
基于深度强化学习的道路目标检测
2020-08-10 02:38吴志鹏董超俊
现代计算机 2020年17期
吴志鹏,董超俊
(五邑大学智能制造学部,江门 529000)
0 引言
如今,随着社会经济的快速发展,汽车已成为几乎家家户户的便捷交通工具之一。这使得道路交通环境越来越复杂,人们期望有一个智能视觉辅助应用,为驾驶员提供交通标志信息,道路车辆信息,道路行人信息,以及协助车辆控制,来确保道路安全。道路目标检测与识别作为驾驶员辅助系统的重要功能之一,已经成为国内外研究人员的一个热点研究方向。它主要是利用车辆摄像头采集实时的道路图像,然后对道路上遇到的目标进行检测和识别,从而为驾驶系统提供准确的信息。
自卷积神经网络(Convolutional Neural Networks,CNN)被提出以来,目标检测的准确度有了较为明显的提高,其中比较经典的算法有R-CNN、Faster R-CNN等。R-CNN[1]是一种结合区域提名(Region Proposal)和卷积神经网络(CNN)的目标检测方法,采用的是选择性搜索(Selective Search),所以目标候选区的重叠使得CNN特征提取的计算中有着很大的冗余,在很大程度上限制了检测速度。而之后提出的Faster R-CNN[2]抛弃了选择性搜索(Selective Search),引入了区域候选网络(Region Proposal Networks,RPN),使得区域提名、分类、回归一起共用卷积特征,从而加速了目标检测的速度。但是Faster R-CNN需要先进行目标判定,然后再进行目标识别。所以两种算法在检测速度和稳定性上仍然有提升的空间。
深度强化学习,顾名思义是将深度学习的感知能力和强化学习的决策能力相结合,目的是让两种算法的优势得到互补,输入如果是图像,深度强化学习也可以直接进行控制。近年来,深度强化学习的热度一直很高。其中Mnih等人[3]结合卷积神经网络(CNN)和Q-learning算法,提出一种深度Q网络模型(Deep Q-Network,DQN),并且在雅达利2600游戏中表现出色。由于Q学习存在过高估计的现象,Hasselt等人[4]提出了深度双 Q网络(Deep Double Q-Network,DDQN),证明了DDQN可以减小过高估计带来的误差。之后,Schaul等人[5]在DQN中加入了优先级经验重放系统,可以更高效的使用样本。Hara等人[6]提出了一种深度增强学习,用于检测视觉目标。本文通过调整折扣因子γ和学习率α,可以使DQN模型更加稳定,学习的质量也有所提升,从而提高目标检测的精准的。
1 相关工作
1.1 强化学习
强化学习(Reinforcement Learning,RL),是机器学习分支。与传统机器学习不同的是,强化学习是通过奖励值来训练模型,而机器学习是通过标签和数据特征来训练模型的。强化学习一般用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题[7]。强化学习主要包含以下几个个元素:环境的状态S、个体的动作A、环境的奖励R、个体的策略π、奖励衰减因子γ和状态转化模型P。强化学习中通常会引入马尔可夫决策过程(Markov Decision Process,MDP)。一般的,会将马尔科夫决策过程定义为一个四元组。其中:
(1)状态S,有限集合{s1,s2,…,sN},即|S|=N。对于建模的问题来说,状态是所有信息中唯一的特征。
(2)动作 A,有限集合{a1,a2,…,aN},即|A|=N。能够用于某个状态s∈S的集合表示为 A(s),其中A(s)⊆A。
(3)转换函数 P,可以通过如下方式定义:S×A×S→[0,1],即它是从(S,A,S)三元组映射到一个概率的函数,其概率表示为P(s,a,s′),表示,从状态s转换到状态s′的概率,其值需要满足 0≤P(s,a,s′)≤1 且,即概率必须满足实际,否则无意义。
(4)奖励函数R,可以定义为S×A→R,在某状态执行某动作获得奖励。
马尔科夫决策过程与环境交互如图1所示。

图1 马尔可夫决策过程
这里假设未来每个时间步获得的即时奖励都必须乘以一个折扣因子γ,则从t时刻开始到T时刻情节结束时,奖励之和定义为:

其中,Rt称之为回报或者累计奖赏,γ∈(0,1]称之为折扣因子。Agent的目标是通过最大化每个状态st下的期望累未来回报的方式来选择操作。
状态-动作值函数:在状态下执行动作后获得的期望回报。

对于所有的动作状态,假如一个策略π*的期望回报大于等于其他策略的期望回报,那么策略π*即为最优策略。

公式(3)为最优状态动作值函数,即当处于状态s,执行了动作a,然后再按照π执行下去到最后,能获得的最大累计回报与期望。并且此值函数遵循贝尔曼最优方程(Bellman Optimality Equation)。即:
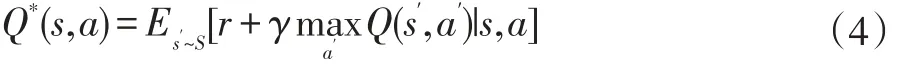
强化学习算法的基本思想是通过使用贝尔曼方程作为迭代更新来估计动作值函数:

当i→∞时,Qi→Q*。这种值迭代算法收敛于最优动作值函数。但是实际上,这种基本方法是完全不切实际的,因为每个序列的作用值函数是单独估计的,没有任何概括。相反,使用函数逼近器来估计动作值函数是常见的,即Q(s,a|θ)≈Q*(s,a)。
1.2 深度Q 网络
深度Q网络(Deep Q-Network,DQN)是 DeepMind团队提出来的深度强化学习算法,它是将卷积神经网络与强化学习中的Q-learning算法相结合,这里卷积神经网络的作用是对在高维且连续状态下的Q-Table做函数拟合,DQN相比于Q-learning有三大改进:①加入了卷积神经网络;②引入了目标网络(Target Network);③训练过程中应用了经验回放机制(Experience Replay)。图2表示了DQN的训练流程。
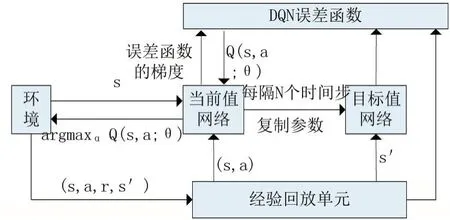
图2 DQN的训练流程
经验回放机制[8],把每个时间步中个体和环境交互所得到的经验样本数据存储到经验池中,当模型在进行训练时,就会从经验池中随机抽取小批量的样本进行训练。引入经验回放机制后,不仅可以较为容易的对奖励数据进行备份,并且随机的从经验池中抽取小批量的数据也减小了样本之间的关联性,提高了系统的稳定性。其中,经验样本是以五元组(s,a,r,s’,T)的形式进行存储的。具体表示为个体在状态s下执行动作a,到达下一个状态s’,就可以获得相应的奖励r。其中T表示下一个状态s’是否为终止状态。
在经典Q-learning算法中,目标Q值会随着预测Q值得增大而增大,这会是模型有震荡或者发散的可能性。所以DQN使用了两个神经网络模型:一个是用卷积神经网络来近似表示当前值函数,另一个神经网络则用来产生目标Q值。
目标函数为:

当前状态下估计值和目标值之间的误差计算公式(损失函数):

DQN算法根据损失函数的公式来更新神经网络中的参数,通过引入目标函数,使得一段时间里目标Q值是不变的,在一定的程度上降低了两个Q值得相关性,使得训练时损失震荡甚至是发散的概率降低,提高了算法的稳定性。
1.3 自适应学习率
通过实验表明,高度复杂的任务,DQN可以很好地训练,但存在过度拟合的风险。相反,复杂度较低的模型不会过度拟合,但可能无法捕获重要的特性。这时候,折扣因子γ在DQN的训练过程中起到了作用,当折扣因子γ在训练过程中越来越逼近其最终值,则可以加快魔性的收敛,从而降低了过拟合的现象,增加了系统的稳定性。

随着折扣因子的增加,学习率随之降低,最终可以得到一个稳定的DQN训练模型。

2 实验与分析
2.1 数据准备
本文主要采用的是伯克利大学AI实验室(BAIR)发布的bdd100k数据集,数据集中的GT框标签共有10 个类别,分别为:Bus、Light、Sign、Person、Bike、Truck、Motor、Car、Train、Rider。其中包含了 10 万段高清视频,每个视频大约约40秒,分辨率为720p,帧数为30fps。每个视频从第10秒对关键帧进行采样,从中获得了10万张图片,并进行标注。在10万张图片中,包含了不同天气、场景、时间的图片,包括晴天、阴天和雨天,以及白天和晚上的不同时间。并且数据集中都是真实的驾驶场景。
2.2 评价标准
由于bdd100k数据集中有多个图像标签,所以本文采用计算平均精度的方式来衡量目标检测模型的性能。下面是查准率(precision)和查全率(recall)的定义:

由此可以得到查准率-查全率曲线,简称“P-R曲线”。由于P-R曲线不方便比较不同模型的性能,所以将P-R曲线换算为mAP值进行比较。
2.3 实验
将bdd100k数据集中的100000张图像导入深度Q网络模型,本文的实验采用了Python编程语言,是Python 3.7。深度学习框架采用了TensorFlow1.0.1。将样本图片分为 Bus、Light、Sign、Person、Bike、Truck、Motor、Car、Train、Rider等 10 大类,不同的图片类别被用作1,2,…,9,10个标记。将数据库中70000张图像作为训练数据,30000张图像作为测试数据。根据类别标识设置每组信号的期望输出值。实验结果如表1。

表1 不同方法下的相同训练域的mAP值比较
由表1可以看出,本文在晴天(clear)、白天(daytime)、城市街道(city)三种不同的环境下,用两种不同的方法进行对比。实验结果表明,本文提出的带自适应学习率的深度Q网络在目标检测的精准度上,有一定的提升;并且在城市街道(city)的环境下表现的最好。
3 结语
本文应用了带自适应学习率的深度Q网络,并将此方法建立模型用于道路目标的检测。实验证明了本文提出的方法优于以前的经典算法,确实提高了模型在复杂环境下对目标的检测性能。希望在将来,本文提出的方法能够得到更深层次的研究,并能够不断地优化对于不同对象的检测性能。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
领导文萃(2019年8期)2019-04-19
读友·少年文学(清雅版)(2018年12期)2018-04-04
软件(2017年6期)2017-09-23
