
TIGGE模式在淮河水系史河流域的应用
2020-02-10 03:14王建群蔡晨凯
河海大学学报(自然科学版) 2020年1期
王建群,段 蓉,蔡晨凯
(河海大学水文水资源学院,江苏 南京 210098)
由雨量站监测到的降落到地面的雨量驱动水文模型得到的洪水过程预报,其预报的预见期仅为产汇流时间,通常难以满足防洪和兴利同时兼顾的要求。为进一步延长预报发布时间至预报对象出现的时间间隔,即洪水预报的预见期[1],有必要将降雨预报和降雨径流模型相结合,充分利用降雨预报的预见期。随着数值天气预报水平的不断提高,降雨预报产品已被研究应用于洪水预报[2-7]。世界气象组织(WMO)于2003年制定了一项为期10 a的研究和发展计划,即观测系统研究与可预报性试验(the observing system research and predictability experiment a world weather research program,简称WWRP/THORPEX)。作为THORPEX的一个重要组成部分,TIGGE归档了全球范围内10个数值天气预报中心的集合预报产品[8-9],为各中心预报产品的比较、自身技术的改进建立了坚实基础。降雨预报的准确性是用于延长洪水预报预见期的关键所在。然而,由于天气系统的复杂性和数值天气预报模式的局限性,单一模式很难获得较高精度的预报值,而采用多模式集合预报技术能够很好地平衡预报模式的不确定性,有效降低降雨预报误差,改善预报效果[10-13]。目前,针对降雨预报能力的评估和集合预报,国内外学者已做了大量研究。例如:杜雅玲等[14]利用TIGGE数据的中期降水预报评估了在江苏省的应用效果,发现各模式在对中雨以上等级降水存在较明显的漏报;赵琳娜等[15]指出多模式集合预报可以改善单一模式的不确定性;杜钧等[16]提出多模式集合预报可能消除预报的系统性偏差;罗聪等[17]提出基于预报误差的反误差加权集成法,可用于日极端气温的多模式预报。
先前的研究已经表明采用适当的多模式集合方法可以有效降低降雨预报误差,如消除偏差集合平均法(BREM)、等权的简单集合平均法(EMN)以及不等权的超级集合平均法(SUP)等[11],但这些方法都是线性方法,其精度有待于进一步提高。本文以淮河水系史河流域为研究区域,选用TIGGE的5个不同模式的降雨预报数据,结合流域实测降雨资料,对各模式在1~7 d预见期内的预报精度进行综合评价,分析TIGGE降雨预报信息在史河流域的可用性;在此基础上,提出基于TIGGE的5个不同模式的实时降雨预报非线性校正方法,旨在提高降雨预报在研究区域内的精度,为洪水预报提供新的预见期降雨预报校正方法。
1 研究区域及TIGGE资料
1.1 研究区域
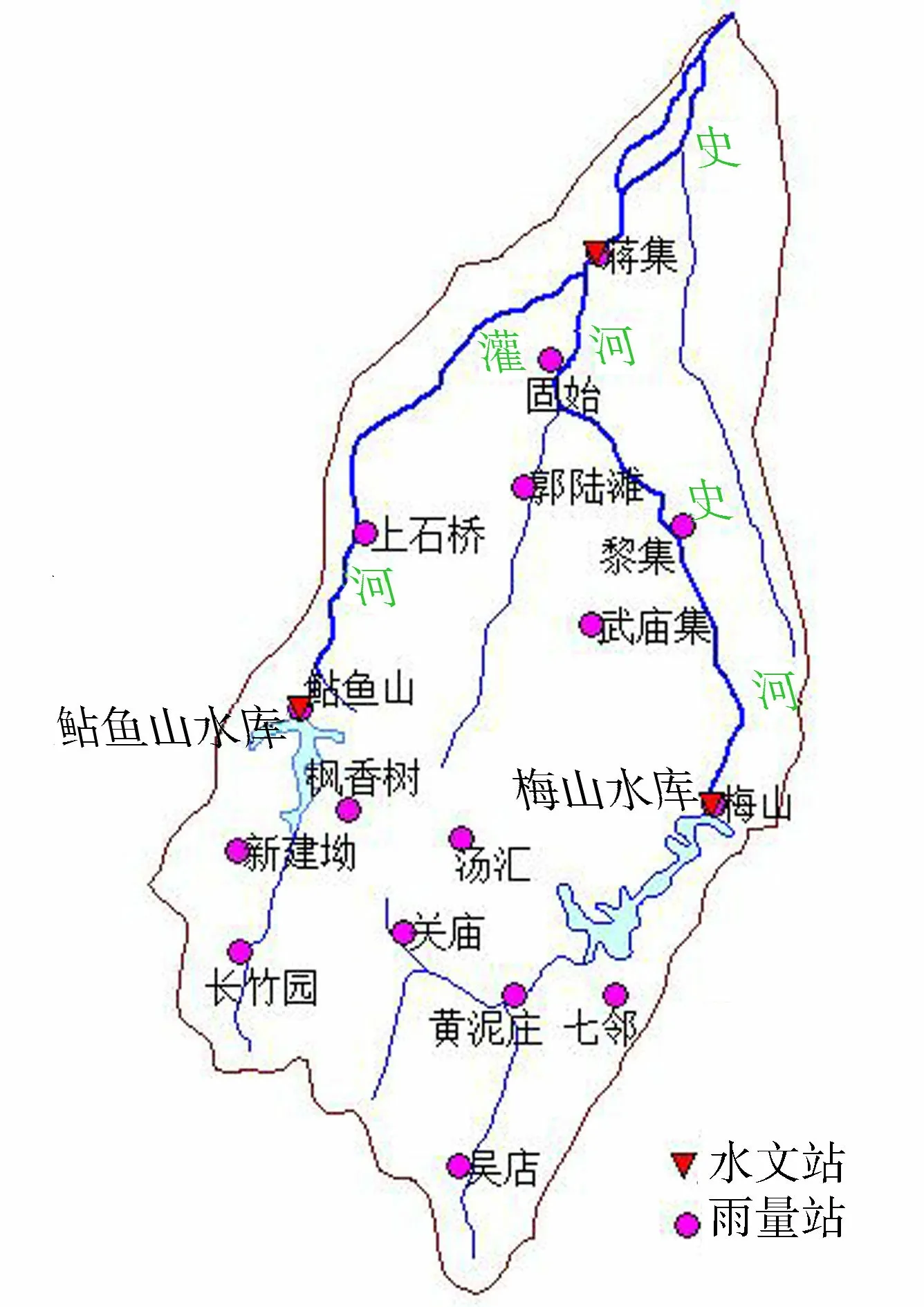
图1 史河流域水系站网分布Fig.1 Drainage system of the Shihe Catchment
