
基于深度卷积神经网络的科研项目不端行为识别研究
2021-03-21 07:04杨生举
中国建材科技 2021年4期
杨生举
(甘肃省科学技术情报研究所,甘肃 兰州 730000)
0 引言
近年来,国家实施创新驱动发展战略,科技经费持续增加,科研项目数量大幅增长。随之而来的问题是,科研项目不端行为(Scientific Research Project Misconduct,SRPM)层出不穷,如重复申报、多头立项,申请书伪造、抄袭、剽窃等现象。
从2006年“汉芯事件”开始,越来越多的科研不端行为被披露、调查、处理。2015年科技部在申报的项目中发现,因重复申报,有13%的973计划项目和20%的高新技术领域项目未能通过审查[1]。2016年12月12日,国家自然科学基金委员会通报了61份科研不端行为案件处理决定[2]。甘肃省通过项目相似度检查系统查出2016-2017年5904项申报项目中相似性80%以上的占4.5%。
SRPM治理具有复杂性和艰巨性,不端行为很难被发现,原因可能是单一数据库源查全率低,新的项目、成果、奖励、报告和论文数据库同步滞后,申请者对申报书有意识“修饰”,以及网络时代造假手段多样化等。
深入研究SRPM识别技术对遏止学术腐败、保护原创成果、净化学术氛围、推进科研诚信有重要的现实意义。SRPM治理是一个世界性难题,也是我国科技创新面临的重大课题。
1 国内外研究现状
1.1 科研不端识别系统及技术分析
治理和防范科研不端行为需要先进的技术手段作为支撑。国外高校对于反剽窃的研究高度重视,技术较成熟,科研不端识别系统已成为欧美高校的必用软件。Turnitin是全球最权威的学术不端识别系统,帮助科研工作者侦测和比对科研成果中含有的不恰当引用、潜在的剽窃行为。CrossCheck能最大程度检查学术不端行为,全球会员单位包括自然出版集团(NPG)、英国医学期刊出版集(BMJ)和美国科学进步协会(AAAS)等。
国内科研不端识别系统代表性的是CNKI科技期刊学术不端文献检测系统(AMLC)、万方论文相似性检测系统和维普通达论文引用检测系统[3]。
1.2 神经网络在语义相似度计算中应用分析
科研项目不端识别的核心技术是语义相似度计算。最早的神经网络词义相似度计算模型是神经网络概率语言模型,最有影响力的是Bengio等于2003年提出的神经网络语言模型(Neural Network Language Model,NNLM),研究者相继提出CBOW及Skip-gram等简易模型,训练词向量一般采用的算法是Hierarchical softmax[4]。
国内外学者对将神经网络应用于语义相似度计算进行了卓有成效的研究。蔡旭勋(2017)研究基于神经网络的词义相似度计算及其在文本检索技术中的应用,其算法提升文本检索的准确率、召回率与综合评价指标[4]。K. Selvi(2014)为了应用奇异值分解,在给定的文档中建立了词对的频率,提出了一种求解相似度量的人工神经网络算法[5]。Rui Cao(2015)基于语义相似性算法和人工神经网络的知识密集型的研究,提出了一种广义回归神经网络的语义相似度算法[6]。Hua He(2016)显式地模拟成对词的相互作用,并提出一种新的相似焦点机制来识别重要的对应关系,以便更好地进行相似性度量[7]。户保田(2016)提出了基于深度卷积神经网络的语句表示模型,通过多层交叠的卷积和最大池化操作对语句进行建模[8]。幸凯(2017)提出了基于主题词向量和长距离关联的卷积神经网络句子文本表示模型[9]。Zeng Shuifei(2017)提出了一种改进的文本表示模型提取文本特征词向量方法,能较好处理高质量的文本特征向量提取和表达序列[10]。以上研究为本研究提供了借鉴和参考。
2 基于卷积深度神经网络的语句匹配架构
2.1 语句匹配架构
如图1所示,将语句SX和SY中的词向量按照词的顺序排列。词向量通过Word2vec训练得到,维度为50,在两个语句上分别使用窗口大小为k1和k2的滑动窗口。
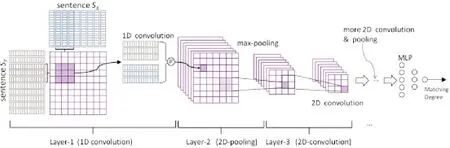
图1 基于卷积深度神经网络的语句匹配架构图
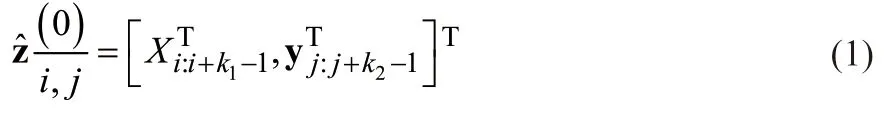

g(·)—为“门函数”;


