
基于深度学习网络模型的车辆类型识别方法研究
2020-05-26 12:33赵池航林盛梅李彦伟薛善光钱子晨
筑路机械与施工机械化 2020年4期
石 鑫,赵池航,林盛梅,李彦伟,薛善光,钱子晨
(1.河北交通职业技术学院 土木工程系,河北 石家庄 050011; 2.东南大学 交通学院,江苏 南京 211189; 3.河北省交通规划设计院 公路建设与养护技术、材料及装备交通运输行业研发中心,河北 石家庄 050011)
0 引 言
车辆类型信息已成为公共交通服务、交通运行监管和安全防护等行业中数据处理与分析的基础,因此,研究基于图像的车辆类型识别方法已经成为智慧交通系统车辆管理和维护工作中亟待解决的问题。Geoffrey Hinton教授提出模型训练的改进方法打破了神经网络层数不能过多的瓶颈。他提出两个观点:一是多层神经网络有更强的特征学习能力,能得到更有利于分类的深层特征;二是深层神经网络的训练难题可以通过逐层训练解决。历经单层感知机、多层感知机、BP神经网络和深层神经网络的发展,深度学习孕育而生。深度学习现已成为人工智能的一大热点,在图像检测、图像分类及自然语言处理等领域均取得了举世瞩目的成绩。2015年,Rong等提出利用自动稀疏编码器生成卷积核[1],利用该卷积核生成卷积特征,之后进行池化操作,重复该步骤得到深层网络框架,达到车型分类的目的。Dong等基于车辆正面图像提出一种半监督卷积神经网络模型[2],引入稀疏拉普拉斯过滤器对无标签数据进行学习,仅将一小部分数据用于分类层Softmax函数训练。2017年,Wang等使用深度迁移学习对车辆图像进行车型分类[3],建立一个既可用于网络图像又可用于监控图像的卷积神经网络模型。2018年,Chen等基于车尾图像提出卷积神经网络行分类模型[4],将车辆尾部图像归一化为32×32送入神经网络中进行车型分类。为了有效提高车辆类型的识别精度,本文基于迁移学习理论,构造了用于车辆类型分类的深度学习网络模型。
1 卷积神经网络
卷积神经网络(Convolutional Neural Network,简称CNN)是专门用来处理形如网格结构数据的神经网络,对于图像数据、时间序列数据等典型网络结构数据的处理表现优异。典型的卷积神经网络包括卷积层、池化层和全连接层。卷积层顾名思义就是对该层网络进行卷积运算。在卷积网络的术语定义中,卷积的第1个参数通常称为输入,第2个参数通常称为核函数,输出也称作为特征映射。由卷积层的定义可以看出,卷积层的运算过程是一个自动提取特征的过程,因此卷积神经网络相对于传统的全连接神经网络而言,既是一个特征提取器,又是一个分类器,能够自主学习特征,而不需要人工预先提取特征。卷积神经网络运用了2个重要思想来改进传统神经网络算法:稀疏交互和参数共享。
