源节点或中间节点首先向整个网络广播HELLO消息,假设N个节点在网络中是可用的且可以接收到HELLO消息,同时这N个节点相对于目的地的相遇值是动态计算的。在这里,每个节点的相遇值显示了过去与其他节点相遇的次数。这些相遇值的总和被存储在名为SumEncounter的变量中。类似地,计算N个节点中的所有节点相对于目的地的欧几里德距离,并且将它们的距离值的总和存储在名为SumDistance的变量中。
为了选择下一跳,针对N中的每个节点计算α。对于给定节点,α的值是其自身相遇值与所有对应节点的相遇值的总和的比,即:
α=Node’s encounter/SumEncounter
(8)
类似地,针对N中的每个节点计算β。β的值是节点相对于目的地的欧几里德距离与所有相应节点相对于目的地的欧几里德距离的总和的比,即
β=Node’s encounter/SumDistance
(9)
为了从N个节点中选择下一个最好的转发节点,本文协议需要使该节点与目的地节点间的相遇的次数最大化,并且使该节点与目的地节点间的距离最小化。网络的γ计算如下:
γ=α/β
(10)
阈值T可以表示为N中所有节点的γ值的平均值,本文协议仅选择γ≥T的节点集合。
2.3.2从源邻居中选择最佳转发参数γ1
假设在给定的网络拓扑结构中一个节点有M个相邻节点,这些相邻节点能够相互通信。这M个节点相对于目的地节点的相遇值是动态计算的,M个节点的相遇值的总和存储在名为SumEncounter1的变量中。类似地,这M个节点相对于目的地节点的欧几里德距离也是动态计算的,并且它们对应的和存储在名为SumDistance1的变量中。为了选择下一跳,每个相邻节点计算α1,α1的值表示如下:
α1=Node’s encounter/SunEncounter1
