
智能视频监控系统中行人再识别技术研究综述
2019-11-11 01:07胡正平张敏姣李淑芳孙德刚
燕山大学学报 2019年5期
胡正平,张敏姣,李淑芳,孙德刚
(1.燕山大学 信息科学与工程学院,河北 秦皇岛 066004;2.燕山大学 河北省信息传输与信号处理重点实验室,河北 秦皇岛 066004;3.山东华宇工学院 电子信息工程学院,山东 德州 253000)
0 引言
迄今为止,行人再识别仍是计算机视觉任务中相对年轻的研究方向,从最初不被广泛关注到近几年成果丰硕,可谓风华正茂。文献[1]于1961年首次提出行人再识别的概念,所谓再识别,即重新确认某一行人既定特征,该任务最初与多相机跟踪任务联系在一起[2]。
行人再识别技术作为智能视频监控系统的关键技术之一,能够实现跨视图信息关联的同时,还是一种通用的特征匹配算法,可为多种不同的机器视觉研究提供解决思路。例如,在无法借助成熟的人脸识别技术进行行人ID匹配的情况下,基于行人穿着、外貌等信息,辅以行人再识别技术,可提高复杂场景中行人身份匹配系统的准确性;此外,行人再识别还可以提供非侵犯性的身份一致性匹配方案。又如,公安执法人员可以在没有嫌犯人像信息的情况下,借助行人再识别技术及时地在案发地周围多地监控录像视频中搜索嫌犯,从而快速准确地定位嫌犯位置并实施抓捕。
除了广泛的应用价值,从学术角度看,利用前沿的计算机技术、借助强大的机器算法,完成对行人信息的高效挖掘和整合可推动其他计算机视觉任务的长足进步。在实际监控场景中,跨视图摄像机捕捉到的图像视角、行人姿态、背景复杂程度、光照条件以及像素分辨率等普遍存在差异,因此针对静态图像的鲁棒性特征提取变得困难,如何充分挖掘行人的有效信息并确定特征提取方法是一个关键问题。此外,如何针对行人这一特殊视觉匹配对象,设计能够有效度量特征相似度的特征匹配方法,更准确地排序是又一挑战性难点。完整的行人再识别框图如图1所示。
完整视频监控系统一般包括行人检测、行人跟踪、行人再识别3个主要模块,但受限于过去的硬件设备性能,早期大都将三者当作独立子任务研究,例如针对行人再识别问题,研究者着重提高再识别的准确率而假设前两个模块的工作已完成[3]。行人再识别的技术本质是使用计算机视觉技术确定特定行人是否存在于图像或视频序列中。该技术的难点主要存在于特征表示和距离度量两方面,其中特征表示包括光照条件复杂、局部背景遮挡、拍摄角度多变、行人姿势多变、衣着外观不固定等诸多问题;另外,距离度量阶段还有类间不同程度混叠、类内不同程度不对齐、训练样本有限、模型泛化能力较弱等挑战,有针对性的解决这些关键问题在行人再识别的研究中有巨大的科研和应用价值。

图1 行人再识别过程框架
Fig.1 Person re-identification framework
本文首先回顾行人再识别研究的发展历程;然后分别从特征表示、距离度量以及深度学习网络模型的角度总结目前出现的优秀算法;介绍几种常用的图像行人数据集、视频行人数据集以及性能评估指标;最后根据目前行人再识别的研究进展和存在的问题,预测未来的研究方向。
1 行人再识别研究概述
随着计算机视觉任务研究方法的不断更新,研究者针对行人再识别问题建立了不少性能良好的系统模型,行人再识别发展历程如图2所示。