传统神经网络中每层的神经元通过矩阵乘法进行交互运算,并且每层的所有神经元都与下一层的所有神经元进行交互。对于卷积网络而言,卷积运算具有稀疏性,即具有稀疏权重的特征,这是由于卷积核尺寸远远小于输入的尺寸。当处理图像时,图像可能有成千上万个像素点,但是对于分类任务或者识别任务而言,只需要对其中的几百个或者几十个特征进行表征,因此采用稀疏权重计算图像特征可以在表示图像的同时减少模型存储空间,提高模型效率。参数共享是卷积网络的又一个重要特征,是指在一个模型中有多个函数使用同样的参数。在传统神经网络中,在计算层参数时,权重矩阵元素都仅仅使用1次,每2个神经元之间的参数都是独立不共享的。而在卷积网络中,卷积核的每个元素都用在每个输入单元中,并不需要针对不同的位置学习独立参数。这种共享权重的方式将模型存储需求空间降低,并在统计效率方面远优于稠密算法。一个典型的卷积网络层通常包括3级:第1级,并行地计算多个卷积产生一组线性激活响应;第2级中,使用激活函数将线性激活响应进行整流;第3级中使用池化函数来调整输出。所谓池化计算,就是使用某位置相邻的总体统计特征作为该位置的输出。常用的池化函数有:最大池化(Max Pooling)、平均池化(Mean Pooling)、L2范数和加权平均函数等。
2 基于迁移学习理论的车型分类深度学习网络模型
2.1 迁移学习理论
对于深度学习而言,几十层甚至几百层网络往往涉及亿万个参数训练,所需训练集的数据量十分庞大。例如,典型的深度学习网络VGGNet具有16~19层,参数数量达到上亿个,基于数据量达120万张的ILSVRC-2012数据集,该网络在装有4个NVIDIA Titan Black GPU的电脑上训练时间长达2~3周。而对于数据量较小的分类问题,例如本文中的车型分类问题,数据量远远不足以从零开始训练一个深层神经网络,因此需要借助迁移学习技术,基于已训练好的成熟网络进行再训练。迁移学习(Transfer Learning)就是将一个场景中学习到的模型、参数运用到另一个场景中,这两个场景应该属于相似的领域,并且具有相似的任务。