
基于自制便携式近红外光谱仪的枇杷果实可溶性固形物无损检测及年度重复验证
2020-04-22 02:12魏雨晴王毓宁李绍佳孙崇德吴迪
浙江大学学报(农业与生命科学版) 2020年1期
魏雨晴,王毓宁,李绍佳,孙崇德,吴迪*
(1.浙江大学农业与生物技术学院果树科学研究所,杭州310058;2.江苏太湖地区农业科学研究所,江苏 苏州215106)
枇杷是一种酸甜爽口、软糯多汁的薄皮型水果,不仅含有丰富的矿质元素、蛋白质等营养成分,还含有多种有益的活性物质(如萜类化合物、苦杏仁苷、类黄酮化合物、酚类物质、有机酸类等),是一种深受消费者喜爱的“明星”水果[1]。为了提高枇杷的经济价值和市场竞争力,需要对其进行分级销售,使枇杷果实的商品价值最大化。这也将有利于引导市场定价和保障消费者的合法权益,还能间接推动水果产业的结构化改革,提升水果产品的市场竞争力。
目前,枇杷市场缺乏能够快速、准确、无损地获取果实内部品质的检测技术。市场上针对枇杷果实的分类大多基于对果实色泽和大小的观察或者采用抽样式破坏性的生理指标检测方法[2]。前者主要凭借人工经验对枇杷果实进行分类,这容易造成分类结果的不准确,分类结果极大地依赖于果农或者经销商的个人主观经验,且无法大批量地对果实进行分级筛选,导致难以在产业上推广应用。而后者虽然可以取得较为准确的结果,但这种方法检测过程复杂耗时,需要破坏水果,导致只能对抽样果实进行检测,同样无法对枇杷果实进行大批量的品质检测,无法满足市场上枇杷快速分级筛选的需要。因此,目前市场上的枇杷果实极少按照内部品质进行分级销售,这使得优质的枇杷果实不能以优价销售,从而造成枇杷果实经济价值的浪费。
近红外光谱技术作为一种快速、无损、简便的检测技术,已在生物、食品、能源、农业等领域得到广泛的应用[3-6]。由于近红外光谱结合化学计量学方法可以实现水果的快速检测,已被应用于多种果实的内部品质检测,如枇杷[7]、苹果[8]、桃[9]、梨[10]、柑橘[11]等。但目前大多数应用近红外光谱技术进行的果实品质检测研究主要存在3 方面问题:一是采用的台式光谱仪较昂贵,尚没有开发出低成本的便携式枇杷专用检测仪,限制了仪器的产业化推广;二是大多研究都只对同一时间段采集的建模集和预测集样本进行建模,没有考虑模型在不同年度样本中的应用效果;三是光谱采集大多由专业的检测人员进行,采集过程非常小心,但在实际生产中,仪器的使用者往往不是专业检测人员,导致基于实验室里精心采集的光谱数据所建立的模型在实际应用中检测精度不佳。
针对上述问题,本研究拟采用自主研发的便携式枇杷果实品质无损检测仪,分别采集2018和2019年的枇杷光谱数据,然后采用化学计量学分析方法构建枇杷果实中的重要品质指标——可溶性固形物(total soluble solids,TSS)的检测模型,并开展独立样本年度验证,以实现枇杷果实的快速无损品质分级。
1 材料与方法
1.1 试验设备
枇杷果实品质无损检测仪的结构示意和实物图如图1所示,其光谱范围为900~1 700 nm,光谱分辨率为10 nm,单次1 s扫描,信噪比为5 000∶1,狭缝尺寸为1.69 mm×0.025 mm,传感器为1 mm3的正方体非制冷铟镓砷芯片,扫描形式为直线扫描。仪器上部开口,便于放置枇杷样品及进行光谱采集。
无损检测仪光路模拟如图2 所示,大致的光路过程如下:在枇杷采集过程中将未吸收的反射光谱线导入狭缝,狭缝分散光经过准直镜后变为平行光并投射到平面光栅上进行波段分光,然后将分光后的光线导入聚焦镜,将平行光聚焦成线形光并在直线性探测器上进行感光,驱动点探测器移动和进行分光扫描,并将探测器上的信号通过通用串行总线(USB)接口导入电脑内存,在电脑界面中显示光谱信息,最终实现光谱数据的采集和分析处理。
1.2 样本准备与数据采集
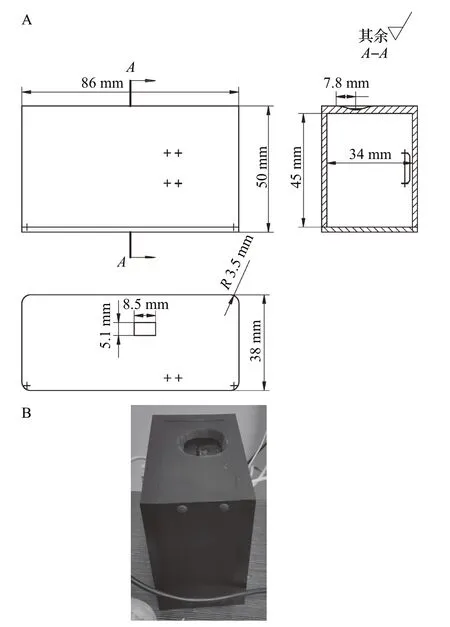