图2 行人再识别主要研究历程
Fig.2 The main study history of person re-identification
早期行人再识别通常被当作多相机跟踪任务的子任务之一,行人图像的几何对齐与表观模型结合后与跨摄像头校准集成以实现跟踪目的。其中表观模型包括颜色、纹理、边缘等特征的提取,1997年Huang Timothy等人提出联系上下文的贝叶斯公式[4],该模型根据摄像机A中观察所得的目标表观特征预测摄像机B中该目标的表观特征,在某种程度上能够克服相机参数的差异,为行人再识别中表观特征的学习带来了新思路。“行人再识别”专业名词直到2005年才被Wojciech Zajdel等人首次明确提出[5],其意义被重新定义为 “重新确定一个离开观察视野区后再次进入的行人的身份”。该研究假定每个行人都有一个独特标签,首先利用动态贝叶斯网络对行人标签和不同表观特征的概率对应关系进行编码,当有行人目标重新进入观察视野区时,该行人身份ID可通过近似贝叶斯算法计算而得的后验身份标签的分布决定。作为行人再识别研究的首次独立尝试,该研究具有里程碑式的意义。
2006年,文献[6]提出在前景检测操作之后基于颜色、显著边缘直方图和Hessian-Affine兴趣点算子提取行人的表观特征,该工作的创新点在于:在前景检测操作中针对视频帧设计时空分割方法,并针对行人再识别子任务专门设计特征提取方法,而不再仅仅将其作为多相机跟踪的某一环节。其实验数据集包括由中度视域重叠的3个摄像头捕获的44个行人,虽然该工作实质上仍属于基于静止图像的行人再识别范畴,但是标志着行人再识别与多相机跟踪任务的正式分离,此后行人再识别开始成为一个独立的计算机视觉任务。
由于单图像中的行人特征有限,研究者从2010年开始尝试基于多帧图像的行人再识别模型的研究。文献[7]提出新颖表观特征提取机制,同一行人的多帧图像的表观信息被集中到一个高度信息化直方图加缩影特征(Histogram Plus Epitome,HPE)中,该特征融合了行人的全局以及细节特征信息。另外文献[8]利用分割模型检测前景之后再提取颜色特征,可以成功克服前景中行人主体外的干扰。随着所选帧数的增加,基于多帧图像的行人再识别模型相对于基于单帧图像的行人再识别模型可以提取更丰富的表观特征,对各种环境变化的鲁棒性更强。
基于多帧图像的行人再识别取得性能优化之后,越来越多的研究者开始尝试基于视频提取时间-空间特征,视频具有时间连续性,理论上可以挖掘到更多的行人辨别性特征。思路之一是将行人视频帧中的某段时间中的一系列动作为基元进行对齐,文献[9]利用此思路首先基于光流能量分解图像序列,为模型学习提供一组候选视频片段集,如此一来,在测试过程中系统将会自动选择最具区分性的片段进行匹配,充分利用了视频中包含的行人全局信息。然而基于视频的行人再识别研究充分利用时间信息的同时也存在一定的挑战,一般情况下,行人的表观特征例如衣服颜色会存在较大的差异,然而行走速度或行走周期的差异较细微,对应特征向量的类间距离更小从而变得更难区分。
2012年,基于深度学习方法的图像分类效果取得重大突破[10]。Hinton团队在ImageNet图像识别大赛中使用自己构建的AlexNet摘得桂冠,证明了深度学习在计算机视觉领域里不容小觑的实力,之后深度学习技术逐渐被迁移学习到行人再识别的研究中。国内代表性研究有,Ouyang Wanli等人提出共同学习特征提取,变形、遮挡处理以及分类等行人检测的关键过程,并提出一个新的联合深度网络JointDeep模型架构[11]。文献[12]则基于三元组深度多度量学习(Deep Multi-metric Learning,DMML)框架分别学习行人全局和局部特征,并基于梯度下降法训练多度量损失网络,为每一种特征单独学习度量函数。同时国外研究者Anelia A等人采用soft-cascade与卷积神经网络(Convolutional Neural Network,CNN)网络结合的方式得到性能优良的行人检测模型[13]。之后越来越多利用深度学习技术研究行人再识别的文章发表在国际重要会议CVPR、ICCV、ECCV、AAAI等和期刊TPAMI、TIP等上。
随着行人检测和再识别两个子任务的性能提升,逐渐有研究者将两者结合以求得更优异的性能表现。Xu Yuanlu等人首次将行人检测和再识别两个子任务结合研究,联合行人视频帧的共性和特性共同构造行人搜索模型框架[14]。此后2017年CVPR大会上,Xiao Tong等人也提出结合行人再识别过程的行人搜索问题,相对地说,行人搜索是将前端行人检测与后端行人再识别的匹配问题同时进行的综合创新[15]。经实验部分验证联合考虑行人检测和再识别比独立研究这两部分子任务可以获得更高的匹配率。
2 行人再识别相关问题
行人再识别模型通常包括行人特征提取、特征转换、距离度量等模块,若想提高整个系统模型的性能表现,可对各个模块的性能逐一改善,其中行人再识别问题中的研究重点聚集在特征表示和距离度量上,因此目前行人再识别研究领域的工作主要可以分类为:1)改进行人目标的特征表示方法,力求提取内容更丰富且鲁棒性更强的行人特征,从而可以更全面地描述行人固有特征;2)寻求更具判别力的距离度量函数或特征映射子空间,尽可能获得大类间距离和小类内距离。随着该研究的持续升温,从不同角度出发设计的各种方法不断出现,类别结构图如图3所示,接下来将对相关行人再识别算法做分类介绍。

图3 行人再识别类别结构图
Fig.3 The category structure of person re-identification
2.1 行人再识别特征提取
实际应用时,行人表观特征在不同应用场景中容易受场景光照、自身穿着、摄像视角、外部遮挡等因素影响,同时不同摄像设备还存在参数和分辨率不同等特点,这使得寻找鲁棒的行人再识别特征描述子成为关键的技术环节。
2.1.1低层视觉特征
常用的低层视觉特征主要有:基于RGB[16]、HSV[17]等颜色空间提取的颜色直方图;Gabor滤波器[18]、局部二值模式(Local Binary Pattern,LBP)等纹理特征;尺度不变特征(Scale-Invariant Feature transform,SIFT)等。
行人再识别研究中提取低层视觉特征时,通常采用分块机制,文献[10]基于人体的对称性和不对称性为人体局部特征建立加权算法,提取身体各部分的加权颜色直方图、最大概率区域以及高复发结构片段三种互为补充的细节特征。但因摄像设备视角差异的存在,一个背包行人的前后表观特征可能存在较大差异,若对每张行人图像均提取细节表观特征可能会带来过拟合问题反而导致误判。因此2007年,文献[19]定义了形状和表观上下文概念,通过模拟每个样本对象的表观空间分布区域,引入可实时计算包含所有给定样本类的图像区域间相似度的表观模型。行人再识别是一个全局与局部信息对识别都很重要的问题,具体的特征提取分块机制对特征的表现力也有着巨大影响。2008年,文献[20]提出首先将行人划分为几个稳定的特征提取水平条区域,然后在每个水平条区域提取颜色和纹理特征,同时注重全局与细节特征的描述。意大利维罗纳大学的Michela Farenzena等人利用人体左右对称性和上下不对称性建模的对称性设计局部累积特征(Symmetry-Driven Accumulation of Local Features, SDALF),并混合颜色直方图、区域颜色和高复发结构等互补特征[21]。具体的特征提取示意图如图4所示。局部特征相对于全局特征,更容易受光照、视角、行人姿势等因素的影响,因此从2013年开始,研究者在工作[22-23]中创新了行人特征块划分机制,该类方法使用固定步长的重叠子窗口在水平和垂直方向上滑动分块,然后从每个兴趣块中密集采样出LAB颜色直方图和SIFT特征。Das Abir等人结合行人特点划分特征块,直接从行人头部、躯干和腿部提取HSV颜色直方图,获得了更丰富的行人表观信息[24]。
相对于特征分块机制,更加具有表现力的特征描述符也很重要,Kviatkovsky J等人提出利用ColorInv进行行人再识别,颜色不变量ColorInv结合Log空间中的颜色直方图、协方差描述符,基于局部形状上下文描述子共同描述行人表观[25]。类似于利用上下文形状关系描述行人特征,将行人的颜色特征与颜色名称结合可实现对行人表观特征的语义描述,文献[26]引入基于颜色描述符的显著颜色特征,并利用此颜色机制对行人颜色特征进行全局描述,该颜色特征的RGB值对光照变化具有更强的鲁棒性。文献[27]提出局部最大概率特征(Local Maximal Occurrence Representation,LOMO),该特征融合HSV颜色直方图、尺度不变局部三元模式描述子,最大化人体局部颜色以及纹理特征在同一水平条出现的概率,为了处理光照变化,该算法还应用Retinex变换和尺度不变纹理算子。2016年,文献[28]提出一种层级高斯特征,利用特定的高斯分布来模拟每个特定行人兴趣块中的颜色和纹理特征,最终高斯集的特征仍然使用另一高斯特征表示,层级高斯特征充分利用一般颜色描述符协方差中不存在的像素特征平均信息,可自然地模拟行人兴趣块中的表观特征,该方法示意图如图5所示。
图4 对称性局部累积SDALF特征示意图
Fig.4 Schematic diagram of SDALF feature

