
视频对象移除篡改的时空域定位被动取证
2020-08-02 05:09陈临强杨全鑫袁理锋姚晔张祯吴国华
通信学报 2020年7期
陈临强,杨全鑫,袁理锋,姚晔,张祯,吴国华
(1.杭州电子科技大学网络空间安全学院,浙江 杭州 310018;2.杭州电子科技大学计算机学院,浙江 杭州 310018)
1 引言
随着数字视频处理技术的飞速发展和图像编辑软件的更新换代,篡改视频[1-3]变得随处可见。而在众多视频篡改类型中,面向视频对象移除篡改[4-5]的被动取证研究更有应用价值和研究意义。移除篡改即将某个关键视频对象从原始视频序列中移除,经过修补和填充后,该视频对象在被篡改视频序列的每一帧中都不可见,且凭肉眼无法辨别篡改痕迹。如果需要将视频作为执法依据,则必须证实其真实性和完整性。而数字视频的被动取证研究仍然处于起步阶段[5],尚有较大的探索和完善空间。
近年来,有众多的科研工作者在图像和视频篡改被动取证领域做出了贡献。在图像被动取证领域,李岩等[6]提出的翻转不变加速稳健特征(FI-SURF,flip invariant speeded-up robust feature)算法可以有效检测出图像的镜像复制粘贴篡改。黄维隽等[7]利用块离散余弦变换(BDCT,block for discrete cosine transform)[8]系数构造马尔可夫特征[9],再用支持向量机(SVM,support vector machine)分类器可以有效识别图像的拼接篡改。随着深度学习在图像识别和目标检测领域广泛应用,Adobe 公司提出的双流[10]Faster R-CNN(region-convolutional neural network)[11-13]可以很好地检测出图像中的拼接、复制和移除篡改区域。相比于图像篡改,视频篡改操作可以从相邻帧中获得更多的场景信息,从而可以更完美地对移除对象的区域进行修补,使基于单帧视频图像的篡改检测更加困难。
在数字视频的被动取证领域,刘雨青等[14]针对固定监控摄像头所拍摄视频中运动目标的移除,提出一种基于时空域能量可疑度的视频篡改检测方法。首先计算视频各帧能量可疑度,提取时域上的篡改序列;然后通过帧差法计算可疑的运动点图像,提取空域上的可疑运动图像块;最后通过能量可疑度排除干扰图像块,确定篡改图像块区域。李倩等[15]针对固定背景下运动目标的移除,将视频帧划分为网格,并统计每个网格内光流方向的标准差。通过与阈值比较来判断每个网格是否为篡改区域,进而对整帧篡改区域进行空域定位,最后根据空域定位的结果利用二分查找法进行时域定位。Yao 等[4]针对视频对象的移除篡改,利用相邻两帧帧差构造帧差序列,再用高通滤波器提取帧差高频信号作为CNN 的输入,使用CNN 自动提取相邻帧间的高频篡改特征,有效提高了篡改帧检测的准确率。何沛松[16]提出了基于卷积神经网络的帧级双压缩检测算法,利用中值滤波器提取中值滤波残差信号作为CNN 的输入,其鉴别能力明显优于AlexNet。
现有视频取证算法可以分为四大类[5]:基于噪声模式的算法、基于像素相关性的算法、基于视频内容特征的算法和基于抽象统计特征的算法。大多数算法都是基于视频对象篡改引起的视频内容本身的异常和视频篡改的先验知识,手动设计特定的特征提取和分析算法,以检测和识别视频对象的篡改。这类人工设计的特征提取算法,通常针对特定且有限的篡改视频库。视频篡改检测的准确率由人工设计的特征提取算法决定。同时,篡改视频库的制作方式、内容和编码参数等都会影响视频篡改取证算法的检测性能。目前针对视频对象移除篡改的深度学习算法中,使用视频帧差法等方法并不能充分体现篡改特征在视频时域方向上的连续性和相关性。
为了提升视频对象篡改被动取证算法的通用性,并充分提取篡改操作在时空域方向上的特征,本文提出了基于三维卷积(C3D,3D convolution)神经网络[17-19]的视频对象移除篡改时空域定位技术。针对被篡改的视频帧,可以判别待测视频帧是否存在视频对象被移除篡改,并定位被移除篡改的区域。相比于传统算法,本文算法具有以下优势:1) 没有视频背景保持不变,监控摄像头及移除的视频对象为运动或静止状态等硬性要求,增加了算法的可应用场景;2) 对预测结果的判断不需要人工观察和挑选阈值等操作,减少了人工操作和人为误差;3) 在空域定位算法中,将基于深度学习的目标检测理念运用到时空域三维空间,提高了算法的通用性和灵活性。
2 时空域定位系统结构与数据集处理方法
2.1 时空域定位系统结构
本文提出的视频对象移除篡改区域的时空域定位系统结构如图1 所示。该系统是基于带标注的视频数据集设计的。标注信息包括每一帧是否为篡改帧,以及篡改帧中篡改区域的矩形坐标。文献[5]中介绍4 种篡改取证算法的数据集:SULFA(surrey university library for forensic analysis)、REWIND、DICGIM 和SYSU-OBJFORG。其中,前2 种数据集分别只有5 段和10 段关于视频对象移除篡改的视频,且每段视频长度只有10 s(帧率为30 frame/s),由于数据集太小不利于使用深度学习框架来进行训练。DICGIM 数据集篡改类型中不包含视频对象的移除篡改,不适于本文算法。SYSU-OBJFORG 库是目前最大的视频对象篡改库,包含100 段原始视频和100 段原始视频对应的篡改视频。该数据集篡改类型均为视频对象移除篡改,且平均每段视频长度为11 s(帧率为25 frame/s),所有视频均经过H.264/MPEG-4 编码格式压缩。数据集中的篡改视频是将原始视频解码之后,由数据集制作者对视频图像逐帧进行空域上的篡改,再编码压缩而成的。篡改视频经历了解压缩、篡改、再压缩的过程,对篡改检测和定位算法的要求更高。本文首先将数据集中的所有视频解压成图像帧,然后进行裁剪、翻转等数据增强操作,所得数据集规模可以满足深度学习训练的要求。