图1 枇杷果实品质无损检测仪结构示意(A)和实物图(B)Fig.1 Schematic diagram(A)and physical map(B)of nondestructive detector for loquat fruit quality

图2 枇杷果实品质无损检测仪光路图Fig.2 Light path of non-destructive detector for loquat fruit quality
以江苏省苏州地区主栽的‘白玉’枇杷品种为试验材料,于2018 年5 月采摘并挑选出无病虫害、无明显机械损伤的八成熟‘白玉’枇杷作为研究对象。采摘后立即运回实验室,在25 ℃条件下保存6 h,而后对其进行编号和光谱采集(采集积分时间为1 s,功率为20 W)。为减少样品表面差异性带来的误差,每个枇杷样品数据采集5次,平均处理后得到一条平均光谱,作为枇杷果实的样本光谱。共对200颗枇杷果实进行光谱采集,得到200条光谱。每条光谱有100 个波段,即100 个变量。光谱采集过程由此前没有经过光谱采集训练的人员进行。完成近红外光谱采集后,剪碎枇杷果肉,挤出果汁,使用手持式阿贝折射仪(PAL-1,日本爱拓公司)测定每个枇杷果实的TSS 值,作为数据建模的参考值。为了开展模型的年度验证,于2019 年另外采摘30颗‘白玉’枇杷,获取其光谱数据,并测定其TSS 含量。光谱采集方法与2018年的一致。
1.3 模型构建
为构建枇杷果实TSS 值与光谱数据之间的定量关系,采用线性偏最小二乘(partial least squares,PLS)回归模型[12]和非线性最小二乘支持向量机(least squares support vector machines,LS-SVM)模型[13]进行回归模型的构建,并对这2个模型的计算结果进行分析和对比,确定最优回归模型。PLS 采用蒙特卡洛交叉验证来确定潜在变量个数。LS-SVM采用径向基核函数,其2个参数(γ和σ2)的最优值通过基于留一法交叉验证的网格搜索寻优得到。
为进一步简化模型计算,提升模型的预测精度,无信息变量消除法(uninformative variable elimination,UVE)[12]和竞争性自适应重加权算法(competitive adaptive reweighted sampling,CARS)[14]2种常用的光谱变量选择方法被采用。UVE主要用于消除那些无信息变量,留下信息变量,而CARS则主要是基于自适应重加权采样和交叉验证来进行无信息变量的剔除。基于选出的特征变量构建更简化的定量模型,并将模型表现与全变量模型进行对比,从而确定枇杷果实品质检测最优模型策略。
本研究的建模思路是:首先对2018 年的200 个枇杷果实样本按照建模集和预测集比值为3∶1 的比例,对样本进行随机划分,建立2018 年度的枇杷果实预测模型。而后为进一步验证模型的泛化能力,应用2018 年的200 颗枇杷果实的光谱数据和TSS 值作为建模集构建检测模型,以2019 年的30颗枇杷果实作为独立预测集来进行模型的年度验证。
建模得到的结果评价采用2种思路进行。一种是常规的光谱模型评价方法,即基于建模集相关系数(Rc)、预测集相关系数(Rp)、建模集均方根误差(root mean square error of calibration,RMSEC)、预测集均方根误差(root mean square error of prediction,RMSEP)、剩 余 预 测 偏 差(residual prediction deviation,RPD)对建立的模型进行评价。另外一种思路则是以实际生产上更适合的好果率和选果率来评价,以更切合果农需求。模型结果的评价指标主要包括:一类好果率(一类好果数除以总果数)、二类好果率(二类好果数除以总果数)、选果率。根据产业实际需求,一类好果被定义为TSS 值大于14°Brix,二类好果被定义为TSS 值大于13°Brix。选果率的定义为:通过模型无损选出的好果数除以全部样本中实际的好果数。
