
基于双重相似度孪生网络的小样本实例分割
2020-01-09 09:17罗善威
武汉科技大学学报 2020年1期
罗善威,陈 黎
(1.武汉科技大学计算机科学与技术学院,湖北 武汉,430065;2. 武汉科技大学智能信息处理与实时工业系统湖北省重点实验室,湖北 武汉,430065)
一般的监督学习需要大量的样本来对模型进行迭代训练,但是很多特殊场景下的样本是难以收集的,如医疗领域、安防领域等,因此,小样本学习成为机器学习研究领域中亟待解决的热点问题。现阶段小样本学习方法主要分为三大类:①基于数据增强的方法。常用的数据增强技术通过对图像进行旋转、翻转、平移和缩放等操作来实现训练集的扩充。同时,研究人员也设计了各种新的数据增强策略[1-3]。②基于迁移学习的方法。迁移学习是把一个领域(源域)的知识迁移到另外一个领域(目标域),使得在目标域也能够取得良好的学习效果。在迁移学习中需要解决的主要问题是领域自适应问题[4-5]。③基于元学习的方法。元学习具有学会学习的能力,即利用以往的知识和经验来指导新任务的学习,其主要方法之一为基于度量的元学习。度量学习的基本思想是学习数据之间的相似性,而孪生网络(Siamese Network)在衡量两个输入的相似程度上具有优势,在深度学习相关领域取得了较好的应用效果。
Koch等[6]将孪生网络应用于小样本学习,孪生网络的两个子网络共享权值,通过计算两个输入的相似度进行二分类。在图像识别领域,Bertinetto等[7]通过构建一个学习网络来对孪生网络中的参数进行学习,并采用因子分解机来解决网络参数过多的问题。在细粒度识别领域,细粒度的手动标记非常耗时且需要特定领域的广泛专业知识,Yuan等[8]通过孪生网络的二分类特性来解决细粒度识别中的标签缺乏和样本不均衡问题。对人体跌倒进行动作识别时,Droghini等[9]提出通过孪生网络来计算不同事件类别信号之间的差异,并且在分类阶段只需要使用一个人体跌倒信号作为模板。在自然语言处理中,O’Neill等[10]采用孪生网络解决单词的相关性问题,并同时运用了迁移学习策略。在半监督学习领域,Motiian等[11]将孪生网络与生成对抗网络相结合,最大化不同类样本在目标空间的差异,同时也最小化同类样本在目标空间的差异。孪生网络在目标跟踪领域中的应用报道较多。Bertinetto等[12]对传统孪生网络中相似度计算方法进行改进,提出了新方法SiamFC,对参考图像特征图和场景图像特征图进行卷积计算来得到相似度矩阵。Li等[13]针对目标跟踪中的精度问题和实时性问题,提出了新的孪生网络结构SiamRPN,其包含用于特征提取的孪生网络和候选区域生成网络,后者由分类和回归两条分支组成。Wang等[14]提出用掩膜对目标进行跟踪的SiamMask方法,该方法在SiamRPN的基础上引入了Mask分支,通过掩膜生成旋转框,从而提升目标跟踪的精度。Li等[15]用更深的网络结构去克服孪生网络中平移不变性的限制,即提出一种基于层次的互相关操作特征聚集结构,该结构有助于模型从多个层次的特征中预判出相似度。