由于直接对新场景进行学习成本较高,因此采用迁移学习找到新场景与老场景的相似点,这也是迁移学习的核心。将已有的知识叫做源域,待学习的新知识叫做目标域,迁移学习就是将源域的知识迁移到目标域中,源域与目标域通常有一定的关联。在数据分布、特征维度以及模型输出变化的条件下,基于源域中的知识对目标域更好地建模,并不需要从零开始建模。这种学习方式在有标定数据缺乏的情况下,可以很好地利用相关领域有标定的数据完成数据的标定,在数据样本比较少时,可以以相关领域模型为基准进行再训练。
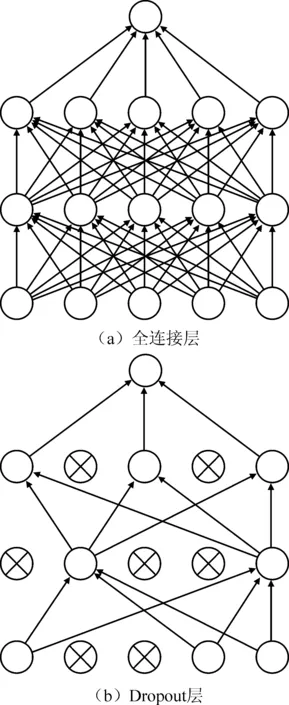
图1 经典网络与Dropout网络
经典的卷积神经网络通常是在低层采用卷积运算,之后采用全连接层进行分类,可以简单地理解为卷积层是在提取图像特征,全连接层是传统的神经网络分类器。但是全连接层参数数量庞大,参数数量太大会导致2个瓶颈:一是训练的机器配置压力较大,且耗时长,降低训练效率;二是容易导致过拟合,网络的泛化能力不尽人意。因此,本文在迁移学习已有成熟网络的同时采用参数优化策略,用以降低参数数量,并防止过拟合。本文采用Dropout和全局平均池化2种策略。Dropout是指在深度神经网络训练中,按照一定概率随机地将网络中的隐藏节点暂时丢弃,丢弃的节点可以认为暂时不属于网络结构。从理论上来说,可以将Dropout看作是模型平均的一种。如图1所示,Dropout后的网络与经典网络相比更“瘦”,在图示网络中,经典网络中有55个参数,在Dropout一半节点后,参数变成15个。Lin等提出了用全局平均池化层代替全连接层的方法,试验结果表明全局平均池化层代替全连接层具有可行性,并在性能上略优[5]。如图2所示,对于采用全连接层的卷积神经网络而言,每组卷积核对应的特征图输出后将之串联成全连接层的输入后使用Softmax进行多分类,得到输出。对于全局平均池化而言,对每张特征图取平均值,将平均值直接作为Softmax分类的输入与输出节点对应。采用平均池化后特征图只输出1个特征,在保留特征的同时大大减少参数,可以很好地避免过拟合。
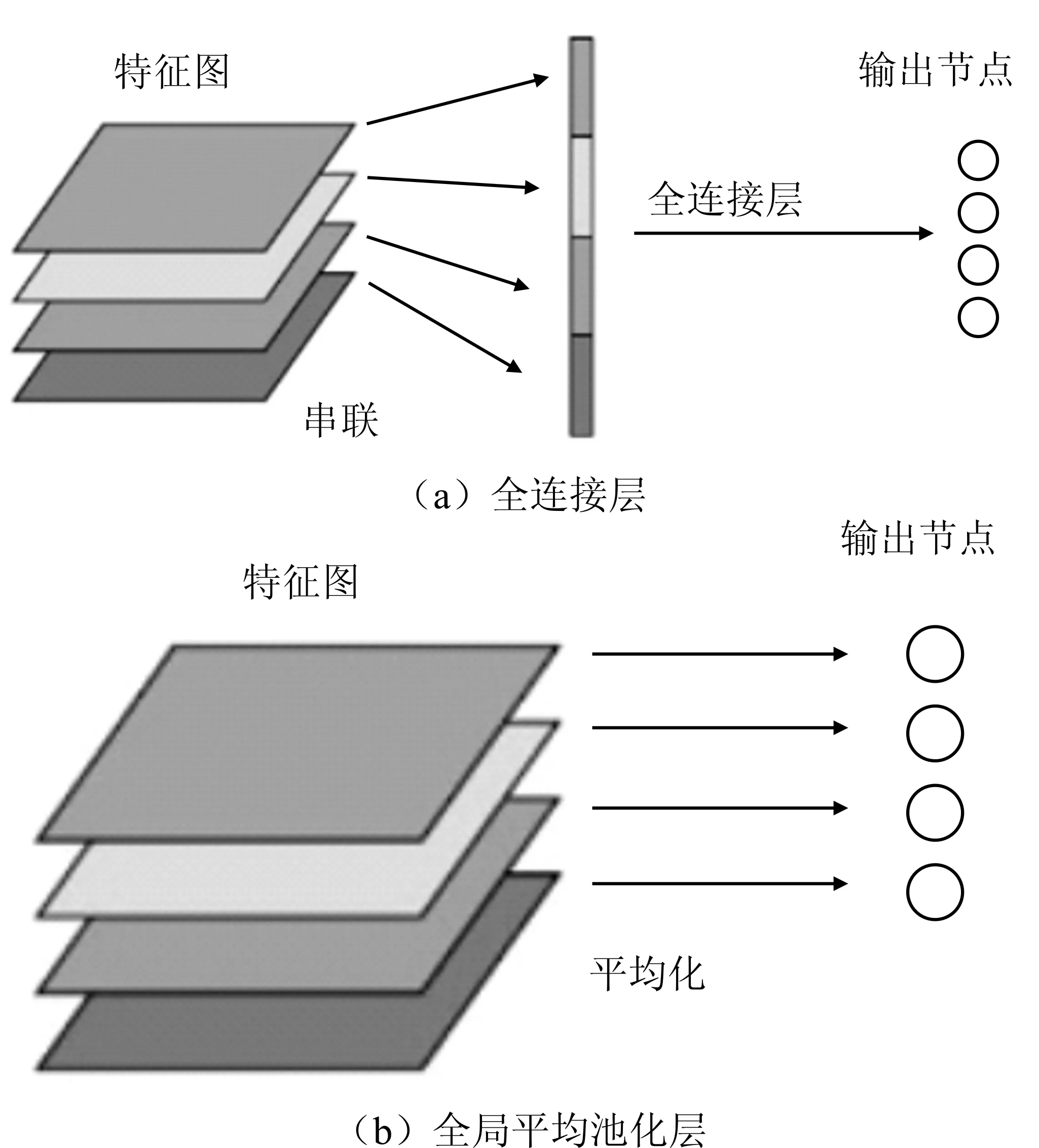
图2 全连接层与全局平均池化
2.2 基于迁移学习理论的Inception V3车型分类模型
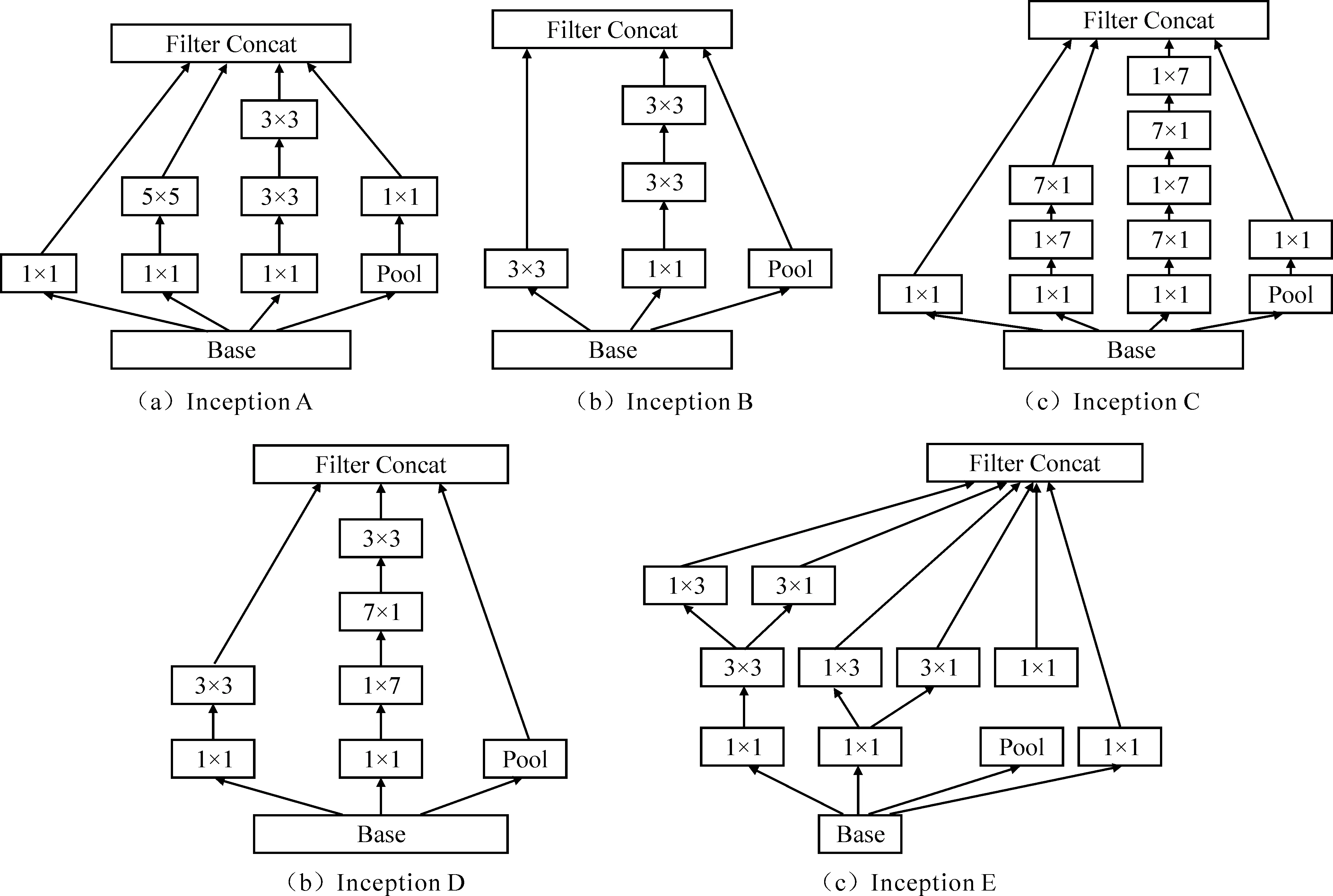
图3 Inception单元结构