2 结果与分析
2.1 枇杷近红外光谱响应信号分析
2018 和2019 年度枇杷果实的近红外光谱平均数据如图3所示。从中可以看出,2018与2019年采集到的近红外光谱线趋势整体一致。900~1 400 nm波段范围的整体光谱反射率在10%~40%之间;1 400~1 600 nm 范围的整体光谱反射率在5%~20%之间;1 600~1 700 nm范围内的整体光谱反射率有一定的上升趋势。在960、1 200和1 440 nm附近存在典型的枇杷果实光谱吸收峰。其中960 nm附近的吸收峰被归属于O—H 拉伸振动的二级倍频,1 200 nm 附近的吸收峰被归属于C—H 拉伸振动的一级和二级倍频以及C—H拉伸和伸缩振动的一级倍频的合频,1 440 nm 附近的吸收峰被归属于O—H拉伸振动的一级倍频[7,15]。从光谱图中虽然可以得到光谱波段响应信息,但无法完成枇杷果实无损检测的定量分析,因此还需结合化学计量学方法进行数据挖掘和建模分析。

图3 2018和2019年度枇杷果实近红外光谱平均响应信号Fig.3 Average response signals of near-infrared spectra of loquat fruit harvested in 2018 and 2019
2.2 基于全变量的枇杷果实品质检测计算结果
基于2018 年采集的200 颗枇杷果实的全变量光谱数据分别建立了PLS和LS-SVM回归模型,结果如表1 所示。可以看到,线性PLS 模型的结果优于非线性LS-SVM 模型。其中PLS 模型的Rc和Rp值分别达到了0.802和0.765,RMSEP达到了1.358,RPD值为1.553。这些结果表明,采用相同年份的枇杷果实建立的预测模型可以对枇杷果实进行预测,其结果可用于枇杷果实品质检测。进一步基于2018年数据建立的全变量模型预测2019年的数据。结果(表1)显示:LS-SVM 的Rc和Rp值分别达到了0.869 和0.796,RPD 值达到了1.577,优于用2018 年数据所建立的回归模型;而PLS回归模型取得了更好的预测结果,其Rp值达到0.819,RPD 值达到1.729,相 比 于LS-SVM 模 型 的RPD 值 提 升 了9.638%,而且RMSEP 也从2.027 减小到了1.634。上述结果表明,在采用全变量进行建模时,PLS模型可以取得更好的预测精度,且在分析跨年度样本时同样可以取得较好的预测结果。
2.3 基于特征变量的枇杷果实品质检测计算结果
经过UVE和CARS进行变量选择后,分别从全变量中筛选出26和28个特征变量,相比于100个全变量,变量个数分别减少了74%和72%。基于这2种方法选出的特征变量分别建立枇杷分级筛选模型,计算结果如表1所示。从中可以看出,经过变量选择后建立的模型,其RPD 值均在1.619~1.881 之间。通过综合比较和分析,发现在这4个特征变量回归模型中,UVE模型在不同程度上出现了欠拟合的现象,即Rc与Rp出现较大偏差。因此,虽然基于UVE建立的模型可以取得较高的预测精度,但由于模型欠拟合,UVE 模型并非最优的枇杷筛选分级模型。导致UVE模型过拟合的原因主要是,虽然UVE能够去除无信息的变量,从而将有信息的变量选择出来,但无法解决变量冗余度高的问题,从而导致模型容易过拟合。而对比竞争性自适应重加权算法-偏最小二乘法(competitive adaptive reweighted samplingpartial least squares,CARS-PLS)和竞争性自适应重加权算法-最小二乘支持向量机(competitive adaptive reweighted sampling-least squares support vector machines,CARS-LS-SVM)的分析结果可以看出,CARS-LS-SVM 具有更好的预测效果,其RMSEP 值为1.453,Rp值为0.818,RPD 值为1.737。