图1 时空域定位系统结构
图1 中左右两条分支为2 个不同的网络模型,分别用于视频被篡改区域的时域和空域定位。2 个模型的输入都是连续的5 帧视频图像,且特征提取器的结构相同。2 个CNN 模型最大的区别在于特征提取器所生成的特征图是用于分类还是用于RPN(region proposal network)[20]框回归定位。2 个模型训练数据增强的处理方式也不同。用于时域定位的网络需要同时输入原始帧和篡改帧进行训练,而用于空域定位的网络则只需要输入篡改帧进行训练。
2.2 2 种不同的数据集处理方法
为了尽量不破坏视频数据,同时对训练数据进行比例调整和样本扩充,在诸多的计算机视觉数据增强策略中,本文只选取了裁剪和翻转2 种数据增强策略。2 种数据集的处理方法都是基于连续的5 帧视频图像进行操作的(即当前帧加上连续的前2 帧和连续的后2 帧),以便提取篡改痕迹在时域上的连续性特征。对于时域定位,由于数据集中原始帧和篡改帧比例约为13:3,为了保证训练集正负样本数量相当,本文借鉴文献[4]提出的非对称数据增强策略,将2 种视频帧按帧数的相反比例进行裁剪并打包。对于空域定位,篡改帧内的定位在完整的帧图像中进行,因此不对输入图像帧进行裁剪,而是通过水平翻转、垂直翻转和水平垂直翻转来进行增强。具体增强策略分别介绍如下。
2.2.1 用于时域定位的数据集增强策略
本文视频数据集尺寸为1 280 像素×720 像素,裁剪尺寸需要满足以下条件:每个裁剪区域在训练集的篡改帧中至少要包含大部分的篡改区域;测试集中所有裁剪区域要覆盖整帧进行测试,不能有遗漏区域。为了方便计算和模型的简洁性,本文设定裁剪尺寸为720 像素×720 像素。对于训练集和验证集采用相同的裁剪方案,只对连续的5 帧原始帧或篡改帧进行裁剪。
对于连续原始帧,统一按均匀步长左中右三次裁剪(可以适当在横坐标方向进行随机像素的微小偏移,以防过多学习每一帧的边缘特点)或随机裁剪三次,并且连续5 帧的裁剪位置保持严格一致。
连续5 帧篡改帧的篡改区域如图2 所示。假设坐标框(xi1,yi1,xi2,yi2)内为视频对象移除篡改区域,其中i=1,2,3,4,5。按式(1)求出如图3 所示的连续5 帧篡改区域最小外接矩形区域(Xmin,Ymin,Xmax,Ymax),以(Xmin,0,Xmax,720)为裁剪边界,按平均步长平移裁剪出若干份或随机裁剪出若干份(但要保证裁剪部分包含篡改区域或大部分篡改区域)连续5 帧的图像数据并打包。对于测试集,将连续5 帧视频均按统一步长进行左中右三次裁剪,以保证检测区域覆盖视频帧全部区域。以上每裁剪出连续5 帧便打包为一组作为时域定位模型的输入数据,且label 以中间帧的label 为准。


