
基于上下文注意力CNN的三维点云语义分割
2020-08-02 05:10杨军党吉圣
通信学报 2020年7期
杨军,党吉圣
(兰州交通大学电子与信息工程学院,甘肃 兰州 730070)
1 引言
点云是三维模型最重要的数据表示形式之一,其能够准确、直观地描述三维模型。随着三维成像技术的飞速发展,三维点云数据呈海量增长趋势,对其进行分析和处理显得尤其重要。语义分割作为三维点云数据分析处理的前提与基础,已广泛应用于医学成像、自动驾驶、机器人导航、虚拟现实、遥感测绘等领域,成为计算机视觉和计算机图形学领域的一个重要研究课题。由于卷积神经网络[1]的飞速发展以及GPU(graphics processing unit)计算能力的显著提高,传统的手工设计描述符[2-4]的方法已渐渐被基于深度学习的方法所取代,一些研究者开始设计针对大规模、多种类的复杂三维点云模型语义分割的深度学习框架。目前,基于深度学习的三维点云模型语义分割方法主要有:基于投影的方法、基于多模态的方法、基于体素化的方法和基于点云表示的方法。
基于投影的方法。受二维图像语义分割方法的启发,Ku 等[5]将三维点云投影为二维鸟瞰图,然后使用经典的二维深度学习网络提取特征用于三维点云语义分割。Yang 等[6]设计了一个单级检测器,从像素级神经网络输出点云分割结果。Kalogerakis等[7]提出了投影卷积神经网络,首先对三维模型进行多方位拍照,然后将二维视图输入VGG(visual geometry group)[8]中提取特征,最后将特征反投影到三维点云表面预测每个点的语义类别。Huang 等[9]提出多视图卷积神经网络,从对应关系中学习局部描述符,增强了网络的泛化能力。然而,基于投影的方法的关键问题是在生成2D 投影图时,丢失了具有鉴别力的几何结构信息。
基于多模态的方法。Chen 等[10]提出MV3D(multi-view 3D)目标检测网络,把鸟瞰图和点云同时作为输入获得多模态特征,进一步融合用于点云语义分割任务。Qi 等[11]利用一个二维检测网络构建截锥体点云。然而,基于多模态的方法通常计算效率较低。
基于体素化的方法。Wu 等[12]将不规则的三维点云模型转化为规则的体素网格,这样便可以使用三维卷积神经网络处理体素模型提取特征,但是体素方块大小的选择会影响网络性能,太大会丢失细节,太小会增加计算负担。改进算法提出了空间划分方法,如Kd 树[13]或者八叉树[14],解决了一些分辨率低的问题,但仍然依赖于边界体的细分,没有考虑局部几何结构。
基于点云表示的方法。为了避免多方位投影、体素化等方法的烦琐操作,Qi 等[15]提出了可以直接作用于无序点云数据的PointNet 模型,利用多层感知机(MLP,multi-layer perceptron)学习每个独立点的高维表征,然后采用一个最大池化层对所有点的高维特征进行聚合得到全局特征描述符。PointNet是深度学习框架可以直接作用于不规则三维点云数据的先驱性工作,然而,PointNet 只关注每个点的全局特征,缺乏捕捉局部特征的能力。Qi 等[16]提出了PointNet++,通过划分局部点云分层提取多尺度特征。该网络虽然考虑了点云局部特征,但是没有考虑点对之间的关联信息,缺乏捕捉几何特征的能力。Wang 等[17]通过建立和更新动态图,在保证置换不变性的同时捕获局部几何特征,取得了较先进的分割结果。Chen 等[18]建立局部区域加强对相邻点的关注,以充分提取点云的局部几何特征。Liu 等[19]提出一种点云序列学习模型,采用注意力机制来突出不同尺度区域的重要性。Wang 等[20]提出了相似分组提议网络(SGPN,similarity group proposal network)模型,引入相似矩阵作为输出,表征嵌入特征空间中每对点之间的相似度,从而预测每个点的语义标签。Jiang 等[21]设计了PointSIFT模块,该模块可以对不同方向的信息进行编码,并且通过堆叠几个方向编码单元来实现多尺度表示,最后将解码器的输出连接到全连接层,用于预测每个点的语义类别。Ye 等[22]提出利用超点图来有效捕捉点云的组织结构,然后通过图卷积神经网络从超点图中提取特征来完成语义分割任务。Landrieu 等[23]提出了一种新的端到端语义分割方法,首先研究了利用多尺度邻域捕获不同密度局部结构特征的金字塔池化模型,然后利用双向循环神经网络(RNN,recurrent neural network)学习点云的空间相关性来捕捉空间结构信息,最后输出每个点的语义标签。
相对于三维目标识别任务,三维点云语义分割需要预测每个点的语义类别,提取更精细的点特征,因此是一项需要结合上下文信息的更具挑战性的细粒度点云分析任务,但由于点云存储在不规则和无序的结构中,提取点云的上下文细粒度特征信息仍然具有很大的挑战性。现有方法在三维点云语义分割过程中对于整体几何形状极其相似、局部细节结构略有不同的语义类不能进行有效区分,造成的欠分割问题一直没有得到很好的解决。本文提出一种基于上下文注意力卷积神经网络(CACNN,contextual attention convolutional neural network)的三维点云语义分割算法,充分挖掘三维模型的多尺度上下文细粒度特征信息,改善了三维点云语义分割的过分割问题,提高了三维点云语义分割的准确率。主要贡献和创新点如下。1) 构建上下文注意力卷积层。通过在局部点云中引入图注意力机制来对邻域特征进行自适应筛选,更好地学习点云的细粒度局部特征。2) 通过上下文RNN 编码每个采样点的不同尺度邻域特征来学习每个采样点的多尺度上下文几何特征,并与细粒度局部特征相互补偿增强特征描述符的语义丰富性。3) 采用多头部机制聚合不同的单头部上下文注意力卷积层的特征,使网络具有良好的泛化能力,同时在网络中引入残差学习以充分挖掘三维点云的深层隐含特征信息,进一步提高网络特征学习的能力。
2 上下文注意力卷积神经网络
2.1 上下文注意力卷积层
在实际应用(如自动驾驶)中,点云的数目非常大,为了减少计算成本,需要构建一个k近邻图G=(V,E)来表示点云的一个局部区域。其中,V={1,2,…,N}为点的集合,E⊆V×αi表示连接相邻点对的边,αi为点xi的邻域点的集合。为了使点集的特征学习不受旋转、平移等变换的影响,将每个局部区域点的坐标xij转换为中心点xi的相对坐标,即得到边的特征为

