
基于优化聚类的IXGBoost短期电力负荷预测*
2020-06-18 09:07任利强张立民王海鹏
计算机与数字工程 2020年4期
任利强 张立民 王海鹏 郭 强
(海军航空大学信息融合研究所 烟台 264001)
1 引言
短期负荷预测(short-term load forecasting,STLF)是电力系统负荷预测的重要组成部分,也是智能电网建设的基本环节之一[1]。STLF的主要应用是为机组组合和经济调度提供负荷预测[2]。例如,如果预先知道负荷需求,便可以用尽可能低的成本运行发电机,从而提高发电厂的经济效益。STLF的第二个应用是电力系统的安全评估。此外,短期负荷预测结果有助于实现节能减排和环境保护的目标。
目前,STLF方法可分为经典方法、人工智能方法和机器学习方法三类。经典预测方法基于数学模型,包括时间序列方法、回归分析方法等[3],经典预测法是一种简单的线性方法,对于具有非线性特性的电力负荷预测精度不够。人工智能方法主要有神经网络、极限学习机等,文献[4]提出一种利用主成分分析法简化BP神经网络结构的短期电力负荷预测方法,该方法具有较快的学习速度。机器学习方法主要有支持向量机、随机森林等,文献[5]提出一种利用小波变异果蝇算法优化支持向量机模型参数的短期负荷预测方法,预测精度得到了明显提高;文献[6]基于Spark平台对随机森林算法进行并行化处理,该算法在短期电力负荷预测时间上具有明显的优势,但无法保证预测的精度。随着智能电网的发展,电网中可获取的数据类型和数据量迅速增涨。上述方法在处理大规模、复杂多样的数据时不能兼顾预测速度和精度,具有一定的局限性。近年来,新提出的极限梯度提升(XGBoost)机器学习算法计算速度快、准确性高。目前,在生物医学工程和经济金融等领域都有良好的性能[7~8]。文献[9]使用XGBoost算法建立短期电力负荷预测模型,预测精度和速度均有明显地提高。然而,该文献未考虑实际应用对象,直接将XGBoost算法应用于短期电力负荷预测,且对负荷样本集的预处理工作研究较少,预测精度有待进一步提高。
针对上述问题,提出一种基于优化K-means聚类的改进XGBoost短期电力负荷预测方法。采用改进模拟退火遗传(Improved Simulated Annealing and Genetic Algorithm,IGASA)算 法 优 化 的K-means算法对电力负荷样本进行分类,并利用改进的XGBoost(Improved Extreme Gradient Boosting,IXGBoost)算法对不同类别的负荷样本建立短期电力负荷组合预测模型。使用某市实测电力负荷数据进行负荷预测实验,以检验本文方法的有效性和准确性。
2 基于IGASA优化的K-m eans聚类
相似属性因素下负荷曲线具有相似性,为了进一步提高负荷预测的准确性,利用K-means算法对电力负荷样本进行聚类分析。由于K-means算法随机地选择初始聚类中心,容易陷入局部最优解,影响聚类质量[10]。因此,采用IGASA算法搜索K-means的全局最优初始聚类中心点。
2.1 K-means聚类算法原理
K-means算法根据聚类的个数c随机地选择c个样本点作为初始聚类中心,通过计算剩余样本和聚类中心的距离,将样本划分到距离其最近的类中,之后根据聚类的结果更新聚类的中心点[12]。
K-means的目标函数定义如下:

式中,xi是第i个样本点,cj是第j个聚类的中心,d(xi,cj)是样本点xi到其聚类中心cj的距离。
聚类中心的计算公式为

式中,c*j是更新后的第j个聚类的中心,nj是第j个聚类中的样本数。
K-means算法通过不断地迭代计算d(xi,cj)和cj,使得目标函数值趋向于最小。
2.2 IGASA优化K-means聚类算法设计
遗传算法(Genetic Algorithm,GA)是一种结合生物进化与随机交换理论的自适应搜索全局最优解的群体智能优化算法[12]。模拟退火(Simulated Annealing,SA)是一种通过模拟高温物体退火过程,并利用Metropolis接受准则避免算法陷入局部最优陷阱的优化算法[13]。GA具有全局搜索能力强的特点,但其局部搜索能力弱,易于陷入局部最优解;SA局部搜索能力强,能够避免陷入局部最优的解,但其全局搜索能力差[14]。IGASA方法结合了GA和SA各自的优势,不仅可以克服遗传算法易于陷入局部最优的缺点,而且能加快算法收敛到全局最优解的时间。
2.2.1 算法步骤
IGASA优化K-means聚类中心算法具体步骤如下。
1)初始化参数。
假设将m维负荷样本聚类为c类,首先初始化种群大小为n=10,种群中个体染色体的长度为c×m,设置最大进化的代数gmax=100,退火温度T0=100,终止温度Tend=1,冷却系数α=0.95。
2)定义适应度函数。
随机产生c个聚类中心并生成初始种群,计算种群中个体的适应度值,其中,适应度函数定义如下:

式中,J为式(1)定义的K-means聚类算法的目标函数,Jmax为算法定义的目标函数最大值,T为当前温度。
该适应度函数可使种群中个体之间的差异(适应度值的差异)随退火温度的减小而降低,从而增加温度降低时选择适应度较小个体的概率,确保了种群中个体的多样性,有效地提高了算法从局部最优中跳出的能力。
3)初始化进化代数g=1。
4)通过选择、交叉和变异操作,更新个体的染色体。
使用轮盘选择方式对个体进行选择,将适应度高的个体保留,适应度低的个体丢弃,使种群进化向适应度高的方向发展[15]。随机地对选择的个体进行组队,以式(4)定义的交叉概率Pc对个体进行自适应的交叉操作,接着以式(5)定义的变异概率Pm对个体进行自适应的变异操作。

式(4)和式(5)中,fmax和favg分别是群体中的最大适应度值和平均适应度值,f′是交叉时较大适应度个体的适应度值。
上述自适应交叉变异策略可使Pc和Pm随着适应度值的变化而变化,即适应度值较高的个体具有较低的Pc和Pm,从而将该个体得以保留,而适应度值较低的个体具有较高的Pc和Pm。该自适应方法确保了GA算法的收敛特性和种群的多样性。
5)生成新的种群,计算新种群中子代个体适应度值。
6)对新种群的个体进行模拟退火操作。若新种群子代中第i个个体适应度值fi′大于父代中第i个个体的适应度值fi,则用子代个体替换父代个体;否则,以Metropolis规则,即式(6)定义的概率P接受子代个体,丢弃旧的个体。

7)循环。若g<gmax,则g=g+1,转到步骤4);否则,转到步骤8)。
8)若Ti<Tend,则算法结束,输出全局最优解;否则,进行降温处理,Ti+1=αTi,转到步骤3),α为冷却系数。
2.2.2 算法流程
IGASA优化K-means聚类中心算法详细流程如图1所示。
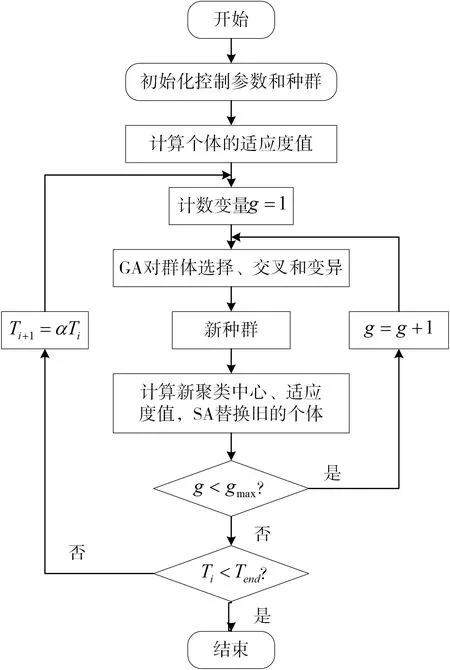
图1 基于IGASA优化K-means聚类算法流程图
3 优化XGBoost电力负荷预测
3.1 IXGBoost算法
XGBoost(extreme gradient boosting)是一种基于梯度提升回归树的改进算法[16]。该算法不仅具有传统Boosting算法精度高的优点,而且能够高效地处理稀疏数据,灵活地实现分布式并行计算。因此,XGBoost算法适用于大规模数据集。此外,XGBoost在损失函数中加入了正则项,用以控制模型的复杂度和降低模型的方差,使学习到的模型更简单,防止了过度拟合风险。XGBoost在确保一定计算速度的情况下提高了算法精度。
XGBoost算法通过建立一系列决策树并为每个叶节点分配一个量化权重来实现对目标变量的估计。对于具有n个样本和m个特征的给定数据集,假设XGBoost模型有K个决策树,则电力负荷预测模型为