史河发源于大别山北麓的伏牛岭,是淮河干流王家坝站至临淮岗闸区间南岸的主要支流,流域面积6 889 km2。史河在蒋集有支流灌河汇入,史河上游建有梅山水库(控制流域面积1 970 km2),灌河上游建有鲇鱼山水库(控制流域面积924 km2),蒋集水文站控制流域面积5 848 km2。史河流域水系站网分布见图1。史河流域位于北纬31°12′~31°18′、东经115°17′~ 115°55′,属于亚热带湿润季风气候区,雨量丰沛,多年平均年降水量为1 077 mm。每年的5月份开始出现长时期高强度的频繁降雨,极易造成洪涝灾害。鲇鱼山水库和梅山水库的洪水预报与调度对于淮河干流的防洪调度和临淮岗工程的控制运用有着重要的意义。
1.2 TIGGE资料
主要选取TIGGE的欧洲中期天气预报中心ECMWF、日本气象厅JMA、中国气象局CMA、英国气象局UKMO和韩国气象厅KMA预报模式的7 d累计降雨量[8-9,18],数据来源于http://apps.ecmwf.int/datasets/。由于各个机构发布的降水预报时空分辨率有所不同,因此统一选用预报时间为每天的世界标准时间(0:00 UTC)的预报产品,预报时长统一为168 h(7 d),分辨率为0.5°×0.5°; 由于JMA在2013年缺少世界标准时间0:00的预报数据、CMA在2014年缺少8月份的预报数据,时间序列取为2015—2017年淮河流域汛期(5—9月),采用泰森多边形法由TIGGE产品0.5°×0.5°格点预报雨量计算各子流域面雨量作为面雨量预报值;提取研究区域雨量站相应时段的实测雨量数据,采用泰森多边形法,由各雨量站实测雨量计算各子流域面雨量作为面雨量实测值,对比同期面雨量预报值与实测值,评价降雨预报的精度。
2 降雨预报精度评价
2.1 精度评价方法
通常采用雨量预报的均方根误差及确报率、空报率和漏报率来评价降雨预报的精度。均方根误差计算公式如下:
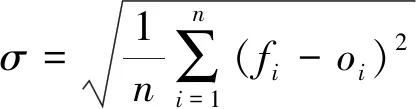
(1)
式中:σ——均方根误差;fi——降雨预报值;oi——降雨实测值;n——样本容量。
采用气象部门制定的24 h降雨量级多级划分标准[19],并从洪水预报的实用性角度对其进行了微调。将24 h内的降雨量分为无雨、小雨、中雨、大雨、暴雨、大暴雨和特大暴雨等7个量级。通常,气象上认为无雨即降雨量为0;由于在实际进行洪水预报时,小于1 mm的时段降雨量对于洪水的形成几乎没有直接的影响,因此,本文将气象部门的无雨标准改为24 h降雨总量小于1 mm,小雨标准改为24 h降雨总量1.0~9.9 mm,其余不变。
为了能综合评价降雨预报精度,笔者在确报率、空报率和漏报率评价指标的基础上提出降雨预报三率综合评价方法,公式如下:
Pi=w1Ph,i+w2(1-Pf,i)+w3(1-Pm,i)
(2)

(3)

