
基于异质网络表征学习的链路预测算法
2020-08-10 02:38蒋宗礼管戈
现代计算机 2020年17期
蒋宗礼,管戈
(北京工业大学信息学部,北京100124)
0 引言
随着人工智能和数据科学的发展,网络建模分析成为网络研究中一个热点方向。早期研究通常把网络建模成同质信息网络。然而我们现实中遇到的大多数系统并不是只有一种相同单元节点组成的,而是包含了多种相互关联、类型不同的单元节点组成。使用同质网络模型抽象系统的方法很难处理复杂多样的网络,这样做会导致网络的信息缺失。尤其近些年各种社交网络、购物网络的涌现使得同质网络无法处理多类型关系网络的问题日益凸显。为了解决这些问题,研究人员提出了异质信息网络的建模方式。与同质网络相比,异质网络包含了更丰富对象类型和更复杂的连接关系。异质网络所蕴含的更加丰富的语义信息对网络的挖掘、分析有着重要意义。
在大数据时代网络科学发展迅速,链路预测成为数据挖掘的一个重要研究方向。它不仅对研究网络演化有着重要意义,也在实际问题处理中被广泛应用。但是,当前多数链路预测方法主要针对于同质网络,异质网络因为其网络结构和蕴含信息的复杂性无法将同质网络的研究方法直接应用在它身上。所以研究异质网络的链路预测对复杂网络本身的研究有着深刻意义。
1 国内外研究现状
近几年网络科学的快速发展,为链路预测的研究提供了广阔的平台。链路预测作为数据挖掘的一个重要研究方向已产出许多研究成果。在同质网络中的链路预测主要基于网络相似性分析,可以分为以下三类:基于局部信息相似性、基于路径相似性和基于随机游走相似性。根据局部信息相似性判断的方法有很多,例如 CN(Common Neighbors)指标[1],通过两点共同邻居的数量来判断产生连接的概率。与之相似的还有Salton等人提出的余弦相似性指标[2]以及Jaccard指标[3]和Sorenson指标[4]。这些指标都是从公共邻居的角度出发预测连接可能性。在此基础上,Adamic等人考虑到共同邻居节点的度信息,认为度小的共同邻居贡献更大,并根据度的大小赋予一个权重提出了AA(Adamic Adar)指标[5]。还有通过路径相似性来预测连接概率,例如Lu等人提出的局部路径指标LP(Local Path)[6]这种方法与局部信息相似性指标类似,又考虑了三阶邻居的影响;还有Katz等人提出的Katz指标[7]主要是对路径赋予权重,路径越长权重越小。基于随机游走的相似性指标中常见的有Klein等人提出的平均通勤时间即ACT(Average Commute Time)指标[8];Brin 等人提出了一种 RWR(Random Walk with Restart)指标[9],这种方法本质上是在网页排序中常用的重启随机游走算法的扩展。
相比于同质网络,针对异质网络链路预测的研究成果较少。Davis等人提出了一种多关系的链路预测算法 MRLP(Multi-Relational Link Prediction)[10],作为AA指标在异质网络上的一种扩展,通过概率加权不同链接类型来定义连接概率。Yang等人提出的MRIP(Multi-Relational Influence Propagation)[11]方法通过节点间的相互影响力来预测连接概率。黄立威等人[12]根据元路径的质量权重建立预测模型,构建出一种基于元路径的链路预测方法。
2 基于异质网络表征学习的链路预测模型
通过对过往研究的分析,我们发现多数链路预测方法都是基于节点相似度,所以如何量化网络节点的相似度是问题的关键。与同质网络不同,异质网络不同类型的节点和链接关系给量化节点间的相似度增加了难度。为解决这一问题,我们选择网络表征学习来降维表示网络,在提取网络特征的同时也量化了网络节点。我们提出一种基于异质网络表征学习的链路预测模型 RLLP(Representation Learning Link Prediction)。
