
基于分块的移动边缘计算密文检索方法
2020-08-02 05:09王娜郑坤付俊松李剑
通信学报 2020年7期
王娜,郑坤,付俊松,李剑
(1.北京邮电大学计算机学院,北京 100876;2.北京邮电大学网络安全学院,北京 100876)
1 引言
随着云计算应用的逐渐普及,越来越多的企业和用户选择将数据存储在云服务器上,云计算极大地方便了数据的存储和使用[1-2],但是随着时代的进步,海量数据带来的通信负担和计算压力使现有的云计算在很大程度上已经不能够满足用户的需求。与此同时,物联网的崛起和5G 时代的到来,带动了移动边缘计算和雾计算的快速发展[3-8]。移动边缘计算和雾计算通过在网络的边缘设置一些边缘服务器,可以实现快速响应用户的需求或是提前进行一部分数据处理来减轻云服务器的通信负担或者计算压力。
移动边缘计算上的密文检索与云计算上的密文检索大体上是相似的,不同之处在于边缘计算环境下,若干个移动边缘服务器分布在网络的边缘,数据使用者选择最近的边缘服务器发送查询请求,由边缘服务器负责计算文档与查询的相关性,将排好序的查询结果返回给云服务器,云服务器再将对应的加密文档发送给用户,这种方式减轻了云服务器的计算压力。同云服务器一样,边缘计算也被认为是半可信的、“诚实而好奇”的实体[5],云服务器上的数据隐私安全问题[9-11]在边缘服务器上同样存在,数据需要在上传给云服务器、边缘服务器之前进行加密,这样一来便限制了数据的使用[12-13],所以寻找一个可以应用于移动边缘计算的密文检索方案是十分有必要的。
2 相关工作
现有的可搜索加密方案大多是基于云计算环境的研究,在移动边缘计算上的方案很少。而边缘计算可以认为是云计算的拓展,所以本文方案主要是与现有的云计算上的可搜索加密方案进行比较。
早些时候,可搜索加密方案集中在单关键词检索的研究[14-16],由于单关键词的搜索结果过于粗糙,用户为了获得更加准确的检索结果,通常会输入多个关键词进行检索,尤其是在云计算的按使用收费机制下,返回高相关性的文档是有必要的,不仅节省了流量,也方便了用户的使用,基于这些原因,支持多关键字排序的密文检索方案陆续被提出。