式中,q(xi)表示将xi映射到对应叶子节点的第k个决策树的结构函数,ω是叶子结点的量化权重向量(即叶子分数),T是树中叶子节点的数量。
XGBoost算法在损失函数中加入正则化项,同时考虑了模型的准确性和复杂性。通过最小化公式(9)的损失函数来学习预测模型。

考虑到电网短期负荷变化特点和负荷预测中极值点预测误差较大,可以用极大和极小值负荷来修正负荷的预测值。具体而言,根据电网负荷需求特点,当前负荷需求与前一天的负荷需求具有极大相似性和继承性,此外,前一天负荷需求的极大与极小值对当前负荷的预测具有指导作用。因此,本文在XGBoost原有损失函数的基础上引入式(10)惩罚函数,构建改进XGBoost(improved extreme gradientboosting)电力负荷预测模型:

式中,yi,min和yi,max是负荷对应的前一天的极大和极小值负荷,α1和α2是调节惩罚函数效应的系数。根据式(11),如果,的值小于1。此外,通过适当地调整参数α1和α2,当在区间(yi,min,yi,max)内,p的值可以被忽略。在区间(yi,min,yi,max)外时,p变得非常大。在此,设置α1和α2的值分别为2和0.0001。
IXGBoost算法通过最小化式(11)增加惩罚项的损失函数来学习负荷预测模型。

基于上述IXGBoost算法训练短期电力负荷预测模型。
3.2 构建IXGBoost电力负荷预测模型
采用IXGBoost算法进行短期负荷预测,具体流程如图2所示。
具体步骤如下。
1)数据采集及预处理。电力负荷受历史负荷、气象因素、日期类型等多种因素影响。本文采集历史负荷因素,包括前一天负荷、前一天负荷极值;气象因素,包括湿度、温度、风速、降雨量、气压;日期类型因素,包括小时、星期、月份、节假日等数据集进行负荷预测。根据文献[17],历史负荷和气象因素具有持续性效应,选择与这些因素较相关的前四个时刻值以及日期类型,总计32维电力负荷属性特征进行负荷预测。
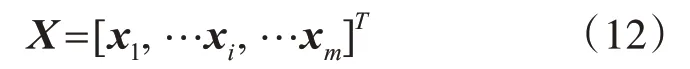
式中,X是电力负荷属性特征集;xi是第i个属性特征矩阵;m=32是属性特征的数量。
为了避免由于数据采集误差、设备的故障和干扰噪声等因素引起的样本数据缺失或者异常,在预测前对数据集进行预处理[18]。本文利用最近临插补法对采集到的原始数据集中缺失和异常的数据点进行填补和纠正。
由于各属性的物理单位不同,不同属性的数值相差较大,影响预测结果的精度。因此,对数据集进行如下归一化处理:

式中,xi为原始数据;x′为归一化后的数据,其取值范围是[0,1]。
2)特征选择。负荷预测中使用过多的特征变量会增加模型的复杂度和训练时间,从而影响预测结果的准确性。因此,参考文献[19]使用最大相关最小冗余(maximum relevance minimum redundancy,MRMR)算法对步骤1)采集到的负荷属性特征进行选择,以减少数据中的冗余信息,提高预测精度。
3)负荷样本聚类。根据第二节,利用IGASA优化的K-means聚类算法对负荷样本进行聚类分析,将相似特征属性的负荷样本划分为一类。
4)建立IXGBoost负荷预测模型。采用IXGBoost算法对每个类别的电力负荷样本集建立负荷预测模型,得到组合预测模型。
5)负荷预测结果反归一化处理。根据式(14)对该预测结果进行反归一化处理:
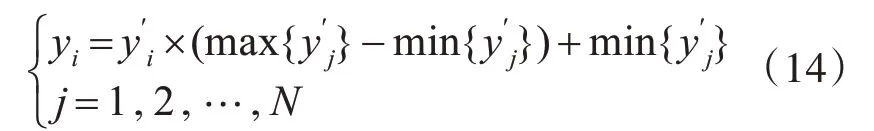
式中,y′i是i时刻的预测值;yi是i时刻反归一化的预测值;N是预测样本数量。

图2 短期电力负荷预测流程图
4 算例分析
本文数据集来源于某市2013-2017年实测电力负荷数据和相应时间的气象数据,数据的采样间隔为1小时。实验选取2013年至2016年数据为训练集,对35012个样本进行分析,建立电力负荷预测模型,对应预测模型每次输出未来一天24小时的负荷值。选取2017年数据为测试集,以测试模型的预测性能。本文经特征选择后的输入变量如表1所示。