鉴于漏报对于防洪调度可能产生较大不利,本文主要考虑漏报率最低、确报率高的预报方案,应给予非漏报率较高的权重、确报率次高权重、非空报率稍低权重,经分析确定w1、w2、w3分别取为0.3、0.2、0.5。从洪水预报与调度工作对未来降雨预报的要求来看,未来某时段距离预报根据时间(实测截止时间)越近,该时段降水预报的预见期就越短,对该时段降雨预报的精度要求就越高。经分析,确定1~7 d的预见期精度综合评价指标权重分别赋值为0.2、0.2、0.15、0.15、0.15、0.1、0.05。
需要说明的是,降雨预报三率综合评价值不是“一次预报”指数,而是多次预报样本的统计值。
2.2 精度评价结果
选择5个预报模式的TIGGE数据,对其降水预报在史河流域的精度进行评估。计算结果如图2、表1所示。

图2 降雨预报均方根误差Fig.2 Root mean square error of the rainfall forecast

表1 三率综合评价值
对于均方根误差指标σ:(a)JMA的σ在3个子流域表现最好,均相对低于其他几个模式; ECMWF的σ表现仅次于JMA;CMA的σ明显高于其他几个模式的σ。(b)KMA的σ波动较大,在预见期为1 d时对降雨过高预估导致产生较大的误差,其值几乎是其他模式的2倍,但随着预见期的增长,又降低到正常水平。根据笔者对淮河上游息县以上流域、淮河支流淠河横排头以上流域的研究,KMA在1 d预见期的σ与史河流域的情况一致。(c)总体上,σ随着预见期的增加而增加。
3)建立分布式建筑模型,BIM技术还可以将建筑的整体进行分布式模型的建立,使用一种虚拟状态的空间想象对这些问题进行布置和分析,从而防止实际操作中出现问题[2]。BIM技术的操作示意如图1所示。
对于本文提出的降雨预报三率综合评价指标P: (a)5个预报模式对于无雨情况在3个子流域的预报三率综合评价值在0.87以上,精度相对于其他情形较高。(b)小雨、中雨及大雨3个量级降雨预报在3个子流域的三率综合评价值在0.60左右,暴雨量级降雨预报在3个子流域的三率综合评价值在0.47左右,精度相对较低;对于大暴雨及以上量级降雨预报,由于2015—2017年淮河流域汛期未发生此级别的降雨,因此无法计算预报三率综合评价值。 (c)从不同模式来看,JMA在3个子流域的精度优于其他模式,UKMO的表现仅次于JMA,但5个模式随着降雨量级的增大,预报三率综合评价值下降幅度很大,对暴雨的预报三率综合评价综合值降至0.5。
3 降水预报校正
为了改善降雨预报的精度,许多学者提出了各种集合预报的方法[20-24],例如消除偏差集合平均法(BREM),公式如下:
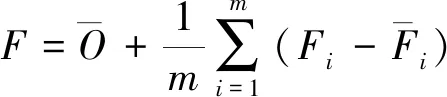
(4)

式(4)中,F与F1,F2,…,Fm的关系是线性的,广义地,有
F=f(F1,F2,…,Fm)
(5)
其中f可以是非线性回归关系。径向基人工神经网络RBF和ν-支持向量回归(ν-SVR)可以用来逼近f。
径向基人工神经网络RBF由Darken和Moody于1989年提出,具有最佳逼近的特性以及非线性映射能力,且计算量少,近年来被广泛应用于径流预报和降雨预报[25-26]。
