
融合边界信息的越南语名词短语深度学习识别方法
2019-12-12 07:06王闻慧
计算机应用与软件 2019年12期
王 闻 慧
(战略支援部队信息工程大学洛阳校区 河南 洛阳 471003)
0 引 言
名词短语识别是自然语言处理(Natural Language Processing,NLP)的基础性任务之一,是近年来研究者持续关注的重要研究课题。名词短语是组成句子基本的语言单元,是文本信息的重要携带者,同时也是各类短语中数量最多、构成复杂度最高、识别困难最大的一类。作为高于词而低于句子层面的中间结构,短语在表达上含有比词更明确且稳定的意义,而在结构构成上远不如句子复杂多变。因此,名词短语识别不仅为进一步实现句法分析奠定基础,也可为自然语言处理更高层次的应用性任务如机器翻译、信息检索、自动文摘等提供有力支持。在越南语自然语言处理任务中,名词短语识别同样起着基础性作用。
在越南语名词短语识别任务中,主要面临以下三个难题:(1) 除了相互嵌套,越南语名词短语还存在定语后置的现象,因而相对于汉语名词短语,越南语名词短语内部结构更为复杂;(2) 同汉语一样,越南语缺乏形态标记,动词短语作定语与动词短语作谓语的情况在形式表达上完全一样,造成对越南语名词短语识别时存在很大的歧义消解难题;(3) 越南语名词短语繁多,未登录越南语名词短语在测试语料中占比非常高,对未登录越南语名词短语的识别是越南语名词短语识别面临的根本性问题。
针对上述问题,本文采取了融入越南语名词短语边界信息的解决思路。通过将越南语名词短语边界信息向量化,并将其融入深度学习模型中,在一定程度上解决了越南语名词短语内部构成复杂、缺乏形态标记、未登录词占比高的识别难题。
1 相关研究
目前,越南语名词短语识别的相关研究还比较薄弱,无论是越南国内学者还是国际学者,对越南语名词短语识别的研究成果还比较少。文献[1]针对越南语标注语料缺失的问题,采用先简单规则过滤,后进行人工校对的方法对9 000个句子进行了名词短语标注,并分别用随机条件场(Conditional Random Fields,CRFs)、支持向量机(Support Vector Machine,SVM)、Online Passive-Aggressive Learning等判别模型进行实验,实验结果显示,在这三种模型中CRFs效果最好。文献[2]在越南语树库上依据树深度重新定义了越南语名词短语,并将词性特征、词汇正字法特征融入到CRF模型中,实验结果显示词性特征、词汇正字法特征能够有效提升越南语名词短语的识别效果。文献[3]针对越南语组块识别任务,将越南语名词组块的词性组合特征作为约束条件,并将其融入到CRF模型中,取得了较好的识别效果。
在汉语名词短语识别方面,近年来的研究较为丰富,主要方法有早期的基于规则的识别方法,之后的传统统计方法与近年兴起的深度学习识别方法。规则方法方面,主要是通过语言学家对名词短语内部结构特征、边界规律特征的总结[4],依据词性组合序列[5]、词类信息[6]、句法结构信息[7]和语义关系[8]等制定相应规则进行识别研究。尽管基于规则的识别方法对语言特征的利用程度最高,但语言现象的复杂性难以用规则穷尽,规则的增多同样带来时空复杂度的上升。随着统计模型的出现,短语识别方法也向统计以及统计与规则相结合的方法转变。例如采用SVM[9]、最大熵模型[10]、CRF[11]以及混合模型[12-13]的识别方法,结果表明单靠词性和词汇本身信息在识别效果上具有一定的局限性。文献[14]在以往研究的基础上提出了最长名词短语的定义,对其内部结构以及外部分布特征进行了分析研究,并由此提出一种基于归约的汉语最长名词短语识别方法。文献[15]提出一种融合了神经网络、传统统计模型与规则的名词短语识别方法,得到了89%的准确率。
综合而言,目前对越南语名词短语的识别研究还不够,主要存在三点不足:(1) 对越南语名词短语的界定和描述较为模糊;(2) 仅采用传统统计模型来进行识别,没有将深度学习模型应用到越南语名词短语识别任务中;(3) 仅采用了词形特征、正字法特征与词性特征来进行识别,而对越南语名词短语语言学规律的挖掘和应用还不足。
针对上述三点不足,本文首先明确对越南语名词短语的界定。在此基础上,对语料库中越南语名词短语的边界规律进行统计调查,并提出了两种将越南语名词短语边界信息向量化的方法。通过将向量化的边界信息融入Bi-LSTM+CRF模型,提升了模型对越南语名词短语的识别效果,一定程度上弥补了研究空白。
2 越南语名词短语边界规律
2.1 越南语名词短语