Inception网络与传统卷积神经网络最大的不同之处在于:传统卷积神经网络如VGG结构将卷积网络层层堆叠,是典型的纵向结构,而Inception网络除了纵向堆叠卷积层,还提出Inception层,而Inception单元是由不同尺寸卷积核叠加而成,这个叠加过程增加了网络的“宽度”,也增加了网络对于尺度的适应性[6]。典型的Inception单元如图3所示,以Inception A为例,该单元结构使用1×1卷积核、3×3卷积核、5×5卷积核和pool核为基础,纵向横向叠加,直接使用1×1卷积核得到当前尺度特征,使用1×1卷积核后进行5×5卷积计算可以得到浅层卷积特征,使用1×1卷积核后进行2次3×3卷积计算可以得到深层次卷积细节特征,池化后进行1×1卷积计算得到下采样后的特征。总之经过Inception单元计算后,可输出不同尺度特征图。Inception V3网络的低层结构还是经典的卷积层堆叠,采用卷积层-卷积层-卷积层-池化层-卷积层-卷积层-池化层的结构,池化之后加入3个Inception A单元,连接1个Inception B单元,连接4个Inception C单元,连接1个Inception D单元,连接2个Inception E单元,之后采用平均池化处理和Dropout处理,再采用全连接层后进行Softmax分类。
本文提出的基于Inception V3的车型分类模型是在Inception V3的基础上去除最后的全连接层,并加入参数优化层,采用Dropout和全局平均池化层,具体结构见表1。整个网络模型输入为299×299 RGB三通道图像,每个block代表1组计算,前2组为卷积计算,1组卷积计算中包含若干卷积层和1个池化层,卷积核为3×3,完成2个Block卷积计算后,与Inception单元相连,Block 3中使用3个Inception A单元,Block 4中使用1个Inception B单元,Block 5中使用4个Inception C单元,Block 6中使用1个Inception D单元,Block 7中使用2个Inception E单元,之后与全局平均池化层相连,再使用丢弃率为0.5的Dropout层,最后用Softmax函数与输出节点相连。
3 其他类型的卷积神经网络模型
3.1 基于VGG-16的车型分类模型