2.1 问题定义
定义1:异质信息网络
给定一个信息网络G=(V,E),其中,V是节点集合,E是连接集合(边集合)。对任意节点v,存在节点类型Ai∈A满足v→Ai,A是所有节点类型的集合;对任意边e,存在边类型Ri∈R满足e→Ri,R是所有边类型的集合。如果满足A>1或者R>1,则该网络定义为异质信息网络,反之定义为同质信息网络。
定义2:元路径
元路径是定义在网络概要图TG=(A,R)上的路径,可 以 表 示 成,其中,A1,A2,…,Ai+1表示的是不同类型的节点,R1,R2,…,Ri表示的是不同类型节点之间的复合关系即网络中的边,箭头符号表示在关系上的综合操作。
定义3:网络表征学习
表征学习学习通常也被称为网络嵌入或者网络表示。给定一个信息网络G=(V,E),网络表征学习通过一系列学习训练生成一个目标函数f:v→rv∈Rd,通过这个函数可以将节点转换为低维向量表示,其中rv表示为节点v的表示向量,d为转换后的向量维度。
定义4:链路预测
给定一个异质信息网络G=(V,E),链路预测的任务是预测G中两个节点未来是否会产生连接或者存在连接的可能。链路预测的目标是通过计算找到并学习一个预测函数f:( )V,E,vi,vj,l→P,通过函数可以计算出给定两个节点vi和vj之间产生连接即可能存在或未来会产生的边l概率,其中P表示两个节点是否会产生关系的描述值。
2.2 基于元路径随机游走
如何捕获网络特征,对网络表征结果影响重大。受到网络表征方法Deepwalk[13]的启发,我们选用随机游走来获取网络的结构特征。但异质网络因为存在不同类型的节点和边,所以如果按照同质网络的方法进行随机游走,那样会忽略了节点类型信息。为了能够在捕获异质网络不同节点关系的同时尽可能的保证网络结构的整体性和完整性,随机游走需要满足两点:一是选取的路径尽可能多的包含不同种类的节点类型,这样才可以采集异质网络中不同类型节点的相互关系和拓扑结构;二是随机游走对下一节点的选定,需要偏向于高度可见的节点类型,即具有优势或主导数量的节点。本文借鉴了异质网络表征方法metapath2vec[14]的思想,使用了基于元路径的随机游走,捕获不同类型节点之间的语义和结构相关性。给定一个异质网络G=(V,E)和元路径P:V1→V2→…Vt→Vt+1…→V2→V1那么第i步的转移概率可定义为:

其中P是定义的元路径,节点表示节点的邻域中属于Vt+1类型的节点集合。换而言之,随机游走是建立在给定的元路径P条件上的。且本文选用的元路径均为对称路径:

2.3 训练模型网络表征
完成随机游走对网络的特征采集后,我们需要使用游走序列训练神经网络模型,进而完成对网络的表征。本文选用Skip-Gram模型对网络进行表征学习。Skip-Gram[15]最早是由Tomas等人提出的一种词嵌入模型,被广泛应用于自然语言处理。这个模型的基本思想是通过神经网络的学习,将文本单词转换到低维的实数向量空间中,以此简化文本处理。例如在处理文本相似度时,可以通过计算向量相似度来处理文本相似性问题。
为了将其应用在异质网络上,我们采用metapath2vec算法的处理方式,对模型参数进行一下修改。给定一个异质网络G=(V,E),通过在节点v的邻域上最大化条件概率来表征学习该网络:
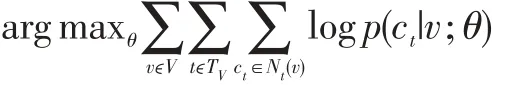