本文从定语类型上去除介词短语、句子作定语的部分,只考虑除这两类以外的其他类型成分作定语的情况。一是由于介词短语结构固定,通常表示为“介词+其他类型短语”,因此在识别名词短语的基础上再对其后介词短语进行识别的方法更为有效。二是句子作定语的情况涉及到的不再是短语层面的识别问题,而关系到更高层面的句法分析。
2.2 边界规律
通过对语料库(约含越南语名词短语30 000个)中越南语名词短语的邻接词与邻接词性进行统计,可以得到越南语名词短语的边界规律。对频数排名前十的越南语名词短语左邻接词的统计结果如表1所示。表中第一列是越南语名词短语左邻接词词形,第二列是该词占语料库中全部越南语名词短语左邻接词的比率,第三列为累计占比。对频数排名前十的越南语名词短语右邻接词的相应统计结果如表2所示。
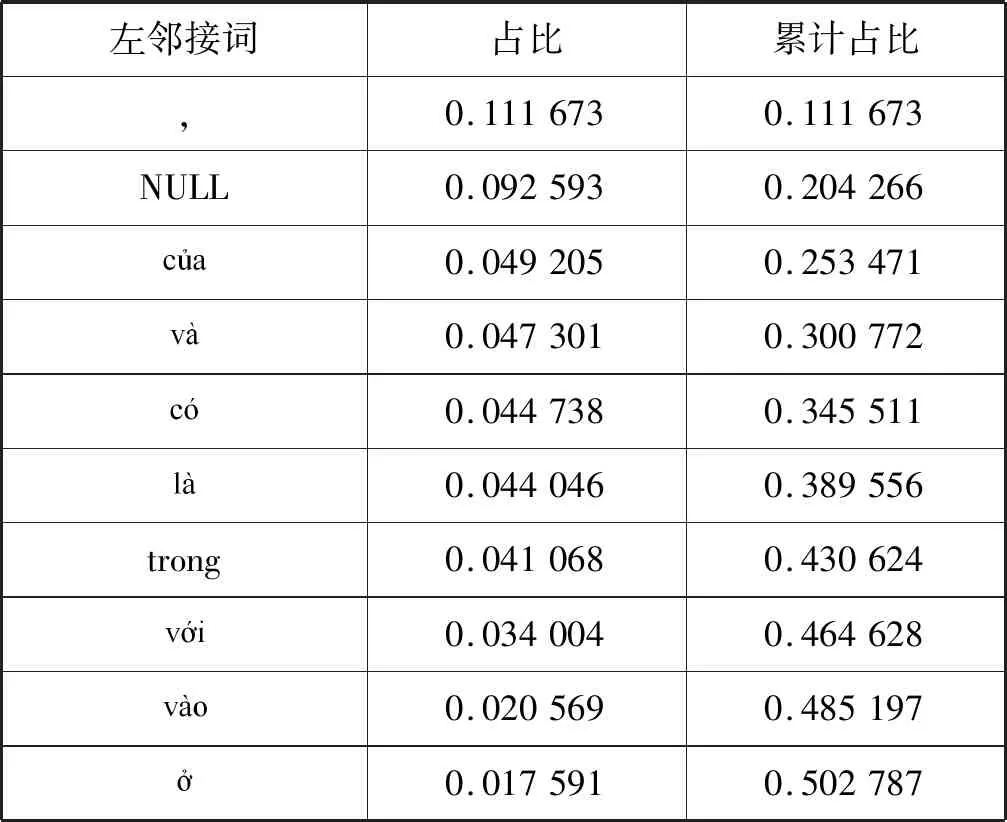
表1 越南语名词短语左邻接词词形统计结果
在表1中,“NULL”表示该越南语名词短语为句子开头,其不具有左邻接词。从表1中可以看到,越南语名词短语左邻接词分布较为集中,排名频数前五的左邻接词占到了越南语名词短语全部左邻接词的34.55%,排名前十的则占到了50.28%。从表2中可以看到,越南语名词短语右邻接词规律性非常明显,排名频数前五的右邻接词占到了越南语名词短语全部右邻接词的46.95%,排名前十的则占到了56.91%。