Cao 等[17]提出了安全的、多关键字可排序的密文检索方案(MRSE,multi-keyword ranked search over encrypted cloud data),该方法基于安全k 最近邻(kNN,k-nearest neighbor)技术[18],利用可逆矩阵来加密索引和查询向量,通过计算查询向量与文档向量的内积得到文档在本次查询下的相似性得分,但该方法对每一个无关的关键词都进行了计算,在检索效率上有改进的空间。Sun 等[19]在此基础上提出了基于多维B 树的索引结构,使用贪婪的深度优先搜索来加快检索效率,但是该方法的检索效率与查询的关键词分布情况有关,当关键词分布在多维B 树的底部时查询效率严重退化,在一定程度上影响了数据使用者的体验。Fu 等[20]提出了基于二叉树的索引结构,该方法自下而上建树,通过中间节点存储辅助向量来标识关键词是否出现,出现为1,未出现则为0,在检索过程中排除不包含查询向量的子树,这种方法过滤掉了不包含查询关键词的文档,只对包含查询关键词的文档计算相关性得分,从而加快查询。Xia 等[21]同样提出了基于二叉树的索引结构,该方法也是自下而上构建索引树,但中间节点存储的是其孩子节点关键词权值的最大值,在检索过程中利用贪婪的深度优先搜索过滤掉文档的最大可能得分小于当前阈值的子树,以此加快检索。这2 种基于二叉树的检索方法没有考虑到文件之间的相似性,叶子节点是随机放置的,因此在检索效率上还有提升的空间。文献[22-24]采用聚类的方法,利用基于k-means的方法自顶向下构建层次聚类索引树,该方法效率较高,但会存在一些检索误差。文献[25-26]采用了两段式的索引结构来提升查询效率,在查询的第一阶段筛选掉无关的文档,在第二阶段计算剩余文档的相关性得分,效率较高,但在第一阶段其检索模式是“半保护的”,会暴露查询陷门的隐私。文献[27-29]引入了布隆过滤器来过滤不包含查询关键词的文档,效率较高,但会有一定的误差。
综上所述,现有的各种检索方案都是从过滤低相关性文档的角度进行改进来提高检索效率,而本文从过滤无关关键词的角度进行改进,提出一种分块的多关键字排序密文检索方案。本文的创新如下。
1) 由于只需要加密和发送包含查询关键词的分块,与其他加密和发送整个字典长度的查询向量方法相比,减少了数据使用者的计算开销和通信开销。