其中,xi∈V,xij∈αi。
为了充分挖掘点云的细粒度细节和多尺度上下文信息,在PointNet[15]的基础上,本文构建上下文注意力卷积(CAC,contextual attention convolutional)层,采用注意力编码和上下文RNN 编码2 个并行编码机制分别学习局部区域内细粒度特征和局部区域之间的多尺度上下文几何特征,上下文注意力卷积层网络结构如图1 所示。其中,MLP{}表示多层感知机操作,{ }中的数字表示卷积核的数目。
注意力编码机制首先采用输出通道为F1的MLP 将原始点特征和边特征映射到高维特征空间,如式(2)和式(3)所示。

其中,λ为参数化的非线性激活函数,Θ为卷积核中可学习的参数集合,BN 为批归一化处理,c为卷积操作,其下标F1×1 表示卷积核大小。实验中F1取16,即特征通道数为16。对分别采用一个MLP 生成描述点xi自注意力系数和邻域注意力系数,并将两者进行融合得到描述点xi到其邻域内k个邻近点的注意力系数bij,如式(4)所示。
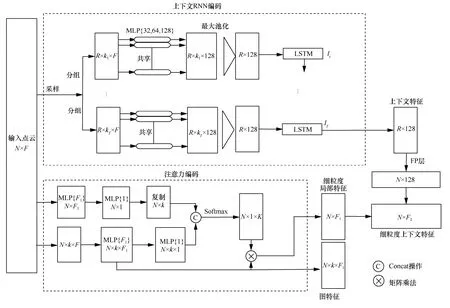
图1 上下文注意力卷积层网络结构
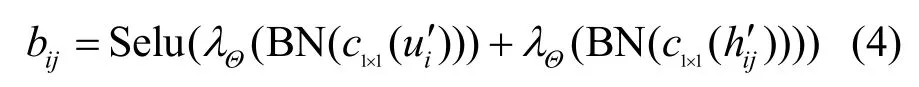
其中,Selu()为非线性激活函数。为了提高模型收敛速度,采用Softmax 函数对注意力系数进行归一化处理,如式(5)所示。