表2 越南语名词短语右邻接词词形统计结果
此外,本文还对越南语名词短语左右邻接词性进行了统计,由于词性是对词的一种归类,对越南语名词短语左右邻接词性的统计能进一步说明越南语名词短语的边界规律。对频数排名前五的越南语名词短语左右邻接词性的统计结果分别如表3、表4所示。

表3 越南语名词短语左邻接词词性统计结果
在表3中,“NULL”表示该越南语名词短语为句子开头,其不具有左邻接词性。从表3中可以看出,越南语名词短语的左邻接词性主要集中在介词、动词、标点和连词上,排名前五的左邻接词性就占全部越南语名词短语左邻接词性的89.93%。从表4中可以看出,越南语名词短语的右邻接词性较左邻接词性更为集中,排名前五的右邻接词性就占全部越南语名词短语右邻接词性的94.79%。

表4 越南语名词短语右邻接词词性统计结果
综上,越南语名词短语的邻接词与邻接词性规律性非常明显,该边界信息是对越南语名词短语进行识别的重要依据,在越南语名词短语识别中充分挖掘和利用这种边界信息能够促进对越南语名词短语的识别效果。
3 模 型
3.1 预训练词向量模型
本节采用Google在2013年开发的Word2Vector模型预训练获取越南语词向量,并使用Python的Gensim开源工具包作为Word2Vector模型的代码实现。词向量训练语料方面,本文选用了越南语维基语料。
Word2Vector是神经概率语言模型(Neural Probabilistic Language Model)的一种实现,其中包含了CBOW与Skip-gram两种模型,如图1所示。

图1 Word2Vector 模型
Word2Vector可以在构建神经概率语言模型的同时得到每个词所对应的词向量。其中:CBOW模型是通过上下文来预测当前词;而Skip-gram模型则是通过当前词来预测上下文。在CBOW模型中,模型的训练目标就是最大化如下对数似然函数:

(1)
式中:C表示训练文本中的所有词集合;Context(w)表示词w在文本中的上下文。而在Skip-gram模型中,则将Context(w)与w的因果关系进行了转换。
来斯惟[16]在2016年研究表明:当用于训练词向量的语料规模达到百兆级时,CBOW模型要好于Skip-gram模型。因此,本文采用越南语维基语料作为训练词向量的语料规模,其达到了百兆级,采取CBOW模型来训练得到词向量。
3.2 融入边界信息的Bi-LSTM+CRF模型
本文采用Bi-LSTM+CRF模型作为越南语名词短语识别模型,模型整体架构如图2所示。