2) 通过分块过滤掉大部分无关的关键词,大幅减少了边缘服务器计算文档相似性得分时的计算量,提升了查询效率。
3) 通过理论分析和仿真实验,证明了所提方法在保证一定安全性的同时提升了查询效率。
3 问题描述
3.1 系统模型
系统模型如图1 所示,各部分功能介绍如下。
1) 云服务器
云服务器存储数据拥有者上传的密文文档集合和对应的加密后的索引,将索引分发给所有的边缘服务器,接收边缘服务器传来的查询结果索引号,将对应的加密文档发送给指定的数据使用者。
2) 边缘服务器
边缘服务器存储云服务器传来的加密后的索引,接收数据使用者传来的查询陷门,利用查询陷门和索引计算出最相关的K个文档索引编号,发送给云服务器。
3) 数据拥有者
数据拥有者拥有明文文档集合F,基于明文文档集合构建可搜索加密索引I,对明文文档加密得到密文文档集合C,将加密后的索引I和密文文档集合C上传的云服务器,负责对数据使用者发放检索密钥和文档解密密钥。
4) 数据使用者
数据使用者从数据拥有者获得密钥,生成查询陷门T,上传查询陷门给边缘服务器,得到云服务器返回的K个文档,利用数据拥有者发来的密钥来解密文档得到想要的明文文档。
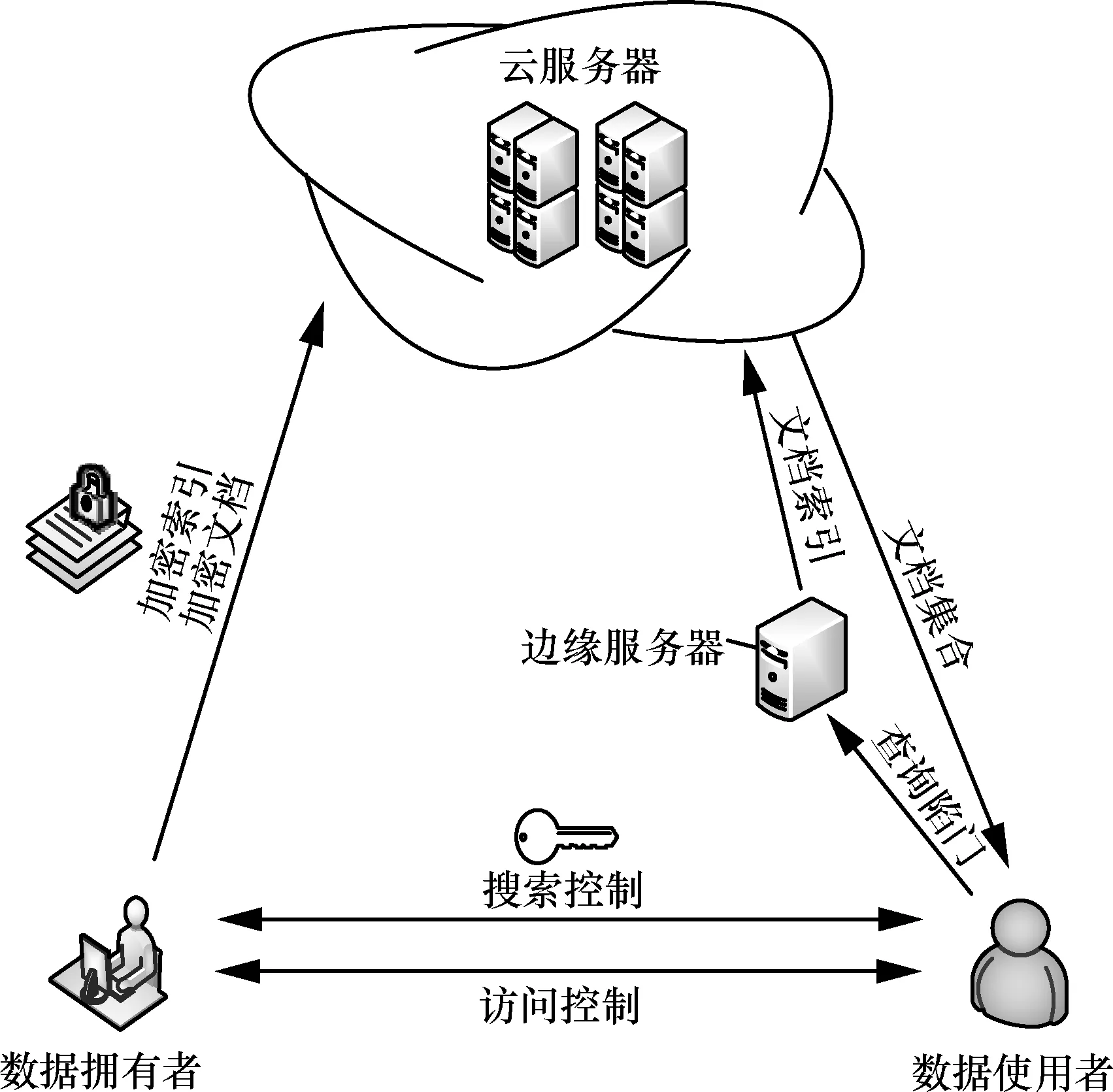
图1 系统模型
3.2 威胁模型
本文假设云服务器和边缘服务器是“诚实而好奇”的:服务器会按照规定执行指定的操作,同时对存储其上的数据和收到的查询是好奇的,会试图根据得到的信息进行推理、分析文档数据和用户的隐私,但不会对数据进行恶意篡改、破坏。
根据云服务器和边缘服务器能够获得的有效信息,本文考虑以下2 种威胁模型。
1) 已知密文模型,云服务器能够获得密文文档集合、密文索引。除此之外,云服务器不知道任何其他信息,云服务器只能发动密文攻击。同样,边缘服务器只能获得加密的查询陷门,不知道其他信息。
2) 已知背景知识模型,在已知密文模型的基础上,边缘服务器还会根据用户的查询请求,统计分析用户查询记录中的隐含信息,结合已有的相关背景知识,试图挖掘出一些其他有用信息,如用户的关键词查询偏好、关键词被使用的频率、文档与关键词之间的关联关系等。
3.3 符号说明
表1 为本文主要符号说明。