(11)
类似地,每个相邻节点计算β1:
β1=Node’ distance/SumDistance1
(12)
为了从相邻节点中为源/中间节点选择下一个最好的转发节点,本文协议需要最大化节点与目的地的相遇次数,并且最小化与目的地的欧几里德距离。另外,协议对从源/中间的每个相邻节点获得的α1和β1值的均值进行归一化,并计算γ1:
γ1=α1/β1
(13)
源/中间节点的阈值T可以表示为对应于相邻节点的γ1值的平均值。所提出的协议从γ1值大于或等于T的相邻节点集合中仅选择一组L个节点。从该集合中最后选择一组P个节点,源/中间节点将向其转发消息,其中P=K∩L。
2.4 本文协议详述
本文协议将整个网络划分为由N个节点组成的r个均匀区域,称为k1,…,kr,r=1,2,…,p是不同逻辑划分的区域,其中kr代表区域r。令nk,i为区域k中的一个节点,k=1,2,…,l;i=1,2,…,m。其中n1,1表示属于区域1的节点1,n2,1表示属于区域2的节点1,依此类推。在初始化步骤中,算法向网络中的每个节点发送或者广播HELLO分组报文。在收到HELLO报文后,每个节点计算其上下文信息,如欧几里德距离、相遇值等。
假设Ek,n是属于区域k的节点n相对于目的地的相遇值。相应区域中所有节点的相遇值的总和计算如下:
(14)
其中k=1,n=1,2,…,p。为了计算属于特定区域的特定节点的最佳计数值,本文协议计算节点与属于该特定区域的所有节点的总相遇值的比值为
(15)
类似地,属于网络中的每个逻辑划分区域的所有节点的相遇值SumEncounter的累积总和可表示为:
TE,N=TE,1+TE,2+…+TE,r
(16)
其中:TE,1和TE,2分别表示区域1和区域2中所有可用节点的相遇值的总和。
(17)