图2 连续5 帧篡改帧篡改区域示意

图3 连续5 帧篡改区域最小外接框示意
2.2.2 用于空域定位的数据集增强策略
对于训练集,连续5 帧同时采取水平翻转、垂直翻转和水平垂直翻转进行数据增强。而测试集不需要进行翻转。训练集翻转的同时,篡改区域标注框Ground Truth 坐标做相应变换。设视频帧的宽为W,高为H,篡改区域坐标为(x1,y1,x2,y2),则水平翻转后为(W–x2,y1,W–x1,y2),垂直翻转后为(x1,H–y2,x2,H–y1),水平垂直翻转后为(W–x2,H–y2,W–x1,H–y1) 。同样每5 帧进行打包并标注,且标注框Ground Truth 以中间帧为准。
3 搭建时空域定位网络
模型分为三部分,分别为用于提取三维高频特征的特征提取器、用于时域定位的分类器和用于空域定位的RPN 框回归器,其网络结构分别如图4~图6 所示。

图4 C3D 神经网络特征提取网络结构
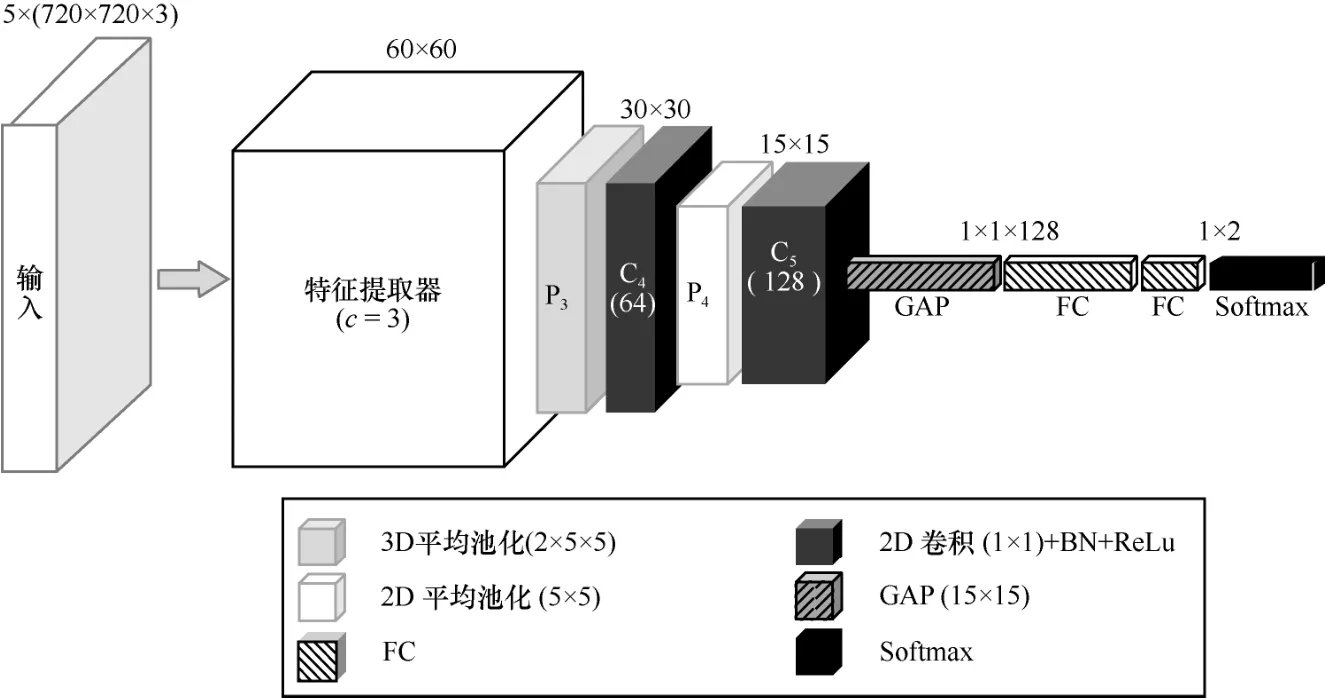
图5 时域定位分类模型

图6 空域定位回归模型
3.1 特征提取器