为了挖掘细粒度局部特征,将注意力系数aij与局部图特征相乘,则细粒度局部特征li为

此时,注意力系数作为一个特征选择器,自适应地对描述点xi具有鉴别力的邻域特征进行增强,抑制无意义的邻域特征(如噪声)充分挖掘点云局部区域内的细粒度细节信息。
上下文RNN 编码机制首先采用迭代最远点采样算法从输入点云中选取R(R<N)个点作为R个局部区域的中心点。对于每个采样点,采用k最近邻算法分别搜索距离采样点最近的[K1,···,Kt,···,KT]个点来构建T个不同尺度的局部邻域。然后,分别采用卷积核数目为32、64、128 的3 个MLP 提取每个局部邻域的几何特征,第一个MLP 卷积核大小为F×1,由于1×1 卷积核[24]可以增强网络的非线性拟合能力,减少参数的同时可以聚合各通道信息,因此,网络中其余MLP 的卷积核大小均采用1×1。最后,采用一个最大池化层分别将不同尺度的邻域特征聚合到每个采样点上,得到每个采样点的不同尺度的特征序列。其中,为采样点的kt邻域的几何特征向量。
为了获得采样点的不同尺度邻域之间的相关性,把采样点的特征序列输入RNN 编码器,并用一个隐藏层d依次编码采样点不同尺度的邻域特征向量来充分挖掘上下文几何信息。RNN 在编码采样点xi的不同尺度邻域的特征向量时,依次更新隐藏层状态,如式(7)所示。
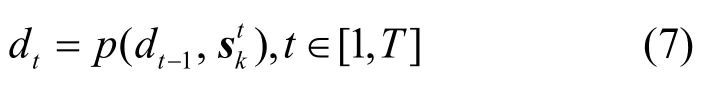
其中,p为非线性激活函数,实验中采用LSTM 单元;dt-1为编码上一个邻域特征向量sk-1的隐藏层状态。在RNN 编码采样点的第t个邻域的特征向量sk时,编码器的输出ot为

其中,Wa是一个可学习的权重矩阵。当网络学习完成整个特征序列后,得到隐藏层状态dT,和Wa相乘得到采样点的多尺度上下文几何特征oT。
注意力编码虽然引入注意力机制增强了网络捕捉局部区域内细粒度细节的能力,但是忽略了对于点云语义分割至关重要的局部区域之间的上下文几何信息。上下文RNN 编码机制充分挖掘了点云的多尺度上下文高级特征,因此低级别的细粒度局部特征和高级别的多尺度上下文几何特征可以相互补偿。采用Selu 非线性激活函数将采样点的不同层次的细粒度局部特征和上下文几何特征融合,可以得到采样点的大小为N×F2的上下文细粒度几何特征。在特征融合前,采用插值操作[16]在R×128的点云上采样N×128 的点云。特征融合计算式为

2.2 多头部上下文注意力卷积层
为了获得丰富的特征信息以进一步增强网络的泛化能力,本文引入多头部机制。在计算CAC层的上下文细粒度特征和图特征时引入随机丢弃(dropout)算法,通过随机丢弃一些权重得到M个不同的单头部(single-head)CAC 层。然后,把M个单头部CAC 层连接到一起得到特征信息更加丰富的多头部上下文注意力卷积(M-CAC,multi-heads contextual attention convolutional)层。多头部CAC层网络结构如图2 所示,计算式如式(10)所示。

图2 多头部CAC 层网络结构

2.3 上下文注意力卷积神经网络
为了进一步挖掘点云的深层隐含语义特征信息,本文在构建的上下文注意力卷积神经网络中引入残差学习,网络结构如图3 所示。其中,空间转换网络为一个3×3 的矩阵。
对于网络输入的N×F点云矩阵,首先采用一个空间转换网络对其进行规范化,实现点云矩阵的空间变换不变性。然后,采用M-CAC 层提取输入点云的上下文细粒度几何特征和图特征,将得到的特征维度为N×176 的上下文细粒度几何特征与区域中心点的三维坐标特征相结合,获得维度为N×179 的点云矩阵输入堆叠的MLP层进行二次特征提取。此外,为了挖掘深层隐含语义特征,引入残差连接,在避免梯度消失的同时加深了网络深度,各层卷积层的具体参数设置如表1 所示。最后一层卷积层Layer6输出的N×1 024 特征矩阵通过一个最大池化层进行特征聚合得到1×1 024 的全局特征描述符。为了从全局形状特征描述符中获取点级别的特征,在网络中引入2 个插值层[16],通过上采样将特征从形状级别传播到点级别。本文采用三维空间中点与点之间的欧氏距离来实现特征传播过程χ,由点q与其k最近邻点qi的欧氏距离插值而成,计算式如下

