
基于Mask-RCNN的服装识别与分割
2020-06-24 12:59张泽堃张海波
纺织科技进展 2020年6期
张泽堃,张海波
(1.北京服装学院 信息中心,北京100029;2.北京服装学院 服装材料研究开发与评价北京市重点实验室 北京市纺织纳米纤维工程技术研究中心,北京100029;3.北京服装学院 图书馆,北京100029)
根据中国服装协会发布的《2018-2019年度中国服装行业发展报告》[1]显示,2018年全年限额以上服装品类零售额实现7 742.8亿,累计增长9.1%,增速较2017年提高了1.1%,网上销售增长了22%,大型零售增长0.99%。2018年全年服装行业规模以上企业主营业务收入17 106.57亿。服装行业发展迅速,计算机行业进军服装领域,如何理解、区分和识别不同的服装图像,以及如何处理海量的服装图像,并从中提取出有用的信息成为当前的研究热点。除了电商的以图搜物外,服装的智能搭配和服装定制都用到了服装的图像识别与分割。目前网购服装的检索主要以文字检索为主,但随着服装数量剧增,服装款式变化多样,传统的图像处理已无法满足当前快速、智能准确的要求,而这也使得计算机在服装图像的处理上遇到了瓶颈。
从最初的人工标注到使用卷积神经网络来训练模型,期间出现了很多图像识别和分割的算法。早期的识别方法有静态图像中的分割、边缘提取、运动检测等,如局部模板方法、光流检测法等,这些方法速度较慢,识别率较低,误报率也高。随着深度学习[2]的不断发展,深层卷积神经网络在图像的处理上更加针对服装图像的特征,具有独特的优势。Kim[3]等为了识别摄像机拍摄的灰度图像中的任务,使用边缘提取的方法提取服装图像的纹理特征,计算欧几里得距离来判定特征向量之间的相似性。只使用服装边缘的直方图特征向量,并不适用于图像缩放、旋转、扭曲等形变。Hidayati[4]等提出了一种基于视觉差异化风格元素的服装风格自动分类方法,而不用低层次特征或模糊关键词来识别服装风格,基于服装设计理论,确定了一组对识别服装风格的特定视觉风格至关重要的风格元素,将服装风格元素归一化为上身的特征向量和下身的特征向量,通过一个判别函数来判断输入特征向量到类别标签的映射关系,利用判别函数来确定服装的类型。Liu[5]等设计了用于服装图像分类检测的Fashion Net,提出了Deep Fashion数据集,这是一个具有全面注释的大型服装数据集。Luo[6]等研究了频场景中识别服装的相关技术,在Image Net数据集上预训练GoogleNet模型,并根据服装本身的特点对网络进行微调,以完成服装的检索任务。
根据现有研究,目前使用较多的检测算法有RCNN、Fast R-CNN、Faster R-CNN 和 Mask-RCNN,检测结果的准确性和速度不断提高,但是缺点是需要大量的训练数据。Mask-RCNN[7]是目前最新的实例分割架构,引入了RoI Align,增加了一个分支用于分割任务,在时间上有一定的优化。而且Deep Fashion2数据集在Deep Fashion数据集的基础上进行了优化。
本文基于Mask-RCNN和Deep Fashion2的服装识别与分割,对传统深度学习目标检测算法的训练数据和特征提取器做了调整,使得模型更加适用于服装识别和服装分割,得到的结果更加准确。
1 DeepFashion2数据集
1.1 Deep Fashion2数据集概况