C3D 神经网络可以捕捉连续帧在时域方向相关语义的变化特征,因此常用于计算机视觉的视频内容识别领域,来检测人物动作及行为。由于篡改操作会留下痕迹[21-22],这种痕迹在高频区域[23-25]往往更加明显。通过观察发现,在篡改视频中,篡改区域的高频信号在相邻帧间具有极大的连续性和相关性[26-27]。这种连续性和相关性可以看作篡改痕迹在连续帧间发生的“动作”,类似使用C3D 神经网络对人物动作的识别,本文使用C3D 神经网络来提取篡改区域的“动作”特征。
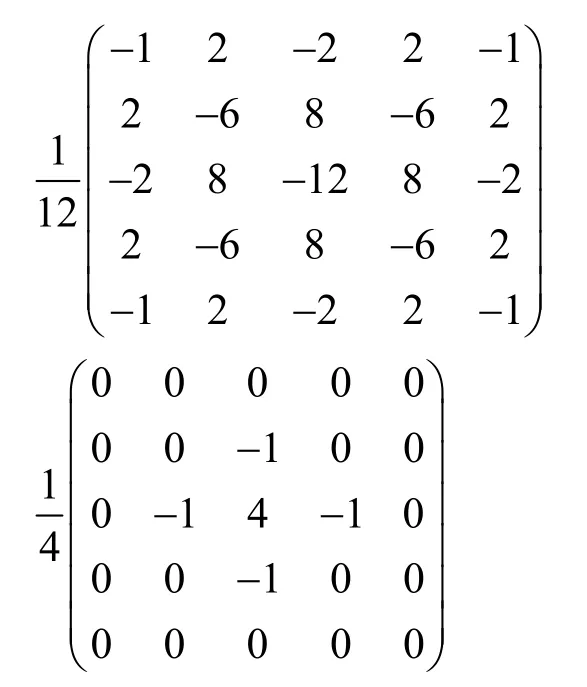
输入的连续5 帧图像首先经过2 个图像处理层:三维最大池化层和空间富模型(SRM,spatial rich model)[10]过滤器层。其中,最大池化层滑动窗口尺寸为1×c×c[28],在时域定位器中c设置为3,在空域定位器中c设置为2,时域方向池化参数为1,以保证数据在输入CNN 前时域方向特征不被破坏。最大池化层的作用是在空域方向上对输入数据进行降维,保留其主要特征,同时减小计算量。SRM 过滤器层使用3 个不同参数的卷积核分别提取视频帧3 种不同的高频残差信号,并将其参数设置为不可训练。本文中SRM 过滤器所使用的3 个卷积核参数分别为