表1 输入变量描述
4.1 评价指标
采用平均绝对百分比误差(MAPE)和平均绝对误差(MAE)作为误差评估标准来分析预测结果的准确性。

式中,Yi表示真实值,表示预测值,n为预测时间点数。MAPE越小,预测结果越准确。
4.2 实验结果与分析
采用交叉验证算法确定K-means算法的聚类个数c=4,利用IGASA优化的K-means算法对训练样本进行聚类分析,聚类划分结果如表2所示。
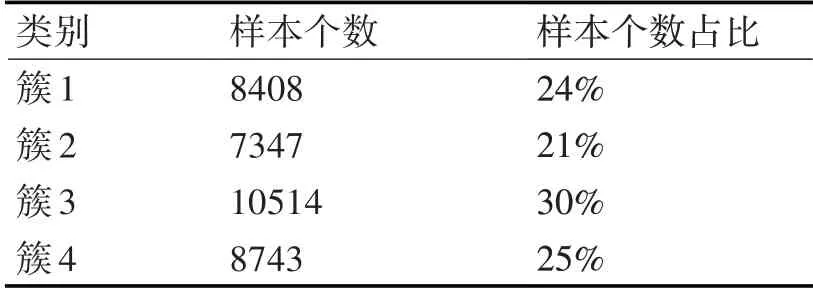
表2 聚类结果
为了测试IXGBoost模型的预测效果,在相同实验条件下,采用梯度提升回归树(GBRT)模型和传统XGBoost模型作为对比进行电力负荷预测,选取该市2017年2个具有代表性的日期进行实验分析。图3显示了上述各模型的负荷预测结果。
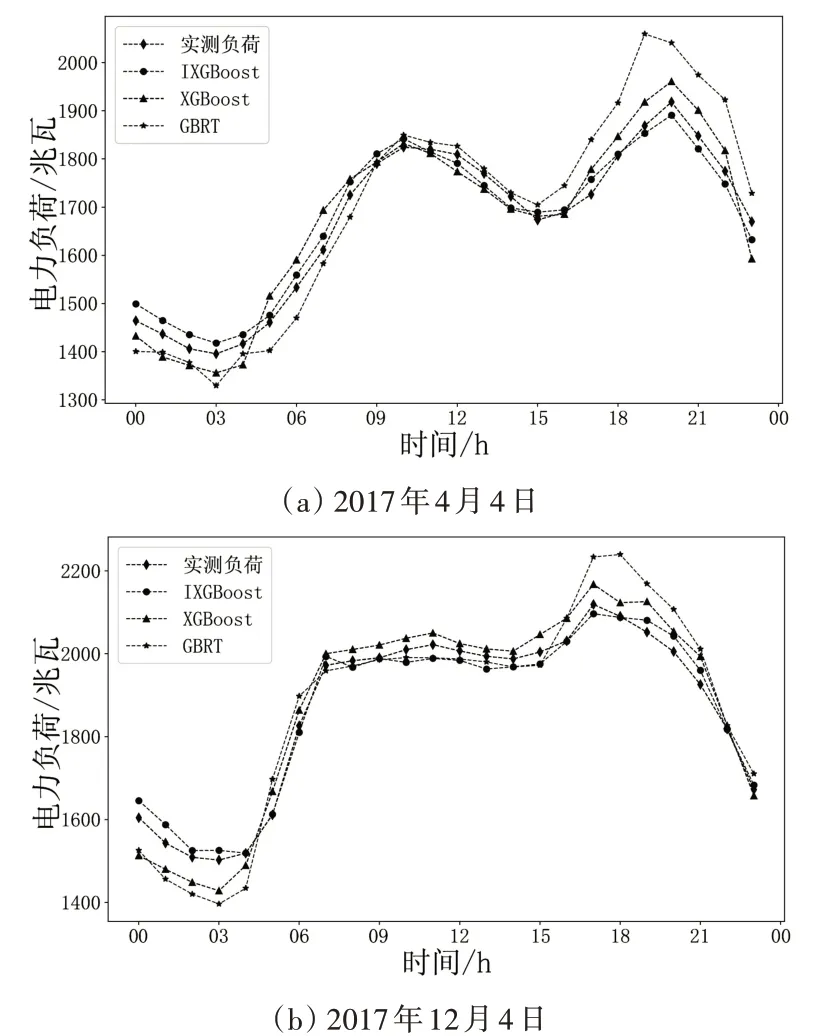
图3 不同模型预测结果对比
从图3可观察到,当电力负荷的变化较平缓时,如图3(a)的09:00-14:00与图3(b)中的07:00-14:00,三种模型的预测曲线和实际负荷曲线较为接近。然而,在电力负荷波动较大的极值点附近,如图3(a)的16:00-22:00与图3(b)中的0:00-06:00、16:00-21:00,GBRT和XGBoost模型的负荷预测值与实际负荷值相差较大,而IXGBoost模型的预测结果更接近实际负荷值。
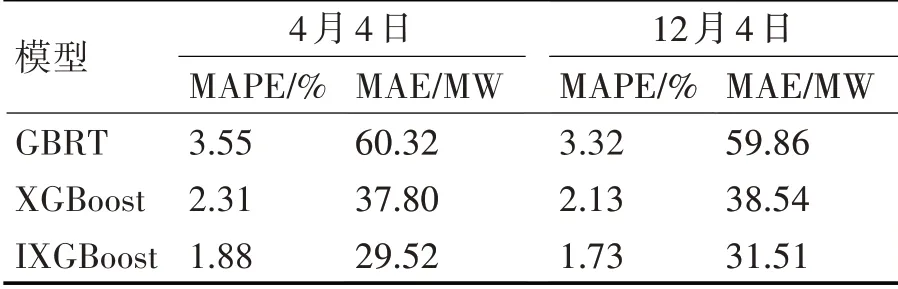
表3 不同模型预测结果误差对比
表3显示了上述各模型的预测误差,从对比结果可以看出,与GBRT模型相比,XGBoost模型具有较小的预测误差。IXGBoost在传统XGBoost损失函数中加入惩罚项,提高了模型在负荷波动较大的极值点附近的预测性能。预测误差结果表明,与XGBoost和GBRT模型相比,IXGBoost模型具有较高的预测精度。
分别采用聚类IXGBoost(KM+IXGBoost,方法1)、GA优化聚类IXGBoost(GA+KM+IXGBoost,方法2)和IGASA优化聚类IXGBoost(IGASA+KM+IXGBoost,方法3)进行电力负荷预测。上述三种法方法预测结果的曲线如图4所示,预测结果的误差见表4。