图5 局部最大概率LOMO特征提取示意图
Fig.5 Schematic diagram of LOMO feature extraction
2.1.2语义属性特征
所谓属性特征,即借鉴人类鉴别两人是否为同一个人的思路,对待匹配两人的发型、外套颜色、裤子鞋子等特征进行计算机语言描述。例如图6所示女生,假设定义可描述的6个属性(是否女性;是否长发;是否穿短裙;是否背包),该女生对应的属性特征向量为[1 1 1 0]。2012年,文献[29]首先标注了15种表观语义属性特征,利用支持向量机(Support Vector Machine,SVM)对某一行人A的语义属性特征作属性加权,然后再与几种其他低层视觉特征融合作为该行人的特征描述向量,该方法首次将低层视觉特征与中层语义特征进行融合,提取更为丰富的行人固有信息从而提高了行人特征描述子的鲁棒性。

图6 行人示例
Fig.6 Person example
除了已定义的行人属性,属性特征中的隐含关联也引起研究者的注意,文献[30]中提出将交叉视图行人数据的低层特征与中级属性特征集成之后投影到连续的低秩属性空间,该低秩属性矩阵具有较小的类内差和较大的类间差,可以纠正不精确的属性并恢复丢失的属性,使属性向量具有更大的区分性,在iLIDS-VID和PRID两大具有挑战性的数据集的Rank-1分别提高了8.5%和3.5%。为进一步利用低层视觉特征的分块思想对属性特征进行精确描述,Shi Zhiyuan等人使用最近邻分割算法对行人图像进行超像素划分后再定义多种属性特征,采用传输语义进行行人再识别[31]。使用中层语义特征前,作为数据准备,必须对行人的属性特征进行人工标注,这是一项耗时费力的工作,为方便研究,Li Dangwei等人收集了一个具有丰富行人属性注释的大型数据集,以此来促进基于属性特征的行人再识别的研究[32]。
2.1.3时间-空间特征
行人静止图像中并不包含时间信息,若单靠颜色和纹理来表示行人表观特征,在遇到外部遮挡、光照变化、摄像角度变化等情况时识别效果又会受到影响,因此基于视频帧提取行人运动信息成为行人再识别算法中特征提取部分的又一研究方向。
行人表观特征偶尔存在服装颜色相似等情况,但步态和行走周期相对表观特征来说是较为独特的行为特征,因此一些研究人员提出利用步态信息作为识别的关键[33],该类方法首先利用视频帧提取行人步态信息,辨别行人行走步态之间的细微差别,从而达到区分不同行人的目的,其中提出的平均池化时间对齐集合表示算法(Avg-Temporally Aligned Pooling Representation,Avg-TAPR)在数据集iLIDS-VID和PRID 2011的实验中将Rank-1提高到55%以及73.9%。另外还有一种比较常见的时空信息提取方法,基于人体结构信息,利用人体不同区域的空间直方图和协方差特征描述视频帧之间的空间关系。早在2006年,文献[8]中首先将行人视频帧进行前景分割,利用一个时空分布图标记时间-空间稳定区域后再提取特征,提高了针对低分辨率、遮挡、姿势、视角以及照明变化的鲁棒性。同时期,Hamdoun Omar等人提出使用SURF局部特征来检测和描述短视频序列中的特征兴趣点,并利用KD树对这些短视频序列特征依次进行索引以加速匹配过程,但提取SURF特征使得特征构成较为单一,仍旧限制了系统性能的进一步提高[34]。
上述工作大都基于多相机视频帧间的空间信息构建特征描述子,更注重行人视频帧的空间联系,而在最近的一些研究中,将时间次序关系加入特征提取模型成为研究趋势。2014年,文献[10]提出通过提取光流能量分布图检测行走周期,然后使用时空梯度方向直方图(Histogram of Oriented 3D Gradient, HOG3D)[35]和步态能量图像(Gait Energy Image,GEI)[36]描述行人运动特征。但是随着数据集的增大,行人的行走周期也非常接近以至于难以分辨,只提取行人的步态特征显然不能满足行人较多的情况,You Jinjin等人在视频水平提取HOG3D特征,融合基于行人图像水平提取的表观特征后构成行人的时间-空间特征,该研究利用了所有可用的行人视频帧,表观特征提取阶段还加入特征池化以保证特征的丰富性[37]。文中顶推距离度量学习算法(Top-push Distance Learning, TDL)被用来解决距离度量问题,顶推约束强制对顶级匹配进行优化,可使模型更有效地选择判别性特征来准确区分不同行人。TDL算法处理前后特征分布对比示意图如图7所示。