将三维高频数据送入C3D 神经网络特征提取网络中,同时提取时空域高频信号特征。网络结构如图4 所示,其中,Ci(i=1,2,3,4,5)表示第i层卷积层,Ci下面括号中的数字表示该层卷积核的个数。图4 中C1~C3分别是第1~3 层三维卷积层,卷积核尺寸均为3×3×3。每个卷积层均进行批标准化(BN,batch normalization)操作,激活函数均为ReLu。Pi(i=1,2,3,4,5)表示第i层池化层,P1、P2分别是第1、2 层三维平均池化层,滑动窗口均为2×5×5,池化层步长均为2。
3.2 时域定位分类器
时域定位分类器由图4 的特征提取器(其中c=3)后接二分类器组成,用于判别输入的连续5帧是否为篡改帧。时域定位分类模型如图5 所示。特征提取器生成的特征图经过一个三维平均池化层P3(滑动窗口为2×5×5,步长为2),将特征图时域维度降为1,然后依次经过卷积核为1×1 的2 个二维卷积层C4和C5,卷积核个数分别为64 和128。1×1 的卷积核是为了避免学习过于复杂的特征,同时起到降维的作用。P4为二维平均池化层(滑动窗口大小为5×5,步长为2)。全局平均池化层(GAP,global average pooling)P5将数据由128 维的特征图变为128 维向量。最后经过全连接层(FC,fully connected layer)将数据维度降为2,并利用Softmax层进行归一化分类。
3.3 空域定位回归器
空域定位回归器是由特征提取器(其中c=2)后接RPN 框回归器组成的,用于预测篡改位置并给出相应的置信度(即预测区域为篡改区域的可能性)。空域定位回归模型如图6 所示。由特征提取器生成的特征图需要经过三维平均池化层P3(滑动窗口为2×5×5,步长为2)将时域维度降为1。将P3和C4的特征图合并为Concatenate 层[20]作为框回归的特征图,C4和C5(有上、下2 个分支)均为卷积核尺寸为1×1 的二维卷积层,其中C4卷积核个数为64;C5(上)卷积核个数为36,C5(下)卷积核个数为18,分别对应特征图每个位置9 种尺寸的回归框所对应的框坐标和其置信度。
在测试阶段,通过非极大值抑制(NMS,non-maximum suppression)[10]将候选框按置信度排序,本文中只保留置信度最高的一个候选框作为预测的篡改区域。
4 实验过程
4.1 数据集介绍
在SYSU-OBJFORG 数据集上验证本文算法。SYSU-OBJFORG是Chen等[29]提出的基于视频对象移除篡改的数据集,由100 段原始视频和100 段篡改视频组成。原始视频来源于静态视频监控摄像机拍摄的视频片段,篡改视频则是从这些原始视频中通过逐帧移除目标对象获得的。其中篡改帧中的篡改区域是用其在帧内左上角和右下角的坐标来标注的。
实验中,将100 对视频序列进行随机排序,按照5:1:4 的比例分为训练集、验证集和测试集。2 个模型均使用相同序列的训练集,数据增强方式如2.1节所述。2 个模型都训练好后,首先将测试数据输入时域定位器,得到视频每一帧的分类结果,即完成篡改时域定位;然后记录下篡改帧编号,将这些篡改帧作为空域定位器的输入序列,进行篡改帧空域定位。重复5 次,每次都从不同的随机序列中分出训练集、验证集和测试集,并重新开始训练。对5 次实验的测试结果求平均值,作为衡量实验模型有效性的依据。
4.2 实验设置
本文的神经网络模型基于Tensorflow 深度学习框架实现,运行于NVIDIA Geforce GTX1080ti GPU上。使用AdamOptimizer 进行优化,将学习率设置为1×10–3,动量设置为0.9,l2正则化参数设置为0.000 5,参数初始化标准差均设置为0.1。
对于时域定位网络,批大小设置为64,即每次输入神经网络的图像块维度为64×5×720×720×3。当验证集损失函数趋于收敛时,挑选出训练好的模型用于测试。测试时批大小设置为3,即同时输入同一帧的三次裁剪的图像数据。如果全部被预测为原始帧,则判断中间帧为原始帧;否则判断为篡改帧,进而得到篡改帧时域定位序列。
对于空域定位网络,批大小设置为1,即每次输入神经网络的图像块维度为 1×5×720×1 280×3。设置的空域定位损失函数与文献[11]中定义的损失函数相似,包含前景框(篡改区域)和背景框(原始区域)分类误差、篡改区域定位框误差两部分。当损失函数趋于收敛时,用训练好的模型进行测试,将篡改帧时域定位产生的篡改帧序列作为空域定位器的输入。本文中采用的损失函数如式(2)所示。

其中,Ncls是随机抽取的前景框(与篡改标注框交并比大于0.8)和背景框(与篡改标注框交并比小于0.2)的视频帧(篡改帧)总数,i是这些框的下标,Lcls是对其中每一个框二分类(前景框与背景框)的损失函数;Nreg是抽取的框中前景框的数量,j是其中前景框的下标,Lreg是预测框与真实篡改区域标注框之间误差的损失函数。
为了使正负样本框数量均衡和减少目标区域误检率,设定每一帧中参与训练的前景框与背景框数量之比为1:α,则前景框数量fg_num 和背景框数量bg_num 可由式(3)进行约束。

其中,fg_sum 为前景框的总数;roi_num 为常数,其大小控制着正负样本的训练密度。实验中,设置roi_num=128,α=5,保证在正负样本数量相差不大的情况下加强对负样本的训练,目的是降低单一目标区域检测的误检率。
4.3 实验结果
4.3.1 时域定位测试
在篡改视频时域定位测试中,本文与文献[4]方法进行了对比。本文采用Chen 等[29]定义的测试结果衡量标准,如式(4)所示。