图2 Bi-LSTM+CRF模型
作为循环神经网络(Recurrent Neural Network,RNN)的一种变体,双向长短时神经网络(Bidirectional Long-Short-Term Memory,Bi-LSTM)通过增加门限机制,在一定程度上缓解了RNN存在的梯度弥散和梯度爆炸问题。由图2可以看出,Bi-LSTM利用了正向和反向两个序列方向上的信息,从而能够更好地将上下文信息融入到模型中,因此在处理序列标注任务时表现优异。
但Bi-LSTM存在没有考虑输出值间转移概率的问题,因而在设计上存在先天缺陷。为此,通过在Bi-LSTM上增加CRF层,可以将输出值间的转移概率纳入到模型中,从而解决上述问题。本文通过TensorFlow平台搭建Bi-LSTM+CRF模型,完成模型的代码实现。
3.3 边界信息向量化
从2.2节中可知,与越南语名词短语邻接的词具有某种程度的规律性,这对越南语名词短语本身的边界确定具有重要价值。在深度学习学习框架下,如何将该边界信息融入神经网络对越南语名词短语的识别具有很大的意义。通过对越南语名词短语的边界信息向量化,本文对深度学习模型提出了两种优化方法:(1) 将每个词向量与预训练所得的NP(名词短语,Noun Phrase)向量的相似度融入了模型,即边界相似度向量(Border Similarity Vector,BS Vector);(2) 将每个词向量与预训练所得的每一个标签类别向量的相似度融入了模型,即标签相似度向量(Label Similarity Vector,LS Vector)。
3.3.1融入BSVector的Bi-LSTM+CRF模型
本文采取预训练的方式获取NP向量。通过将训练集中标注的越南语名词短语全部替换为“N-P”,并将替换后的训练集融合到越南语词向量训练集中进行训练,从而在同一个向量空间内获得了越南语词向量与NP向量。这种方式可以将越南语名词短语的内部结构隐去,而将名词短语的边界信息突显出来。
在一个向量空间内,计算测试语料中每个词与NP向量的欧式距离,可以获得该词与NP向量的相似度,本文将其称之为BS Vector,该向量只有一维。由于在训练NP向量时隐去了名词短语的内部结构,从而在训练中可以将整个名词短语的上下文信息(即边界信息)体现在NP向量中,而每个词与NP向量的相似度就能一定程度上体现该词与名词短语的邻接信息,从而实现将名词短语的边界信息向量化。对每一个词而言,其BS Vector的计算表示如下:
(2)
式中:VBS表示BS Vector,wk表示当前词的词向量的第k维;NPk表示NP向量的第k维;n表示词向量与NP向量的维度。在本文中,词向量与NP向量的维度都为50维,n为50。
将测试语料中每个词的词向量与其相应的BS Vector前后连接形成Bi-LSTM+CRF模型的输入层。在融入BS Vector条件下,Bi-LSTM+CRF模型的输入层如图3所示。

图3 融入BS Vector的输入层
3.3.2融入LSVector的Bi-LSTM+CRF模型
除了将整个越南语名词短语替换为“N-P”,从而训练得到NP向量,还可以将训练语料中整个越南语名词短语内部的各个组成词分别替换为其对应的标签“B-NP”或者“I-NP”,将非越南语名词短语组成成分的其他词替换为“O”,从而获得与训练集相对应的标签语料。将该标签语料与训练越南语词向量的语料合并进行训练,可以在同一个向量空间得到预训练的越南语词向量与各个标签向量。
在同一个向量空间内,通过计算测试语料中每个词与各个标签向量的欧式距离,可以获得该词与三个标签向量的相似度,由这三个相似度可以组成一个向量,本文将其称之为LS Vector,该向量有三维。三个不同的标签从本质上是对语料中每个词汇所对应类别的一种划分,可以一定程度上体现名词短语的边界信息。由于将训练语料中的每个词替换为其对应的标签,从而可以将体现越南语名词短语边界规律的三个标签的信息融入到每个标签向量中。而每个词与这三个体现越南语名词短语边界信息的标签向量的相似度就能一定程度上体现该词与越南语名词短语的邻接信息,进而实现将越南语名词短语的边界规律向量化。LS Vector的计算表示如下:
(3)
式中:VLS表示LS Vector;wk表示当前词的词向量的第k维;L1k表示“B-NP”标签向量的第k维;L2k表示“I-NP”标签向量的第k维;L3k表示“O”标签向量的第k维;n表示词向量与标签向量的维度。在本文中,词向量与标签向量的维度都为50维,n为50。
通过将测试语料中每个词的词向量与其对应的LS Vector前后连接,形成融合了名词短语边界信息的联合向量作为Bi-LSTM+CRF模型的输入层。在融入LS Vector的条件下,Bi-LSTM+CRF模型的输入层如图4所示。