图7 TDL处理前后特征分布对比图
Fig.7 Comparison of feature distribution before and after TDL
2.1.4深度特征
随着深度学习的发展,行人再识别领域内也逐渐利用深度神经网络自动提取行人本质特征。2014年,文献[12]首先将输入图像划分为三个水平条,经过两层卷积层和一个全连接层得到激活响应,然后将基于所有水平条提取的特征融合后以向量形式输出,最后在距离度量阶段使用余弦距离计算两个输出向量的相似度。Michael Jones等人利用分类问题的常用思路,建立一个深度神经网络系统,通过计算输入图像和样本特征之间的差异设定阈值来判断是否属于同一行人[38]。传统深度网络都是提取整体行人特征再结合反馈调整提取机制,文献[39]则首先将行人图像分块,利用多分支卷积神经网络自适应提取深度特征,根据深度特征间的相似度排序判断行人是否为同一个,自适应特征提取网络的使用使得计算速度被提高。
传统特征提取方法可以分别提取低层视觉特征和中层语义特征,深度网络同样也可以考虑中层语义特征的提取。文献[40]尝试利用深度卷积体系结构自适应地学习人的中层特征,还可以自动学习所有输入特征的对应潜在关系,成功地将传统方法中的有效特征迁移到了深度网络的应用中。Xu Fangjie等人提出利用卷积自动编码器进行无监督的特征提取,之后交由多个属性分类器进行属性分类,结合属性类别的映射关系表计算最终类别的判定[41]。属性特征的设计将在很大程度上影响再识别效果,如何实现数据驱动的属性生成是提取属性特征的改进方向。Wu Lin等人提出将SIFT特征和颜色直方图等低层视觉特征汇总到Fisher向量中,经过一层全连接层得到最终的行人特征向量,最后使用线性判别分析(Linear Discriminant Analysis,LDA)作为目标函数进行距离度量[42]。
2.1.5特征提取方法总结
综合多种特征提取方法的一般过程,可以看出,特征提取器若鲁棒到极致,则趋于刻画一些无关紧要的特征,如此,针对同一行人,即使差异较大的图像表示也会比较接近,但同时这也会导致不同行人特异性的丢失,降低特征的判别力,反之亦然。恰恰说明这两个切入点在一定程度上是互补的:只有探索同时具有高鲁棒性和高判别性的特征,并基于一个合理角度找到两者之间的折中,才能更从容地应对各式各样的行人图像,使模型达到真正的鲁棒。
上述几种常用特征描述方法各有优劣,针对不同特点的数据集可以实现不同的性能表现,各个方法的特点及优缺点比较总结如下:1)颜色和纹理特征融合后作为特征描述子,一定程度上可以克服行人表观差异,但在实际应用时仍存在一些问题:颜色特征在不同光照环境下差异较大,这会导致距离度量阶段的匹配出现差错;相机设备参数设置不合适时,不同颜色在视觉上会很接近而导致误判;视频中出现的行人分布面积较小,纹理特征比较模糊,因此难以提取到具有强判别性的纹理特征;将行人分块进行特征提取虽然较好地克服了由于视角不同而带来的视觉差异,但并不能克服外部遮挡的影响。2)与低层视觉特征相比,语义属性特征可以更好地应对环境以及背景变化,但由于摄像设备的像素质量不高以及取像距离较远等问题的存在,计算机准确判断男女并进行描述的技术难度较大。3)模型提取空间、时间特征,或将两者结合当作行人的辨别性特征,目的都是尽可能寻求更加具有区分性的视频特征。但在实际应用时,时空特征容易受行人姿势、光照、行人数量规模等影响,从生物学角度分析,当行人数据集的规模逐渐增大时,行人行走姿势之间的相似性也会随之增加,从而限制时空特征的判别性。4)深度神经网络与传统神经网络相比,具有无监督情况下准确感知高层特征的优势,该特点恰恰适应了行人视频监控中存在大量无标签数据的情况,为行人再识别带来了新的希望。然而大多数行人再识别数据集都只为目标行人提供两张可用图像,用来训练网络的数据不够充足;并且深度网络系统的参数目前仅仅通过经验来设置,若要将系统应用到实际中,其中的参数设置等细节需要相关专家的专业指导,因此它的大规模应用将是一条具有挑战的道路。
2.2 行人再识别度量学习
不论哪种特征提取方法,其实质都是按某种规则将图像固有的特征信息以向量形式表示,在特征空间中,如何计算相似特征向量间的距离成为另一研究要点。实质上,度量学习与特征提取互为补充,最终的研究目的是增强特征描述子的鲁棒性和判别性,将原始图像投影到更理想的分类空间中。
传统方法中,利用L2范数、巴氏距离、余弦相似度等方法计算得到特征向量之间的距离或相似度之后,可以采用K近邻算法完成识别匹配过程。这种方法计算速度较快,但识别率普遍不高,因此在行人再识别问题中的应用并不普遍。在行人再识别研究中,大多数方法都属于监督式的全局度量学习范畴。所谓全局度量,其目的是针对全部特征使类间距离尽可能大,同时类内距离尽可能小,在距离度量中最常使用的是马氏(Mahalanobis)距离,两个特征向量xi和xj之间的平方距离可以描述为
d(xi,xj)=(xi-xj)TM(xi-xj),
(1)
其中,M是一个半正定矩阵。
2.2.1图像水平的度量学习
许多经典距离方法大都基于公式(1)引入,例如文献[43]中提出给匹配对设置边界阈值,并且惩罚那些侵入边界的边缘临近值,这种方法称为大间隔最近邻(Large Margin Nearest Neighbor,LMNN)分类算法,该方法是马氏距离度量学习算法的典型代表。为了避免LMNN中出现的过拟合问题,Zheng Weishi等人提出利用信息理论度量学习方法(Information-Theoretic Metric Learning,ITML),通过优化两个多元高斯分布间的相对熵来学习度量矩阵,确保学习到的距离函数既满足给定相似性约束又接近实际距离[17]。度量学习算法中的一大特点是,正样本对的数量相对比较有限,因此数量巨大的负样本对学习过程的影响重大。Guillaumin Matthieu等人将度量矩阵的学习描述为逻辑回归问题,最大化训练数据中的正负样本对的分类概率,从而达到学习度量标准的目的[44]。2015年,Liao Shengcai等人推导了一种具有半正定(Positive Semi-Definition,PSD)约束和非对称样本分类加权策略的度量学习方法,并基于Log逻辑损失函数应用加速近邻点梯度算子寻找待优化距离函数的全局最小解,该算法充分利用了负样本对的非对称性,加权策略增大了特征区分性[45]。进一步地,为降低行人图像中普遍存在的特征不对齐问题,Sun Chong等人同时学习度量矩阵和空间分布变量,引入垂直偏差、水平偏差以及腿部变化等三种潜在变量来描述再识别问题中存在的不对齐特征,两个行人特征之间的距离通过与潜在变量距离最小化给定的距离函数来确定[46]。另一层面看,不对齐的特征也是行人图像的特性之一,若能将其与共性结合共同描述行人,可以作为补充特征利用,为此文献[47]提出同时考虑图像对之间的特性和共性,并且得出不同类图像对之间的协方差矩阵可以从同类图像对之间的协方差矩阵中推断而出的结论,该结论进一步推动了行人再识别技术在大数据集上的研究。
除了学习判别性较强的距离度量标准外,部分研究者专注于学习区分性子空间[48]。Liao Shengcai等提出将交叉视图数据投影到一个公共低维子空间w中[27],利用类似于线性判别分析的计算方法[49],该方法中学习子空间时将待优化目标函数简化为
(2)
其中,Sb和Sw分别是类间和类内散布矩阵,在学习到的子空间w中,使用简单而直接的度量学习(Keep It Simple and Straightforward Metric Learning,KISSME)算法学习距离函数。KISSME算法无需迭代优化就可以寻求到闭合形式的解,但缺点是当特征向量的维度较高时,算法运算时间及速度等容易受影响。为了克服该算法的这一特点,文献[27]利用视网膜Retinex理论和最大化局部特征出现分别处理光照和视角变化,然后通过最大化投影矩阵投射后的同类与不同类样本对之间差异的方差比学习一个距离度量子空间。文献[50]利用跨摄像头数据学习一个交叉视图映射模型,利用学习好的映射模型进行行人特征变换,从而消除不同摄像机拍摄区域的特征差异,具体的模型优化框图如图8所示。为学习具有较强区分性的子空间,Zhang Li等人采用Null Foley-Sammon变换学习满足零类内散射和正类间散射的判别零空间,增强了子空间判别性[51]。
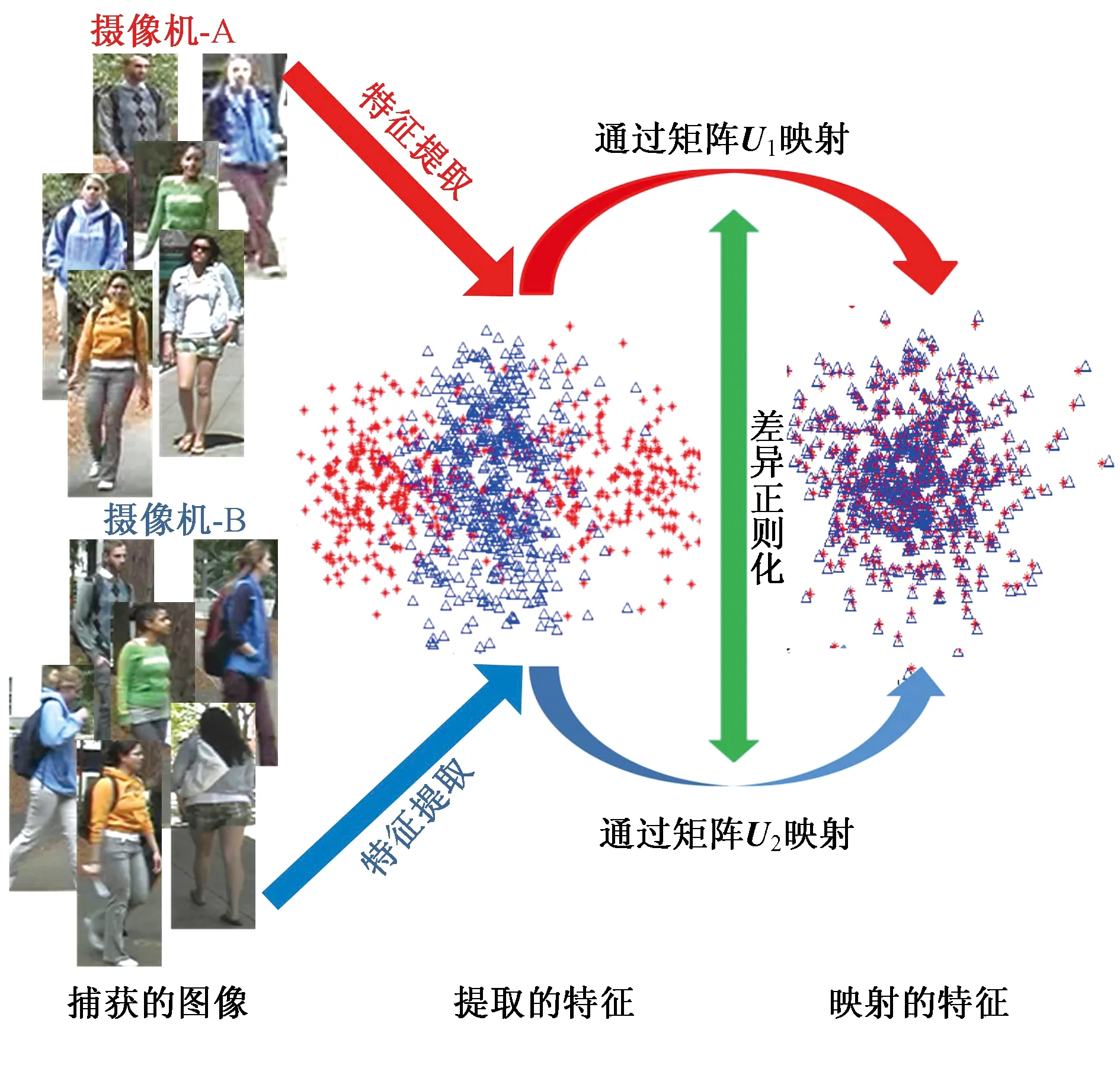
图8 交叉视图映射模型
Fig.8 Cross-view mapping model
还有一部分研究为降低计算复杂度从而减少系统匹配时间,提出省去KISSME算法之前的必要降维步骤,文献[52]提出了成对约束成分分析(Paired Constraint Component Analysis,PCCA)算法,该方法学习一个线性映射函数以便能够直接处理高维数据,从而减小了计算复杂度。进一步地,文献[53]又对子空间投影方法PCCA进行了改进,提出应用效果更好、精度更高的正则化成对约束成分分析(rPCCA)算法。学习一个可以直接计算特征表达向量间的相似度的模型也是解决行人再识别问题的一个常用思路,Chen Dapeng等人将特征经过二次多项式函数的特征映射,从而实现了马氏距离与双线性相似度融合的模型[54-56]。使用支持向量机SVM进行分类也是当时研究者的思路之一,Prosser Sateesh等人提出首先学习一组弱RankSVMs分类器,之后再将这些弱分类器级联组成强分类器,通过此强分类器来完成分类即再识别任务[17]。利用从训练数据中学习而得的词典表示行人是来自与人脸识别的解决思路,Lisanti Giuseppe等人采用迭代策略学习稀疏编码,匹配过程则采用排序法[57]。文献[58]利用每个行人的特征特性为每个行人ID学习特定的支持向量机分类器,提出利用最小二乘耦合字典算法来学习行人的特征词典映射函数,在常用数据集中,该研究取得了较大的性能优化结果。Pedagadi Sateesh等人将近邻保持映射(Locality-Preserving Projection,LPP)融入传统的费舍尔判别分析(Fisher Discriminant Analysis,FDA)中,提出了局部费舍尔判别分析LFDA,该方法在多个数据集中取得了不错的效果[59]。
2.2.2视频水平的度量学习
在基于视频的行人再识别过程中,除了图像特征提取和距离度量两个阶段,还有一个必要过程,即考虑对多帧图像的特征做何种距离度量会使特征更具区分性。
其中一类比较简单的方法,直接选取两个图像特征集合中距离最近的图像对之间的距离作为集合间距离,该策略被称为近邻点法。例如文献[16]提出表观特征的上下文学习方法,注重行人视频帧中的表观特征里所隐含的空间分布模式,该测度使特征能够反映更多的空间信息。相对近邻点法,平均分布法更为有效,该方法直接计算两个图像特征集合中所有的图像对之间的距离,最后取这些距离的均值作为两个集合间的距离。其中比较具有代表性工作如文献[60],该文献提出将同一行人的两不同视角下所得的图像特征向量级联之后,利用径向基函数核的支持向量机做二分类操作,支持向量机输出的分数可作为排序参考。
另一种可行方法是集合建模法,即以一种显式的表征形式来表示几何特征,通常情况下直接取一个典型表达刻画整个集合的特征,该典型表示的提取方法有两种,其一是针对视频时空表观特征设计更加全面的表示模型;另外一种是直接对所有图像的特征求平均作为代表。
基于静止图像的行人再识别问题中存在类间距离和类内距离的概念,在基于视频的行人再识别研究中同样存在类似的距离概念,文献[61]同时学习视频内和视频间距离的度量方法,这使视频表示变得更为紧凑且区分性更强。Wang Taiqing等人利用RankSVM从行人的不完整图像序列中自动选择最具辨别力的视频片段,计算可靠时空特征的同时学习人物ReID的视频分级功能,从而实现了RankSVM在视频行人再识别中的应用[62,9]。
2.2.3度量学习方法总结
综合图像、视频水平的度量学习方法,可以看出,现有研究大都从距离概念定义、投影子空间学习、特征对齐等角度出发,对行人再识别的度量学习方法进行创新和扩展,逐步提出很多行之有效的经典算法。总结目前度量方法的特点如下:1)目前出现的大部分度量学习方法大都基于行人特征向量间的距离度量即特征相似度概念进行模型设计,倘若受特征提取器的影响,行人特征向量中出现了关键信息缺失的情况,该类度量方法的准确度将会大打折扣。因此,基于特征序列提取行人更加立体和全面的表观及运动细节,并辅以有效的序列相似度匹配方法,将成为未来针对度量学习角度的主研方向之一。2)大多数现有度量方法的模型稳定性和实验结果的鲁棒性需要借助大量的标注数据集,然而在现实跨摄像头监控环境中,对行人样本的完整采集已属不易,对大量行人样本的标注也是一项艰巨的任务,样本不足增大了高准确度度量方法的学习和优化的难度。因此如何利用大量未标注行人数据,学习合理高效的度量方法模型,使其在小数据集中仍有较好的泛化能力,是未来针对度量方法的又一主研方向。
2.3 常用深度学习模型
文献[12]最早将深度学习用于解决行人再识别问题,在行人再识别研究中,常用的深度CNN模型有分类模型[10]和暹罗网络模型[63]。文献[9]利用深度网络提取行人特征,首先将将行人图像划分成3个图像区域,然后经过两组参数共享的卷积层和一个全连接层进行融合,最后输出特征向量。香港中文大学的Li Wei等人首次将深度神经网络应用在行人再识别问题中,提出了DeepReID模型,用深度神经网络来联合处理误对齐、光度学变换、几何变换、遮挡和背景杂乱问题,并取得了不错的效果[64],模型示意图如图9所示。方法[10]则提出了一种增加了部件匹配层的改进网络结构,部件匹配层的引入能够将两幅图像上对应位置的卷积响应相乘。文献[65]将暹罗网络与长短时记忆模型融合,在分块基础上,记忆模型的引入可以自适应地记忆图像之间存在的空间关系,从而得到更有区分性的深度特征。暹罗网络的缺点是仅仅考虑成对行人图像的标签,然而在最近公布的行人数据集中行人图像大都大于两张,此时分类模型就显得更加适用于行人再识别问题。文献[66]使用Softmax代价函数,结合每个全连接神经元的影响系数和Dropout影响系数,共同学习而得的通用分类网络可以有效提高行人再识别系统的识别准确率。