其中,PFACC 是原始帧正确率,FFACC 是篡改帧正确率,FACC 是所有帧的正确率,Precision 为精确率,Recall 为召回率,F1Score 为F1分数,Tp为篡改帧被正确预测的数量,Fp为原始帧被错误预测为篡改帧的数量,FN为篡改帧被错误预测为原始帧的数量。重复5 次实验,每次都随机产生不一样的训练集、验证集和测试集,测试结果取平均值,如图7 所示。
4.3.2 空域定位测试
在目标检测领域,mAP 是最经典的衡量预测精确度的指标,而交并比是目标检测算法指标mAP 计算的一个非常重要的函数,可以被直观地理解为预测框与标注框的重合程度。在文献[30]中,交并比被认为是定位准确率的最佳标准。视频篡改检测与计算机视觉中的目标检测不同:目标检测中的语义对象可以肉眼看到,并且和周边场景有较大差异;视频篡改检测中的篡改区域可能远大于运动目标或语义对象所在的区域,并且篡改之后区域和周边的场景没有明显的差异,肉眼无法区别原有的语义对象和真实的篡改区域。因此,预测区域不能简单地与被移除的语义对象区域进行比较,而应该与实际的被篡改区域进行比较。由于要预测的只有被篡改区域这一个类别,因此引入了比mAP值更直观的成功检测率和平均交并比作为替代指标。成功检测率表示在篡改帧中,可以较好地预测出篡改区域的帧数与测试总帧数的比例。平均交并比表示这些预测出的较好的篡改区域与其真实篡改区域重合比例的平均值。
对于每个篡改帧,取预测框序列中置信度最高的框作为最终的预测区域。当预测框与真实篡改区域标注框的交并比为0 或置信度小于0.8 时,定义为漏检帧Fmis,否则为成功检测帧Fsuc。由此可以计算出成功检测率Suc_rate 为

定义测试集平均交并比IOU_mean 为

图7 时域定位测试结果
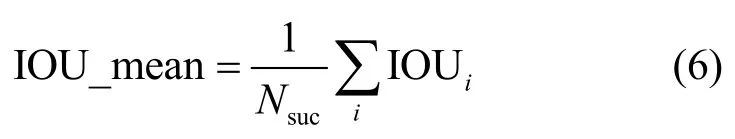
其中,Nsuc表示成功检测帧的总数,i表示成功检测帧的下标。
将时域定位中检测出的真实篡改帧序列作为空域定位的输入,空域定位算法流程如图8 所示。将篡改帧结合连续的前2 帧和后2 帧作为输入,经过两层图像处理层,再经过C3D 神经网络特征提取器生成如图6 所示的96 维的特征图。在特征图上产生一系列预测框及其对应的置信度,将所有的预测框按置信度从大到小排序,取置信度最高的前3个框的外接框作为最终的预测区域。本文中则仅采用置信度最高的框作为最终的预测区域。图8 中,ROIi表示预测框序列
对不同的篡改特征处理和提取算法,本文进行了一系列对比实验。不同算法空域定位检测结果如表1 所示。从表1 可以看出,本文算法中SRM 层与C3D 神经网络相结合可以明显改善空域定位的效果。SRM 层的作用最明显。相比于VGG16 的16层CNN,C3D 神经网络特征提取器只需要三层便可以有很好的效果,说明C3D 神经网络更能胜任对连续帧数据的特征提取任务。
当空域定位器输入的连续帧数不同时,分别采用1~5 帧连续帧作为空域定位器的输入。实验对比结果如表2 所示。实验结果表明,当输入帧数越多时,空域定位效果越好;当输入帧数超过3 帧时,空域定位效果增益减缓。

图8 空域定位算法流程

表1 不同算法空域定位检测结果对比

表2 本文算法输入不同连续帧数的实验对比结果
当空域定位结果由多个置信度最高的预测框共同决定时,分别采用置信度最高的前1~3 个预测框的外接框作为最终预测区域,如图9 所示。方案a、方案b、方案c 分别为3 种不同的决策方案。区域内的数字表示区域交叠次数,阴影区域分别为3 种方案的最终预测结果。