其中t∈TV,TV表示节点类型的集合,Nt(v)代表节点v的邻域中属于节点类型t的节点集合,p(ct|v;θ)表示为在给定节点v的情况下,节点ct的条件概率,并将其定义为Softmax函数:
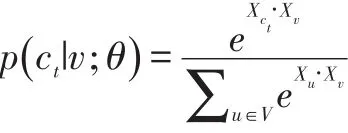
其中Xv表示顶点v的嵌入向量。为了优化参数更新效率,采用了负采样进行参数迭代更新,给定一个负采样的大小M,参数更新过程如下:

2.4 计算相似度矩阵
通过以上两个步骤,我们完成对异质信息网络的表征学习,可以得到各个节点的向量表示。一般认为,节点之间相似度越高,那他们之间产生链接的概率也就越大。所以,我们将网络节点间链接预测问题转化为判断节点向量间的相似性问题。我们采用节多维向量的欧氏距离来计算节点向量间的相似性。存在维度为d的向量vx:(x1,x1,…,xd)和vy:(y1,y1,…,yd),定义两向量间的相似度为:
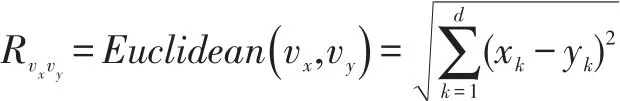
为了对链接类型分类并计算预测准确率,本文会构建一个相似度矩阵来存储各个节点间的相似度也就是链路连接概率。正常一个节点数为N的网络,两两计算出一个链接概率会产生一个N*N的相似度矩阵,显然这不适用于大规模网络。本文研究的是异质网络的链路预测,所以在预测节点链接时区分了链接类型,对不同类型的链接建立不同的相似度矩阵。假设存在节点类型x和节点类型y,这两类节点建立的链接类型为R,那么定义节点xi和节点yj产生链接的概率为链接类型为R的相似度矩阵E定义如下:

3 实验与结果
3.1 数据集
实验使用IMDB(Internet Movie Database)数据集。该数据集包含了众多电影、演员、导演、评分、出版商等电影信息。为方便使用,我们需要对数据集进行预处理。首先我们从数据集中提取出五种类型的节点:电影 M(Movie)、演员 A(Actor)、导演 D(Director)、电影类型 G(Genre)、电影出版国家 C(Country)。同时抽离出四种关系:演员和电影的参演关系A-M、导演和电影的指导关系D-M、电影和电影类型的所属关系M-G以及电影和出版国家的出版地关系M-C。以上信息构建出我们所需的异质信息网络。
经验证本文方法对于网络中的隐藏关系的预测效果更好,因此,我们提取出三种不在网络中直接提现的隐藏关系:演员之间的合作关系A-A、演员和导演之间的合作关系A-D以及演员和电影类型之间的参演喜好关系A-G作为研究对象。因元路径的选取对网络表征具有较大影响。我们对不同关系选取不同的元路径,选用演员-电影-导演-电影-演员(AMDMA)作为研究AD关系的元路径,选用演员-电影-电影类型-电影-演员(AMGMA)作为研究AA关系和AG关系的元路径。
3.2 度量标准与基准方法
为了验证算法的准确性,本文选用AUC[16]作为度量指标。AUC是一种可以衡量算法预测准确率的度量标准。具体是从测试集网络中选取一条边,按给定算法计算它分数值代表产生连接的概率,然后从网络中随机选取一条不存在的边计算分值进行比较,如果测试集中选取的边的分值高,则累计1分;两者相累计0.5分;而如果不存在的边分值更高,则不计分数。独立比较n次,假设有n'累计1分;n''次累计0.5分,则AUC如下:
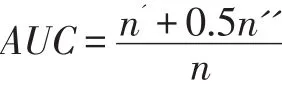
换而言之,AUC体现了存在链接的预测值比不存在的链接的预测值高的概率。显然,如果通过随机选择进行链路预测,则AUC应在0.5左后。因此,AUC越高,预测算法准确率就越高且至少应高于0.5。
同时作为对比,本文选用了四个常用指标作为校准方法,各算法相似性指标的定义描述如下。