图9 深度再识别DeepReID模型示意图
Fig.9 DeepReID model diagram
由于视频运动特征的有效性,若能将运动特征和深度特征提取网络综合考虑,理论上会得到更优秀的性能。文献[67]提出结合CNN及RNN的循环卷积网络(Recurrent Convolutional Network),首先使用CNN网络模型从输入视频帧中提取特征,然后将特征作为RNN网络的输入,得到视频帧之间隐含的时间信息,最后经过最大或者平均池化对输入视频帧的特征进行整合,得到视频帧特征的鲁棒表达。实验结果表明,该算法在iLID-VID以及PRID 2011两大数据集中的Rank-1提高到58%和70%,比传统深度方法基线高出将近20%。
如上所述,大多数现有的研究都将行人检测和行人再识别作为独立部分来改进,但行人检测中抓取到的行人框的质量和行人跟踪中追踪器的准确性将直接影响行人再识别的准确度,分开研究并无法保证实际应用时系统的高效性和实时性。
深度学习模型的端到端工作模式使这两者的融合成为可能,一个包含行人检索和行人再识别模块的端到端系统示意图如图10所示。自工作[14]之后,文献[68]和文献[69]引入基于大规模数据集的端到端行人再识别系统模型,这两个系统模型均采用原始视频帧作为输入,在原始视频帧中直接进行行人检测,将抓取到的行人框构成行人再识别的数据集,而不再仅仅局限于提升行人再识别模块的性能。