VGGNet网络结构有A、A-LRN、B、C、D和E等6种不同结构,层数和参数配置基本一样,常用的网络层数通常有11层、13层、16层和19层,11层和13层VGGNet大约有133百万个参数,16层C类结构有134百万个参数,16层D类结构有138百万个参数,19层E类结构有144百万个参数。综合考量性能和参数,本文将D类的VGGNet网络结构(VGG-16)用于车型分类。VGG-16结构整个网络分成5个Block,每个Block内有多组卷积,卷积核均为3×3,Block间通过最大池化层连接。3个全连接层,采用ReLU激活函数,最后使用Softmax进行多分类。本文在VGG-16模型的基础上去除最后3个全连接层,并在卷积层之后加入参数优化层,采用Dropout和全局平均池化层。整个网络模型输入为224×224 RGB三通道图像,每个Block代表1组卷积计算,1组卷积计算中包含若干卷积层和1个池化层,卷积核为3×3,完成5个Block卷积计算后,与全局平均池化层相连,之后使用丢弃率为0.5的Dropout层,最后用Softmax函数与输出节点相连。
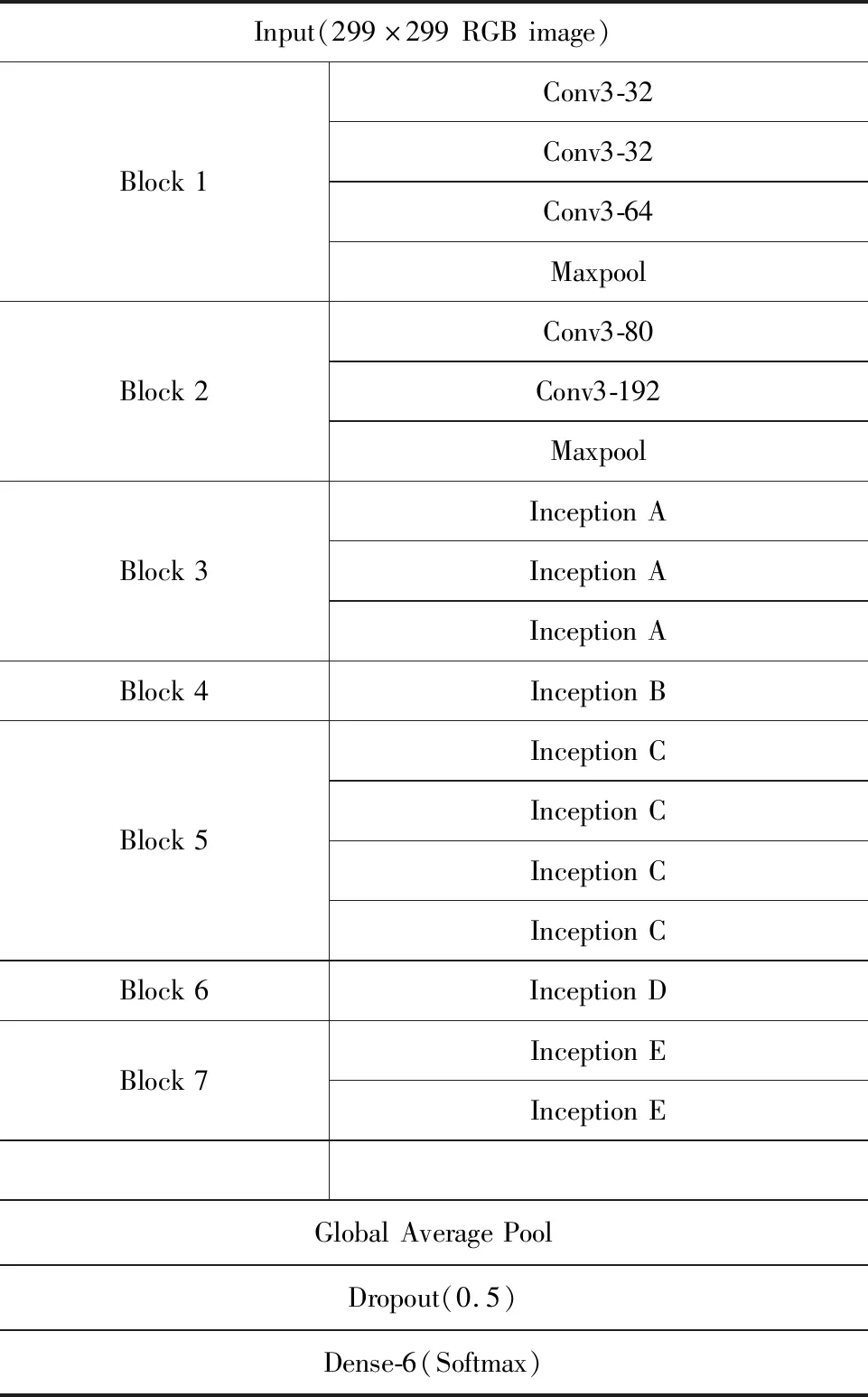
表1 基于Inception V3的车型分类模型结构

图4 东南大学车辆类型图像样例
3.2 基于Xception的车型分类模型
Xception网络结构的最大特点在于引入深度可分卷积(Depthwise Separable Convolution)计算。该计算过程的核心在于深层卷积计算,Xception网络结构分为输入模块、中间模块和输出模块。本文在Xception的车型分类模型的基础上去除最后的全连接层,并加入参数优化层,采用Dropout和全局平均池化层。整个网络包括输入模块、中间模块和输出模块,模型输入为299×299 RGB三通道图像。输入模块进行2次卷积核为3×3的卷积运算,并经过激活函数提高非线性,之后连接深度可分卷积运算单元,每个运算单元都包含2次带ReLU激活函数的3×3深度可分卷积运算和最大池化,输入模块得到19×19×728的特征图。中间模块是8个一样的深度可分卷积运算单元相连,每个运算单元都包含3次带ReLU激活函数的3×3深度可分卷积运算。输出模块是1个深度可分卷积运算单元,运算单元包含2次带ReLU激活函数的3×3深度可分卷积运算和最大池化,之后进行2次带ReLU激活函数的3×3深度可分卷积运算。最后与全局平均池化层相连,再使用丢弃率为0.5的Dropout层,最后用Softmax函数与输出节点相连。