图4 不同预测模型结果对比
从图4可看出,在电力负荷变化不明显期间,如图4(a)的09:00-13:00与图4(b)的07:00-15:00,三种方法负荷预测结果都可以较好地拟合实测负荷的变化趋势。但在电力负荷变化比较剧烈的时期,如图4(a)的15:00-21:00与图4(b)中的16:00-21:00,方法3比方法1和方法2具有更好的预测性能。此外,从图4与表4能够看出,方法2的负荷预测准确度高于方法1。这是因为与方法2相比,方法1随机地选择K-means的初始聚类中心。方法3相较于方法2不仅改进了遗传算法的适应度函数和交叉变异算子,而且引入模拟退火算法克服了遗传算法易陷入局部最优的缺点,使算法快速收敛到全局最优解。实际预测结果表明方法3具有较低的预测误差。

表4 不同模型预测结果误差对比
利用方法3预测该市2017年小时用电负荷(以12月为例),结果如图5所示。对2017全年电力负荷预测误差进一步分析,MAPE为1.93%,MAE为34.13MW,结果表明本文提出的方法可以有效、准确地预测短期电力负荷的变化规律,能满足实际应用需求。

图5 12月份电力负荷预测值与实测值对比
5 结语
本文以电网实测大数据为基础,提出一种基于优化K-means聚类的IXGBoost短期电力负荷预测方法。该方法采用改进适应度函数和交叉变异算子的模拟退火算法优化K-means的初始聚类中心,有效解决了遗传算法局部寻优的问题,使算法快速收敛到K-means全局最优初始聚类中心。基于K-means聚类结果,利用改进XGBoost算法建立电力负荷组合预测模型,并根据不同的属性特征使用不同的预测模型,提高了电力负荷预测模型的准确度。实验结果证明了本文方法在短期电力负荷预测实际应用中的有效性和准确性。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
北京航空航天大学学报(2022年8期)2022-08-31
纺织标准与质量(2022年2期)2022-07-12
煤气与热力(2022年4期)2022-05-23
南京理工大学学报(2022年1期)2022-03-17
煤气与热力(2022年2期)2022-03-09
计算机应用与软件(2021年7期)2021-07-16
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
小资CHIC!ELEGANCE(2019年5期)2019-04-30
当代旅游(2016年10期)2017-04-17