2.2 语句匹配架构的训练
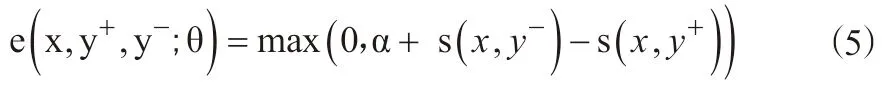
式中,θ—卷积架构与多层感知机的模型参数;
α—正确的匹配对 s (x,y+)得分比错误的匹配对s (x,y-)得分至少大的差值。
对于给定的语句对(x,y),其输出的匹配分数为s (x,y)。然后在其上使用逻辑回归分类器(logistic regression),则其类别“1”的概率见公式(6):

对于给定的语句对(x,y)的损失函数,见公式(7):

式中,ℓ取值为“0”或“1”,参数的更新采用基于随机批处理的后向传播算法。
3 结果与分析
3.1 试验数据
试验数据采用MSRP (Microsoft Research Paraphrase Corpus)。每个句子对的语义等效结果用0和1表示,1表示等效,0则反之。
3.2 评价指标
试验结果采用了精度Prec、准确度Acc、召回率Rec和F值作为衡量标准[11]。4个评价指标定义如下:
Prec=(TP)/(TP+FP)
Acc=(TP+TN)/(TP+TN+FP+FN)
Rec=(TP)/(TP+FN)
F=(2×Prec×Rec)/(Prec+Rec)
其中,FP、TP分别是预测相似但实际不相似、预测和实际都相似的句子数量;TN、FN分别是预测和实际都不相似、实际相似但预测不相似的句子数量[12]。
3.3 试验结果
结果如表1所示。表中L&C和Lin是基于知识库实现的方法,PMI-IR和LSA是基于语料库实现的方法。
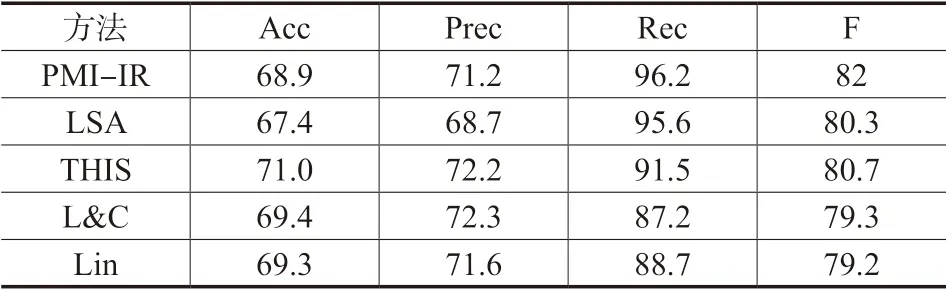
表1 文本相似性计算结果对比%
从表1可以看出,本文所用建模及计算方法有较高可行性。
4 结语
SRPM造成了学术资源和学术生命的极大浪费,破坏了正常的学术秩序,扼杀了创新活力,违背科学精神,加剧了社会腐败的蔓延,阻碍了科技进步和社会发展。本文研究大数据环境下科研项目不端行为的特征提取方法,提出基于深度卷积神经网络(DCNN)的语句表示模型和匹配架构,并对其进行有效训练,以学习得到语句匹配在不同层次上的表示,提高模型的表示能力,从而提高文本相似度计算的准确度和精度。
猜你喜欢
江科学术研究(2022年3期)2022-09-26
新世纪智能(语文备考)(2020年4期)2020-07-25
航天工业管理(2020年1期)2020-04-20
军事运筹与系统工程(2019年2期)2019-11-16
公民与法治(2016年4期)2016-05-17
天然气与石油(2016年5期)2016-02-11
出版与印刷(2015年3期)2015-12-19
西藏科技(2015年12期)2015-09-26
肝胆胰外科杂志(2015年4期)2015-02-27
语文知识(2014年4期)2014-02-28