3.3 基于Resnet50的车型分类模型
Resnet网络结构的核心是残差学习(Residual Learning)。在常规网络中,每层求解参数时目标函数都是最优解的映射H(X),对于Resnet网络而言,并不直接匹配最优解映射H(X),而是去匹配1个残差映射F(X)=H(X)-X。本文在Resnet50模型的基础上去除最后的全连接层,并加入参数优化层,采用Dropout和全局平均池化层。Resnet50第1层为7×7的卷积层,之后进行3×3池化,之后连接3个Conv2_x单元、4个Conv3_x单元、6个Conv4_x单元和3个Conv5_x单元,其中Conv2_x单元、Conv3_x单元、Conv4_x单元和Conv5_x单元均包括3个卷积层,卷积算子分别为1×1,3×3和1×1。最后与全局平均池化层相连,再使用丢弃率为0.5的Dropout层,最后用Softmax函数与输出节点相连。
4 试验分析
本文试验基于构建的东南大学车辆类型图像库,包括9 850幅车辆图像,车辆图像分为客车、小客车、小货车、轿车、SUV和卡车6种类型,像样例如图4所示。本文试验中所用算法模型均在Jupyter Notebook (Ipython)环境中基于Python3.6和Keras深度学习框架(TensorFlow作为后端),计算机CPU配置为Intel Core i7-6700HQ 2.6 GHz,RAM为8 GB,ROM为1 TB;显卡配置为NVIDIA GeForce GTX960M,显存为4 G。试验中采用东南大学车辆类型图像库的60%作为训练图像,20%作为验证图像,剩余20%作为测试图像。
图5为Resnet50-VCM 使用Adam优化器的训练过程,图6为Resnet50-VCM 使用RMSprop优化器的训练过程,图中左上角train-loss图代表训练损失随着迭代次数的变化,左下角validation-loss图代表验证损失随着迭代次数的变化。图中右上角train-accuracy图代表训练精度随着迭代次数的变化,右下角validation-accuracy图代表验证精度随着迭代次数的变化。可以看出,无论是Adam优化器还是RMSprop优化器,在迭代8次epoch之后模型趋于收敛,模型收敛时的训练精度和验证精度都基本持平,但RMSprop优化器随着迭代次数增加精度变化较为缓慢,验证损失明显呈下降趋势。