图10 一个包含行人检索和行人再识别的端到端系统
Fig.10 An end-to-end person re-ID system that includes person detection and re-identification
基于深度学习的静止图像行人再识别的主要瓶颈在于早期行人图像数据集的数据量较小,数据不足导致训练不出性能更优良的深度网络模型。基于深度学习的视频行人再识别在数据量上完全不用担心,解决要点在于采取何种策略对不同的行人视频序列进行匹配。
3 常用数据集及评价指标
3.1 数据集
过去几年发布了许多基于帧图像的行人数据集,其中常用的基于图像的行人再识别数据集汇总如表1。最先发布的是VIPeR[70]数据集,它包含632对行人的1 264张行走图像,该数据集是在室外环境中经两个角度不同的摄像设备采集而得,背景、光线、角度等的变化丰富,在行人再识别的研究中非常具有挑战性,因此到目前为止该数据集是应用最为广泛的行人数据集之一。之后陆续发布的行人数据集尽可能地涵盖了各种实际应用场景,例如,iLIDS[71]收集了机场大厅中来往匆匆的行人图像,行人目标的年龄段分布广泛;CUHK01[72]、CUHK02[73]、CUHK03[64]和Market-1501[74]收集的多为大学校园的行人,衣着特色变化明显的年轻人较多。其中CUHK01数据集包含971个行人的3 884幅图像,采用人工标注方式产生,因此图像质量很好;Market-1501数据集包含由6个相机拍摄的1 501个行人的32 668幅图像,采用部分变形模型自动检测算法标注行人,有些行人图像只包含了行人的身体部件,但因该数据集规模较大,深度学习模型常采用它作为训练集。
行人再识别研究中常用数据集详情汇总如表2所示,部分数据集示例如图11所示。其中MARS[75]数据集非常值得一提,它是到目前为止行人再识别研究领域内规模最大的数据集,由清华大学的Zheng Liang等人在一家校园超市门口自设角度不同的六台摄像机录制而得,MARS数据集中包含的是连续的视频帧,共包括1 261个行人的17 467段视频片段,共有行人图像1 067 516张,由此可见其规模之大。该数据集的行人图像标注工作全部由计算机使用部分变形模型自动检测算法(Deformable Parts Model,DPM)完成,也存在严重的行人误检、较多的错误标注和图像噪声,不过这种特点使得它成为近期行人再识别研究中最具挑战性的数据集之一。
表1 部分常用基于图像的行人再识别数据集
Tab.1 Some image-based person re-identification data sets

