
基于最近邻的标签修正推荐算法*
2020-06-18 09:07余利国丁卫平
计算机与数字工程 2020年4期
余利国 丁卫平 景 炜
(南通大学信息科学技术学院 南通 226019)
1 引言
随着信息技术和互联网的快速发展,人类逐渐从信息匮乏的时代步入了信息过载(Information Overload)的时代。推荐系统(Recommender System)是解决信息过载问题的重要工具,近年来得到了快速的发展[1~3]。推荐系统的任务是关联用户和信息,一方面帮助用户找到对其有价值的信息,另一方面将信息呈现在对其感兴趣的用户面前,从而实现信息生产者和信息消费者共赢[4]。基于标签的推荐系统是推荐系统中研究与应用的热点[5]。豆瓣是国内个性化推荐领域的领军企业之一,也是标签推荐系统的典型代表。豆瓣提供书籍、电影、音乐等作品的信息,其描述、评论、分类、筛选都是由用户提供和决定,用户对书籍和电影等打标签,网站再使用用户所标注的标签为用户进行个性化推荐[6]。
让普通用户给物品打标签,即User Generated Content(UGC),通过用户对一个物品打上一个标签,这个标签描述了用户的兴趣,也将用户和物品联系起来,分析这种用户行为为用户进行个性化推荐,即为UGC标签推荐系统。
近年来,基于标签的推荐系统在学术界受到了广泛的关注,国际著名会议ECML/PKDD举办了多场基于标签的推荐系统比赛[7~9]。在对其研究中,取得了新的进展并涌现了很多新的方法,比如Krestel等提出基于LDA的算法[10];Symeonidis等构建用户、标签、项目的三阶张量模型,提出结合聚类方法的张量分解,以减小张量进而精简推荐运算[11];Jiang等综合考虑社会关系信息和时间因素,从而改进了基于标签的推荐效果[12]。虽然目前在基于标签的推荐系统上已经有很多研究,但大部分的研究并未考虑到标签的质量问题。由于用户的文化水平存在差异,用户所打标签可能有拼写错误的单词,因此标签质量的优劣也不确定,从而影响基于标签的推荐系统的推荐效果。
基于上述考虑,本文提出一种基于最近邻算法的标签修正算法。该标签修正算法关键在于引入最近邻算法思想,使用欧式公式计算待处理标签与其他标签的距离,找出最接近的单词,即为修正后的单词,并据此修正数据集中所有标签,最后在处理过的标签基础之上为用户进行个性化推荐。
2 基于标签的推荐系统经典算法
本文提出的算法是基于经典推荐算法Classical Tag Based algorithm(CTB)[4]。CTB算法的核心思想为
1)统计每个用户u常用的标签user_tags;
2)对于每个标签tag,统计被打此标签次数最多的物品tag_items;
3)对于每个用户u,首先找到其常用的标签user_tags,然后找到具有这些标签的最热门物品recommend_items,并推荐给这个用户u。
用户u对物品i的兴趣公式如下:

其中nu,b是标签b被用户u使用的次数,nb,i是使用标签b标注物品i的次数。给定用户标签行为记录的三元组(u,b,i)。CTB算法的示例如图1所示,该图包含4个用户(A,B,C,D)、4个标签(1,2,3,4)和5个物品(a,b,c,d,e)。
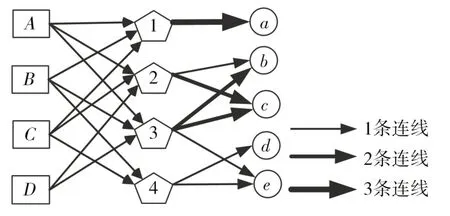
图1 UGC经典算法示例图
由图1可得,用户标签行为记录有(A,1,a)(A,2,c)(A,3,c),(B,1,a)(B,3,b)(B,3,e)(B,4,e),(C,1,a)(C,2,b)(C,4,d),(D,3,b)(D,2,c)(D,3,c)。具体推荐过程如下:首先分别计算出nu,b:nA,1=1,nA,2=1,nA,3=1;nB,1=1,nB,3=2,nB,4=1;nC,1=1,nC,2=1,nC,4=1;nD,2=1,nD,3=2。接着分别计算出nb,i:n1,a=3,n2,b=1,n3,b=2,n2,c=2,n3,c=2,n4,d=1,n3,e=1,n4,e=1。其余未列出的nb,i和nu,b值为0。再次统计出nb,i和nu,b后,根据兴趣公式,可以得出对于用户u兴趣度最高的TopN,作为给用户u个性化推荐的物品。图1示例中,选择用户A,为其个性化推荐物品。据兴趣公式,分别求得位列前两位,所以为用户A个性化推荐的物品列表为(b,e)。
算法1给出了CTB算法为目标用户u产生推荐列表的伪代码。
算法1Recommend
输入:u-目标用户,n-推荐列表中物品的个数
输出:recommend_items-为目标用户u推荐的物品列表
步骤:
1:InitStat()
2:tagged_item=user_items[u]
3:for tag,wut in user_tags[usr].items()do
4:for item,wit in tag_items[tag].items()do
5:if item_not in tagged_item then
6:if item not in recommend_list then
7:recommend_list[item]=wut*wit
8:else
9:recommend_list[item]+=wut*wit
10:end if
11:end if
12:end for
13:end for
14:return Sorted(recommend_list).top(n)
算法1中InitStat()是推荐算法对数据集的初始化方法,该方法进行各项数据的统计,包括每个用户u常用的标签user_tags及对于每个标签tag,被打这个标签次数最多的物品tag_items,用户u打过标签的物品user_items等。
由于要处理海量数据,InitStat()在实验中使用了Spark的RDD离线计算,算法2为其伪代码。
算法2 InitStat
输入:f-数据集user_tagged.dat文件地址字符串
输出:(user_tags,tag_items,user_items)-各项统计数据的集合
步骤:
1:data_file=open(f)
2:line=data_file.readline()
3:while line do
4:terms=line.split(“ ”)
5:user=terms[0],item=terms[1],tag=terms[2]6:addValueToMat(user_tags,user,tag,1)
7:addValueToMat(tag_items,tag,item,1)
8:addValueToMat(user_items,user,item,1)
9:line=data_file.readline();
10:end while
11:return(user_tags,tag_items,user_items)
3 基于最近邻的标签修正推荐算法
3.1 引入最近邻算法
K近邻算法,即K-nearestneighbor(KNN)最早在1967年被Cover和Hart提出,用以处理文本的分类问题[13]。相较于其他分类算法,KNN算法简单且易于实现,分类精准率也较高,适合用于多分类问题,是实际分类应用比较常用的算法[14~15]。KNN算法基本思想是假设一个样本在特征空间中的k个最相邻样本中的大部分属于某个类别,则该样本也属于这个类别,并拥有该类别中样本的特征。
算法3给出了KNN算法的描述。
算法3 KNN
输出:实例x所属的类y
步骤:
1:依据选定的距离度量,在训练集T中找出与x最近的k个点,涵盖这k个点的邻域,记为Nk(x)
2:在Nk(x)中根据分类决策规则(如多数表决),决定x的类别y:

在上式中,I为指数函数,即当yi=cj时,I为1,否则I为0。
KNN算法特殊情况是k=1的情形,称为最近邻算法,对于输入的实例点(特征向量)x最近邻算法将训练数据集中与x最近邻的类作为x的类。本文采取的就是KNN算法的这种特殊情况,即最近邻算法。
在KNN算法中,有很多距离的计算方法,本文采用欧式距离(Euclidean distance)计算待修正单词与其他单词的距离[13],具体计算方式如下:
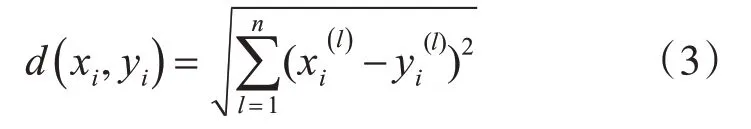
3.2 TCNNB算法核心思想
本文针对用户所打标签可能出现拼写错误的问题,提出基于最近邻的标签修正推荐算法(tag correction recommendation algorithm based on nearestneighbor,TCNNB)。在给用户个性化推荐之前,对用户所打的标签进行修正。其核心思想为:1)分别统计出所有标签单词的字母频次;2)使用欧式距离计算出待处理标签单词与所有其他标签单词的频次之差,即该单词与其他单词的距离;3)根据距离找出最接近的单词,即该单词与其他单词的频次之差的平方和,再求开平方,结果最小的单词。
算法4给出了上述修正过程的伪代码。
算法4Check_Modify
输入:word-待检测标签的单词,words-所有标签中的单词集合
输出:modifiedWord-检测并纠正后的单词
步骤:
1:L=len(words),minDist=0,similarWord=word
2:for i from 1 to L do
3:fre=Counter(word)
4:distance=distance(word,words[i])
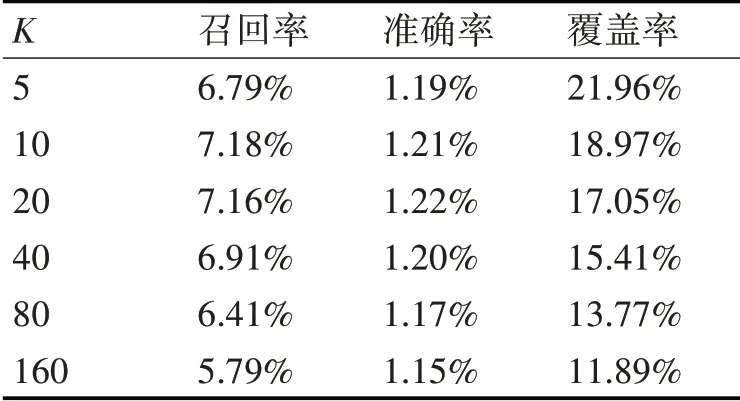
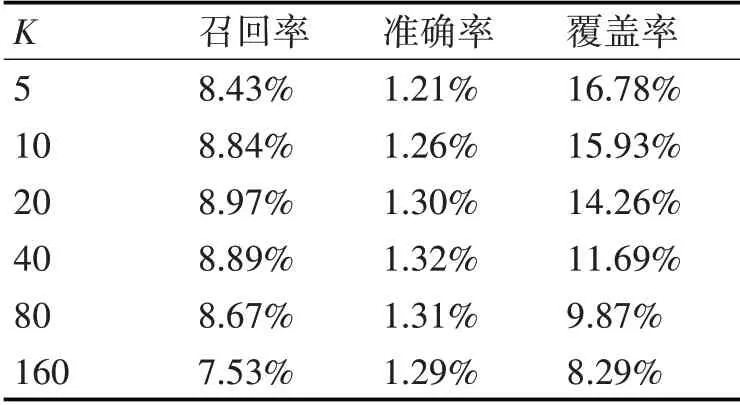
5:if distance 6:similarWord=words[i] 7:minDist=distance 8:end if 9:end for 10:return similarWord 算法4在实验中同样使用了Spark的RDD离线计算对数据集进行处理。在算法4中,第3行Counter()方法用来统计待处理word里字符出现的次数,distance()方法使用定义2)中的欧式距离,计算两个单词的距离。 在CTB算法基础上,本文引入TCNNB算法对数据集中用户所打标签进行了修正,整个推荐算法的流程如图2所示。 图2 TCNNB算法流程 该算法首先使用算法4 Check_Modify对数据集中用户所打标签进行修正,然后将修正后的的数据进行统计,统计出user_tags,tag_items和user_items等集合,最后使用算法1为用户进行个性化推荐,输出为该用户推荐的物品列表recommend_items。 本文采用的实验平台为PC(Intel(R),CPU i5-7300HQ,RAM 16GB),Windows10家庭中文版操作系统,开发工具为IntelliJ IDEA、JetBrains PyCharm,代码使用Scala语言编写Spark程序处理数据集,Python语言编写推荐算法。 本节首先进行实验数据集介绍和相关实验设计,接着介绍实验中采用的度量标准,最后展示了TCNNB算法与CTB算法的实验结果,并对实验结果进行分析。 本文采用Delicious数据集,Delicious是UGC标签推荐系统的开创者,是目前网络上最大的书签类站点。Delicious数据集中包含用户对网页URL的标签记录,其每一行由一个四元组表示,该四元组包括用户ID(userID)、网页URL(bookmark ID)、标签ID(tagID)和时间(包括年、月、日、分、秒)。Delicious数据集的统计信息如表1所示,实验中使用大数据处理框架Spark中wordcount案例的方法对数据集进行处理,统计出最热门的10个标签如表2所示。 表1 Delicious数据集的基本信息 表2 Delicious数据集中最热门的10个标签 为了全面测评本文提出的TCNNB算法在推荐中性能,本文采用交叉验证方法进行相关实验[4]。实验中将数据集随机分为K份,以键值用户和物品进行划分,不包含标签。其中,用户对物品的多个标签记录被分入训练集或测试集,不含分入训练集和测试集交叉情况。随机挑选1份数据集作为测试集,剩下的K-1份作为训练集,总共进行K次测试。