对比全变量定量分级模型可以看出,虽然CARSLS-SVM模型与全变量模型PLS在预测精度上无显著性差异,但CARS-LS-SVM不仅可以减少变量个数、简化计算,还能够进一步降低模型的RMSEP值。这表明先进行CARS变量选择再建立LS-SVM模型是建立枇杷果实品质快速筛选模型的更好策略。

表1 枇杷果实品质分级模型的回归结果Table 1 Regression results of grading model for loquat fruit quality
2.4 基于全变量和特征变量的枇杷果实品质分级模型计算结果
基于2.1和2.2节的分析可以看到,在全变量和特征变量条件下的较优模型分别为基于2018—2019跨年度的全变量PLS(FULL-PLS)模型和特征变量CARS-LS-SVM模型。为更准确地了解模型对枇杷果实的分类效果,进一步对这2个模型的好果识别率进行统计和分析。本研究中,在2019年所采集的30个枇杷果实中,有15 个一类枇杷(TSS>14°Brix),22个二类枇杷(TSS>13°Brix)。基于这些信息,我们计算了预测集的好果率和选果率。从表2可以看出,对于FULL-PLS 模型,一类好果率从50.00%提升到了60.00%,而二类好果率则从73.33%提升到了78.57%,好果识别率提升了5.24%。值得注意的是,在分类模型中仅仅考虑好果率这一个指标是片面的。即模型在预测过程中,并不是所有的好果都被选择出来,也有部分好果会被模型判定为差果。因此,为更准确地描述分类这一结果,我们还计算了一类和二类选果率。从表2可以看出:全变量PLS模型在一类枇杷和二类枇杷上的选果率均达到了100%。而最优的特征变量模型CARS-LS-SVM 在一类好果率和二类好果率的结果上优于全变量PLS模型;其预测集的一类好果率和二类好果率分别达到了71.43%和81.48%,而选果率则均达到了100.00%。
从表2 中还可以看出,虽然一类好果率和二类好果率在经过模型分级后有一定的提升,但好果率提升程度有限。为更有把握地选择出高品质的好果,我们进一步将模型TSS 预测值在15°Brix 以上的枇杷果认定为一类好果(TSS>14°Brix),再根据其参考值是否大于14°Brix来判断该样本的预测是否正确。同理,将模型TSS 预测值在14°Brix 以上时挑选的枇杷果认定为二类好果(TSS>13°Brix),再根据其参考值是否大于13°Brix来判断预测是否正确。根据上述原则,对2019 年的30 个独立验证集的枇杷果实进行统计分析,结果如表3 所示。可以看到,经过更加严格地筛选,好果率得到了进一步提升。一类好果率和二类好果率较分级前的提升幅度分别达到了30%和10%以上。虽然模型选果率有所下降,但仍然维持在一个较高的选果率水平(大于80%)。基于以上分析可以看出:对枇杷果实按照TSS含量进行检测可以取得较高的分选准确性,对于提升枇杷果实经济价值具有重要作用;更高标准的TSS 指标可以显著地提升分级模型的好果率,同时能够保证选果率维持在一个较高的水准。

表2 枇杷果实品质分级模型的预测集分类结果Table 2 Classification results of prediction set of grading model for loquat fruit quality %

表3 提高分选标准后的枇杷果实品质分级模型的预测集分类结果Table 3 Classification results of prediction set of grading model for loquat fruit quality after raising the sorting standard %