其中:E=1;k=1,2,…,r。本文协议通过将特定区域节点的相遇值与网络中所有逻辑划分区域的SumEncounter值的比率表示为一个新的参数:
(18)
由下式可得α的值:

(19)
类似的,假设Dk,n是属于区域k的节点n相对于目的地的欧几里德距离。相应区域中所有节点的欧几里德距离的总和计算如下:
(20)
其中:k=1;n=1,2,…,p。为了达到最优化结果,本文协议计算一个节点与属于该特定区域的所有节点的欧几里德距离之和的比值,即
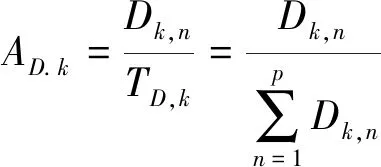
(21)
计算属于网络中每个逻辑分离区域的所有节点的SumDistance的值,即
(22)
其中:D=1;k=1,2,…,r。本文协议通过将区域内节点的欧几里德距离值与对应于每个逻辑分区的所有可用节点的SumDistance值的比率表示为新的参数:
(23)
由下式可得β的值:
(24)
为了从网络中可用的N个节点中选择下一个最佳转发节点,本文协议需要最大化节点与目的地的相遇次数,且最小化与预期相邻节点的目的地的欧几里德距离。将每个分割区域的所有节点获得的α和β值的均值进行归一化,并从所有区域中计算γ:
(25)
考虑到前面讨论的阈值T,确定满足条件γ≥T的可用节点的集合K。这里,T值被认为是所有节点的相遇值的最大值或所有节点的欧氏距离的最小值。
假设r是消息的源/中间节点所属的区域之一,它由M个节点组成。以上述类似的方式计算α1、β1和γ1。
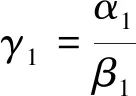
(26)
接下来,通过将阈值T与区域r中的相应节点的所有γ1值进行比较,本文协议找到集合L。在此基础上,协议选择最可能的最佳转发者的集合{P}:
{P}={K}∩{L}