支持向量机(SVM)是Vanpik在20世纪90年代提出的一种分类和回归的机器学习方法[27-28],具有良好的泛化能力,Scholkopf提出的ν-支持向量回归(ν-SVR)算法,已被用于洪水预报领域[29-31]。
本文采用ν-SVR逼近f并与BREM及RBF对比,选取2015年和2016年的汛期即5—9月作为训练期,2017年的汛期作为验证期。由2.2节对TIGGE的5个预报模式评价结果可知,JMA预测精度较高,ECMWF与UKMO预测能力仅次于JMA。现将BREM、RBF、ν-SVR这3种集合校正方法与JMA、ECMWF、UKMO这3个模式进行对比。
训练期计算结果精度统计见图3、表2。

图3 训练期降雨预报均方根误差Fig.3 Root mean square error of the rainfall forecast in training period
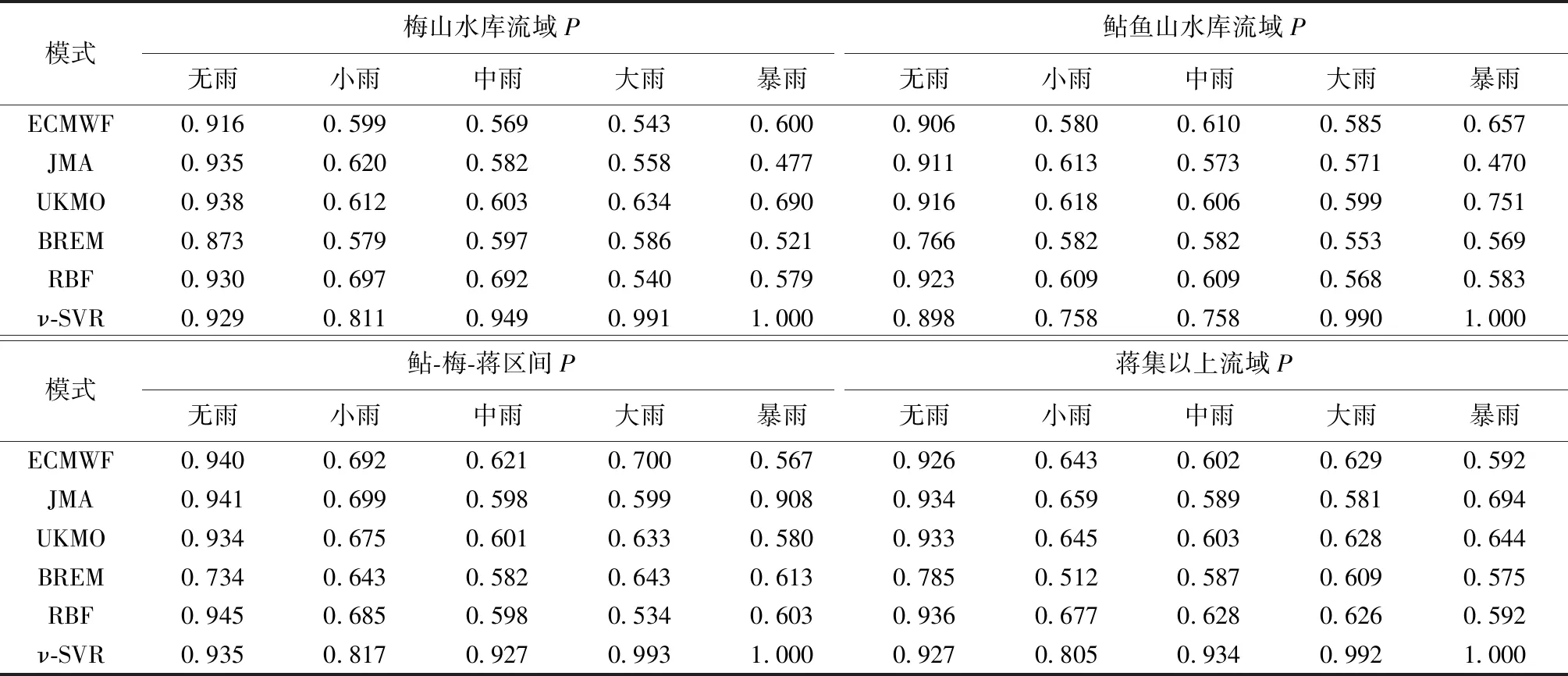
表2 训练期三率综合评价值
对于训练期均方根误差指标σ:(a)线性方法BREM在3个子流域的σ均明显低于ECMWF以及UKMO的σ,与JMA的σ接近。(b)2种非线性方法RBF及ν-SVR在3个子流域的σ均比ECMWF、JMA、UKMO模式及线性方法BREM的σ低,以梅山水库流域为例,RBF法的σ比JMA的σ降低了4 mm左右,ν-SVR法的σ比JMA的σ降低了10 mm左右。(c)总体上,BREM、RBF、ν-SVR的σ随着预见期的增加而增大。
对于训练期降雨预报三率综合评价指标P:(a)BREM法的P在各量级降雨情形都相对较低,与ECMWF、JMA、UKMO模式的P相当,甚至比ECMWF、JMA、UKMO模式中最好的结果差。(b)RBF法的P在无雨、小雨、中雨和暴雨情形均高于BREM法的P,但在大雨情形低于BREM法的P。(c)对于除小雨外的每一个量级降雨,ν-SVR法的P均高于0.929,小雨情形为0.811,远高于其他方法和模式的P。
以梅山水库流域为例,验证期的均方根误差以及三率综合评价值计算结果见图4、表3。

图4 验证期梅山水库流域降雨预报均方根误差Fig.4 Root mean square error of the rainfall forecast for the Meishan reservoir catchment in verification period

表3 验证期梅山水库三率综合评价值
对于验证期的均方误差指标σ:(a)线性方法BREM及2种非线性方法RBF和ν-SVR的σ均比ECMWF、JMA、UKMO模式的σ小,预测精度高。(b)2种非线性方法RBF及ν-SVR的σ均比线性方法BREM的σ低。(c)2种非线性方法中,ν-SVR的σ除2 d预见期外均低于RBF的σ;RBF表现相对较差,σ波动性较大,而ν-SVR的σ随着预见期的增加呈现相对平缓的增加趋势。