图9 预测框的交叠区域示意
方案a 使用置信度最高的预测框作为预测结果,方案b 和方案c 分别由置信度最高的前2 个和3 个预测框的外接框作为最终的预测结果。采用不同预测方案的实验结果对比如表3 所示。随着参与预测的预测框数量的增加,成功检测率呈上升趋势,平均交并比呈下降趋势。因此,为了使定位更加准确,本文采用方案a 作为最终预测方案。
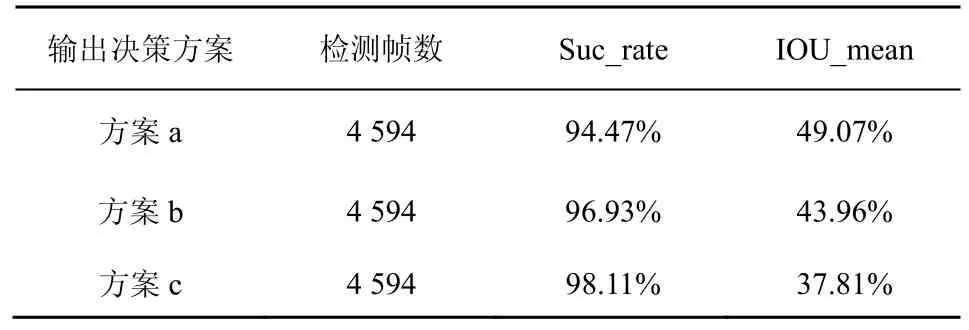
表3 空域定位3 种决策方案测试结果对比
4.3.3 时空域定位测试
随机从测试集选取10 个篡改视频来进行完整的时空域定位测试,时空域定位流程如图10 所示。首先将测试数据打包成时域定位的输入形式,送入由特征提取器1 和帧鉴别器组成的时域定位器,得到每一帧的判断结果,并记录其中的篡改帧;然后将记录的预测正确的篡改帧序列打包为空域定位器的输入形式,送入特征提取器2 和空域定位器进行空域定位;最后进行计算评估。

图10 时空域定位流程
对于实验结果,需要特别说明的是:1) 在时域定位模型训练过程中,仅输入连续5 帧的原始帧和连续5 帧的篡改帧,没有输入连续5 帧中既有原始帧也有篡改帧进行训练;测试集中输入的连续5 帧视频帧的label 以中间帧为准。因此,测试中时域定位FACC 的主要精度损失通常会不可避免地存在于对原始帧和篡改帧交界处连续几帧的判别过程中;2) 在空域定位模型训练过程中,由于只对连续的篡改帧进行了空域定位模型的训练,因此只将在时域定位中预测正确的篡改帧序列输入空域定位器进行篡改区域的预测,这样就可以用不同的指标来表现模型分别在时域和空域的定位能力。
本文算法在部分测试视频中完整的篡改区域时空域定位结果如表4 所示。FACC、Suc_rate 和IOU_mean 这3 个指标中,后2 个指标依次在前一个指标测试结果已知的条件下才有意义。
5 结束语
基于SRM 和C3D 神经网络构建了2 个深度卷积神经网络模型,分别用于视频对象移除篡改中篡改区域的时域定位和空域定位。使用SRM 滤波器提取高频信号,使篡改特征初步显现出来;使用三维卷积神经网络C3D 神经网络作为特征提取器,在高频信号中提取视频篡改痕迹在帧间连续性和相关性的特征;利用三维池化在特征图时空域方向进行降维,当特征图在时域方向维度降为1 时,结合RPN思想进行篡改区域预测框的训练。通过多组实验对比,结果表明本文算法在时域和空域定位上都表现良好。但是,也存在网络模型计算量庞大、实验步骤复杂和对视频序列中篡改帧和原始帧的过渡区域无法精确且有效地判别的缺点。如何在提高精度的同时减少计算量、加快训练速度是未来的主要工作。

表4 本文算法在部分测试视频中完整的篡改区域时空域定位结果
猜你喜欢
哈尔滨工程大学学报(2021年10期)2021-11-05
军民两用技术与产品(2021年10期)2021-03-16
环球时报(2021-02-01)2021-02-01
科技视界(2020年8期)2020-05-18
北京航空航天大学学报(2019年9期)2019-10-26
军事运筹与系统工程(2019年4期)2019-09-11
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
宇航计测技术(2019年1期)2019-03-25
电子制作(2018年19期)2018-11-14