(27)
3 仿真结果和分析
使用机会网络模拟器ONE[15]来评估提出协议的性能,并与Prophet协议、HBPR协议和PRoWait协议进行比较。模拟区域呈矩形,其中节点的位置由笛卡儿x和y坐标系表示。表3为仿真参数的值。

表3 仿真参数
1) 平均延迟
图1~3显示了TTL、节点数量和消息生成间隔对平均延迟的影响。在图1中可以看到:在变化的TTL值下,本文协议的平均延迟约为2 513 s,而HBPR协议、PRoWait协议和Prophet 协议的平均延迟分别为3 318、3 165和3 228 s。本文协议的平均延迟时间小于其余3种协议,这是由于本文协议根据节点相对于目的地的相遇值和距离来适当选择下一个转发节点。从图2中可以看到:当节点数量变化时,本文协议的平均延迟约为2 325 s,而HBPR协议、PRoWait协议和Prophet 协议的平均延迟分别为2 731、2 557和2 560 s。本文协议的平均延迟相对于其余3种协议分别降低了14.9%、9.1%和9.2%,性能较好。同样地,在图3中,当消息生成间隔逐渐增加时,本文协议的平均延迟呈现下降的趋势,且相对于其余3种协议而言,平均延迟最小。
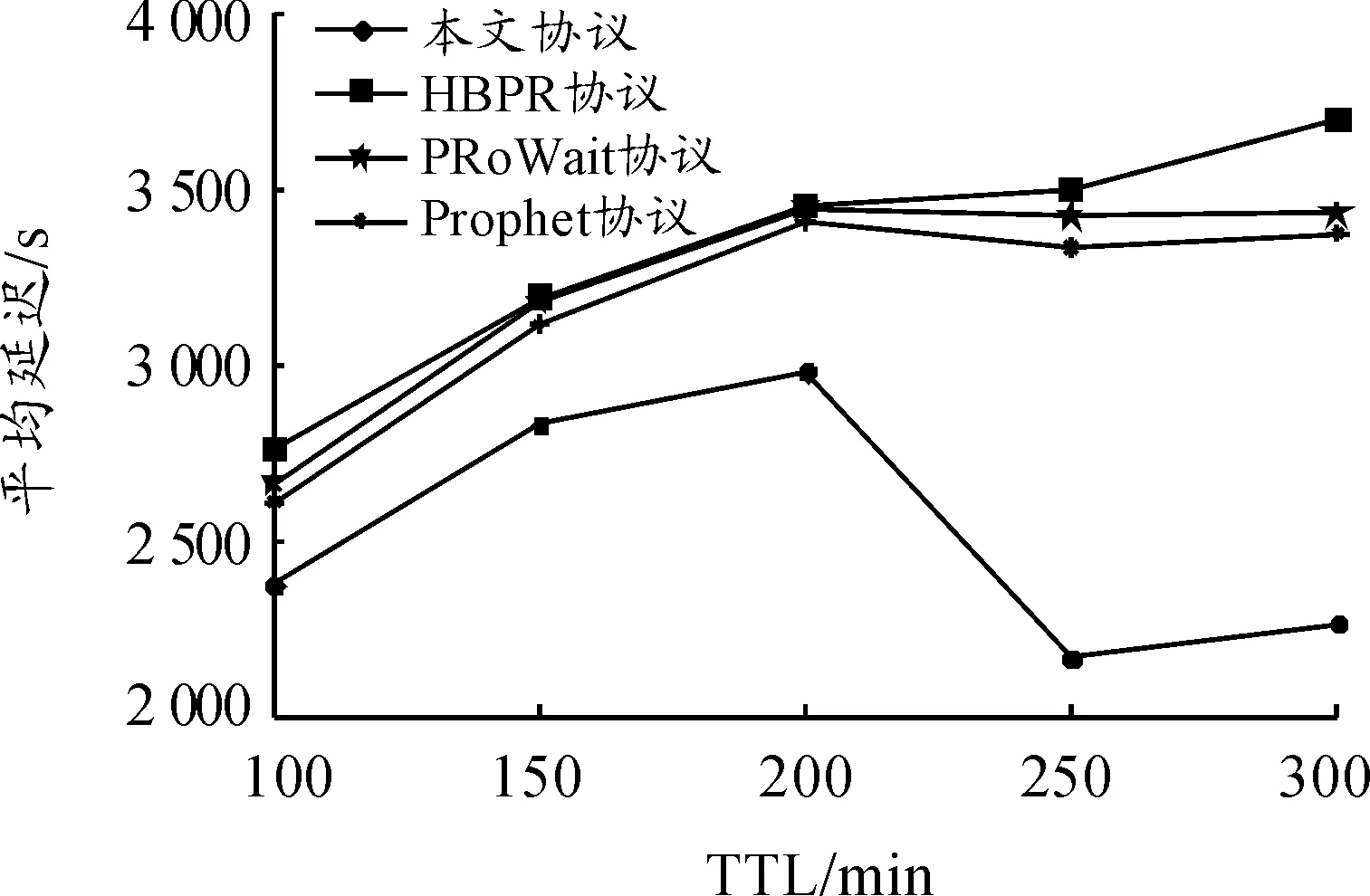
图1 TTL对平均延迟的影响

图2 节点数量对平均延迟的影响
2) 丢弃的消息数
图4~6显示了TTL、节点数量和消息生成间隔对于丢弃的消息数量的影响。从图4可以看出:在变化的TTL下,本文协议平均丢失消息数为91 041,HBPR协议、PRoWait协议和Prophet 协议的平均丢失消息数分别为111 440、108 362和104 110。本文协议平均丢失消息数相对于其余3种协议而言分别降低了18.3%、16.0%和12.6%。