通过学习训练集中用户所打标签的数据,预测测试集中用户将会给什么物品打标签。所有测试后,计算K次测试所得的度量指标的平均值,以确保算法验证的可靠性。 本文还将设置不同的K值(K=5,10,20,40,80,160)进行实验,考察K值不同情况下,本文算法在度量指标上的性能,实验步骤设计如图3所示。 图3 实验设计流程图 在推荐系统中,通常给用户一个个性化的推荐列表,这个推荐列表是推荐对象根据推荐算法排序的前N个推荐对象,这种推荐即Top N推荐,本文将使用此方法。本文采用召回率(Recall)和准确率(Precision)评测推荐系统推荐算法的精度[4]。 召回率的计算公式定义为 准确率的计算公式定义为 其中,R(u)表示为用户u推荐的长度为N的物品列表,R(u)包括了推荐算法预测用户会打标签的物品。T(u)表示测试集中用户u实际打过标签的物品集合。 本文还采用覆盖率(Coverage)全面测评UGC标签推荐系统的性能。覆盖率是测评推荐系统发觉物品长尾的能力[4]。覆盖率有不同的定义方法,本文采用最常用的方法,即推荐系统能够推荐出来的网页URL集合占总网页URL集合的比例。其中,U表示用户集合,R(u)表示推荐系统为用户u推荐长度为N的网页URL列表,覆盖率计算公式定义为 本节主要展示了在Delicious数据集上分别使用TCNNB和CTB算法基于标签的推荐系统的实验结果,对度量标准的各项指标结果进行比较。表3和表4分给出了两种算法在Delicious数据集上实验的各项度量标准的测评结果。 表3 CTB算法的实验结果 表4 TCNNB算法的实验结果 根据表3和表4,我们可得出如下实验结论:1)推荐结果的精准度(召回率和准确率)和K不成正相关或者负相关,K取较小值时,精准率随着K增大而增大,精准率会达到一个峰值,随后,随K值增大,精准率会随之减小;2)K增加会降低覆盖率。 推荐算法的精准率(召回率和准确率)在不同K值下,两种算法的实验结果对比分别如图4和图5所示。 图4 两种算法下的召回率 图5 两种算法下的准确率 从图4和图5可以看出,在不同K值下,本文提出的TCNNB算法在召回率和准确率上都明显高于原有的CTB算法,其原因在于TCNNB算法修正了用户可能拼写错误的标签,去除掉随意性的标签,修改为与其最相似的标签,进而提高了个性化推荐的召回率和准确率。从图4和图5中发现,召回率和准确率的变化趋势相似。TCNNB相对于CTB算法,召回率和准确率改进的增幅随着K值增加而随之增大,这是因为K值越大,训练集占数据集比例越高,经过TCNNB算法修正的标签比例也越高,测试集的推荐结果也更加精准。 推荐算法的覆盖率在不同K值下,两种算法的实验结果对比如图6所示。 图6 两种算法下的覆盖率 从图6可以看出,在不同K值下TCNNB算法的推荐结果的覆盖率都比原有的CTB算法要差。这是因为对数据集中用户所打标签进行修正,去除了一些生僻词汇的标签,改用了一些出现次数较多且相似的标签,这些标签很大一部分是为那些不流行的网页URL所打。因此,提出的TCNNB算法在覆盖率这一指标上会略微有所降低。 在基于标签的推荐系统中,为了更加精确地为用户个性化推荐物品,必须提高用户所打标签的质量,本文提出了一种基于最近邻的标签修正推荐算法,对用户所打标签的拼写错误,进行了有效的修正,提高了推荐结果的精确率(召回率和准确率)这个关键指标,达到了提高个性化推荐性能的效果。在Delicious数据集上的实验表明,本文算法能够在一定程度上达到提高标签质量的目的,推荐系统的推荐效果明显提高。 本文重点考虑了拼写错误的标签对推荐结果的影响,其他问题,如:修正海量的用户标签,需要搭建Spark等大数据框架进行处理,以及因词根不同,但意思相同的同义词对推荐结果的影响,将在今后的工作中进一步开展研究。3.3 基于TCNNB算法的推荐流程

4 实验结果与分析
4.1 数据集


4.2 实验设计

4.3 度量标准



4.4 实验结果与分析



5 结语
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31
快乐语文(2021年35期)2022-01-18
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
小天使·二年级语数英综合(2017年3期)2017-04-01
旅游纵览(2015年8期)2015-09-25
小天使·一年级语数英综合(2015年8期)2015-07-06