近年来,时尚产业愈发火爆,时尚服装图像分析成为了热点。现有最大的时尚数据集Deep Fashion存在标记较为稀疏,没有定义服装姿态,没有对每个像素进行掩膜标注的缺点。为了解决上述缺陷,提出了Deep Fashion2[8],它是一个大规模的基准集,能全面的进行服装分类和服装图像的标注,包含49.1万张时装图像,图片可分为13种流行的服饰类别。Deep-Fashion2定义了相对全面的任务,包括服装的检测和识别,关键点的标记和服装姿态估计,服装分割,服装的验证和检索。所有的服装图像都有丰富的标注。它有81万个服装项目,每个项目都有丰富的注释,其中每件都标有不同的比例、不同大小的遮挡、不同的缩放大小、不一样的视角、精准的边界框、密集的标注和每个像素的掩膜。表1为Deep Fashion2与其他数据集的比较。
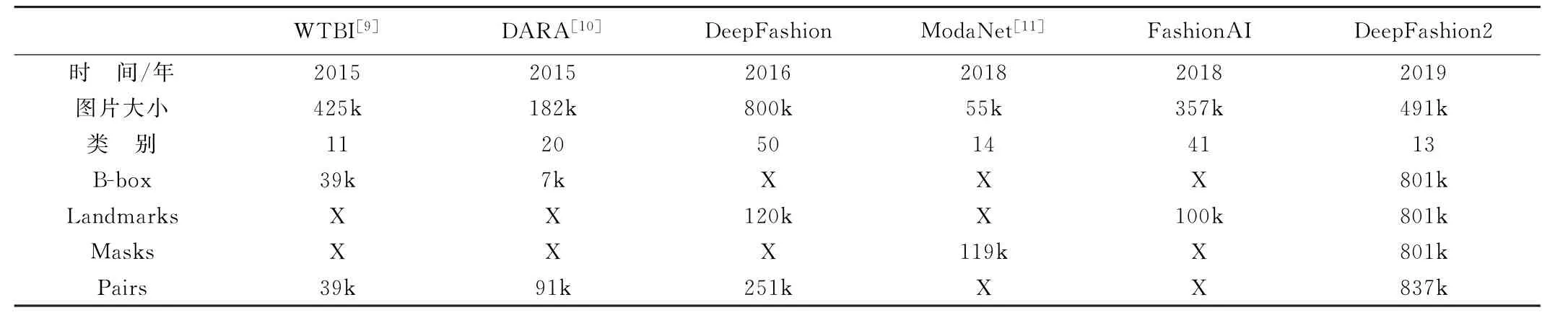
表1 Deep Fashion2与其他数据集的比较
Deep Fashion2的贡献主要有三个:(1)构建了拥有丰富标注的大规模数据集,推动了时尚图像分析的发展。拥有丰富的任务定义和最大数量的服装标签。它的标注至少是Deep Fashion的3.5倍,是Moda Net的6.7倍,是Fashion AI的8倍。(2)在数据集上定义了全部任务,包括服装检测、服装姿态、服装分割与检索。(3)使用Mask-RCNN对数据集进行识别和分割。
1.2 Deep Fashion2数据集和基准
1.2.1 数据标签
(1)类别和边界框。对服装图片进行人工标注,并为每个服装项目指定一个类别标签。通过重新对Deep Fashion的类别进行分组,得到了13个没有歧义的服装类别。
(2)服装标签、轮廓和骨架。由于不同类别的衣服(如上下半身服装)有不同的形变和外观变化,通过捕捉服装的形状和结构将特征点连接。将每类服装进行人工标注,每个特征点都被将指定为“可见”或“遮挡”。然后,将特征点通过一定顺序连接后生成轮廓和骨架,还将标注区分为两种类型,即轮廓点和连接点。以上过程控制了标签的质量,生成的骨架有助于人工重新检查这些标记是否具有较高的识别效率。只有当轮廓覆盖整个项目时,标记的结果才合格,否则将重新确定关键点。
(3)掩膜。使用两个阶段的半自动方式为每个项目标记像素掩膜。第一阶段自动从轮廓生成掩膜。在第二阶段,要求人工重新定义掩膜,因为当呈现复杂的人体姿势时,生成的掩膜可能不准确。例如,当从人腿交叉侧视图拍摄图像时,标记会不准确,这时掩膜需要人工调整,如图1所示。

图1 掩膜出现识别错误时进行人工调整
1.2.2基准
使用Deep Fashion2的图像和标签构建了四个基准。对于每个基准测试,训练集图像39.1万,验证集图像3.4万,测试集图像6.7万。
(1)服装检测。通过识别边界框和类别标签来检测图像中的衣服。根据COCO数据集,评价标准为。
(2)特征点估计。预测每个图像中检测到的每个服装项目的标志。采用COCO用于人体姿态估计的评估指标,通过计算关键点AP pt、AP OKS=0.50pt和AP OKS=0.75pt的平均精度,其中OKS表示目标特征点相似性。
(3)图像分割。将类别标签(包括背景标签)分配给项目中的每个像素。评估指标是平均精度,包括在掩膜上计算的AP mask、AP IoU=0.50mask和AP IoU=0.75mask。
2 Mask-RCNN服装识别
2.1 检测框架设计思路
在检测模型训练阶段,对具有初始参数的卷积神经网络进行迭代训练,并通过Tensorboard来查看训练过程,从而不断修改和优化训练模型的参数,最终得到目标检测模型。在模型测试阶段,将待检测样本输入之前得到的目标检测模型并得到检测结果。主要有检测模型的训练和模型测试两个阶段,如图2所示。

图2 服装识别检测模型框架