其中,q-qi表示点q与qi的欧氏距离。为了引导插值过程,将插值后的特征与对应的点特征连接起来,并在网络中引入多个MLP 层和Selu 层促进点级别特征的提取。最后网络输出分割结果N×S点云矩阵,表示每个点的语义类别。
3 实验结果与分析
3.1 实验数据集

图3 CACNN 的网络结构

表1 卷积层参数设置
为了验证本文算法的语义分割性能和泛化性,实验选用3 个标准公开数据集,分别为部件语义分割数据集ShapeNet Parts[25]、室内场景语义分割数据集 S3DIS[26]和户外场景语义分割数据集vKITTI[27]。ShapeNet Parts 数据集包含16 个类别的16 881 个CAD 模型,其中9 843 个模型用于训练,2 468 个模型用于测试,定义了50 个部件语义标签。S3DIS 数据集是一个大规模室内RGB-D 数据集,共有6 个区域271 个房间,定义了地板、窗户、门、横梁等13 个语义类别。实验设置和文献[15]一样,采用6 个区域交叉验证。vKITTI 数据集是一个模拟现实世界的可应用于自动驾驶的户外大规模点云数据集,将5 个不同城市场景的视频序列分为互不重叠的6 个区域,定义了车、树木、马路、建筑物等13 个语义类别。
3.2 网络参数设置
本文算法CACNN 的训练和测试过程的实验环境基于Linux Ubuntu 16.04 操作系统、Intel i7 8700k CPU、内存32 GB、GeForce RTX 2080 GPU,运算平台为CUDA-Toolkit 9.0,采用Cudnn 7.13 作为网络的GPU 加速库,深度学习框架为Tensorflow-GPU,版本号为1.9.0。在实验中,CACNN 的训练过程采用基于动量的随机梯度下降(SGD,stochastic gradient descent)优化算法,设置动量为0.9,权重衰减为0.000 5,初始学习率为0.001,学习率衰减系数为0.5,衰减速度为300 000,全连接层中dropout的参数保留率为0.5。优化器采用Adam,网络参数初始化采用Xavier 优化器。
3.3 实验结果与分析
为了验证本文算法在处理三维点云语义分割任务上的优越性,在ShapeNet Parts 数据集上与其他先进算法在识别准确率和效率两方面进行了对比,评估准则采用前向传播时间和平均交并比mIoU(mean intersection-over-union),实验结果如表2 所示。可以看出,本文算法以85.4%的mIoU 和39.0 ms的前向传播时间获得了较好的分割性能。本文算法相比于当前主流算法 DGCNN(dynamic graph convolutional neural network),在分割准确率和计算效率方面都具有一定优势。图4为本文算法CACNN与PointNet[15]在ShapeNet Parts 数据集上几个类别的模型分割结果对比,其中 PointNet_diff 和CACNN_diff 分别标出了PointNet 和CACNN 的预测结果与真实体的不同之处。与PointNet 相比,本文算法总体分割错误率明显减少,纠正了PointNet在细粒度边界处的欠分割问题,如桌子的底部、台灯的底端等,进一步验证了本文算法通过构建CAC层能够捕捉对于点云语义分割至关重要的上下文细粒度信息。

表2 不同算法在ShapeNet Parts 数据集上的网络性能比较

图4 本文算法与PointNet 在ShapeNet Parts数据集上的模型分割结果对比
此外,为了探究本文构建的CAC 层中采用注意力编码和上下文RNN 编码机制的有效性,在实验中依次引入这2 种编码机制以验证每一种编码机制的作用,实验结果如表3 所示。PointNet 算法采用自编码机制对独立的点提取特征,本文算法通过引入注意力编码方式对三维点云语义分割的mIoU比PointNet 提高了0.7%,原因在于注意力编码机制通过对每个点的邻域特征进行区分,能够充分挖掘局部点云的细粒度局部特征信息。注意力编码和上下文RNN 编码相结合的方式对三维点云语义分割的mIoU 比PointNet 提高了1.7%,因为上下文编码可以结合每个采样点的多尺度上下文几何信息,和注意力编码提取到的细粒度特征进行相互补偿,得到特征信息更加丰富的细粒度多尺度上下文特征。