表1 主要符号说明
4 预备知识
4.1 TF×IDF
TF×IDF 是一种统计方法,其中TF 是词频,表示关键词出现的频率,TF 值越大,说明关键词在文档中越具有代表性。IDF 是逆文档频率,计算方法是文档总数除以包含该词语的文档数量,再将得到的结果取对数,关键词的IDF 值越大,意味着文档集合中包含该关键词的文档数量越少,该关键词就越具有区分性。
联合使用TF 与IDF,可以避免单独使用TF 导致一些不具有区分性的常用词被赋予过高的权重,又可以避免单独使用IDF 造成生僻词或者噪声词被赋予过高的权重问题。
本文采用被广泛应用的归一化的TF×IDF方法为每个文档中的关键词进行评分,计算式为
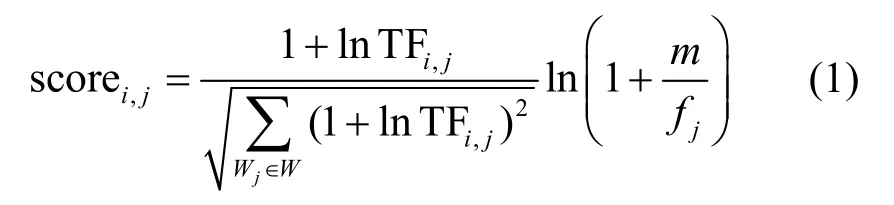
其中,scorei,j和TFi,j分别表示关键词Wj在文档Fi中的相关性得分和词频,fj表示包含关键词Wj的文档数量。
4.2 向量空间模型
向量空间模型(VSM,vector space model)由Salton 等[30]于20 世纪70 年代提出。VSM 利用向量表示文本,把对文本的处理转化为向量空间中的内积运算。VSM 中向量的维度大小等于关键词的长度,每一维度表示一个关键词。VSM 中每个项的值表示关键词在文档中的权重。
通过VSM,2 个文件的相似度可以利用这3 个文件的向量夹角来衡量,夹角越小,相似度越高。查询请求可以看作一个文档,根据查询的关键词生成一个与向量空间维数相同的向量,通过比较查询请求与所有文档的相似度得到文档与查询的相似性得分,从而按照需求得到与查询最相关的若干个文档。对于查询来说,除了通过比较向量的夹角偏差程度来计算相关程度外,还可以通过计算向量内积来计算每个文档与关键词的相似性得分。有了上述的向量空间模型,文本数据就转换成了计算机可以处理的结构化数据,文档与查询关键词之间的相关性得分就转换成了2 个向量的内积结果。
本文使用了文献[17]中的应用于向量空间模型的基于安全kNN 技术[18]的安全内积计算方案。这个技术可以使边缘服务器通过加密的索引和加密的查询陷门计算出陷门与每个文档的明文相关性分数,有效地保护了服务器上索引和查询的隐私。
5 本文方案
5.1 初始化
数据拥有者遍历明文文档集合F中的所有文档,提取所有关键词,去掉停用词后得到关键词字典W,长度为n。数据拥有者随机生成一个长度为n+2、由0 和1 组成的向量S作为分裂指示器,再生成两组可逆矩阵,每组前vh-1个矩阵大小为第vh个矩阵大小为,最终生成的密钥为
5.2 构建索引
数据拥有者为每个文档Fi构建一个长度为n的向量Di,向量的第j位是关键词Wj在这个文档中的TF×IDF 值,然后将向量Di扩展至n+2维得到,其中第n+1位为随机数ε,第n+2位为1,即。接下来,对根据分裂指示器S进行随机分裂得到2 个长度为n+2 的向量和,如果S[j]=0,则使⇀⇀⇀,否则使,然后将按照与密钥相同的方式分割,得到和,并计算其与的乘积,最终得到加密后的索引
图2 展示了构建索引的过程,首先数据拥有者为每个文档生成文档-单词矩阵,然后进行分块操作,得到分块后的文档-单词矩阵,将分块后的矩阵作为索引上传给云服务器,云服务器将收到的索引分发给边缘服务器。