反观Adam优化器训练损失和验证损失在经过2次epoch后下降缓慢,无论验证精度还是训练精度均呈上升态势。模型训练损失和验证损失对比如图7所示,VGG16-VCM的训练损失和验证损失较大,模型没有得到很好的收敛效果,从损失便可以看出此模型精度可能比较低。除了VGG16-VCM之外,其余3个模型的损失均较小于0.6,并且验证损失都大于训练损失,符合训练规律,说明Resnet50-VCM、Inception-VCM和Xception-VCM都是拟合较好的模型,模型结构与车型分类问题比较适配。模型训练耗时对比如图8所示,Resnet50-VCM、Inception-VCM和Xception-VCM计算1个epoch需要近1 min的时间,由于VGG16-VCM只有十几层结构,所以耗时仅需28 s,而Resnet50-VCM、Inception-VCM和Xception-VCM结构都比较复杂,层数达到几十层甚至100多层,耗时都将近1 min,训练效率较低。
从表2可得,VGG16-VCM模型在使用RMSprop优化器时训练精度和验证精度都比使用Adam优化器更高。Resnet50-VCM、Inception-VCM和Xception-VCM使用不同优化器对精度的影响较小,属于正常误差范围,可以看出,优化器的选取对于模型精度的影响并不大。从图9可知,VGG16-VCM精度在4个模型中最低,测试精度小于0.7,这说明VGG16-VCM并不能很好地拟合车型分类问题,这与之前loss分析得到的结论一致。除VGG16-VCM外,Resnet50-VCM、Inception-VCM和Xception-VCM都得到比较好的训练精度,4个模型中精度表现最好的为Inception-VCM,测试精度达83.85%。经过训练得到5个车型分类模型后,对测试集进行测试试验。为测试模型的稳定性及鲁棒性,用测试集与验证集作为测试样本库,进行100次交叉验证测试试验,每次试验从测试样本库中随机抽取1 800张图像,并统计模型精度。模型精度箱型图分布如图9(b)所示。从图中可以看出,Inception V3-VCM模型精度较高,Inception V3-VCM和Resnet50-VCM精度相差无几,Inception V3-VCM和Xception-VCM模型精度分布在一个比较小的范围内,说明模型有比较好的稳定性。VGG16-VCM和Resnet50-VCM有几个异常点,说明模型稳定性不好。综合对比可知,Inception V3-VCM优于其余3种模型。