表3 不同编码机制的有效性分析
本文继续探究了CAC 层、M-CAC 层和残差学习对网络性能的影响。通过构造不同的网络进行训练并测试,对比实验结果如表4 所示。可以看出,在PointNet 基础上加入CAC 层后mIoU 提高了1.4%,因为CAC 层中聚合了多尺度上下文细粒度特征。采用M-CAC(M=3,dropout=0.7)后mIoU提高了0.2%,原因在于多头部机制提高了特征的丰富性,增强了网络的泛化能力。引入残差学习后mIoU 又提高了0.1%,因为残差学习在避免梯度消失问题的同时加深了网络容量,能够充分挖掘点云的深层语义特征信息。

表4 不同组件的有效性分析
3.4 室内和室外场景分割
为了验证本文算法对于大规模点云分析的有效性,在室内数据集S3DIS 和户外场景分割数据集vKITTI 上进行了训练和测试,并与主流算法进行了对比,实验结果如表5 和表6 所示。可以看出,本文算法语义分割的总体准确率(OA,overall accuracy)和mIoU 都优于其他主流方法,取得了较理想的分割准确率。除了定量分析外,图5 和图6 展示了定性的分割可视化结果。

表5 S3DIS 数据集上不同方法的分割准确率对比

表6 vKITTI 数据集上不同算法的分割准确率对比

图5 S3DIS 数据集上模型语义分割可视化

图6 vKITTI 数据集上模型语义分割可视化
从图5 中可以看出,CAC 层能够改善PointNet存在的欠分割问题,获得更准确的分割结果。例如,PointNet 对于椅子腿这类细粒度语义类识别能力有限,而本文算法能够很好地分割出椅子腿的边界腿梢,总体上以更少的错误分割整个场景,证明了本文算法的注意力编码机制能够挖掘局部点云的细粒度细节信息的能力。此外,相比于PointNet 的粗预测,本文算法对Board 的预测准确率也有所提高。原因在于Board 和Wall 的几何形状十分相似,只有上下文细节信息有所差异,本文算法能够结合Board 的上下文信息和Wall 的特征,可以更好地确定其边界,改善了欠分割问题,进一步证明了本文算法的上下文RNN 编码机制能够有效结合点云上下文几何信息的能力。在图6 中,本文算法对于几何形状极其相似的Terrain和Road 这两类语义的识别能力明显提高,总体分割错误率也相对较少,原因在于本文算法能够结合每个点的上下文细粒度信息,对于识别Terrain,能够结合其上下文Tree 的细粒度细节信息以便于确定其边界,可以减少与Road 的混淆。
4 结束语
本文提出了一种基于上下文注意力卷积神经网络的三维点云语义分割算法。首先将注意力机制引入CAC 层来挖掘点云的局部细粒度特征,其次通过RNN 编码不同尺度邻域特征以捕捉点云的多尺度上下文特征,与局部细粒度特征进行优势互补,并采用多头部机制增强了网络的泛化能力。同时在网络中引入残差学习进一步充分挖掘点云的深层隐含语义特征。定性和定量实验结果表明,本文算法有效改善了三维点云语义分割中存在的欠分割问题,总体分割准确率得到了提升,且本文算法在3 个标准公开数据集上都表现优异,充分证明了其具有良好的泛化性。然而,本文网络结构复杂,训练参数较多,难以适用于实时点云分割任务,如何构建一个可部署到嵌入式设备中的轻量级实时点云分割网络是需要进一步研究的问题。
猜你喜欢
红外技术(2022年11期)2022-11-25
北京航空航天大学学报(2022年8期)2022-08-31
农业工程学报(2022年7期)2022-07-09
逻辑学研究(2021年3期)2021-09-29
安阳工学院学报(2020年2期)2020-06-05
计算机应用与软件(2018年12期)2018-12-13
现代电子技术(2018年1期)2018-01-20
电脑知识与技术(2017年26期)2017-11-20
长江学术(2016年4期)2016-03-11
人间(2015年21期)2015-03-11