图4 融入LS Vector的输入层
4 实 验
4.1 实验语料与标注集
越南语名词短语标注语料匮乏,即使在公开评测任务越南语及语音处理会议(Vietnamese Language and Speech Processing,VLSP)中,也只有越南语组块标注语料。为此,本文选用维基百科语料来进行越南语名词短语人工标注和校对,最终形成越南语名词短语标注语料的总词数为201 417个。本文将该语料按照3∶1的比例划分为训练集与测试集,现就语料的情况介绍如下:语料中共有越南语名词短语29 189个,其中训练语料中含有名词短语21 699个,测试语料中含有名词短语7 490个,其中测试语料中有5 792个名词短语属于未在训练语料中出现过的未登录越南语名词短语。在测试语料中,去除重复的越南语名词短语,共有名词短语类型6 272种,其中有5 318种名词短语类型属于未登录越南语名词短语。从这些数据中可以看出,未登录越南语名词短语在语料中占比非常高。
本文采用了IOB2标注集,对越南语名词短语的起始词标注为“B-NP”,对越南语名词短语的非起始词标注为“I-NP”,对非越南语名词短语组成的其他词标注为“O”。
4.2 评测标准
本文采用的评价指标及相应计算公式如表5所示。

表5 评价指标
在表5中,准确率P是指标注准确率,即在所有标签中标注正确的比率;越南语名词短语识别准确率PNP是指对越南语名词短语整体的识别准确率,只有对整个越南语名词短语内的所有组成词识别正确才算对该名词短语识别正确;越南语名词短语识别召回率RNP是对越南语名词短语整体识别的召回率;越南语名词短语识别F-value则综合评价对越南语名词短语整体的识别效果;越南语名词短语识别类别召回率RT则排除了对某一名词短语的反复识别成功而造成的识别效果虚高的情况,从越南语名词短语类别的角度真实反映对越南语名词短语的识别情况;未登录越南语名词短语识别召回率RUK则用来评价模型对未登录词的识别效果,是评价模型泛化能力的重要指标,由于对越南语名词短语的识别的难点和关键点都在于对未登录词的识别,该指标也是反映模型识别效果的重要指标;未登录越南语名词短语类别识别召回率RUKT则排除了对同一未登录越南语名词短语的反复识别造成的RUK虚高的情况,从类别的角度评价模型对未登录越南语名词短语的识别效果,该指标同样也是评价模型泛化能力的重要指标。
4.3 实验设计
本文使用Bi-LSTM+CRF模型作为识别模型,采用预训练的词向量作为其输入,并以此识别结果作为本文的基线标准。在此基础上,本文分别将BS Vector与LS Vector融入到模型输入层中,通过将实验结果与基线标准进行对比,验证本文提出的两种将越南语名词短语边界信息融入深度学习框架的有效性。
4.4 实验结果与分析
模型在各实验条件下对越南语名词短语的识别效果如表6所示。

表6 实验结果统计
从表6可以看出,在只有词向量作为模型输入的情况下,模型对越南语名词短语的识别效果较好,其中F-value达到了0.816 9,RUK达到了72.76%,RUKT达到了73.49%。在测试语料中未登录越南语名词短语占比达77.33%的情况下,这样的识别效果证明了Bi-LSTM+CRF模型的泛化能力。



5 结 语
本文针对越南语名词短语识别任务,通过对语料中越南语名词短语的邻接词与邻接词性进行统计,揭示了越南语名词短语的边界规律,该边界信息对越南语名词短语的识别具有重大价值。本文提出了两种将越南语名词短语的边界信息融入深度学习模型中的方法:(1) 通过计算每个词与预训练NP向量的相似度得到BS Vector;(2) 计算每个词与预训练所得的每一个标签类别向量的相似度得到LS Vector。针对这两种方法,本文设计了对比实验,实验结果显示,这两种将越南语名词短语边界信息融入深度学习模型的方法都能有效提升模型对越南语名词短语的识别效果,其中LS Vector对模型识别效果的提升比BS Vector要更大一些。
本文采用了先进行调查获取语言学规律,然后再探索将该语言学规律融入现有模型的思路,有效地提升了现有模型的识别效果。本文的研究思路和方法不仅有效提升了越南语名词短语的识别效果,而且对其他语种、其他领域相似任务的开展都具有较强的参考和借鉴意义。
猜你喜欢
环球时报(2022-09-15)2022-09-15
厦门大学学报(自然科学版)(2021年4期)2021-06-22
电脑知识与技术(2019年23期)2019-11-03
长江丛刊(2018年15期)2018-11-15
青年文学家(2015年2期)2016-05-09
海峡姐妹(2016年2期)2016-02-27
科技视界(2014年33期)2014-08-15
外语教学理论与实践(2014年2期)2014-06-21
教学与管理(理论版)(2009年9期)2009-11-04