本文采用度量学习方法来解决小样本学习问题,针对传统孪生网络难以确定目标定位的问题,为了同时提取目标的相似度特征和位置信息,提出一种基于双重相似度(Double Similarity)计算和孪生网络(Siamese Network)的小样本实例分割模型(命名为DSSN)。DSSN将孪生网络与残差网络相结合,并在特征相似度计算阶段构建双重相似度计算网络来获得特征图的空域相似度和频域相似度,然后将相似度特征图输入实例分割网络获得最后的分割结果。
1 算法设计
DSSN模型有两个输入,分别是参考图像和场景图像,输出为参考图像所属的类别在场景图像中的边界框和形状掩码。
本文算法结构如图1所示,其采用孪生残差网络(Siamese ResNet-101)作为骨干网络,对参考图像和场景图像进行特征提取。输出每一个残差块(Residual Block)的计算结果,得到两组不同的特征图,分别对应于参考图像和场景图像。将这两组特征图输入孪生特征金字塔得到语义更强的两组特征图,然后输入到双重相似度计算网络对空域特征和频域特征进行计算和融合。最后将得到的空域和频域特征图分别输入实例分割阶段的三个分支进行计算:区域提取网络(RPN)、边界框的分类和回归(CLS+Bounding Box)以及掩码分支(Mask)。
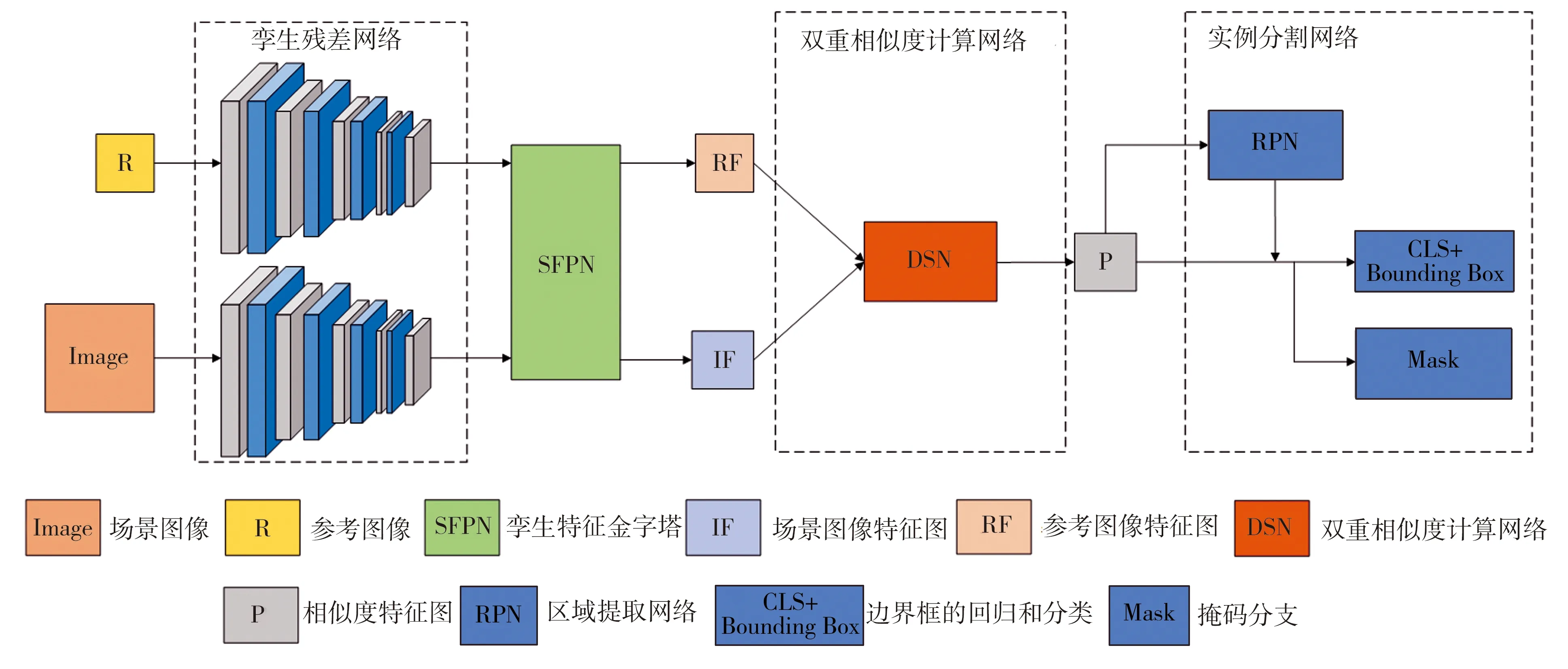
图1 本文算法的网络结构
1.1 孪生残差网络
本文骨干网络Siamese ResNet-101以孪生网络为基本结构,并将残差网络(ResNet-101)[16]作为基础网络。残差网络通过增加跳跃结构来直接连接浅层网络与深层网络,从而能够有效解决随着网络层数的加深而导致的梯度弥散问题。
假设第一个残差单元的输入为xl,输出为xl+1,则残差单元的结构可以表示为:
xl+1=xl+F(xl,wl)
(1)
F(xl,wl)=wlσ(wl-1xl-1)
(2)
式中:F(xl,wl)代表卷积计算函数;wl代表卷积层的参数;σ(·)代表激活函数。所以对于任意单元xL,有:
(3)
假设损失函数为J,可以得到:

(4)

1.2 孪生特征金字塔
本文采用孪生特征金字塔(SFPN)来解决实例分割任务中常出现的多尺度问题。SFPN通过改变网络连接,在基本不增加原有模型计算量的前提下大幅提升了模型性能。对于卷积神经网络而言,不同深度对应着不同层次的语义特征,低层特征语义信息比较少,但是对应的目标位置信息准确,高层特征语义信息比较丰富,但是对应的目标位置信息比较粗略,所以需要构建特征金字塔来对低层语义特征和高层语义特征进行融合。
如图2所示,孪生特征金字塔提取孪生残差网络输出的两组特征图,每组特征图对应不同语义层次残差块的输出。场景图像和参考图像对应的特征图分别记为Ik和Rk(k=2,3,4,5)。将Ik和Rk分别转化为结合上、下层语义特征的特征图IFk和RFk(k=2,3,4,5,6)。孪生特征金字塔中上、下层语义特征结合的计算公式如下:

(5)
式中:conv代表卷积操作;sum代表元素的对位求和操作;upsample代表上采样操作。RFk的计算公式同IFk。