这主要是由于在本文协议中,当消息转发时,其首先保存在缓冲区中,当找到下一个最佳跳跃时,才从缓冲区中读取消息并转发。从图5中可以看到:当节点数量变化时,本文协议的平均丢失消息数为152 661,HBPR协议为189 743,PRoWait协议为174 374,Prophet协议为156 082,本文协议优于其余3种协议。从图6可以看出:在消息生成间隔逐渐增加时,本文协议的平均丢失消息数为69 335,与Prophet协议相差不大,均优于其余两种协议。在本文协议中,当消息生成间隔增加时,网络中生成的消息数量减少,导致丢弃的消息数量减少。
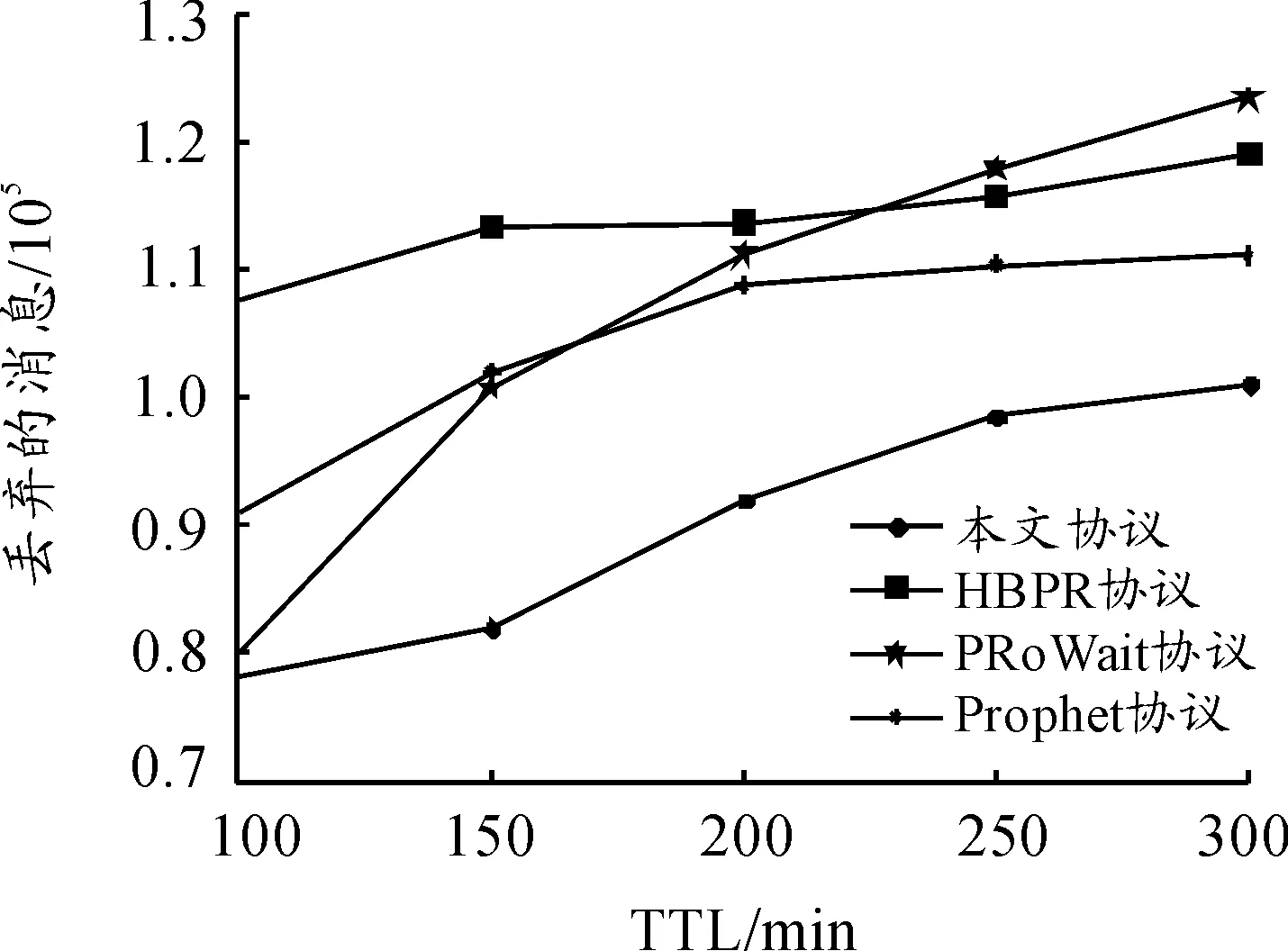
图4 TTL对丢弃的消息的影响
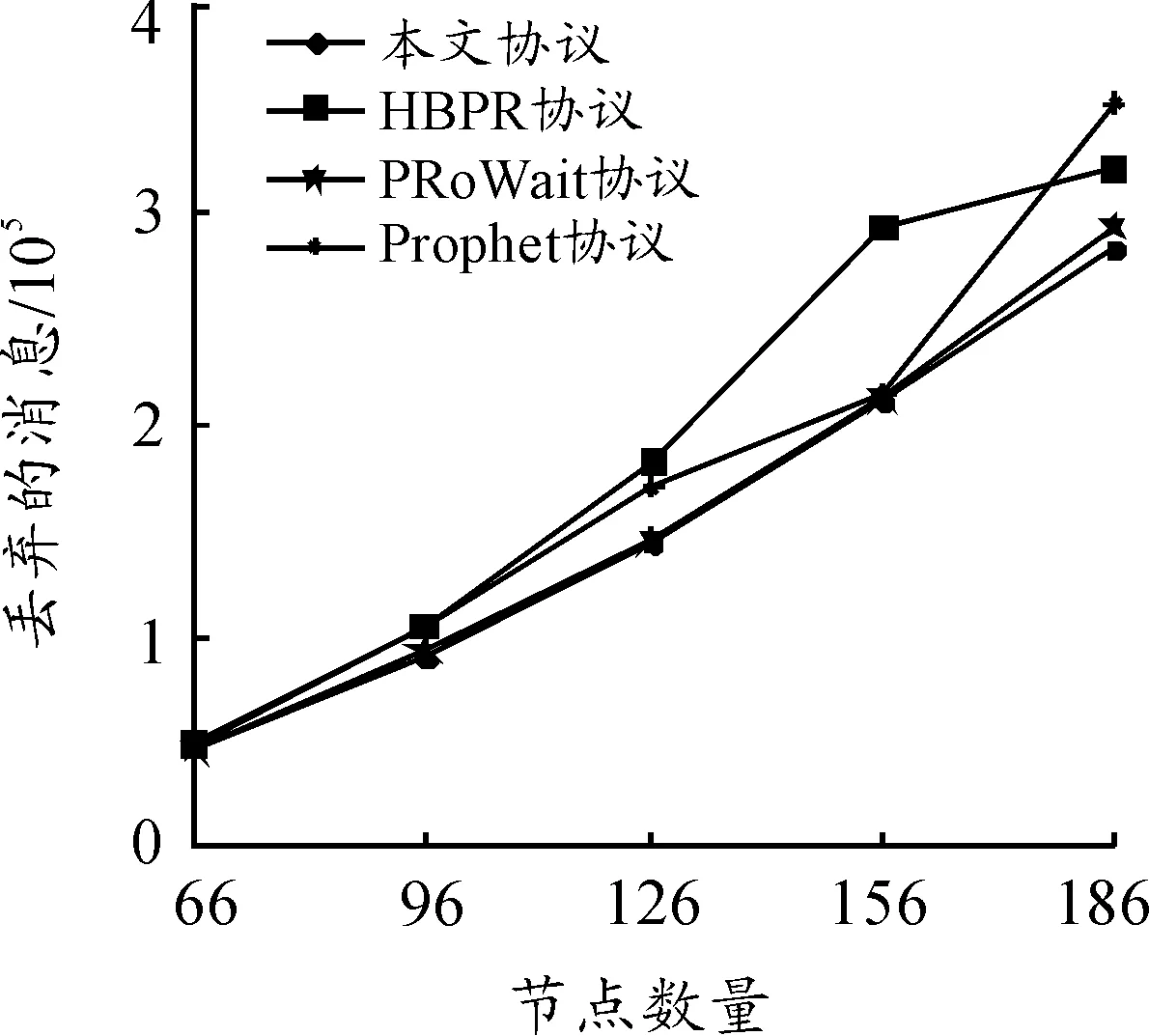
图5 节点数量对丢弃的消息的影响
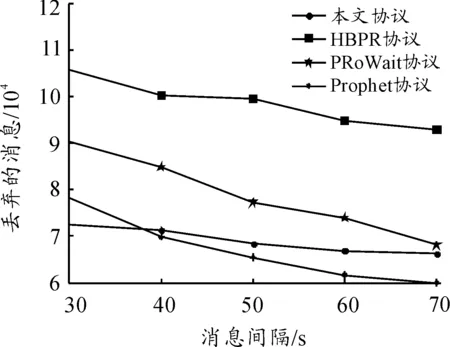
图6 消息间隔对丢弃的消息的影响
3) 开销比
图7~9描述了TTL、节点数量和消息生成间隔对于消息开销比的影响。在图7中,可以观察到当TTL变化时,本文协议的平均开销比为52.1,HBPR协议为70.1,PRoWait协议为58.2,Prophet协议为59.4。与HBPR协议、PRoWait协议和Prophet协议相比,本文协议的平均消息开销比最低。这是由于本文协议使用节点的上下文信息向目的地传送消息期间选择下一个可能的最佳跳跃的方式。从图8中可以看出:当节点数量变化时,所有协议的消息开销比也随之增加,这是由于当节点数量增加时,在网络中生成和转发的消息数量增加。在这种情况下,本文协议的开销比小于其余协议。