图2 构建索引
5.3 生成查询陷门

图3 是生成查询陷门的过程。数据拥有者首先根据查询关键词生成查询向量,然后对查询向量进行分块,同时生成列表L,将与查询相关的块号加入列表L中。接下来,将分块后的向量加密并连同列表L一起上传到边缘服务器。

图3 生成查询陷门的过程
5.4 查询
数据使用者将陷门上传给边缘服务器,边缘服务器首先根据陷门中的L,找出对应位置的索引块,然后按照式(2)计算所有文档的得分

图4 是边缘服务器上的文档相关性分数计算过程。数据使用者传来的查询请求包括了一组查询向量块和一个列表L,其中L=[1,3]表示本次计算文档相关性分数需要对块1 和块3 进行计算,边缘服务器收到查询请求后,对索引的块1和块3 及对应的查询向量分别计算内积,得到2 个内积结果,再对内积结果求和得到文档的相关性分数。
6 安全性分析
6.1 索引安全
索引安全指的是服务器无法根据加密后的索引推断出文档与关键词之间的关联关系。如果服务器能够获得文档与关键词之间的关系,那么服务器就能够得知文档中的一些信息,如果是短文本,甚至能够推断出整个文本内容[31]。
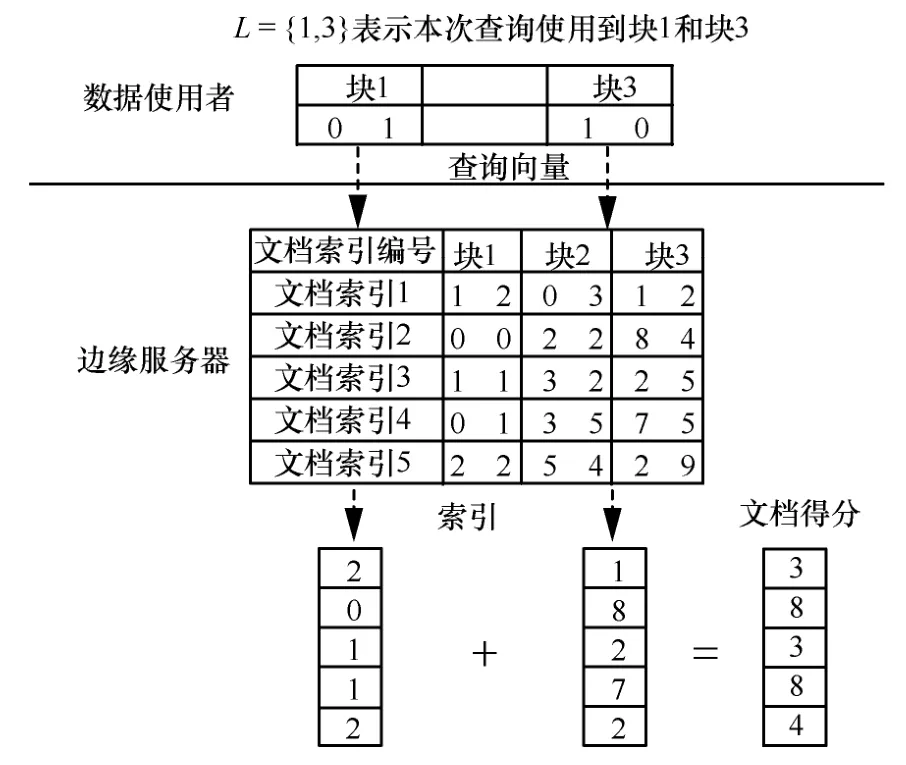
图4 计算文档相关性分数
本文方法中存储在边缘服务器上的索引是2h个加密的矩阵,其密钥是一个长度为n+2 的向量S和2h个矩阵。云服务器在不知道密钥的情况下只能进行穷举攻击,文献[18]中已证明,在对称加密中对称密钥长度超过80 bit 可以认为是安全的。在本文方法中,如果使每个矩阵块的维数为80,则对于每个矩阵块来说都有一个长度为80 的向量和2 个80 ×80 的矩阵作为密钥,由于2 个转换矩阵的存在使维数为80 的矩阵块的破解难度超过了普通的80 bit对称密钥的对称加密。在这种情况下可以认为本文方案能够保证索引的安全性。
此外,由于本文的分割方法使最后一个分块的维数可能很小,为了保证索引的安全性,可以人为地将最后一个分块通过填充0 扩充维度来满足安全要求,这样就可以在不影响查询结果的同时保证整个索引的安全。
6.2 陷门的不可链接性
如果相同的查询生成的陷门也是相同的,那么云服务器就能够统计不同查询请求出现的频率,从而结合背景知识推断出一些关键字。
综上所述,云服务器不能推断出两次查询的关系,从而保证了陷门的不可链接性。
7 效率分析及仿真实验
本节分别对构建查询陷门效率和查询效率进行了理论分析和实验验证。实验使用从网络上爬取的中文语料作为数据集,使用Python 3 语言进行仿真实验。仿真实验的硬件环境为 AMD Ryzen 5 3550H CPU,16 GB 内存,Microsoft Windows 10 操作系统。
将本文方案与文献[17,19,21]方案进行比较,分别是MRSE 方案、基于多维B 树的检索方案和基于平衡二叉树的检索方案。实验中将查询的关键词固定为10 个;文献[19]方案中每层的索引向量固定为100 维,每层按照欧氏距离Ed ≤0.02进行聚类;文献[21]方法采用单线程实现。
7.1 构建查询陷门
由式(3)可知,构建陷门是查询的重要一环,构建陷门需要在用户的本地进行,会给用户带来一定的计算负担,通常来说性能较差的设备会对陷门构建的时延更敏感,为让尽可能多的用户有良好的体验,高效的构建陷门是有必要的。

图5 是本文方案与现有方案关于构建陷门时间的比较。从图5 可以看出,本文方案在构建查询陷门的效率上优于其他方案,虽然文献[19]中的分层操作与本文方案中的分块方法类似,但其对所有层都进行了加密,而本文方案只加密与查询有关的块,因此本文方案构建陷门的效率更高。