图2 孪生特征金字塔结构
1.3 双重相似度计算网络
双重相似度计算网络DSN中的两个子网络分别为空域相似度计算网络和频域相似度计算网络。网络的输入为孪生特征金字塔所提取的语义特征图IFk和RFk,输出为相似度特征图Pk。网络结构如图3所示。

图3 双重相似度计算网络结构
(1) 空域和频域特征提取
为了对空域相似度计算网络和频域相似度计算网络的输入进行不同语义特征的提取,本文采用卷积核大小为3×3的卷积层分别提取空域特征和频域特征。
(2) 相似度计算方法
在空域相似度计算网络中,先对参考图像空域特征图采用全局平均池化,然后通过两个特征图的空间距离来计算空域相似度。本文参照文献[17],构建fσ(x1,x2)来计算空域相似度:
(6)
式中:x1代表场景图像的空域特征图;x2代表参考图像的空域特征图;σ代表scale参数;d(x1,x2)代表x1与x2的空间距离,本文采用L1距离公式,即d(x1,x2)=|x1-x2|。
为了减少特征图的噪声和模型的计算量,本文采用TopK算法对空域相似度特征图进一步提取,即选取K个均值最大的特征图。
在频域相似度计算网络中,通过fφ(x1,x2)对场景图像与参考图像的频域特征图进行卷积计算,然后经过一个卷积核大小为1×1的卷积层得到场景图像与参考图像的频域相似度。fφ(x1,x2)计算公式如下:
fφ(x1,x2)=x2*x1
(7)
式中:x1代表场景图像的频域特征图;x2代表参考图像的频域特征图;*代表以x2为卷积核对x1进行卷积计算。
(3)相似度特征融合方法
在双重相似度计算网络的特征融合阶段,本文采用的方法是将空间相似度和频域相似度在特征通道这一维度上进行合并,并将合并后的特征图进行卷积核大小为1×1的卷积计算,得到场景图像与参考图像的相似度特征图Pk(k=2,3,4,5,6)。
1.4 实例分割网络
DSSN模型中的实例分割网络引入Mask R-CNN[18]中的区域提取网络(RPN)、边界框的分类和回归(CLS+Bounding Box)以及掩码分支(Mask)。
区域提取网络(RPN)的输入为特征金字塔输出的特征图,RPN的实质是通过计算得到不同尺度的候选框,并对候选框进行筛选。候选框的多尺度是通过Anchor来实现的。RPN基于Pk(k=2,3,4,5,6)这5个特征图,通过前向传播得到一个5n维的向量,这个向量代表5种不同尺度的Anchor,每种尺度又包含n个不同长宽比例的Anchor,每个Anchor的相关参数包括Δx、Δy、Δh、Δw、p,其中,Δx代表横坐标相对于中心点的偏移,Δy代表纵坐标相对于中心点的偏移,Δh代表高度相对于原Anchor高度的偏移,Δw代表宽度相对于原Anchor宽度的偏移,p为前、后景置信度。Anchor的相关参数计算公式如下:

(8)
式中:(x,y)代表Anchor的中心坐标;w和h分别代表Anchor的宽和高。当Anchor修正完成后,会产生大量的Box,这时再根据每个Box的p值,使用非极大值抑制(NMS)算法即可过滤出较为精确的候选框。