从图9中可以看出:当消息生成间隔时间增加时,4种协议的开销比同样逐渐增加。本文协议的平均开销比为42.5,HBPR协议为71.4,PRoWait协议为51.6,Prophet为49.4,本文协议的开销比小于其余3种协议,因为本文协议使用基于上下文的机制来进行消息转发。
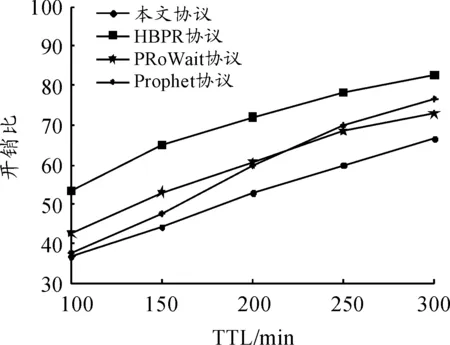
图7 TTL对开销比的影响
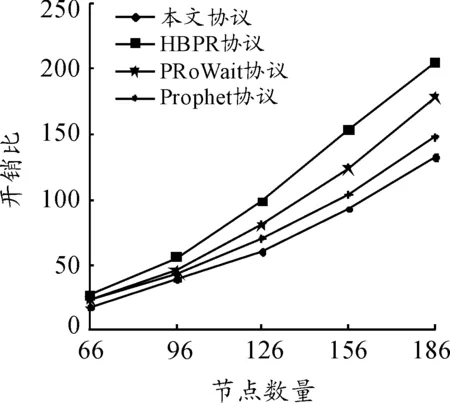
图8 节点数量对开销比的影响

图9 消息间隔对开销比的影响
4 结束语
本文提出了一种新的机会网络路由协议,它依赖于节点最重要属性的标识,即一个节点的相遇值以及该节点到目的地节点间的距离值。在该协议中,通过非零和合作博弈技术来确定给定节点的最佳消息转发者的选择。使用最佳响应分析方法,本文提出的协议可以从其可用邻居的集合中有效地识别和选择给定节点的下一个最佳消息转发器。仿真结果表明:在平均延迟、丢弃消息数和开销比等方面,本文协议的性能均优于Prophet、HBPR和PRoWait路由协议。
猜你喜欢
悦游 Condé Nast Traveler(2022年2期)2022-02-18
小天使·三年级语数英综合(2021年4期)2021-06-15
铁道通信信号(2020年9期)2020-02-06
通信产业报(2020年43期)2020-01-15
太原学院学报(自然科学版)(2019年3期)2019-09-23
太原科技大学学报(2019年3期)2019-08-05
科技与创新(2018年1期)2018-12-23
小猕猴学习画刊·下半月(2018年9期)2018-05-14
中国卫生(2014年12期)2014-11-12
中国卫生(2014年8期)2014-11-12