CN指标:认为两节点公共邻居越多,产生连接的概率越大。给定节点x和y,其邻居集合分别为Γ(x)和Γ(y),则两个节点相似性定义为
AA指标:与CN指标类似,考虑了共同邻居节点度的影响,认为度小的共同邻居贡献更大,并将节点的度的对数分之一作为权重分配给该节点,即
LP指标:该指标基于节点间路径的相似性,根据连接两节点间长度为2和3的路径数量来定义节点相似性,即
RWR指标:重启随机游走指标,是一种网页排序算法的扩展。根据转移概率选择走向下一节点还是返回初始节点,以此来捕获两节点间的相似性。qxy表示从节点x出发到达y的概率,定义两节点连接概率为
3.3 实验结果
本文实验设计如下:选择数据集90%的边作为训练集,10%的边作为测试集。分别对演员之间的关系AA,演员与导演之间的关系AD以及演员与电影类型之间的关系AG计算预测结果的AUC,取10次独立实验结果的平均值并与CN、AA、LP、RWR四种算法进行比较。本文使用的四种基准方法主要应用在同质网络领域,为使其可以应用于异质网络,我们把不同类型的节点和边视为相同类型,在进行划分测试集和处理结果时再区分节点和边的类型,进而比较在不同关系上的链路预测准确度。实验结果如图1。
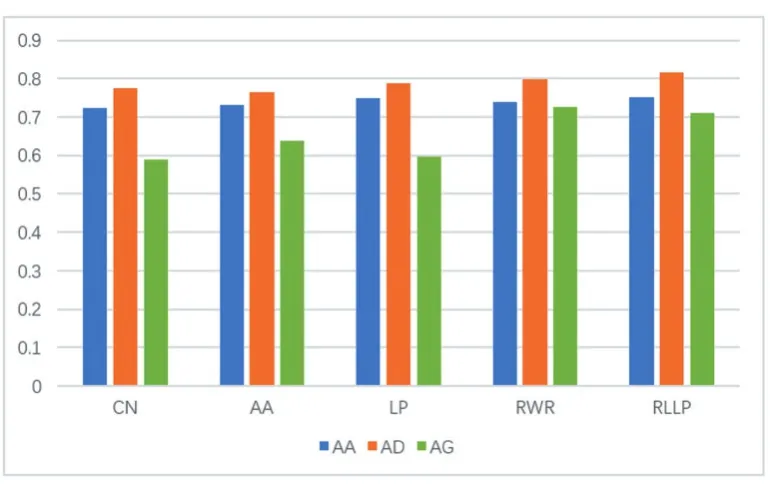
图1 RLLP算法和其他四种算法的对比
图1给出了RLLP算法和基准算法的对比。图中可以看出在AA关系和AD关系上,本文提出的RLLP算法均优于其他基准算法。其中AA关系的链路预测,平均预测准确率提高了2.17%;AD关系中,平均预测准确率提高了4.78%。虽然在AG关系的预测中,准确率不及RWR方法,但差距不大且明显优于其他三种方法。除此之外,我们还研究了算法参数对预测结果准确度的影响,实验结果如图2-图3。
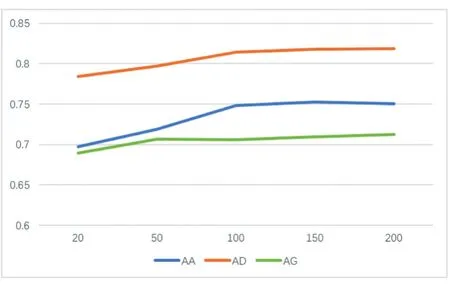
图2 随机游走的长度对预测结果的影响

图3 节点向量的维度对预测结果的影响
图2和图3分别展示了随机游走的长度和节点向量的维度对三种链接关系预测结果的影响。图2可以看出AUC的值会随着随机游走长度的增加而增加,当增加到一定值后会趋于稳定。这也从侧面印证了随机游走对网络结构的采集效果,随着游走长度的增加,对网络结构和语义信息的捕获就愈加越完整,因此预测的准确率就会升高。图3显示AUC的值会随嵌入后的节点向量的维度的变化产生一个峰值,表征后的节点向量维度太低会因为特征向量无法表征网络所蕴含的关系信息而影响预测准确率,同时也表明预测结果并不会因维度越高而变现越好,甚至会出现下降。所以选取一个合适的向量维度才能产生更好的效果。
4 结语
本文提出了基于异质网络表征学习的链路预测模型。通过实验可以看出,该模型对异质网络中某些类型的隐藏关系预测效果较好,可应用于智能推荐、辅助决策等实际问题。对于下一步的研究,希望尝试将该模型应用于多网络分析。可以将多个同质网络通过关键节点整合成类似异质网络的结构,分析多网络间的链路预测。
猜你喜欢
火力与指挥控制(2022年8期)2022-09-16
武汉大学学报(理学版)(2022年2期)2022-05-28
家庭教育报·教师论坛(2021年42期)2021-12-23
现代英语(2021年18期)2021-11-22
移动通信(2021年5期)2021-10-25
现代装饰(2021年1期)2021-03-29
分析化学(2019年3期)2019-03-30
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
科技创新导报(2016年27期)2017-03-14