数据集名称发布时间行人总数图像总数摄像头个数采集场景VIPeR[70]20076321 2642室外校园iLIDs[71]20091194762室内机场CUHK01[72]20129713 8842室内外校园CUHK02[73]20131 8167 26410室内外校园CUHK03[64]20141 46713 1642室内外校园Market-1501[74]20151 50132 6686室外校园
表2 部分常用基于视频的行人再识别数据集
Tab.2 Some video-based person re-identification data sets

数据集提出时间行人总数视频片段行人框总数相机个数采集场景PRID 2011[76]201120040040k2室外步行街ILIDS-VID[9]201430060044k2室内机场MARS[75]20161 26120 7151M6室外校园
综合近年来陆续发布的数据集的特点,可以总结出以下发展趋势:1)发布时间比较连续且近几年发布的数据集的规模在不断增加,行人的形象类别越来越丰富;2)各数据集的采集场景在不断变化,少有重复。要实现行人再识别在实际中的应用,具有较多难点,这也促进了不同场景内更大规模数据集的陆续发布;3)行人边框逐渐由行人检测算法检出而不是人工标出,但同时带来了行人误检、误对齐等问题,这给自动检测算法的研究提出了更高的要求;4)采集行人图像的相机个数越来越多,角度变化越来越多,包含的图像信息也越来越丰富。

图11 多数据集行人图像示例
Fig.11 Pedestrian image examples
3.2 评价指标
行人再识别系统目前常用的评价指标主要有累积匹配特征(Cumulative Match Characteristic,CMC)曲线和Rank-N表格。如图12 CMC曲线示例所示,CMC曲线横轴对应待查询样本的排列序号,纵轴对应概率值即平均精度,例如CMC曲线上的任意一点(k,p)对应的实际意义是指针对查询集中行人A的某张图像,在行人候选集中选出相似度最高的前k张图片,其中包含查询目标行人的概率值p,由全部N个查询样本得到的结果统计而得:
(3)
其中,l(·)表示指示函数,mi是指第i个查询样本对应的待查询前k张图片中与它同类别的样本序号。当横坐标对应相等时,不同算法对应的纵坐标越大,表明识别效果越好,并且随着横坐标的增大,纵坐标表示的准确率呈递增趋势。Rank-N表格是CMC曲线上不同算法识别率的数字直观表示,一般实验中考虑Rank-1,Rank-5,Rank-10和Rank-20所对应概率值,根据实际意义Rank-1代表模型系统真正的行人再识别能力。