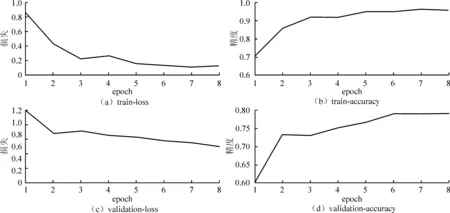
图5 Resnet50-VCM Optimizer=Adam 训练过程

图6 Resnet50-VCM Optimizer=RMSprop 训练过程

图7 模型训练和验证损失对比

图8 模型训练耗时对比

表2 不同优化器模型精度对比

图9 模型精度对比
表3为Inception V3-VCM模型的混淆矩阵。混淆矩阵每行表示预测类,每列表示真实类。例如,第1行第1列表示真实类别为Bus、识别为Bus的样本数为110,第2行第1列表示真实类别为Microbus、识别为Bus的样本数为9,其他行列以此类推。对角线上表示样本正确分类的数目,每种类型车辆被正确识别的样本数分别为:110、165、87、1 022、228和111。由此可以看出,Bus和Microbus正确分类率较高,这可能是因为这两类车与其他类型车辆的卷积特征差距较大,对于样本数量占比较大的Sedan和SUV正确分类率略差,并且由于SUV和Sedan车辆信息一致性较高,出现部分SUV和Sedan误分类的情况。

表3 Inception V3-VCM模型混淆矩阵
6 结 语
为了有效识别车辆类型用于智慧交通系统,本文在分析Inception V3模型的基础上,提出了一种基于迁移学习理论的车型分类深度学习模型,并与基于VGG-16、Xception和Resnet50的车型分类模型进行了对比分析;基于东南大学车辆类型图像库进行了试验研究,理论分析和试验结果表明,基于迁移学习理论的车型分类深度学习模型的性能优于基于VGG-16、Xception和Resnet50的车型分类模型。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
电子制作(2018年11期)2018-08-04
北京航空航天大学学报(2018年1期)2018-04-20
测绘科学与工程(2016年5期)2016-04-17
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
海军航空大学学报(2015年4期)2015-02-27
电子设计工程(2015年3期)2015-02-27