目标检测方法的训练包括6个步骤:(1)获取Deep Fashion2数据集源文件;(2)对训练样本进行预处理,将Deep Fashion2中的json文件转换成dataset备用;(3)将dataset输入到Res Net中,得到对应训练服图像的特征图,对特征图中的每一点设定预定的RoI,得到多个候选RoI;(4)将候选的RoI送入RPN进行二分类(输出为前景或背景)和BB(bounding box)回归,过滤掉一部分候选的RoI,对剩下的RoI进行RoIAlign操作;(5)将得到的RoI进行N类别分类、BB回归和MASK生成;(6)重复步骤4和步骤5,训练完所有的服装样本后得到最终的检测模型。
服装检测的方法包括两个步骤:(1)利用测试的服装样本对检测模型进行测试,最终得到新样本的检测结果。(2)测试结果不符合要求时重新进行模型的调整与参数训练,并且重新训练模型,若测试结果符合要求,则得到最终的目标检测模型。
2.2 Mask-RCNN简介与原理
Mask-RCNN是何凯明等人在Faster R-CNN[12]基础上提出的目标实例分割模型。该模型能够有效地检测图像中的目标并为每个实例生成高质量的分割掩码。如图3所示,该模型通过在Faster R-CNN已存在的B-box识别分支旁并行地添加了一个用于预测目标掩码的分支。掩码分支是一个应用到每个RoI上的小型FCN(全卷积网络),能够预测RoI中每个像素所属的类别,从而实现准确的实例分割。
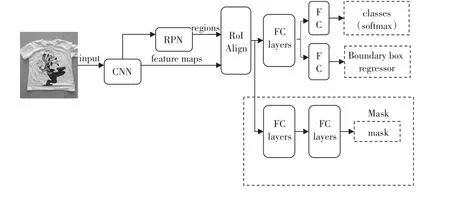
图3 Mask-RCNN结构图
Mask-RCNN的技术要点主要有三个:(1)使用Res Net+FPN来提取图像特征。(2)使用RoIAlign替代RoIPooling,引入了一个插值过程,先通过双线性插值到14×14,再pooling到7×7,解决了仅通过Pooling直接采样带来的Misalignment对齐问题。(3)每个RoIAlign对应k×m2维度的输出。k对应类别个数,即输出k个掩膜,m对应池化分辨率7×7。
2.3 RoI Align操作
RoI Align是取消量化操作和整数化操作,并保留小数,使用双线性内插的方法获得坐标为浮点数的图像数值,将整个特征聚集过程转化为一个具有连续性的操作。RoI Align不是简单的补充出候选区域边界上的坐标点,然后进行池化,而是重新设计。图4中虚线框表示的是5×5的特征图。虚线部分表示的是feature map,实线表示RoI,如图4所示将RoI切分成4个2×2的单元格,之后在每个实线的方形区域中选择4个采样点,除了这4个点还选取离该采样点最近的4个特征点,如图4中黑色小方格的4个顶点,并且通过双线性插值的方法得到每个采样点的像素值;最后计算每个小区域的像素值,并生成2×2的特征图。

图4 RoI Align原理
2.4 FPN(特征金字塔网络)
FPN的提出是为了实现更好的feature maps融合,FPN采用了自上而下的侧向连接来融合不同尺度的特征,使用3×3的卷积来消除混叠现象,来预测不同尺度的特征,不断重复以上的过程,最终得到最佳分辨率。FPN的优点在于,它可以在不增加计算量的情况下提高多个尺度上小物体的准确性和快速检测能力。图5为特征融合原理图。左边的底层特征层通过1×1的卷积得到与上一层特征层相同的通道数;上层的特征层通过上采样得到与下一层特征层一样的长和宽再进行相加,从而得到了一个融合好的新的特征层。
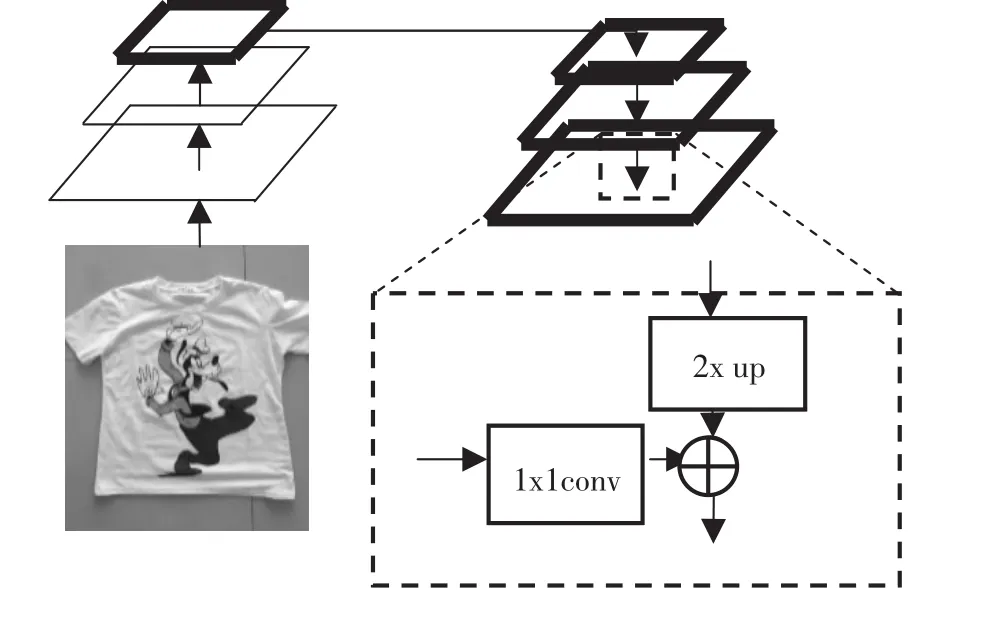
图5 特征融合原理图
2.5 Loss Function
Mask-RCNN的损失函数为:
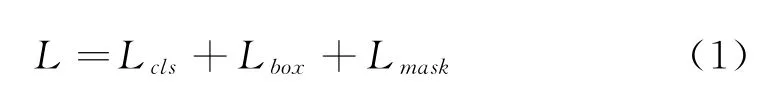