图12 CMC曲线示例
Fig.12 CMC curve example
3.3 常用经典方法性能对比
综合考虑上述各有效方法的优劣,将当前几种表现良好的经典算法在VIPeR数据集中的性能对比、在PRID以及CUHK 01数据集中的性能对比、在视频数据集PRID 2011及iLIDS-VID中的性能对比分别汇总如表3~5所示。
表3 部分算法在VIPeR数据集中的识别结果展示
Tab.3 Some algorithms′ CMC rank results on VIPeR dataset%

算法Rank-1Rank-5Rank-10Rank-20KISSME[16]23.3552.9567.5181.78ITML[17]11.6131.3945.7663.86ELF[20]12.0031.0041.0058.00SDALF[21]19.8738.8949.3765.73LMNN[43]6.2319.6532.6352.25PCCA[52]11.9836.7152.1071.41rPCCA[53]16.0544.0961.6778.24LFDA[59]17.9644.3860.0976.17
表4 部分算法在PRID和CUHK 01数据集中的识别结果展示
Tab.4 Some algorithms′ CMC rank results on PRID and CUHK 01 datasets%

算法PRID数据集CUHK 01数据集Rank-1Rank-5Rank-10Rank-20Rank-1Rank-5Rank-10Rank-20KISSME[16]16.2440.3053.6168.7715.435.8447.9060.48PCCA[52]12.1835.1650.2067.5610.9930.8743.4957.93rPCCA[53]18.5445.0260.0366.1414.7138.6952.3466.65LFDA[59]15.3137.0150.1064.4013.1129.8339.9651.86
表5 部分算法在视频数据集PRID 2011和iLIDS-VID中的识别结果展示
Tab.5 Some algorithms′ CMC rank results on PRID 2011 and iLIDS-VID datasets%

算法PRID 2011数据集iLIDS-VID数据集Rank-1Rank-5Rank-10Rank-20Rank-1Rank-5Rank-10Rank-20KISSME[16]34.3861.6872.1381.0136.5367.8078.8087.07SDALF[21]5.2220.7732.0247.936.3418.8727.1937.34Avg-TAPR[33]68.6494.6197.4498.9355.0287.5693.8897.20TDL[37]56.7480.0087.6493.5956.3387.6095.6098.27LMNN[43]27.1953.7164.9475.1728.3361.4076.4788.93LFDA[59]43.7072.8081.6990.8932.9368.4782.2092.60
由表中结果可知,相对于基于单帧图像数据集,基于视频数据集训练优化的模型具有更好的性能表现。实际应用中的视频流包含丰富的行人细节信息,因此以多帧图像作为集合的行人再识别有着更好的实用性与准确性。当前大多数基于视频行人再识别的方法,在集合表示和距离度量方面往往比较直接,限制了性能的进一步提升。如何在充分利用视频帧图像的细节信息,缓解行人姿态变化、遮挡等带来的负面影响的同时,减少噪声和冗余信息的过多引入,防止模型过拟合将是下一阶段行人再识别研究面临的主要挑战。
4 存在问题与趋势展望
本文回顾行人再识别的发展历程,介绍基本任务的同时,从不同研究方法角度出发将该问题按照基于特征提取、距离度量、深度学习网络等方法进行分析与总结。此外本文还介绍了几种常用行人数据集以及目前使用的性能评价指标;最后对行人再识别目前研究存在的问题和今后趋势作进一步展望。
到目前为止,现有行人再识别模型在某些小规模数据集上的识别效果已经接近人类的识别能力,但随着监控网络规模的不断扩大,研究中的数据集规模还远未达到实际需求。而且实际应用对视频内容的自适应智能化分析要求越来越高,因此从,长远的研究和应用角度来看,未来行人再识别的研究可能主要围绕以下几个方面进行:1)收集更大的行人数据集、寻求更精确的行人检测算法。在保证特征描述子的鲁棒性和度量学习方法的判别性前提下,为接近实际应用场景中的规模,尝试提出大规模数据集。理所当然,若自动检测算法的精度比较低,将会带来很多行人视频帧数据集中的错误标注,随之而来的是行人再识别阶段的误判和再识别准确率的降低,但是目前的自动检测算法的精度远不如人类手动剪裁,因此提出较大规模数据集的同时,还应该研究出应用效果及精度更高的检测跟踪算法。2)与其他生物识别技术结合。随着摄像技术的发展,远距离清晰拍摄或者逆光拍摄逐渐也会成为可能,因此可以在再识别模型中加入人脸识别,来辅助再识别准确率的提高。3)减少算法用时,提高识别速度。尽管在小规模数据集中几乎可以忽略识别时长,但随着数据集规模的增大,识别速度也是一个需要顾及的性能评价指标,应尽可能保证识别效果的同时提高识别效率。实际应用时,总是希望能在较短时间内准确定位目标行人的行走路线和所在位置,最好能够实现大监控网络的实时追踪。4)考虑行人检测、跟踪、再识别集成系统的研究。大多数现有的行人再识别研究可以被当作一种识别任务,是因为实验中用到的查询集总有上限,然而在实际应用时,行人再识别将成为复杂开放问题,识别任务将变为在几乎没有数量上限的行人查询集中搜寻目标行人。因此从技术角度来讲,行人再识别未来的研究目标之一仍是提高匹配精度,在此基础上可以集成行人检测、行人跟踪以及行人再识别形成高效的端到端身份识别系统,这将大大利于行人再识别模型在实际中的高效应用。
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
意林(2021年5期)2021-04-18
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
江西教育B(2019年2期)2019-04-12
扬子江(2019年1期)2019-03-08
中国诗歌(2018年6期)2018-11-14
电机与控制学报(2018年9期)2018-05-14
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