获取候选框之后,采用ROI Align算法直接从特征图中裁剪出候选框对应位置的特征,并将特征变换为统一的尺度。ROI Align算法在池化过程中引入了双线性插值,将原先离散的池化操作变为连续的,使得映射后的坐标值精度更高。
在得到候选框对应的同一尺度的特征图后,将其输入CLS、Bounding Box、Mask等分支进行后续的计算。对于CLS分支,通常采用全连接层和Softmax层来进行类别预测。对于Bounding Box分支,通常对每个类别都回归得出一个5维向量的修正值,修正过程与式(8)一致。对于 Mask分支,根据得到的目标边界框,通过全卷积神经网络(FCN)来得到目标更为精准的形状掩码信息。
1.5 损失函数
DSSN模型的损失函数分别为:区域提取网络的分类损失LRPN-cls、区域提取网络的回归损失LRPN-box、实例分割网络的分类损失Lcls、实例分割网络的回归损失Lbox、实例分割网络的分割损失Lmask。
由于模型在RPN网络结构中会产生大量的背景目标而导致类别不平衡,所以本文将LRPN-cls设置为Focal Loss损失函数[19]。Focal Loss不仅可以解决正、负样本的不均衡问题,还可以平衡简单样本和困难样本,计算公式如下:

(9)
式中:y代表预测类别置信度;y*代表标签类别;α代表平衡因子;γ用于调节简单样本权重降低的速率,当γ=0时,LRPN-cls即为交叉熵损失函数,当γ增加时,调整因子(1-y)γ和yγ的影响也在增加。本文中设α=0.8、γ=2。
Lcls为二元交叉熵损失函数,计算公式如下:
Lcls(y,y*)=
-[y*log(y)+(1-y*)log(1-y)]
(10)
LRPN-box与Lbox的计算公式相同,如下所示:
LRPN-box(t,t*)=Lbox(t,t*)=
(11)
(12)
式中:t代表预测边界框;t*代表标签边界框;(x,y)代表边界框的中心点;(w,h)代表边界框的宽和高。
Lmask的计算公式如下:
(13)
式中:y代表分割结果图;y*代表分割标签图;(i,j)代表在分割图上的每一个像素点的坐标。
模型总的损失函数为LRPN-cls、LRPN-box、Lcls、Lbox、Lmask的加权和:
Ltotal=2LRPN-cls+0.1LRPN-box+
2Lcls+0.5Lbox+Lmask
(14)
2 实验与结果分析
2.1 数据集
本文实验采用微软公司发布的COCO数据集。COCO数据集包含20多万张标注图片,超过150万个对象实例,总计80个类别。本文将其中60个类别用于训练模型,另外20个类别用于检验模型的小样本实例分割性能。为了尽可能减少在对类别进行分配时所造成的随机误差,本文对COCO数据集中的80个类别进行3次随机分配,得到不同的3组训练集和验证集。验证集分别记为S1、S2、S3。
2.2 评价指标
为了定量评估本文算法,采用COCO数据集中的通用指标mAP来客观评价实例分割效果, mAP值越大,表明算法的分割效果越好。
2.3 训练细节
本文算法的实验环境详细信息如下:
(1)硬件设备: CPU Intel Core i7-8700K;内存16 GB;GPU Nvidia GeForce GTX 1080Ti。
(2)软件设备: 操作系统64位Windows 10;Python 3.5;CUDA Toolkit 9.0;深度学习框架TensorFlow 1.8。

2.4 相似度计算方法测评
为了验证基于空域特征和频域特征相结合的相似度计算方法的有效性,在3组不同的数据集上进行测试,并与其他几种相似度计算方法进行了对比,包括:
(1) 基于空域特征的方法(SSSN):计算场景图像特征图与参考图像特征图在空间上的差异性,通过欧氏距离来对特征图的相似性进行度量。
(2) 基于频域特征的方法(FSSN):计算场景图像特征图和参考图像特征图在频域上的差异性,通过卷积计算方法来对特征图的相似性进行度量,即将参考图像的特征图作为卷积核对场景图像的特征图进行卷积计算。
表1给出了不同相似度计算方法的实例分割性能指标mAP。由表1可知,基于单一的空域特征或频域特征的相似度计算方法的mAP值均低于本文方法对应值。相比于SSSN和FSSN,本文方法在3组数据集上的mAP平均值分别提升了22.6%和18.2%。
表1 不同相似度计算方法的性能比较
Table 1 Performance comparison of different similarity computing methods
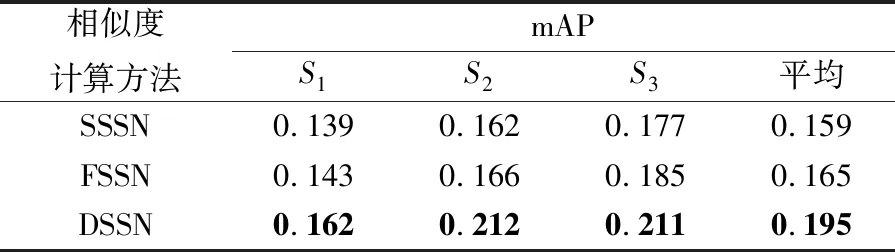
相似度计算方法mAPS1S2S3平均SSSN0.1390.1620.1770.159FSSN0.1430.1660.1850.165DSSN0.1620.2120.2110.195
2.5 空域和频域特征提取方法测评
为了验证本文DSSN模型网络结构中双重相似度计算阶段所提取的空域和频域特征的有效性,在3组数据集上进行特征提取层的性能对比。本实验比较了4种不同的特征提取方法,分别为:不采用卷积层 (DSSN-v0)、采用1×1的卷积核 (DSSN-v1)、采用3×3的卷积核 (DSSN-v3)和采用5×5的卷积核(DSSN-v5)。
表2给出了采用不同卷积层时DSSN模型的实例分割性能指标mAP。由表2可知,采用3×3的卷积核对场景图像和参考图像特征图进行卷积操作能有效提升模型的实例分割性能。与DSSN-v0、DSSN-v1、DSSN-v5相比,DSSN-v3的mAP平均值分别提升了12.1%、5.4%、10.8%
表2 不同特征提取方法的性能比较
Table 2 Performance comparison of different feature extracting methods
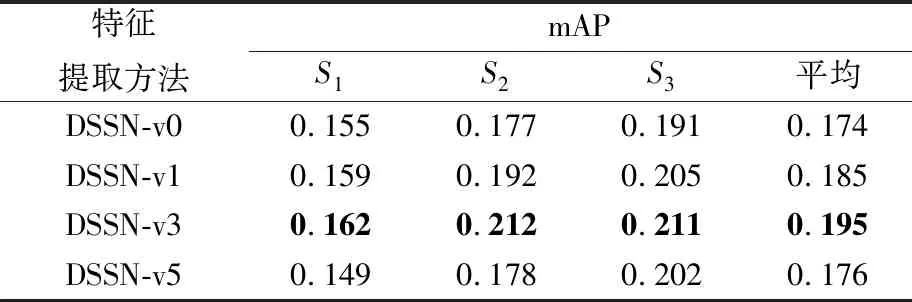
特征提取方法mAPS1S2S3平均DSSN-v00.1550.1770.1910.174DSSN-v10.1590.1920.2050.185DSSN-v30.1620.2120.2110.195DSSN-v50.1490.1780.2020.176