对于验证期降雨预报三率综合评价值P:(a)BREM法的P与ECMWF、JMA、UKMO模式的P相当,甚至比ECMWF、JMA、UKMO模式中最好的P差。(b)RBF法的P在无雨、小雨、和暴雨情形均高于BREM法的P,但在中雨、大雨情形低于BREM法的P。(c)对于除小雨外的每一个量级降雨,ν-SVR法的P均高于RBF法的P。
由上面的分析可知,不论在训练期还是验证期,线性集合校正方法BREM法与2种非线性集合方法RBF法及ν-SVR法相比,预测能力略差;非线性集合方法中,支持向量回归ν-SVR的预测性能优于RBF人工神经网络。
4 结 语
a. 将TIGGE应用于淮河水系史河流域,基于TIGGE的ECMWF、KMA、JMA、UKMO、CMA这5个不同模式2015年、2016年、2017年汛期降雨预报数据和流域实测降雨资料,采用均方根误差指标和本文提出的降雨预报三率综合评价指标,对各模式在1~7 d预见期内的预报精度进行综合评价,采用2种非线性方法RBF及ν-SVR对TIGGE的5个降水预报模式进行非线性集合预报校正,并与线性方法BREM法进行了比较,结论如下:(a)在淮河水系史河流域,TIGGE的ECMWF、KMA、JMA、UKMO、CMA这5个模式中,无论是均方根误差σ还是三率综合评价值,JMA模式的表现最好,其次是ECMWF和UKMO,CMA整体误差偏大,KMA波动性较强;(b)随着预见期的增长,各模式预报精度都呈下降趋势;(c)整个预见期内各模式都对无雨预报能力较强,小雨及以上量级降雨的预报能力相对较弱。
b. 采用线性方法BREM及2种非线性方法RBF和ν-SVR对TIGGE的5个预报模式进行集合预报校正,在一定程度上提高了降雨预报的精度。对于BREM法,无论是训练期还是验证期,其均方根误差均比ECMWF、JMA、UKMO模式的均方根误差稍低,其三率综合评价值与ECMWF、JMA、UKMO模式的三率综合评价值相当。无论是训练期还是验证期:RBF法的均方根误差比BREM法的均方根误差低,三率综合评价值与BREM法的三率综合评价值相当;ν-SVR法的均方根误差及三率综合评价值均优于BREM法和RBF法的结果。
c. 本次研究由于受资料条件的限制,样本序列较短,资料的代表性不够,期间没有发生过大暴雨和特大暴雨,因此未能对大暴雨以上量级各种模式的降雨预报精度和各种方法的校正精度进行很好的评价,还有待进一步研究。
猜你喜欢
河南科学(2022年7期)2022-09-20
中国水土保持(2022年6期)2022-06-08
环境工程技术学报(2022年3期)2022-06-05
环境技术(2022年1期)2022-03-21
成都信息工程大学学报(2021年3期)2021-11-22
科技研究·理论版(2021年22期)2021-04-18
飞天(2019年6期)2019-07-08
人大建设(2017年6期)2017-09-26
环球时报(2017-06-14)2017-06-14
新高考·高二数学(2015年2期)2015-05-27