3 讨论
目前已有基于自制便携式光谱仪进行农产品品质无损检测的研究[16-17],但尚未有关于枇杷果实的光谱仪器开发的研究。本研究开发的枇杷果实品质无损检测仪具有低成本、便携、专门适用于枇杷检测等优点,相比于实验室常用的分辨率较高且性能较好,但价格昂贵的光谱仪,可以大大地节省硬件成本,便于后续的推广应用。结果表明,枇杷果实品质无损检测仪可以实现江苏省苏州地区‘白玉’品种枇杷的TSS 值检测。同时,本研究在模型建立过程中采用2018和2019年度的枇杷果实数据作为独立建模集和预测集,避免了单一时间采集枇杷样本光谱造成的模型在实际生产中适用性不强的问题。结果显示,仪器可以用于不同年度果实的检测。此外,由于整个光谱采集过程是由非专业人员操作的,也模拟了实际产业应用中仪器操作人员大多是非专业的情况,更加验证了仪器的适用性。
进一步对检测结果分析可以看出,基于全变量建模时,线性的PLS模型无论是在RPD值上还是在RMSEP 值上均优于非线性的LS-SVM 模型,表明使用全变量建模时PLS 相比于LS-SVM 是更好的选择。而经过变量选择后建立的模型则相反,即LS-SVM 得到的效果优于PLS 模型。这表明在实际生产应用中应根据具体情况选择适合的建模策略,以取得最好的预测效果。另外,对光谱数据进行变量选择后可以看出,大部分的无信息变量都被消除了,但基于UVE选择的特征变量进行建模分析时出现了欠拟合的现象。综合比较全变量和特征变量6 个模型,确定最优模型为CARS-LS-SVM 模型。基于该模型的水果分类结果可以看出,一类好果率和二类好果率分别提升了21.43%和8.15%,而且选果率达到了100.00%。另外,当依据更高标准的TSS指标进行分选时,可以在选果率较高的水准下,显著提升一类和二类好果率。这种分选策略将更有利于产业应用中提升枇杷果实的经济价值。
虽然枇杷果实品质无损检测仪可以在一定程度上对枇杷果实品质进行快速无损检测,但分级筛选模型精度仍有待提升。造成这一结果主要有2方面的原因:一方面可能是不同年份采集的枇杷果实之间存在差异,使得基于某一天采集的样本建立的模型的代表性不够。针对这一问题,后续我们将进行更多年份的枇杷果实检测,使样本数据充分具有代表性。另一方面则可能是自主研发的近红光谱仪在操作过程中存在的系统误差和不同测量人员操作时带来的差异。针对这一问题,我们将在后续的研究中测试多台次的该款近红外光谱仪,比较仪器生产的稳定性;同时通过进一步提升仪器的硬件性能,尽量避免操作误差带来的影响。
4 结论
本研究结果表明:使用自主研发的枇杷果实品质无损检测仪和建立的CARS-LS-SVM 模型获得了较好的预测结果,其中CARS-LS-SVM 模型的RMSEP 值为1.453,Rp值为0.818,且分级后一类好果率和二类好果率分别从50.00%和73.33%提升到了86.67%和85.71%。总之,使用自主研发的光谱仪不仅可以实现‘白玉’品种枇杷TSS 值的快速无损检测,而且使用近红外光谱无损检测技术进行果实分级后,可以在少错判好果的基础上,显著提高优质果实的选果比例,提升产品的商品价值。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
儿童时代(2022年1期)2022-04-19
娃娃乐园·综合智能(2021年11期)2021-12-06
中国果业信息(2021年1期)2021-12-01
空间科学学报(2021年1期)2021-05-22
热带农业科技(2021年1期)2021-01-14
中国果业信息(2020年6期)2020-12-16
今日农业(2019年14期)2019-01-04
小学生导刊(2018年34期)2018-12-18
学苑创造·A版(2018年2期)2018-01-23