式中L cls和L box与Fast RCNN中定义的分类和回归损失相一致,mask分支对于每一个RoI都有k×m2维度的输出,k个分辨率为m×m的二值mask。L mask为平均二值交叉熵损失。对于一个属于第k个类别的RoI,L mask仅仅考虑第k个mask。
3 试验部分
3.1 深度学习框架与预训练模型的选取
目前深度学习的学习框架有很多,深度学习的模型需要大量时间和海量训练样本进行训练,在考虑到硬件水平的前提下,试验使用COCO 2014数据集作为预训练模型。COCO 2014数据集拥有9 000多张图片,包含了自然图片和生活中常见的物品图片,也有较多的服装图像,因此试验采用迁移学习方法将COCO 2014数据集训练得到的权重模型作为服装检测算法模型的预训练模型,在此预训练模型的基础上使用Deep Fashion2作为训练集再进行样本训练,通过迁移学习的方式不但可提升训练效率,而且能有效地提升检测模型的整体检测精度和模型性能。
3.2 数据集的处理
由于Deep Fashion2已经得到了各图片的json文件,故不需要再使用Lebel Me进行手动标注,只需将json文件转换为dataset即可。试验在Ubuntu18.04、CUDA9.0环境下进行。试验参数设置如下:初始学习率0.000 01,每迭代2 000次缩小10倍。为了使训练效果和模型性能更好,选取服装图片有不同遮挡、不同缩放和不同姿态。
3.3 试验结果与分析
得到训练模型后,使用测试代码进行测试,得到的测试效果如图6所示。

图6 测试效果
试验选取了不同服装姿态的图片,其中矩形框表示检测服装的位置,矩形框上的数字表示的是属于不同服装类别的概率大小。为了提高检测的准确率,将模型中的矩形框概率的阈值设置为0.7。一方面减少了网络中确定服装图像边框的计算量,提升计算速度。另一方面防止发生过拟合。经过测试,把NMS(non maximum suppression)在RPN网络的预测阶段在proposal layer的阈值设定为0.7时,试验结果较好,被标注的服装识别概率均高于0.764。
试验中也存在识别失败的例子,如图7所示。原因可能是服装占比较大或较小、形变较明显、放大不正规和有较大的遮挡等。
由于服装本身的易形变和拍照的角度问题,总体上Mask-RCNN识别率较高,达到了预期的效果。为了提高识别准确率,可以将训练集的数据进行筛选。也可以增加训练集数量来提高训练模型的性能。

图7 服装识别失败例子
4 结语
基于Mask-RCNN和Deep Fashion2的服装检测模型可以更好的识别和分割服装,更好地促进服装识别算法的发展,更好地理解时尚图像。通过使用Mask-RCNN对Deep Fashion2数据集进行测试,得到较为精确的结果,可以通过分割得到的服装进行智能搭配等。这为探索服装形象的多领域学习提供了基础,也为以后进一步优化服装提取算法提供了借鉴。同时,在Deep Fashion2中引入更多的评估指标,例如深度模型的大小、运行时间和内存消耗,可解释现实场景中的时尚图像。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
陶瓷学报(2021年4期)2021-10-14
电子技术与软件工程(2021年5期)2021-06-16
少儿画王(3-6岁)(2020年4期)2020-09-13
证券市场红周刊(2019年44期)2019-11-23
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
电子技术与软件工程(2018年5期)2018-04-09
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