图5 构建陷门时间随字典内关键词数量的变化
此外,由于本文方案中数据使用者只需要上传相关的分块,比其他方法拥有更小的通信开销。
7.2 计算文档相似性得分
本文方案的查询效率主要由计算文档相似性得分决定。每个索引分块的大小是ml,对应的查询向量是长度为l的向量,共有对这样的分块,所以查询的时间复杂度为
首先对本文方案的查询时间与索引块数vh的关系在固定的文档数量、字典长度和返回文档数量下进行实验。从图6 可以看出,本文方案的查询时间随着索引块数的增加而减少。分块数量越多,每个块的长度就越小,云服务器计算文档相似性得分时需要计算的次数越少,因此提升了查询的效率。由此可知,分块数越多查询效率越高,而随着分块数量的增加,系统的安全性也会减弱,所以在实际应用中,可以根据对查询效率与安全性的不同需求来确定适宜的分块数量。

图6 本文方案计算文档相似性得分时间随索引块数vh 的变化(m=3 000,n=5 000,K=100)
从图7 可以看出,随着文档集合的增大,各种方法的查询耗时都随之增加。文献[19]方案在文档数量较大时表现较好,但该方案在构建索引的过程中用到了聚类,对于给定的聚类阈值来说,文档越多,聚类导致的效果提升越显著,这样做提升了效率但牺牲了一定准确性。本文方案的计算文档相似性得分的时间随着文档数的增加而线性增加,与分析结果一致。

图7 计算时间随文档数m 的变化(n=5 000,vh=50,K=100)
图8 是各种方案的查询时间随着字典内关键词数量的变化情况。实验中将本文方案块的维数始终保持为100,所以块的数量随着字典长度的增加而增加。从图8 可以看出,随着字典的增大,本文方案在保持块大小不变、查询关键词数量不变的情况下查询效率与字典长度无关,而其他现有方案都是随着字典的大小线性变化。这表明了本文方案的查询效率与包含查询关键词的块数和每个块的块长有关,与字典长度无关。由此可以得出结论,本文方案比较适于字典维数很大的场景。

图8 计算时间随字典内关键词数量n 的变化(m=2 000,,K=100)
如图9 所示,文献[19]方案和文献[21]方案受返回文档数量的影响比较大,因为这2 个方案是树形索引,采用基于贪婪的深度优先搜索,K值越大,算法在搜索中剪枝的阈值就越小,排除的子树越少,导致需要遍历的树范围就越大;而文献[17]方案和本文方案是先计算出所有文档的相似性得分,然后再选出相似性得分最大的K个文档索引。对于文献[17]方案和本文方案而言,K值影响的是选出前K个文档这一过程,实验中采用的是利用快速排序的思想划分出前K个文档,这一步的时间复杂度是O(m),然后对这K个文档进行排序,所以总的时间复杂度是O(m+KlogK)。随着K的增大,仅在排序前K个文档的过程中增大了一些计算,因此本文方案的查询时间受返回文档数量的影响较小。

图9 计算时间随返回的文档数量K 变化(n=5 000,vh=50,m=3 000)
8 结束语
针对传统的云计算密文检索方案难以满足当今用户需求的问题,本文提出了一种基于分块的移动边缘计算密文检索方案。引入了边缘服务器来分担云服务器的计算压力。在改进搜索效率上,不同于现有的方案从过滤低相关性文档的角度进行改进,本文从过滤无关关键词的角度进行了改进,为提高密文检索的效率研究提供了新思路。理论分析表明,本文方案具有索引安全性和陷门不可链接性。通过实验对本文方案与现有经典方案的查询效率进行了多个方面的比较,结果表明本文方案相对于现有经典方案有效地提高了查询效率,并且字典维数越大提高效果越显著。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
客联(2022年3期)2022-05-31
房地产导刊(2022年4期)2022-04-19
曲阜师范大学学报(自然科学版)(2021年3期)2021-08-26
中国新闻周刊(2021年26期)2021-07-27
新生代(2019年10期)2019-10-18
电脑爱好者(2017年7期)2017-05-06
通信产业报(2016年44期)2017-03-13
雕塑(1999年2期)1999-06-28