2.6 相似度特征融合方法测评
为了验证本文提出的相似度特征融合方法的有效性,在3组数据集上进行测试,并与另外一种常见的特征融合方法进行对比,该方法是对空域特征图和频域特征图进行简单相加求和,记为DSSN-A。
表3给出了两种相似度特征融合方法的性能比较,可以看出,相比于DSSN-A,本文方法在小样本实例分割中的性能更优,mAP平均值提升了6.0%。
表3 不同特征融合方法的性能比较
Table 3 Performance comparison of different feature fusion methods

相似度特征融合方法mAPS1S2S3平均DSSN-A0.1610.1900.2010.184DSSN0.1620.2120.2110.195
2.7 本文方法与现有方法的实例分割性能对比
为了更加客观地评价本文算法的性能,表4给出了本文方法、Mask R-CNN[18]和Siamese Mask R-CNN[20]方法在数据集S1、S2、S3上的实例分割性能指标mAP。
在表4中,FPN代表在骨干网络后面加入特征金字塔,SFPN代表在骨干网络后面加入孪生特征金字塔。由实验结果得知,在引入Siamese RestNet-101 SFPN作为骨干网络的情况下,本文模型DSSN在3组数据集上的mAP指标相比于Mask R-CNN模型平均提升了38.3%,相比于Siamese Mask R-CNN模型平均提升了30%。并且,在孪生残差网络后没有加入特征金字塔时,本文模型DSSN也优于其他两种模型。
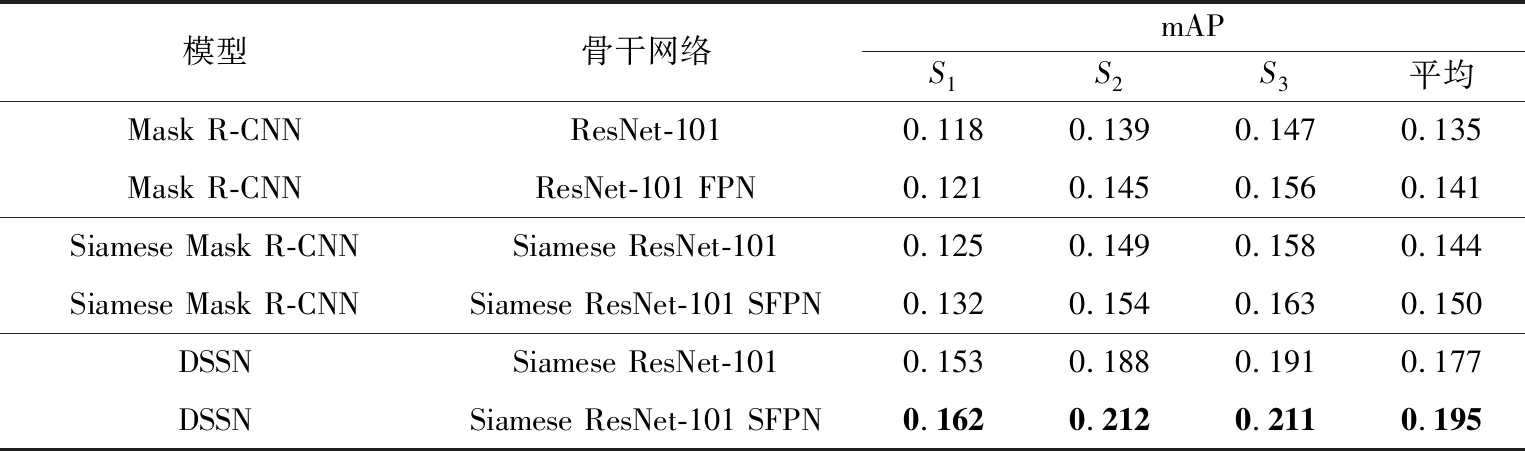
表4 不同方法的小样本实例分割性能对比
图4所示为3种方法在S1数据集上的实例分割结果。由图4可知,对于密度较大的目标,本文模型DSSN比其他两种模型具有更好的分割效果,并且在目标边缘的分割上也更加精细。

图4 不同方法的实例分割结果
3 结语
本文提出了一种基于双重相似度孪生网络的小样本实例分割方法,使用孪生残差网络结构作为骨干网络,融合不同尺度的低层和高层特征语义信息,对参考图像特征图和场景图像特征图的空域相似度和频域相似度进行计算和合并,同时得到两个输入之间的相似度特征和参考图像在场景图像中的位置信息,最后通过实例分割网络得到分割结果。实验结果证明了本文方法在小样本数据集上比其他对比算法具有更好的实例分割性能。
猜你喜欢
成都信息工程大学学报(2021年1期)2021-07-22
军民两用技术与产品(2021年10期)2021-03-16
环球时报(2021-02-01)2021-02-01
科技视界(2020年8期)2020-05-18
雷达学报(2018年3期)2018-07-18
北京航空航天大学学报(2017年3期)2017-11-23
燕山大学学报(2015年4期)2015-12-25
中国科技纵横(2014年11期)2014-08-30
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
